Introduzione
Qual è uno dei concetti più importanti e fondamentali di statistiche che ci consente di fare modelli predittivi, eppure spesso confonde gli aspiranti data scientist? Sì, sto parlando del teorema del limite centrale.
È un potente concetto statistico che ogni data scientist DEVE conoscere. Perché è così?
Ebbene, il teorema del limite centrale (CLT) è al centro del test di ipotesi, una componente fondamentale del ciclo di vita della scienza dei dati. Esatto, l’idea che ci permette di esplorare le vaste possibilità dei dati che ci vengono forniti nasce dal CLT. In realtà è una nozione semplice da capire, ma la maggior parte dei data scientist si arrabbia a questa domanda durante le interviste.
Capiremo il concetto of Central Limit Theorem (CLT) in questo articolo. Vedremo perché è importante, dove viene utilizzato e poi impareremo come applicarlo in R.
Ti consiglio di leggere l’articolo seguente se hai bisogno di un rapido aggiornamento sulla distribuzione e sui suoi vari tipi:
- 6 distribuzioni di probabilità comuni che ogni professionista della scienza dei dati dovrebbe conoscere
Sommario
- Cos’è il teorema del limite centrale (CLT )?
- Significato del teorema del limite centrale
- Significato statistico
- Applicazioni pratiche
- Presupposti alla base del Teorema del limite centrale
- Implementazione del teorema del limite centrale in R
Cos’è il teorema del limite centrale (CLT)?
Comprendiamo il limite centrale teorema con l’aiuto di un esempio. Questo ti aiuterà a capire in modo intuitivo come funziona il CLT sottostante.
Considera che ci sono 15 sezioni nel dipartimento di scienze di un’università e ogni sezione ospita circa 100 studenti. Il nostro compito è calcolare il peso medio degli studenti nel dipartimento di scienze. Sembra semplice, vero?
L’approccio che ricevo dagli aspiranti data scientist è semplicemente calcolare la media:
- Innanzitutto, misura i pesi di tutti gli studenti del dipartimento di scienze
- Aggiungi tutti i pesi
- Infine, dividi la somma totale dei pesi con un numero totale di studenti per ottenere la media
Ma cosa succede se la dimensione dei dati è enorme? Questo approccio ha senso? Non proprio: misurare il peso di tutti gli studenti sarà un processo lungo e faticoso. Allora, cosa possiamo fare invece? Diamo un’occhiata a un approccio alternativo.
- Innanzitutto, disegna gruppi di studenti a caso dalla classe. Lo chiameremo campione. Disegneremo più campioni, ciascuno composto da 30 studenti.

Fonte: http://www.123rf.com
- Calcola la media individuale di questi campioni
- Calcola la media di queste medie campione
- Questo valore ci fornirà il peso medio approssimativo degli studenti nel dipartimento di scienze
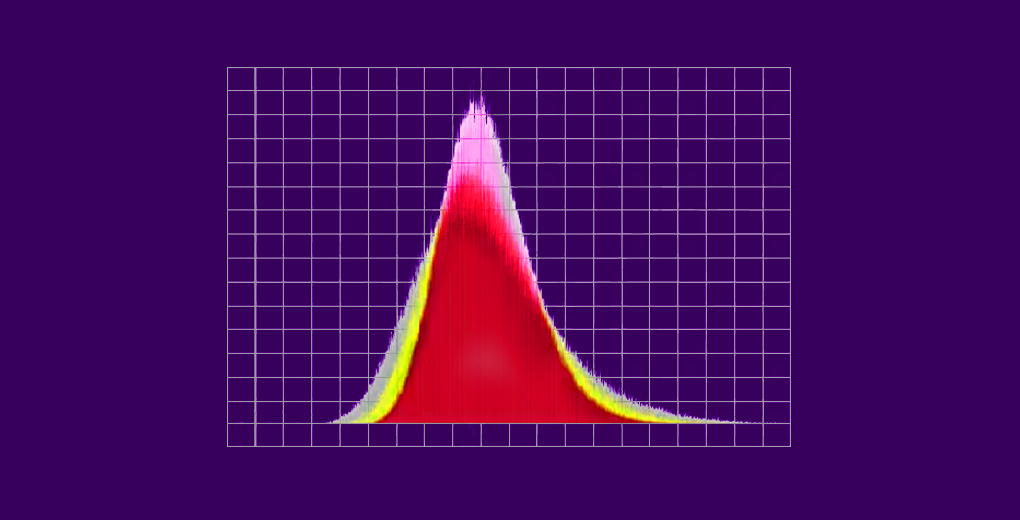
- Inoltre, l’istogramma del peso medio campione degli studenti assomiglierà a una curva a campana (o distribuzione normale)
Questo, in poche parole, è ciò di cui tratta il teorema del limite centrale. Se conduci il tuo apprendimento attraverso i video, dai un’occhiata alla seguente introduzione al teorema del limite centrale. Questo fa parte del modulo di statistica completo nel corso “Introduzione alla scienza dei dati”:
Definizione formale del teorema del limite centrale
Mettiamo una definizione formale di CLT:
Dato un set di dati con distribuzione sconosciuta (potrebbe essere uniforme, binomiale o completamente casuale), le medie del campione approssimeranno la distribuzione normale.
