Inledning
Vad är ett av de viktigaste och centrala begreppen av statistik som gör det möjligt för oss att göra prediktiv modellering, och ändå förvirrar det ofta blivande datavetare? Ja, jag pratar om den centrala gränssatsen.
Det är ett kraftfullt statistiskt koncept som alla datavetare MÅSTE veta. Varför är det nu?
Nåväl, den centrala gränssatsen (CLT) är kärnan i hypotesprovningen – en kritisk komponent i datavetenskapens livscykel. Det stämmer, idén som låter oss utforska de stora möjligheterna med den data vi får kommer från CLT. Det är faktiskt ett enkelt begrepp att förstå, men de flesta dataforskare skrubbar över den här frågan under intervjuer.
Vi kommer att förstå konceptet av Central Limit Theorem (CLT) i denna artikel. Vi får se varför det är viktigt, var det används och sedan lära oss hur man använder det i R.
Jag rekommenderar att du går igenom artikeln nedan om du behöver en snabb uppdatering av distributionen och dess olika typer:
- 6 Vanliga sannolikhetsfördelningar som alla datavetenskapsmän borde veta
Innehållsförteckning
- Vad är den centrala gränssatsen (CLT )?
- Betydelsen av den centrala gränssatsen
- Statistisk betydelse
- Praktiska tillämpningar
- Antaganden bakom Central Limit Theorem
- Implementering av the Central Limit Theorem in R
Vad är Central Limit Theorem (CLT)?
Låt oss förstå den centrala gränsen sats med hjälp av ett exempel. Detta hjälper dig att intuitivt förstå hur CLT fungerar under.
Tänk på att det finns 15 sektioner i universitetets naturvetenskapliga avdelning och varje sektion är värd för cirka 100 studenter. Vår uppgift är att beräkna genomsnittsvikten för studenter på naturvetenskapliga avdelningen. Låter enkelt, eller hur?
Det tillvägagångssätt som jag får från blivande datavetare är att helt enkelt beräkna genomsnittet:
- Mät först vikterna hos alla studenter på vetenskapsavdelningen
- Lägg till alla vikter
- Slutligen delar du den totala vikten med ett totalt antal elever för att få genomsnittet
Men vad händer om är storleken på uppgifterna enorma? Är detta tillvägagångssätt vettigt? Inte riktigt – att mäta vikten på alla elever blir en mycket tröttsam och lång process. Så, vad kan vi göra istället? Låt oss titta på ett alternativt tillvägagångssätt.
- Rita först grupper av elever slumpmässigt från klassen. Vi kommer att kalla detta ett exempel. Vi ritar flera prover, som alla består av 30 elever.

Källa: http://www.123rf.com
- Beräkna det enskilda medelvärdet för dessa prover
- Beräkna medelvärdet för dessa provmedel
- Detta värde ger oss ungefärlig medelvikt för studenterna på naturvetenskapliga avdelningen
- Dessutom kommer histogrammet för provets medelvikt för studenter att likna en klockkurva (eller normalfördelning)
Detta, i ett nötskal, är vad den centrala gränssatsen handlar om. Om du läser igenom videor, kolla in nedanstående introduktion till den centrala gränssatsen. Detta är en del av den omfattande statistikmodulen i kursen ’Introduktion till datavetenskap’:
Definition av den centrala gränssatsen formellt
Låt oss lägga en formell definition på CLT:
Med tanke på en dataset med okänd fördelning (den kan vara enhetlig, binomiell eller helt slumpmässig) kommer exemplet att approximera normalfördelningen.
Dessa prover bör vara tillräckliga i storlek. Fördelningen av provmedel, beräknad från upprepad provtagning, tenderar att vara normal när storleken på dina prover blir större.
