Innledning
Hva er et av de viktigste og viktigste begrepene av statistikk som gjør det mulig for oss å gjøre prediktiv modellering, og likevel forvirrer det ofte håpefulle dataforskere? Ja, jeg snakker om den sentrale grenseteoremet.
Det er et kraftig statistisk konsept som alle dataforskere MÅ vite. Nå, hvorfor er det?
Vel, den sentrale grense-setningen (CLT) er kjernen i hypotesetesting – en kritisk komponent i datavitenskapens livssyklus. Det stemmer, ideen som lar oss utforske de enorme mulighetene til dataene vi får, kommer fra CLT. Det er faktisk et enkelt begrep å forstå, men de fleste datavitenskapsmenn flyter på dette spørsmålet under intervjuer.
Vi vil forstå konseptet av Central Limit Theorem (CLT) i denne artikkelen. Vi får se hvorfor det er viktig, hvor det brukes, og deretter lære hvordan du bruker det i R.
Jeg anbefaler å gå gjennom artikkelen nedenfor hvis du trenger en rask oppdatering på distribusjonen og dens forskjellige typer:
- 6 Vanlige sannsynlighetsfordelinger alle data-fagpersoner burde vite
Innholdsfortegnelse
- Hva er sentralt setning (CLT) )?
- Betydningen av sentralgrenseteoremet
- Statistisk betydning
- Praktiske anvendelser
- Forutsetninger bak Central Limit Theorem
- Implementering av the Central Limit Theorem in R
Hva er Central Limit Theorem (CLT)?
La oss forstå den sentrale grensen setning ved hjelp av et eksempel. Dette vil hjelpe deg med å forstå intuitivt hvordan CLT fungerer under.
Tenk på at det er 15 seksjoner i vitenskapsavdelingen ved et universitet, og hver seksjon er vert for rundt 100 studenter. Vår oppgave er å beregne gjennomsnittsvekten til studenter i realfagsavdelingen. Høres enkelt ut, ikke sant?
Tilnærmingen jeg får fra ambisiøse dataforskere er å bare beregne gjennomsnittet:
- Først måler du vektene til alle studentene i realfagsavdelingen.
- Legg til alle vektene
- Del til slutt den totale vekten med et totalt antall studenter for å få gjennomsnittet
Men hva om størrelsen på dataene er enorme? Har denne tilnærmingen mening? Ikke egentlig – å måle vekten til alle studentene vil være en veldig slitsom og lang prosess. Så, hva kan vi gjøre i stedet? La oss se på en alternativ tilnærming.
- Tegn først grupper av studenter tilfeldig fra klassen. Vi vil kalle dette et utvalg. Vi tegner flere eksempler, hver bestående av 30 studenter.

Kilde: http://www.123rf.com
- Beregn det individuelle gjennomsnittet av disse prøvene
- Beregn gjennomsnittet av disse prøvene
- Denne verdien vil gi oss den omtrentlige gjennomsnittsvekten til studentene i naturvitenskapelig avdeling.
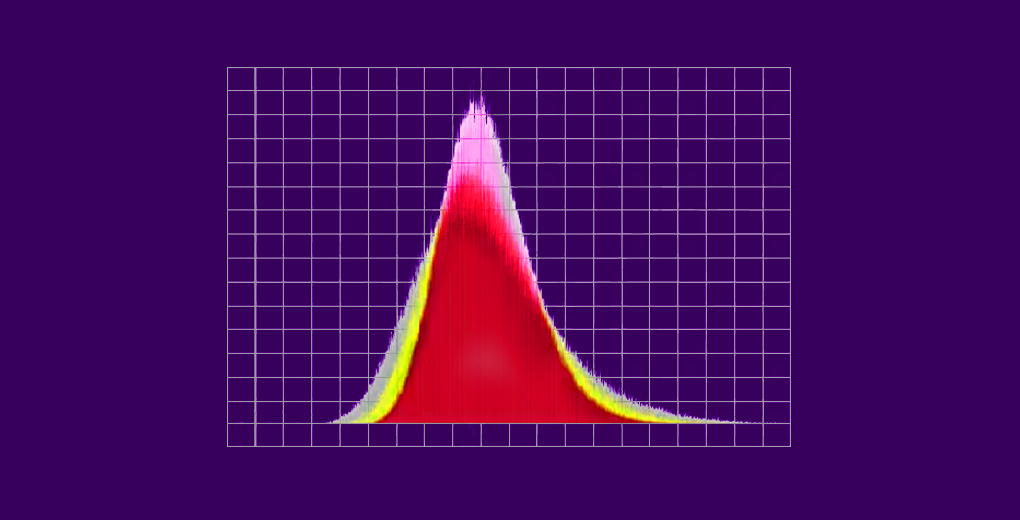
- I tillegg vil histogrammet til prøvenes gjennomsnittlige vekter for studenter ligne en bjellekurve (eller normalfordeling)
Dette, i et nøtteskall, er hva den sentrale grensesetningen handler om. Hvis du tar læringen din gjennom videoer, kan du sjekke ut introduksjonen nedenfor til sentralgrense-setningen. Dette er en del av den omfattende statistikkmodulen i kurset ‘Introduksjon til datavitenskap’:
Definisjon av den sentrale grense teoretisk
La oss sette en formell definisjon på CLT:
Gitt et datasett med ukjent fordeling (det kan være ensartet, binomialt eller helt tilfeldig), vil eksemplet betyr omtrent normalfordeling.
