概要
最も重要でコアとなる概念の1つは何ですか予測モデリングを可能にする統計の数ですが、それでも意欲的なデータサイエンティストを混乱させることがよくありますか?はい、中心極限定理について話しています。
これは、すべてのデータサイエンティストが知っておく必要のある強力な統計概念です。さて、それはなぜですか?
中心極限定理(CLT)は、データサイエンスのライフサイクルの重要な要素である仮説検定の中心です。そうです、私たちに与えられたデータの広大な可能性を探求することを可能にするアイデアは、CLTから生まれました。実際には理解するのは簡単な概念ですが、ほとんどのデータサイエンティストは、インタビュー中にこの質問に悩まされます。
概念を理解しますこの記事の中心極限定理(CLT)の概要。なぜそれが重要なのか、どこで使用されるのかを見てから、Rで適用する方法を学びます。
配布とそのさまざまなタイプについて簡単に復習する必要がある場合は、以下の記事を読むことをお勧めします。
- 6すべてのデータサイエンスの専門家が知っておくべき一般的な確率分布
目次
- 中心極限定理(CLT)とは)?
- 中心極限定理の重要性
- 統計的重要性
- 実用的なアプリケーション
- 背後にある仮定中心極限定理
- Rで中心極限定理を実装する
中心極限定理(CLT)とは何ですか?
中心極限定理を理解しましょう例の助けを借りて定理。これは、CLTがその下でどのように機能するかを直感的に理解するのに役立ちます。
大学の科学部門には15のセクションがあり、各セクションには約100人の学生がいると考えてください。私たちの仕事は、理科の学生の平均体重を計算することです。簡単そうに聞こえますか?
意欲的なデータサイエンティストから得られるアプローチは、単純に平均を計算することです。
- まず、科学部門のすべての学生の体重を測定します。
- すべての重みを追加します
- 最後に、重みの合計を生徒の総数で割って平均を求めます
ただし、データのサイズは巨大ですか?このアプローチは理にかなっていますか?実際にはそうではありません–すべての生徒の体重を測定することは、非常に面倒で長いプロセスになります。では、代わりに何ができるでしょうか?別のアプローチを見てみましょう。