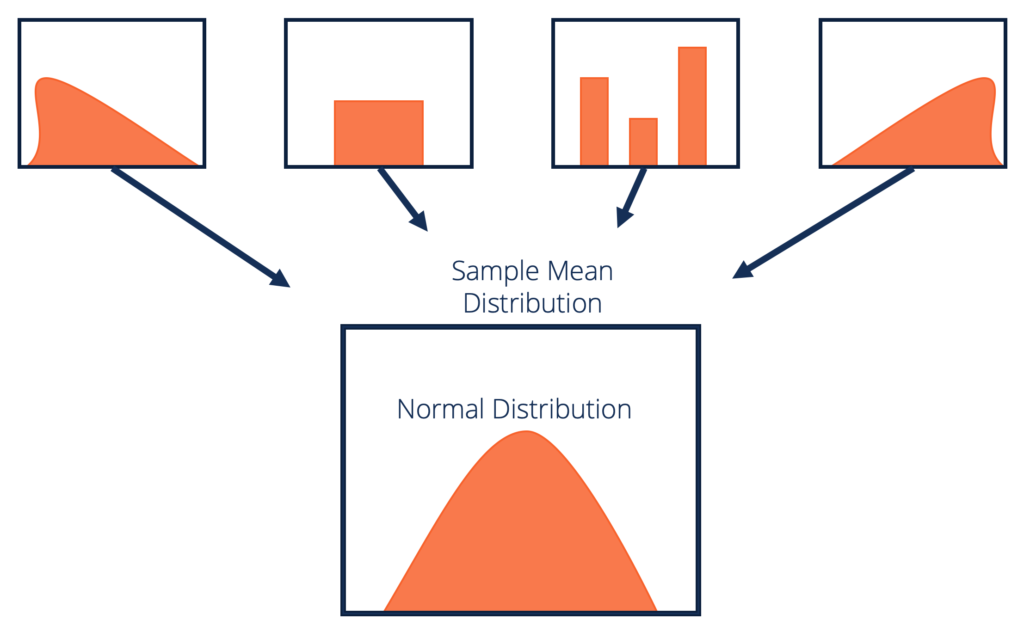
Källa: corporatefinanceinstitute.com
Den centrala gränssatsen har en mängd olika applikationer inom många områden. Låt oss titta på dem i nästa avsnitt.
Betydelsen av den centrala gränssatsen
Den centrala gränssatsen har både statistisk signifikans och praktiska tillämpningar . Är det inte den söta platsen vi siktar på när vi lär oss ett nytt koncept?
Vi kommer att titta på båda aspekterna för att mäta var vi kan använda dem.
Statistisk betydelse av CLT

Källa: http://srjcstaff.santarosa.edu
- Analys av data innefattar statistiska metoder som hypotesprovning och konstruktion av konfidensintervall. Dessa metoder förutsätter att befolkningen är normalt fördelad.I fallet med okända eller icke-normala fördelningar behandlar vi provtagningsfördelningen som normal enligt den centrala gränssatsen
- Om vi ökar proverna från befolkningen kommer standardavvikelsen för provmedlen att minska. Detta hjälper oss att uppskatta populationens medelvärde mycket mer exakt
- Dessutom kan provets medelvärde användas för att skapa ett intervall av värden som kallas ett konfidensintervall (som sannolikt kommer att bestå av populationsmedelvärdet)
Praktiska tillämpningar av CLT
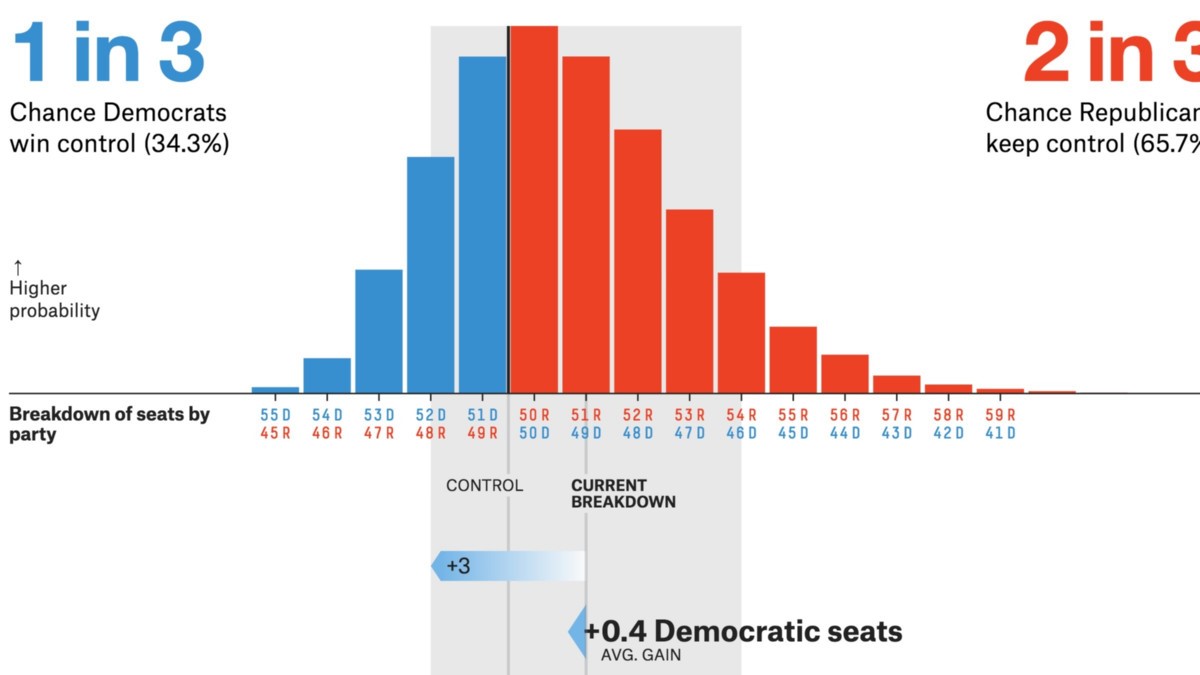
Källa: projekt .fivethirtyeight.com
- Politiska val / omröstningar är främsta CLT-ansökningar. Dessa enkäter uppskattar andelen personer som stöder en viss kandidat. Du kanske har sett dessa resultat på nyhetskanaler som kommer med konfidensintervall. Den centrala gränssatsen hjälper till att beräkna att
- Konfidensintervall, en tillämpning av CLT, används för att beräkna den genomsnittliga familjeinkomsten för en viss region
Den centrala gränssatsen har många applikationer inom olika områden. Kan du komma på fler exempel? Låt mig veta i kommentarfältet nedanför artikeln – jag kommer att inkludera dem här.