Disse prøvene skal ha tilstrekkelig størrelse. Fordelingen av eksempler betyr, beregnet fra gjentatt prøvetaking, har en tendens til normalitet når størrelsen på prøvene dine blir større.
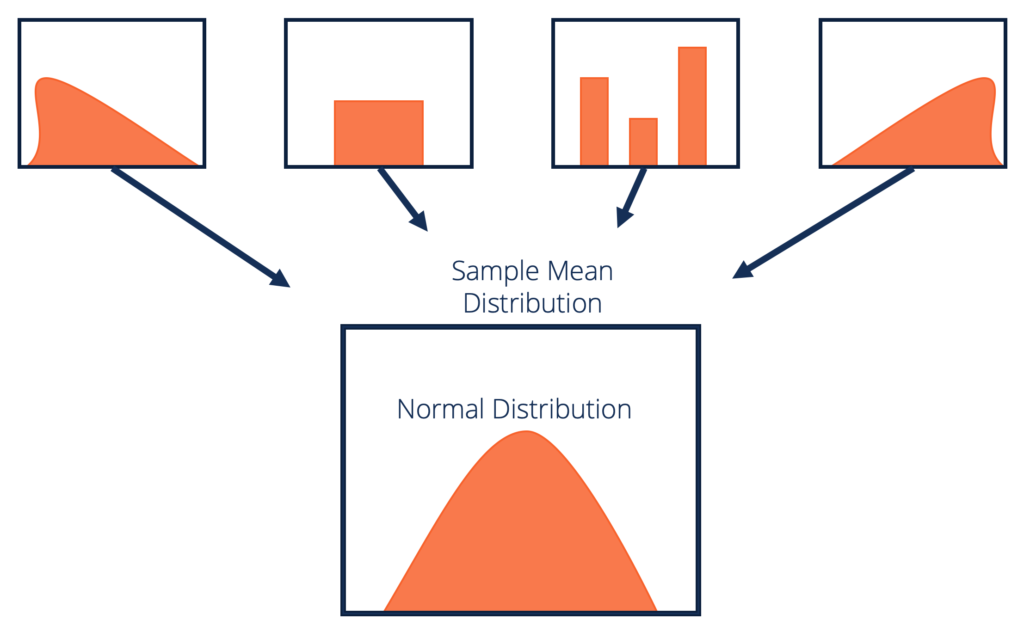
Kilde: corporatefinanceinstitute.com
Den sentrale grensesetningen har et bredt spekter av applikasjoner innen mange felt. La oss se på dem i neste avsnitt.
Betydningen av den sentrale grensesetningen
Den sentrale grensesetningen har både statistisk betydning og praktiske anvendelser . Er det ikke det søte stedet vi sikter mot når vi lærer et nytt konsept?
Vi vil se på begge aspektene for å måle hvor vi kan bruke dem.
