소개
가장 중요하고 핵심 개념 중 하나는 무엇입니까? 우리가 예측 모델링을 할 수있게 해주면서도 데이터 과학자를 헷갈 리게하는 통계가 많습니까? 예, 저는 중심 한계 정리에 대해 이야기하고 있습니다.
모든 데이터 과학자가 반드시 알아야하는 강력한 통계 개념입니다. 그 이유는 무엇입니까?
글쎄요, 중앙 한계 정리 (CLT)는 데이터 과학 라이프 사이클의 중요한 구성 요소 인 가설 테스트의 핵심입니다. 맞습니다. 우리에게 주어진 데이터의 방대한 가능성을 탐색 할 수있는 아이디어는 CLT에서 비롯되었습니다. 실제로 이해하는 것은 단순한 개념이지만 대부분의 데이터 과학자는 인터뷰 중에이 질문에 허덕이고 있습니다.
이해할 개념입니다. 이 기사의 CLT (Central Limit Theorem)의. 왜 중요한지, 어디에 사용되는지 살펴본 다음 R에서 적용하는 방법을 배웁니다.
배포 및 다양한 유형에 대한 간단한 복습이 필요한 경우 아래 기사를 살펴 보는 것이 좋습니다.
- 모든 데이터 과학 전문가가 알아야 할 6 가지 공통 확률 분포
목차
- CLT (Central Limit Theorem) 란? )?
- 중앙 극한 정리의 중요성
- 통계적 의미
- 실제 적용
- Central Limit Theorem
- R에서 Central Limit Theorem 구현
CLT (Central Limit Theorem) 란 무엇입니까?
중심 한계를 이해합시다. 예제의 도움으로 정리. 이렇게하면 CLT가 어떻게 작동하는지 직관적으로 파악할 수 있습니다.
대학의 과학 부서에는 15 개의 섹션이 있으며 각 섹션에는 약 100 명의 학생이 있습니다. 우리의 임무는 과학 부서의 학생들의 평균 체중을 계산하는 것입니다. 간단하게 들리 죠?
데이터 과학자를 꿈꾸는 사람들로부터 얻은 접근 방식은 단순히 평균을 계산하는 것입니다.
- 먼저, 과학 부서에있는 모든 학생의 가중치를 측정합니다.
- 모든 가중치 더하기
- 마지막으로 총 가중치 합계를 총 학생 수로 나누어 평균을 구합니다.
하지만 데이터의 크기가 엄청나 다? 이 접근 방식이 의미가 있습니까? 실제로는 아닙니다. 모든 학생들의 체중을 측정하는 것은 매우 지루하고 긴 과정이 될 것입니다. 그래서 우리는 대신 무엇을 할 수 있습니까? 다른 접근 방식을 살펴 보겠습니다.
- 먼저, 반에서 무작위로 학생 그룹을 그립니다. 이것을 샘플이라고 부를 것입니다. 각각 30 명의 학생으로 구성된 여러 개의 샘플을 그릴 것입니다.

출처 : http://www.123rf.com
- 이 샘플의 개별 평균 계산
- 이 샘플 평균의 평균 계산
- 이 값은 과학 부서에있는 학생들의 대략적인 평균 체중을 제공합니다.
- 또한 학생들의 표본 평균 체중의 히스토그램은 종 곡선 (또는 정규 분포)과 유사합니다.
간단히 말해서 이것이 중심 극한 정리의 전부입니다. 비디오를 통해 학습 한 경우 아래의 중심 극한 정리 소개를 확인하십시오. 이것은 ‘데이터 과학 입문’과정의 포괄적 인 통계 모듈의 일부입니다.
중앙 한계 정리를 공식적으로 정의
CLT에 공식적인 정의를 입력하겠습니다.
분포를 알 수없는 데이터 세트 (균일, 이항 또는 완전 무작위 일 수 있음)가 주어지면 표본 평균은 정규 분포에 가깝습니다.
이 샘플은 크기가 충분해야합니다. 반복 샘플링에서 계산 된 표본 평균 분포는 표본 크기가 커질수록 정규화되는 경향이 있습니다.