Antaganden bakom den centrala gränssatsen
Innan vi dyker in i implementeringen av den centrala gränssatsen är det viktigt för att förstå antagandena bakom denna teknik:
- Uppgifterna måste följa slumpmässiga villkor. Det måste samplas slumpmässigt
- Proverna ska vara oberoende av varandra. Ett prov ska inte påverka de andra proverna
- Provstorleken bör inte vara mer än 10% av populationen när provtagningen görs utan att ersätta den
- Provstorleken bör vara tillräckligt stor. Hur ska vi ta reda på hur stor den här storleken ska vara? Det beror på befolkningen. När populationen är skev eller asymmetrisk bör provstorleken vara stor. Om populationen är symmetrisk kan vi också rita små prover.
I allmänhet anses en provstorlek på 30 vara tillräcklig när populationen är symmetrisk.
medelvärdet för provmedlet betecknas som:
µ X̄ = µ
där,
- µ X̄ = Medelvärdet för provet betyder
- µ = populationsmedelvärde
Och standardavvikelsen för provmedlet betecknas som:
σ X̄ = σ / sqrt (n)
där,
- σ X̄ = Standardavvikelse för provets medelvärde
- σ = Befolkningsstandardavvikelse
- n = provstorlek
Och det är det för konceptet bakom centralt gränssats. Dags att skjuta upp RStudio och gräva i CLT: s implementering!
Implementering av den centrala gränssatsen i R
Glada att se hur vi kan koda den centrala gränssatsen i R? Låt oss gräva in det då.
Förstå problemförklaringen
En rörtillverkningsorganisation producerar olika typer av rör. Vi får månadsdata om väggtjockleken för vissa typer av rör. Du kan ladda ner data här.
Organisationen vill analysera data genom att utföra hypotesprovning och konstruera konfidensintervall för att implementera några strategier i framtiden. Utmaningen är att distributionen av data inte är normal.
Obs: Denna analys fungerar på några antaganden och en av dem är att data ska normalt distribueras.