- まず、クラスからランダムに生徒のグループを選びます。これをサンプルと呼びます。それぞれ30人の学生で構成される複数のサンプルを描画します。

出典:http://www.123rf.com
- これらのサンプルの個々の平均を計算する
- これらのサンプルの平均を計算する
- この値は、科学部門の学生のおおよその平均体重を示します
- さらに、学生のサンプル平均体重のヒストグラムは、ベルカーブ(または正規分布)に似ています
これは、一言で言えば、中心極限定理のすべてです。ビデオを通して学習する場合は、以下の中心極限定理の概要を確認してください。これは、「データサイエンス入門」コースの包括的な統計モジュールの一部です。
中心極限定理の正式な定義
CLTに正式な定義を入れましょう:
分布が不明なデータセット(均一、二項、または完全にランダムの可能性があります)が与えられた場合、サンプル平均は正規分布に近似します。
これらのサンプルは十分なサイズである必要があります。繰り返しサンプリングから計算されたサンプル平均の分布は、サンプルのサイズが大きくなるにつれて正常になる傾向があります。
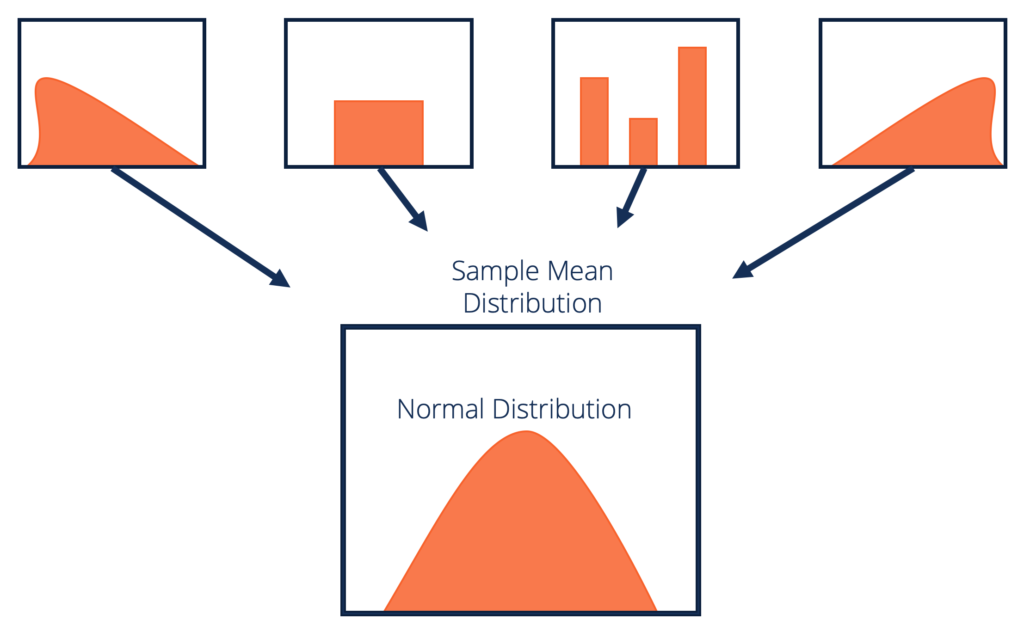
出典:corporatefinanceinstitute.com
中心極限定理には、さまざまな分野でさまざまな用途があります。次のセクションでそれらを見てみましょう。
中心極限定理の重要性
中心極限定理には、統計的有意性と実際のアプリケーションの両方があります。 。新しい概念を学習するときに私たちが目指すスイートスポットではありませんか?
両方の側面を見て、それらをどこで使用できるかを判断します。
統計的有意性CLTの

出典:http://srjcstaff.santarosa.edu
- データの分析には、仮説検定や信頼区間の構築などの統計的手法が含まれます。これらの方法は、母集団が正規分布していることを前提としています。未知または非正規分布の場合、中心極限定理に従ってサンプリング分布を正規として扱います。
- 母集団から抽出されたサンプルを増やすと、サンプル平均の標準偏差が減少します。これにより、母平均をより正確に推定できます。