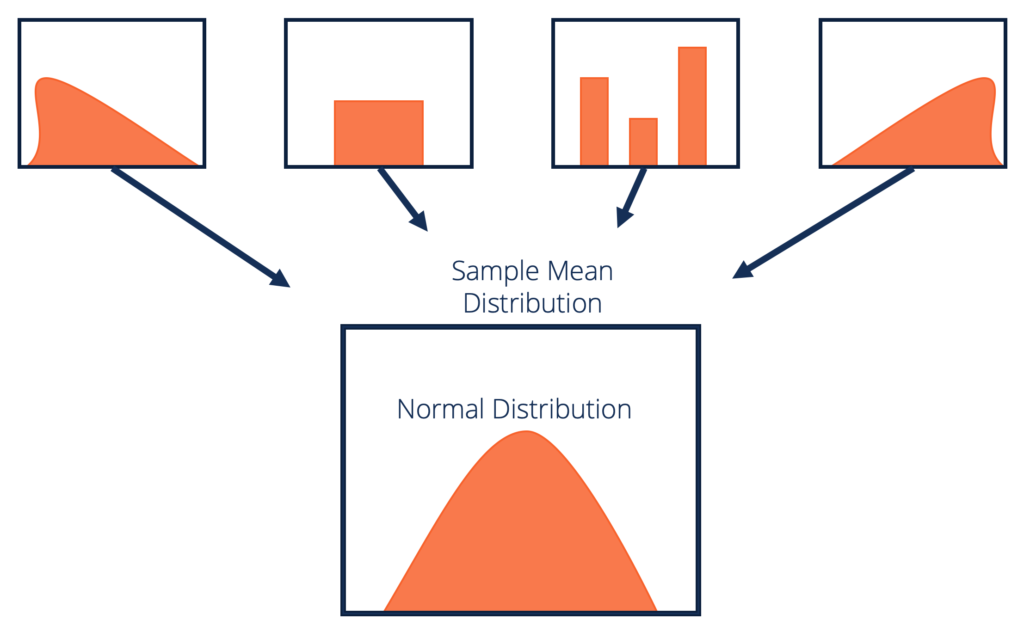
출처 : corporatefinanceinstitute.com
중앙 한계 정리는 여러 분야에서 다양한 응용 분야를 가지고 있습니다. 다음 섹션에서 살펴 보겠습니다.
중심 한계 정리의 중요성
중심 한계 정리는 통계적 유의성과 실제 적용을 모두 가지고 있습니다. . 이것이 우리가 새로운 개념을 배울 때 목표로하는 최적의 지점이 아닙니까?
두 측면을 모두 살펴보고 사용할 수있는 위치를 측정하겠습니다.
통계적 중요성 of CLT

출처 : http://srjcstaff.santarosa.edu
- 데이터 분석에는 가설 테스트 및 신뢰 구간 구성과 같은 통계 방법이 포함됩니다. 이 방법은 모집단이 정규 분포를 따른다고 가정합니다.알 수 없거나 비정규 분포의 경우 중앙 한계 정리에 따라 표본 분포를 정규 분포로 취급합니다.
- 모집단에서 추출한 표본을 늘리면 표본 평균의 표준 편차가 감소합니다. 이렇게하면 모집단 평균을 훨씬 더 정확하게 추정하는 데 도움이됩니다.
- 또한 표본 평균을 사용하여 신뢰 구간 (모집단 평균으로 구성 될 가능성이 높은 값)이라는 값 범위를 생성 할 수 있습니다.
CLT의 실제 적용
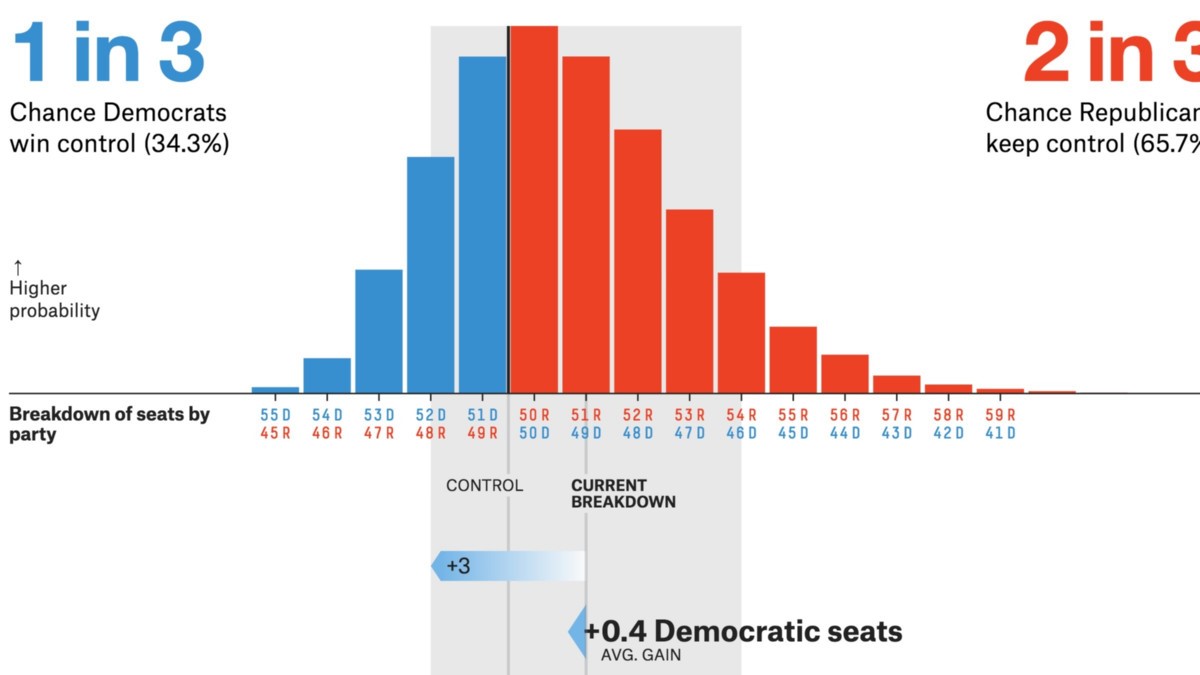
출처 : 프로젝트 .fivethirtyeight.com
- 정치 / 선거 투표는 주요 CLT 응용 프로그램입니다. 이 설문 조사는 특정 후보를지지하는 사람들의 비율을 추정합니다. 신뢰 구간이있는 뉴스 채널에서 이러한 결과를 보았을 것입니다. 중앙 한계 정리는 다음을 계산하는 데 도움이됩니다.
- CLT를 적용한 신뢰 구간은 특정 지역의 평균 가족 소득을 계산하는 데 사용됩니다.
중앙 한계 정리는 다른 분야의 많은 응용. 더 많은 예를 생각할 수 있습니까? 기사 아래 댓글 섹션에서 알려주세요. 여기에 포함하겠습니다.