Questi campioni dovrebbero essere di dimensioni sufficienti. La distribuzione delle medie campionarie, calcolate da campionamenti ripetuti, tenderà alla normalità man mano che le dimensioni dei tuoi campioni aumentano.
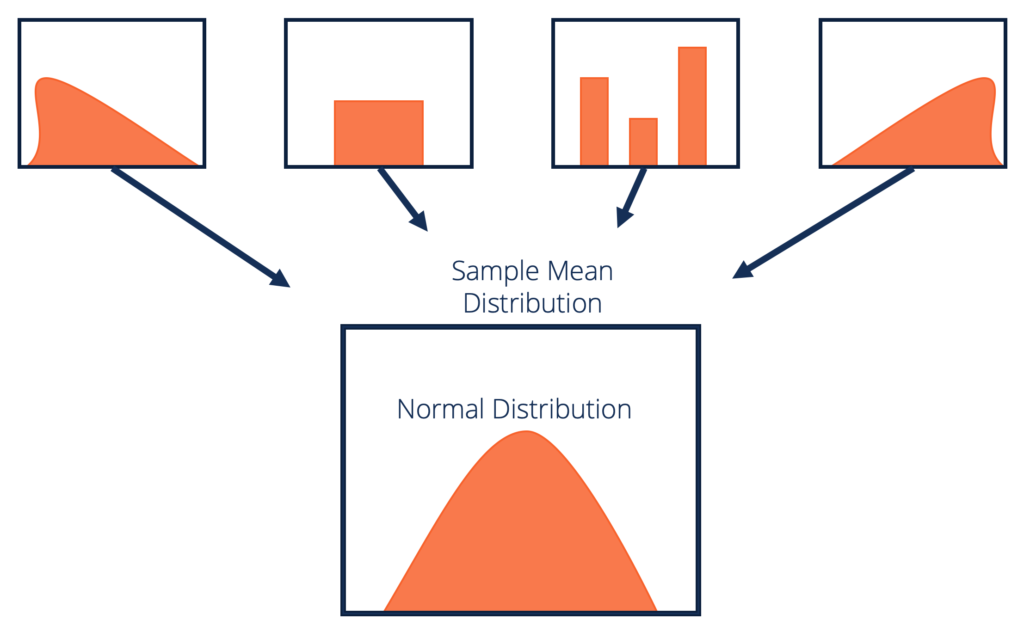
Fonte: corporatefinanceinstitute.com
Il teorema del limite centrale ha un’ampia varietà di applicazioni in molti campi. Vediamoli nella prossima sezione.
Significato del teorema del limite centrale
Il teorema del limite centrale ha sia un significato statistico che applicazioni pratiche . Non è questo il punto debole a cui miriamo quando impariamo un nuovo concetto?
Analizzeremo entrambi gli aspetti per valutare dove possiamo usarli.