Statistisk betydning av CLT

Kilde: http://srjcstaff.santarosa.edu
- Analysering av data innebærer statistiske metoder som hypotesetesting og konstruering av konfidensintervaller. Disse metodene forutsetter at befolkningen er normalt fordelt.I tilfelle ukjente eller ikke-normale fordelinger, behandler vi prøvetakingsfordelingen som normal i henhold til sentralgrenseteksten
- Hvis vi øker prøvene som trekkes fra populasjonen, vil standardavviket til prøvemidlene reduseres. Dette hjelper oss med å estimere populasjonsgjennomsnittet mye mer nøyaktig
- Også gjennomsnittet av prøven kan brukes til å lage verdiområdet kjent som et konfidensintervall (som sannsynligvis vil bestå av gjennomsnittet for populasjonen)
Praktiske anvendelser av CLT
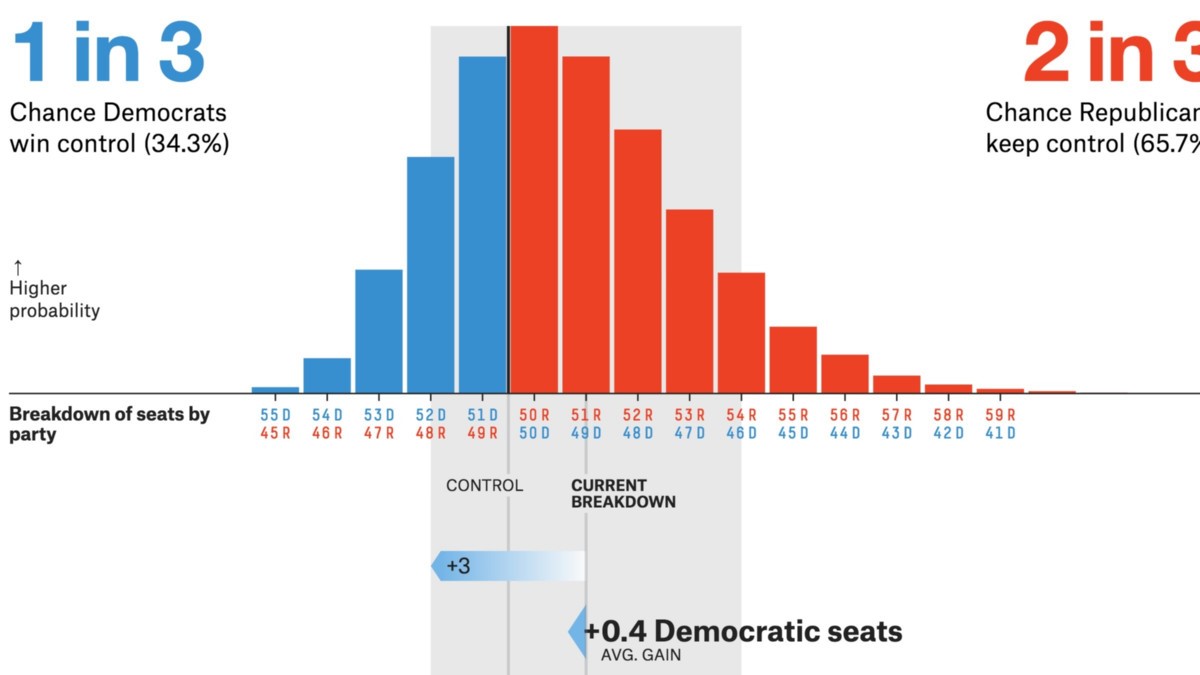
Kilde: prosjekter .fivethirtyeight.com
- Politiske valg / valgmålinger er de viktigste CLT-applikasjonene. Disse meningsmålingene estimerer prosentandelen av mennesker som støtter en bestemt kandidat. Du har kanskje sett disse resultatene på nyhetskanaler som kommer med tillitsintervaller. Sentralgrense-setningen hjelper til med å beregne at
- Konfidensintervall, en anvendelse av CLT, brukes til å beregne gjennomsnittlig familieinntekt for en bestemt region
Den sentrale grense-teoremet har mange applikasjoner innen forskjellige felt. Kan du tenke deg flere eksempler? Gi meg beskjed i kommentarfeltet under artikkelen – jeg vil ta dem med her.
Forutsetninger bak sentralgrenseteoremet
Før vi dykker ned i implementeringen av sentralgrenseteoremet, er det viktig å forstå forutsetningene bak denne teknikken:
- Dataene må følge randomiseringsbetingelsen. Det må samples tilfeldig
- Prøver skal være uavhengige av hverandre. Ett utvalg bør ikke påvirke de andre prøvene
- Størrelsen på prøvene bør ikke være mer enn 10% av populasjonen når prøvetaking utføres uten erstatning
- Størrelsen på prøvene skal være tilstrekkelig stor. Nå, hvordan skal vi finne ut hvor stor denne størrelsen skal være? Vel, det kommer an på befolkningen. Når populasjonen er skjev eller asymmetrisk, bør utvalgsstørrelsen være stor. Hvis populasjonen er symmetrisk, kan vi også tegne små prøver.
Generelt anses en prøvestørrelse på 30 å være tilstrekkelig når populasjonen er symmetrisk.
middelverdien av prøven betyr:
µ X̄ = µ
hvor,
- µ X̄ = Gjennomsnitt av prøven betyr
- µ = Gjennomsnitt for populasjon
Og standardavviket til prøven er betegnet som:
σ X̄ = σ / sqrt (n)
hvor,
- σ X̄ = Standardavvik for prøven betyr
- σ = Befolkningsstandardavvik
- n = utvalgsstørrelse
Og det er det for konseptet bak sentralgrensetning. På tide å fyre opp RStudio og grave i CLTs implementering!
Implementering av Central Limit Theorem in R
Glad for å se hvordan vi kan kode sentralgrense-setningen i R? La oss grave inn da.
Forståelse av problemstillingen
En rørproduserende organisasjon produserer forskjellige typer rør. Vi får månedlige data om veggtykkelsen til visse typer rør. Du kan laste ned dataene her.