- また、サンプル平均を使用して、信頼区間(母平均で構成される可能性が高い)と呼ばれる値の範囲を作成できます。
CLTの実用的なアプリケーション
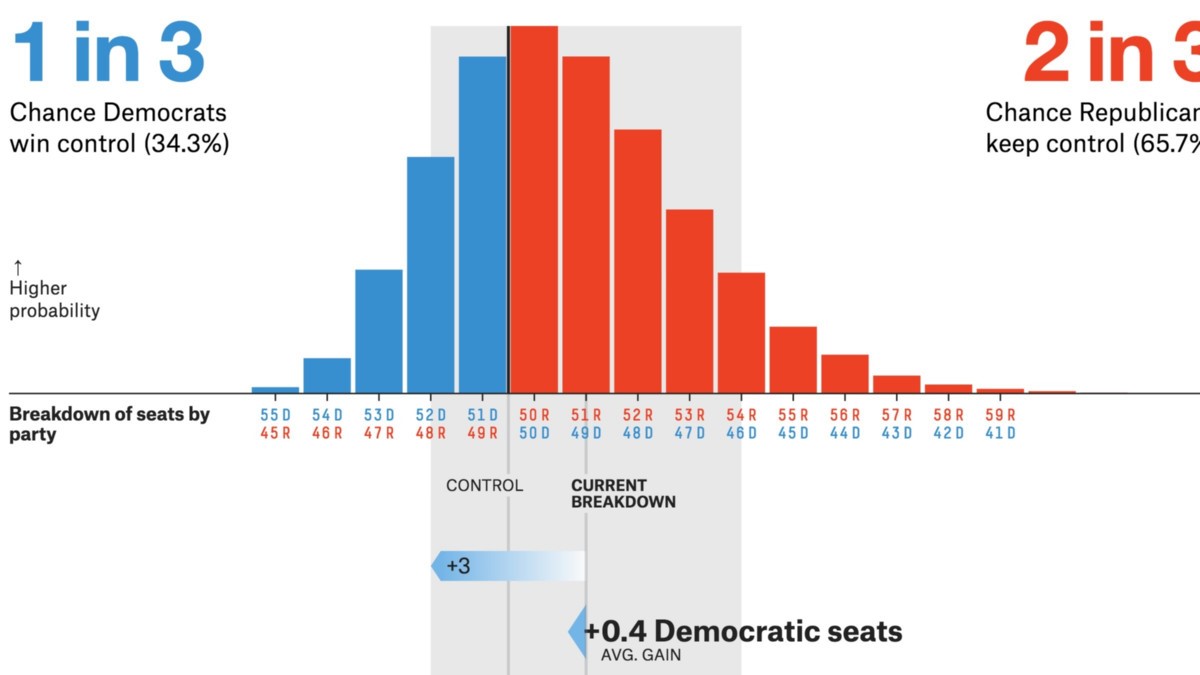
出典:プロジェクト.fivethirtyeight.com
- 政治/選挙の投票は、主要なCLTアプリケーションです。これらの世論調査は、特定の候補者を支持する人々の割合を推定します。これらの結果は、信頼区間のあるニュースチャンネルで見たことがあるかもしれません。中心極限定理は、
- CLTのアプリケーションである信頼区間を使用して、特定の地域の平均家族収入を計算することを計算するのに役立ちます
中心極限定理にはさまざまな分野の多くのアプリケーション。もっと例を考えられますか?記事の下のコメントセクションで知らせてください–ここに含めます。
中心極限定理の背後にある仮定
中心極限定理の実装に飛び込む前に、それはこの手法の背後にある仮定を理解することが重要です。
- データはランダム化条件に従う必要があります。ランダムにサンプリングする必要があります
- サンプルは互いに独立している必要があります。 1つのサンプルが他のサンプルに影響を与えないようにする
- サンプリングを交換せずに行う場合、サンプルサイズは母集団の10%を超えないようにする必要があります
- サンプルサイズは十分に大きくする必要があります。では、このサイズの大きさをどのように判断するのでしょうか。まあ、それは人口に依存します。母集団が歪んでいるか非対称である場合、サンプルサイズは大きくする必要があります。集団が対称である場合、小さなサンプルも抽出できます。
一般に、集団が対称である場合、サンプルサイズは30で十分と見なされます。
サンプル平均の平均は次のように表されます。
µX̄ = µ
ここで、
- µX̄ =サンプル平均の平均
- µ =人口平均
また、サンプル平均の標準偏差は次のように表されます。
σX̄=σ/ sqrt(n)
ここで、
- σX̄=サンプル平均の標準偏差
- σ=母標準偏差
- n =サンプルサイズ
これで、中心極限定理の背後にある概念は終わりです。 RStudioを起動して、CLTの実装を掘り下げましょう!