Significatività statistica di CLT

Fonte: http://srjcstaff.santarosa.edu
- L’analisi dei dati implica metodi statistici come il test di ipotesi e la costruzione di intervalli di confidenza. Questi metodi presuppongono che la popolazione sia normalmente distribuita.Nel caso di distribuzioni sconosciute o non normali, trattiamo la distribuzione del campionamento come normale secondo il teorema del limite centrale
- Se aumentiamo i campioni estratti dalla popolazione, la deviazione standard delle medie campionarie diminuirà. Questo ci aiuta a stimare la media della popolazione in modo molto più accurato
- Inoltre, la media campionaria può essere utilizzata per creare l’intervallo di valori noto come intervallo di confidenza (che è probabilmente costituito dalla media della popolazione)
Applicazioni pratiche di CLT
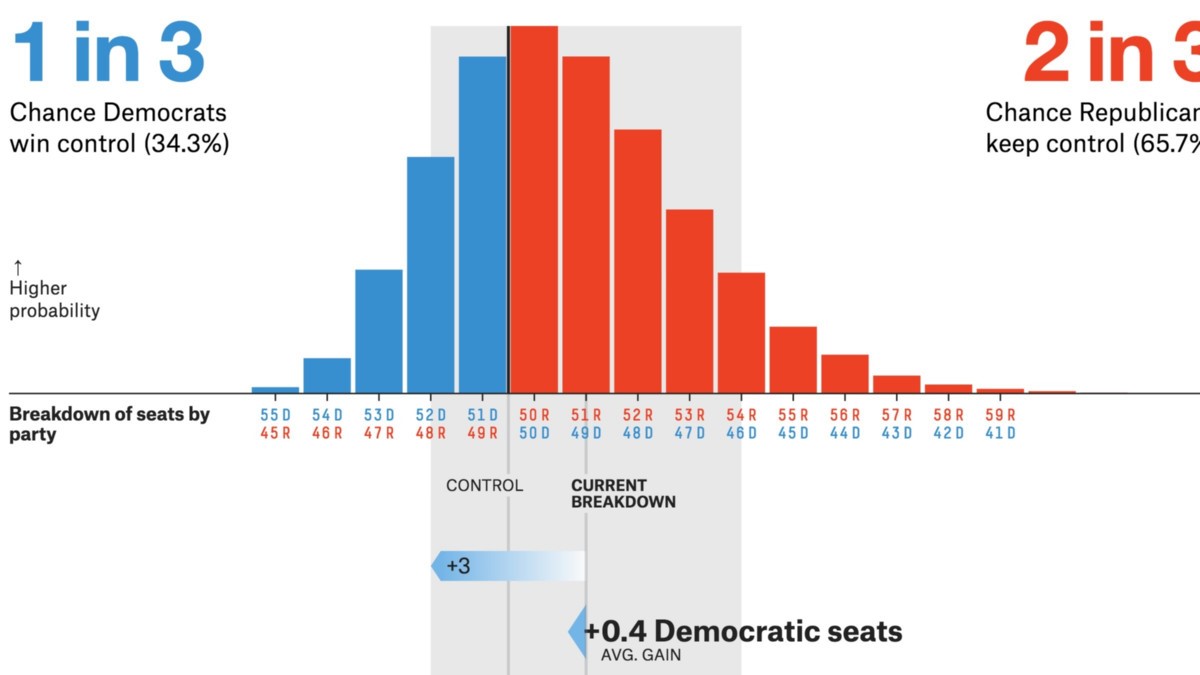
Fonte: progetti .fivethirtyeight.com
- I sondaggi politici / elettorali sono le principali applicazioni CLT. Questi sondaggi stimano la percentuale di persone che supportano un determinato candidato. Potresti aver visto questi risultati sui canali di notizie che vengono forniti con intervalli di confidenza. Il teorema del limite centrale aiuta a calcolare che
- Intervallo di confidenza, un’applicazione del CLT, è usato per calcolare il reddito familiare medio per una particolare regione
Il teorema del limite centrale ha molte applicazioni in diversi campi. Riesci a pensare ad altri esempi? Fammi sapere nella sezione commenti sotto l’articolo: li includerò qui.
Presupposti dietro il teorema del limite centrale
Prima di immergerci nell’implementazione del teorema del limite centrale, è importante per comprendere i presupposti alla base di questa tecnica:
- I dati devono seguire la condizione di randomizzazione. Deve essere campionato in modo casuale
- I campioni devono essere indipendenti l’uno dall’altro. Un campione non dovrebbe influenzare gli altri campioni
- La dimensione del campione non dovrebbe essere superiore al 10% della popolazione quando il campionamento viene eseguito senza sostituzione
- La dimensione del campione dovrebbe essere sufficientemente grande. Ora, come faremo a capire quanto dovrebbe essere grande questa dimensione? Ebbene, dipende dalla popolazione. Quando la popolazione è distorta o asimmetrica, la dimensione del campione dovrebbe essere grande. Se la popolazione è simmetrica, possiamo disegnare anche piccoli campioni
In generale, una dimensione del campione di 30 è considerata sufficiente quando la popolazione è simmetrica.
la media delle medie del campione è indicata come:
µ X̄ = µ
dove,
- µ X̄ = Media della media del campione
- µ = Media della popolazione
E la deviazione standard della media del campione è indicata come:
σ X̄ = σ / sqrt (n)
dove,
- σ X̄ = Deviazione standard della media campionaria
- σ = Deviazione standard della popolazione
- n = dimensione del campione
E questo è tutto per il concetto alla base del teorema del limite centrale. È ora di avviare RStudio e approfondire l’implementazione di CLT!
Implementazione del teorema del limite centrale in R
Entusiasta di vedere come possiamo codificare il teorema del limite centrale in R? Andiamo ora a fondo.
Comprensione della dichiarazione del problema
Un’organizzazione di produzione di tubi produce diversi tipi di tubi. Ci vengono forniti i dati mensili dello spessore delle pareti di alcuni tipi di tubi. È possibile scaricare i dati qui.