Organisasjonen ønsker å analysere dataene ved å utføre hypotesetesting og konstruere konfidensintervaller for å implementere noen strategier i fremtiden. Utfordringen er at distribusjonen av dataene ikke er normal.
Merk: Denne analysen fungerer på noen få forutsetninger, og en av dem er at dataene skal distribueres normalt.
Løsning Metodikk
Den sentrale grensesetningen vil hjelpe oss med å komme oss rundt problemet med disse dataene der befolkningen ikke er normal. Derfor vil vi simulere den sentrale grensesetningen på det gitte datasettet i R trinn for trinn. Så la oss komme i gang.
Importer CSV-datasettet og valider det
Først importerer du CSV-filen i R og validerer deretter dataene for korrekthet:
Utgang:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
Deretter beregner du befolkningens gjennomsnitt og plotter alle observasjonene av dataene:
Utgang:
#Calculate the population mean 12.80205
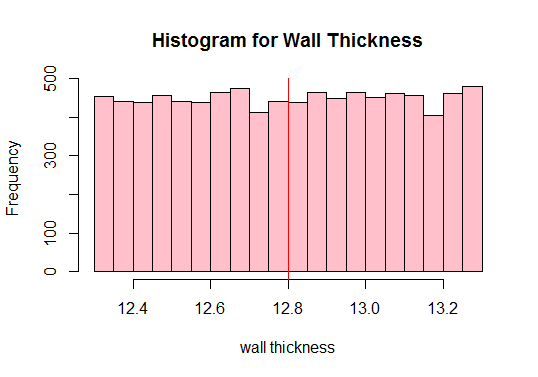
Se den røde loddrett linje over? Det er befolkningens gjennomsnitt. Vi kan også se fra plottet ovenfor at befolkningen ikke er normal, ikke sant? Derfor må vi tegne tilstrekkelige prøver i forskjellige størrelser og beregne deres middel (kjent som eksempler). Vi vil deretter plotte de prøvemidlene for å få en normalfordeling.
I vårt eksempel vil vi tegne tilstrekkelige eksempler på størrelse 10, beregne gjennomsnittet og plotte dem i R. Jeg vet at minimumsstørrelsen på prøven tatt skal være 30, men la oss bare se hva som skjer når vi tegner 10:
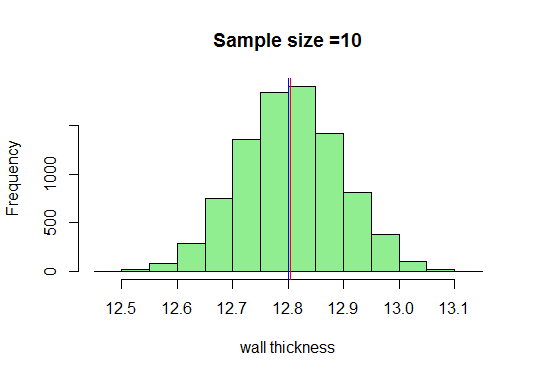
Nå, vi vet at vi får en veldig fin klokkeformet kurve når prøvestørrelsene øker. La oss nå øke størrelsen på utvalget og se hva vi får:
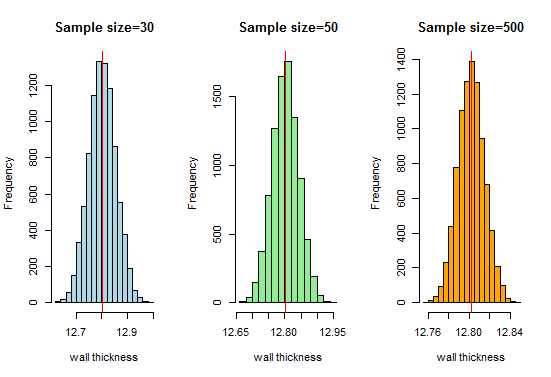
Her får vi en god klokkeformet kurve og prøvetaksfordelingen nærmer seg normalfordeling når prøvestørrelsene øker.Derfor kan vi betrakte prøvetakingsfordelingene som normale, og rørproduksjonsorganisasjonen kan bruke disse fordelingen for videre analyse.
Du kan også spille rundt ved å ta forskjellige prøvestørrelser og tegne et annet antall prøver. Gi meg beskjed om hvordan det fungerer for deg!
Sluttnotater
Sentralgrense-setning er et ganske viktig begrep i statistikk, og følgelig datavitenskap. Jeg kan ikke stresse nok med hvor kritisk det er at du pusser på statistikkunnskapen din før du går inn i datavitenskap eller til og med sitter på et datavitenskapssamtale.
Jeg anbefaler å ta kurset Introduksjon til datavitenskap – det er en omfattende statistikk før du introduserer datavitenskap.