Rでの中心極限定理の実装
中心極限定理をコーディングする方法を見て興奮しています。 Rで?それでは掘り下げてみましょう。
問題の説明を理解する
パイプ製造組織は、さまざまな種類のパイプを製造しています。特定の種類のパイプの肉厚の月次データが提供されます。ここからデータをダウンロードできます。
組織は、仮説検定を実行し、信頼区間を構築して将来いくつかの戦略を実装することにより、データを分析したいと考えています。課題は、データの分布が正規分布ではないことです。
注:この分析はいくつかの仮定に基づいて機能し、そのうちの1つは、データが正規分布する必要があるということです。
解決策方法論
中心極限定理は、人口が正規ではないこのデータの問題を回避するのに役立ちます。したがって、Rで特定のデータセットの中心極限定理を段階的にシミュレートします。それでは、始めましょう。
CSVデータセットをインポートして検証する
まず、RでCSVファイルをインポートしてから、データが正しいかどうかを検証します。
出力:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
次に、母集団の平均を計算し、データのすべての観測値をプロットします。
出力:
#Calculate the population mean 12.80205
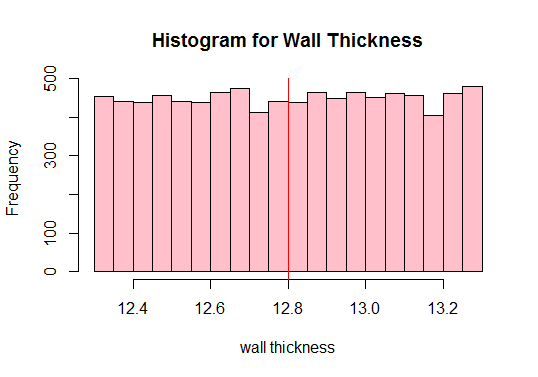
赤を参照上の垂直線?それが人口平均です。上記のプロットから、人口が正規分布ではないこともわかりますよね?したがって、さまざまなサイズの十分なサンプルを抽出し、それらの平均を計算する必要があります(サンプル平均と呼ばれます)。次に、これらのサンプル平均をプロットして正規分布を取得します。
この例では、サイズ10の十分なサンプルを描画し、それらの平均を計算して、Rでプロットします。最小サンプルサイズはわかっています。取得は30である必要がありますが、10を描画するとどうなるかを見てみましょう。
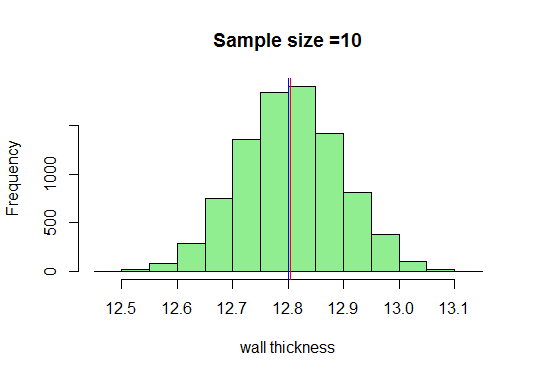
では、サンプルサイズが大きくなると、非常に良いベル型の曲線が得られることがわかっています。ここで、サンプルサイズを増やして、何が得られるかを見てみましょう。
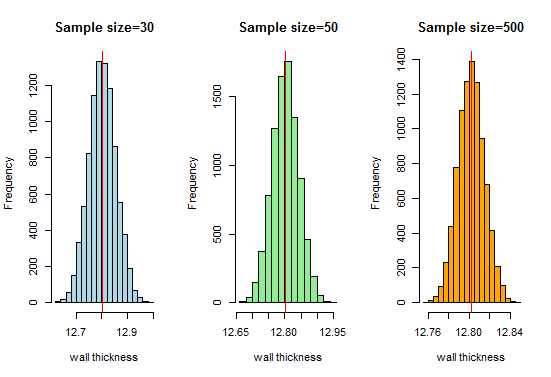
ここで、良好なベル型の曲線であり、サンプルサイズが大きくなると、サンプリング分布は正規分布に近づきます。したがって、サンプリング分布は通常と見なすことができ、パイプ製造組織はこれらの分布を使用してさらに分析することができます。
さまざまなサンプルサイズを取得し、さまざまな数のサンプルを描画することもできます。 それがどのように機能するかを教えてください!
エンドノート
中心極限定理は、統計、ひいてはデータサイエンスにおいて非常に重要な概念です。 データサイエンスに入る前、またはデータサイエンスのインタビューに参加する前に、統計の知識を磨くことがどれほど重要であるかについては、十分に強調することはできません。
データサイエンス入門コースを受講することをお勧めします。 データサイエンスを導入する前に、統計を包括的に調べます。