L’organizzazione desidera analizzare i dati eseguendo test di ipotesi e costruendo intervalli di confidenza per implementare alcune strategie in futuro. La sfida è che la distribuzione dei dati non è normale.
Nota: questa analisi funziona su alcuni presupposti e uno di questi è che i dati dovrebbero essere distribuiti normalmente.
Soluzione Metodologia
Il teorema del limite centrale ci aiuterà ad aggirare il problema di questi dati in cui la popolazione non è normale. Pertanto, simuleremo il teorema del limite centrale sul dataset dato in R passo dopo passo. Quindi, iniziamo.
Importa il set di dati CSV e convalidalo
Per prima cosa, importa il file CSV in R e poi convalida i dati per la correttezza:
Risultato:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
Successivamente, calcola la media della popolazione e traccia tutte le osservazioni dei dati:
Risultato:
#Calculate the population mean 12.80205
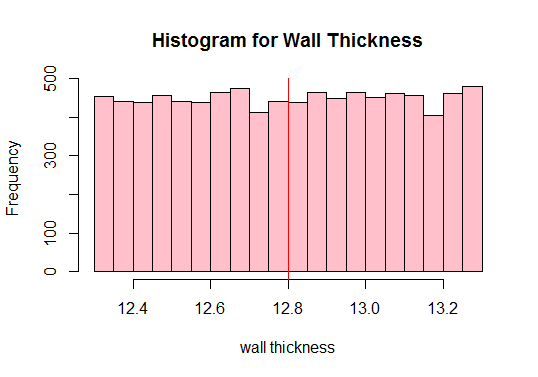
Vedi il rosso linea verticale sopra? Questa è la media della popolazione. Possiamo anche vedere dalla trama sopra che la popolazione non è normale, giusto? Pertanto, dobbiamo disegnare un numero sufficiente di campioni di dimensioni diverse e calcolare le loro medie (note come medie campionarie). Tracciamo quindi le medie campionarie per ottenere una distribuzione normale.
Nel nostro esempio, disegneremo campioni sufficienti di dimensione 10, calcoleremo le loro medie e le rappresenteremo in R. So che la dimensione minima del campione preso dovrebbe essere 30 ma vediamo cosa succede quando disegniamo 10:
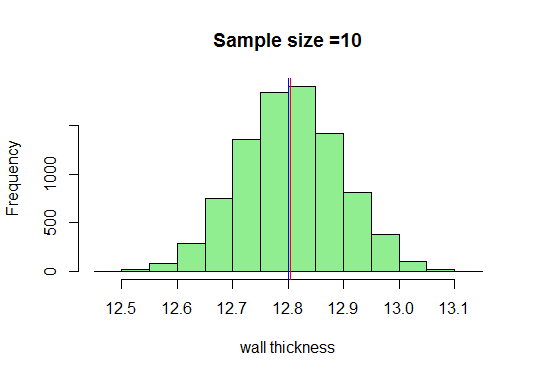
Ora, sappiamo che otterremo una curva a campana molto bella all’aumentare delle dimensioni del campione. Aumentiamo ora la dimensione del campione e vediamo cosa otteniamo:
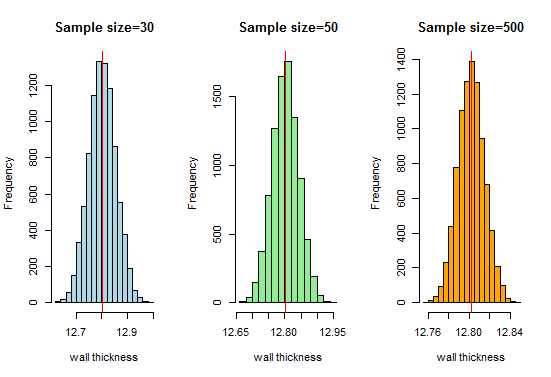
Qui otteniamo una buona curva a campana e la distribuzione del campionamento si avvicina alla distribuzione normale all’aumentare delle dimensioni del campione.Pertanto, possiamo considerare le distribuzioni di campionamento come normali e l’organizzazione di produzione dei tubi può utilizzare queste distribuzioni per ulteriori analisi.
Puoi anche giocare prendendo diverse dimensioni del campione e disegnando un diverso numero di campioni. Fammi sapere come funziona per te!
Note finali
Il teorema del limite centrale è un concetto abbastanza importante nella statistica e di conseguenza nella scienza dei dati. Non posso sottolineare abbastanza quanto sia fondamentale rispolverare le tue conoscenze statistiche prima di entrare nella scienza dei dati o addirittura sederti per un colloquio di scienza dei dati.
Consiglio di seguire il corso di Introduzione alla scienza dei dati: è analisi completa delle statistiche prima di introdurre la scienza dei dati.