Lösning Metod
Den centrala gränssatsen hjälper oss att komma runt problemet med dessa data där befolkningen inte är normal. Därför simulerar vi den centrala gränssatsen på den angivna datamängden i R steg för steg. Så, låt oss komma igång.
Importera CSV-datauppsättningen och validera den
Importera först CSV-filen i R och validera sedan data för korrekthet:
Output:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
Beräkna sedan befolkningens medelvärde och plotta alla observationer av data:
Utgång:
#Calculate the population mean 12.80205
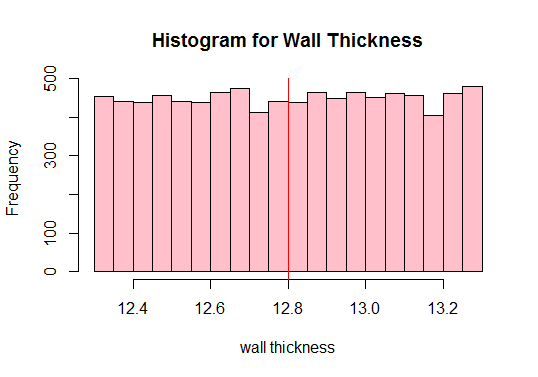
Se den röda vertikal linje ovanför? Det är befolkningens medelvärde. Vi kan också se från ovanstående plot att befolkningen inte är normal, eller hur? Därför måste vi rita tillräckligt med prover i olika storlekar och beräkna deras medel (så kallade provmedel). Vi plottar sedan dessa provmedel för att få en normalfördelning.
I vårt exempel ritar vi tillräckligt med prover av storlek 10, beräknar deras medel och plottar dem i R. Jag vet att minsta provstorlek taget ska vara 30 men låt oss bara se vad som händer när vi ritar 10:
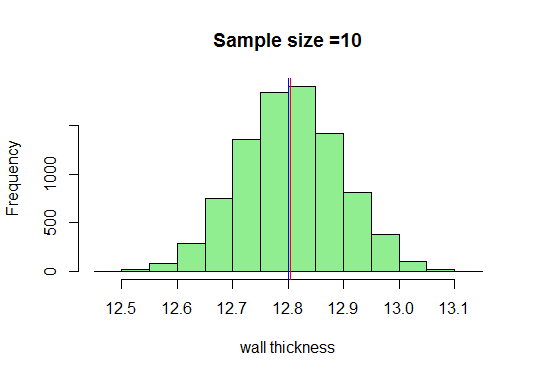
Nu, vi vet att vi får en mycket fin klockformad kurva när provstorlekarna ökar. Låt oss nu öka vår provstorlek och se vad vi får:
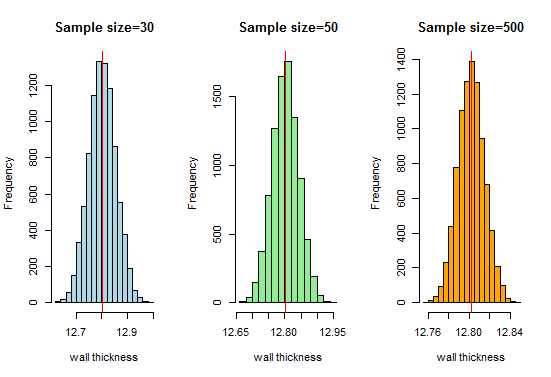
Här får vi en bra klockformad kurva och provfördelningen närmar sig normalfördelningen när provstorlekarna ökar.Därför kan vi betrakta samplingsfördelningarna som vanliga och rörtillverkningsorganisationen kan använda dessa fördelningar för vidare analys.
Du kan också spela genom att ta olika provstorlekar och rita ett annat antal prover. Låt mig veta hur det fungerar för dig!
Slutanmärkningar
Centralgränssats är ett ganska viktigt begrepp inom statistik och därmed datavetenskap. Jag kan inte betona tillräckligt för hur kritiskt det är att du förstärker din statistikkunskap innan du går in i datavetenskap eller till och med sitter på en datavetenskapsintervju.
Jag rekommenderar att du tar kursen Inledning till datavetenskap – det är omfattande titt på statistik innan datavetenskap införs.