중앙 한계 정리 뒤에있는 가정
중앙 한계 정리의 구현에 대해 알아보기 전에 이 기술의 가정을 이해하는 것이 중요합니다.
- 데이터는 무작위 조건을 따라야합니다. 무작위로 샘플링해야합니다.
- 샘플은 서로 독립적이어야합니다. 한 샘플이 다른 샘플에 영향을주지 않아야합니다.
- 대체하지 않고 샘플링을 수행 할 때 샘플 크기는 모집단의 10 %를 넘지 않아야합니다.
- 샘플 크기는 충분히 커야합니다. 이제이 크기가 얼마나 커야하는지 어떻게 알 수 있을까요? 음, 인구에 따라 다릅니다. 모집단이 치우쳐 있거나 비대칭이면 표본 크기가 커야합니다. 모집단이 대칭이면 작은 표본도 그릴 수 있습니다.
일반적으로 모집단이 대칭 일 때 표본 크기 30이면 충분하다고 간주됩니다.
샘플 평균의 평균은 다음과 같이 표시됩니다.
µ X̄ = µ
여기서
- µ X̄ = 표본 평균의 평균
- µ = 모집단 평균
그리고 표본 평균의 표준 편차는 다음과 같이 표시됩니다.
σ X̄ = σ / sqrt (n)
여기서
- σ X̄ = 표본 평균의 표준 편차
- σ = 모집단 표준 편차
- n = 표본 크기
중심 극한 정리 뒤에있는 개념에 대한 것입니다. RStudio를 시작하고 CLT의 구현을 살펴볼 시간입니다!
R에서 중앙 한계 정리 구현
중앙 한계 정리를 코딩하는 방법을보고 기쁩니다. R에서? 그럼 자세히 살펴 보겠습니다.
문제 설명 이해
파이프 제조 조직은 다양한 종류의 파이프를 생산합니다. 특정 유형의 파이프 벽 두께에 대한 월별 데이터가 제공됩니다. 여기에서 데이터를 다운로드 할 수 있습니다.
조직은 향후 몇 가지 전략을 구현하기 위해 가설 테스트를 수행하고 신뢰 구간을 구성하여 데이터를 분석하려고합니다. 문제는 데이터의 분포가 정상적이지 않다는 것입니다.
참고 :이 분석은 몇 가지 가정에서 작동하며 그중 하나는 데이터가 정규 분포되어야한다는 것입니다.
해결책 방법론
중앙 극한 정리는 인구가 정상이 아닌이 데이터의 문제를 해결하는 데 도움이됩니다. 따라서 R의 주어진 데이터 세트에 대한 중심 한계 정리를 단계별로 시뮬레이션합니다. 이제 시작하겠습니다.
CSV 데이터 세트 가져 오기 및 유효성 검사
먼저 R에서 CSV 파일을 가져온 다음 데이터의 정확성을 확인합니다.
출력 :
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
다음으로 모집단 평균을 계산하고 데이터의 모든 관측치를 플로팅합니다.
출력 :
#Calculate the population mean 12.80205
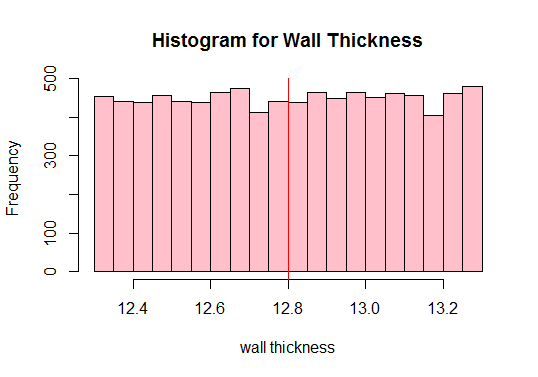
빨간색보기 위에 수직선? 이것이 인구 평균입니다. 위의 그림에서 인구가 정상이 아니라는 것도 알 수 있습니다. 따라서 크기가 다른 충분한 표본을 추출하고 평균 (표본 평균이라고 함)을 계산해야합니다. 그런 다음 해당 표본 평균을 플로팅하여 정규 분포를 얻습니다.
이 예에서는 크기가 10 인 표본을 충분히 추출하고 평균을 계산 한 다음 R로 플로팅합니다. 최소 표본 크기는 taken은 30이어야하지만 10을 그릴 때 어떤 일이 일어나는지 보겠습니다.
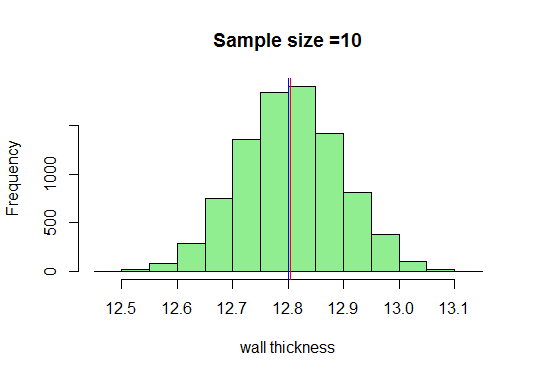
자, 샘플 크기가 증가함에 따라 매우 멋진 종 모양의 곡선을 얻을 수 있다는 것을 알고 있습니다. 이제 샘플 크기를 늘리고 결과를 살펴 보겠습니다.
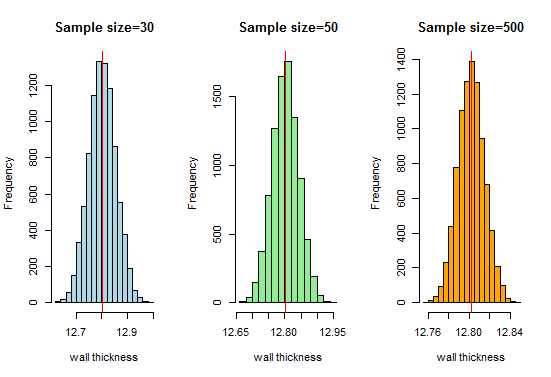
여기에서 좋은 종 모양의 곡선과 표본 크기가 증가함에 따라 표본 분포는 정규 분포에 접근합니다.따라서 우리는 샘플링 분포를 정상으로 간주 할 수 있으며 파이프 제조 조직은 이러한 분포를 추가 분석에 사용할 수 있습니다.
또한 다른 샘플 크기를 취하고 다른 수의 샘플을 그려서 놀 수 있습니다. 어떻게 작동하는지 알려주세요!
최종 노트
중심 극한 정리는 통계에서 매우 중요한 개념이며 결과적으로 데이터 과학입니다. 데이터 과학에 들어가거나 심지어 데이터 과학 인터뷰에 참석하기 전에 통계 지식을 다듬는 것이 얼마나 중요한지에 대해 충분히 강조 할 수는 없습니다.
데이터 과학 입문 과정을 수강하는 것이 좋습니다. 데이터 과학을 도입하기 전에 통계를 종합적으로 살펴 봅니다.
