Wprowadzenie
Co jest jednym z najważniejszych i podstawowych pojęć statystyk, które umożliwiają nam modelowanie predykcyjne, a mimo to często dezorientują początkujących naukowców zajmujących się danymi? Tak, mówię o centralnym twierdzeniu granicznym.
Jest to potężne pojęcie statystyczne, które każdy analityk danych MUSI znać. Dlaczego tak jest?
Cóż, centralne twierdzenie graniczne (CLT) jest sercem testowania hipotez – krytycznym składnikiem cyklu życia nauki o danych. Zgadza się, pomysł, który pozwala nam zbadać ogromne możliwości danych, które otrzymujemy, pochodzi z CLT. Właściwie to proste pojęcie do zrozumienia, ale większość analityków danych zastanawia się nad tym pytaniem podczas wywiadów.
Zrozumiemy tę koncepcję Centralnego Twierdzenia Granicznego (CLT) w tym artykule. Zobaczymy, dlaczego jest to ważne, gdzie jest używane, a następnie dowiemy się, jak zastosować go w R.
Polecam przejrzenie poniższego artykułu, jeśli potrzebujesz szybkiego przypomnienia sobie o dystrybucji i jej różnych typach:
- 6 powszechnych rozkładów prawdopodobieństwa, który powinien znać każdy specjalista ds. danych
Spis treści
- Co to jest centralne twierdzenie graniczne (CLT )?
- Znaczenie centralnego twierdzenia granicznego
- Istotność statystyczna
- Praktyczne zastosowania
- Założenia leżące u podstaw Centralne twierdzenie graniczne
- Implementacja centralnego twierdzenia granicznego w R
Co to jest centralne twierdzenie graniczne (CLT)?
Rozumiemy centralną granicę twierdzenie na przykładzie. Pomoże ci to intuicyjnie zrozumieć, jak działa CLT pod spodem.
Weź pod uwagę, że na wydziale nauk ścisłych uniwersytetu jest 15 sekcji, a każda sekcja ma około 100 studentów. Naszym zadaniem jest obliczenie średniej wagi studentów na wydziale ścisłym. Brzmi prosto, prawda?
Podejście, które otrzymuję od początkujących naukowców zajmujących się danymi, polega po prostu na obliczeniu średniej:
- Najpierw zmierz wagę wszystkich studentów na wydziale nauk ścisłych
- Dodaj wszystkie wagi
- Na koniec podziel całkowitą sumę wag przez całkowitą liczbę uczniów, aby otrzymać średnią
Ale co, jeśli rozmiar danych jest ogromny? Czy takie podejście ma sens? Niezupełnie – mierzenie wagi wszystkich uczniów będzie bardzo męczącym i długim procesem. Więc co możemy zamiast tego zrobić? Przyjrzyjmy się alternatywnemu podejściu.
- Najpierw losuj grupy uczniów z klasy. Nazwiemy to próbką. Narysujemy wiele próbek, każda składająca się z 30 uczniów.

Źródło: http://www.123rf.com
- Oblicz średnią dla tych próbek
- Oblicz średnią tych próbek
- Ta wartość da nam przybliżoną średnią wagę uczniów na wydziale nauk ścisłych
- Dodatkowo histogram przykładowej średniej wagi uczniów będzie przypominał krzywą dzwonową (lub rozkład normalny)
Krótko mówiąc, na tym właśnie polega centralne twierdzenie graniczne. Jeśli uczysz się za pomocą filmów, zapoznaj się z poniższym wprowadzeniem do centralnego twierdzenia granicznego. Jest to część obszernego modułu statystycznego w kursie „Wprowadzenie do nauki o danych”:
Formalne definiowanie centralnego twierdzenia granicznego
Dodajmy formalną definicję do CLT:
Biorąc pod uwagę zbiór danych o nieznanym rozkładzie (może być jednorodny, dwumianowy lub całkowicie losowy), średnie z próby będą przybliżone do rozkładu normalnego.
Te próbki powinny mieć wystarczającą wielkość. Rozkład średnich z próby, obliczony na podstawie wielokrotnego próbkowania, będzie wyglądał normalnie wraz ze wzrostem rozmiaru próbek.
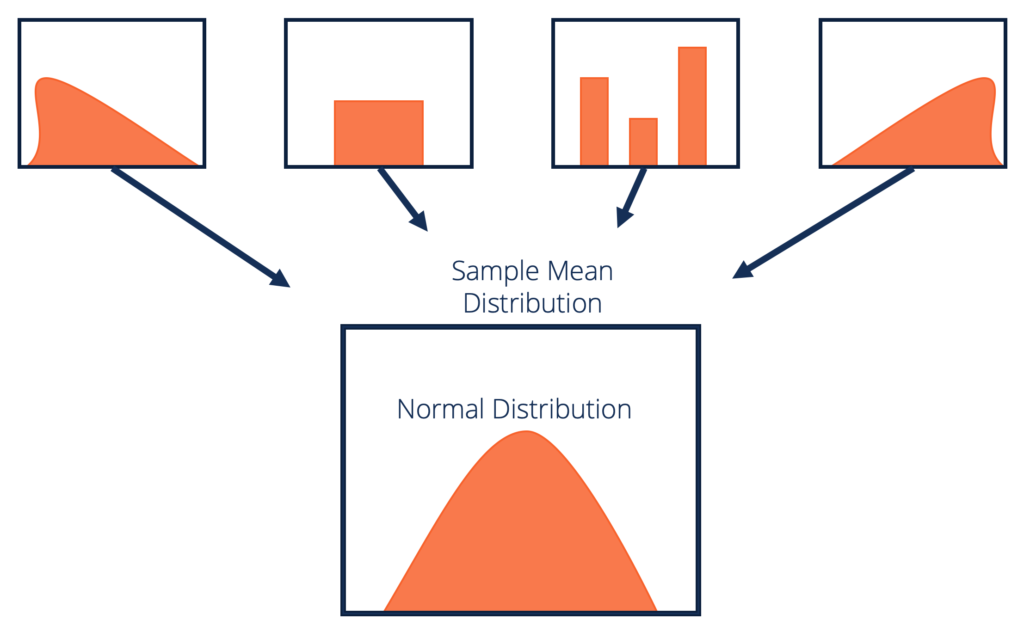
Źródło: corporatefinanceinstitute.com
Centralne twierdzenie graniczne ma wiele zastosowań w wielu dziedzinach. Przyjrzyjmy się im w następnej sekcji.
Znaczenie centralnego twierdzenia granicznego
Centralne twierdzenie graniczne ma zarówno znaczenie statystyczne, jak i praktyczne zastosowania . Czy to nie jest najlepszy punkt, do którego dążymy, kiedy uczymy się nowej koncepcji?
Przyjrzymy się obu aspektom, aby ocenić, gdzie możemy ich użyć.
Znaczenie statystyczne of CLT

Źródło: http://srjcstaff.santarosa.edu
- Analizowanie danych obejmuje metody statystyczne, takie jak testowanie hipotez i konstruowanie przedziałów ufności. Metody te zakładają, że populacja ma rozkład normalny.W przypadku nieznanych lub nienormalnych rozkładów, traktujemy rozkład próbkowania jako normalny zgodnie z centralnym twierdzeniem granicznym
- Jeśli zwiększymy próbki pobrane z populacji, odchylenie standardowe średnich z próby zmniejszy się. Pomaga nam to znacznie dokładniej oszacować średnią populacji.
- Średnia próbna może być również użyta do utworzenia zakresu wartości zwanego przedziałem ufności (który prawdopodobnie będzie składał się ze średniej populacji)
Praktyczne zastosowania CLT
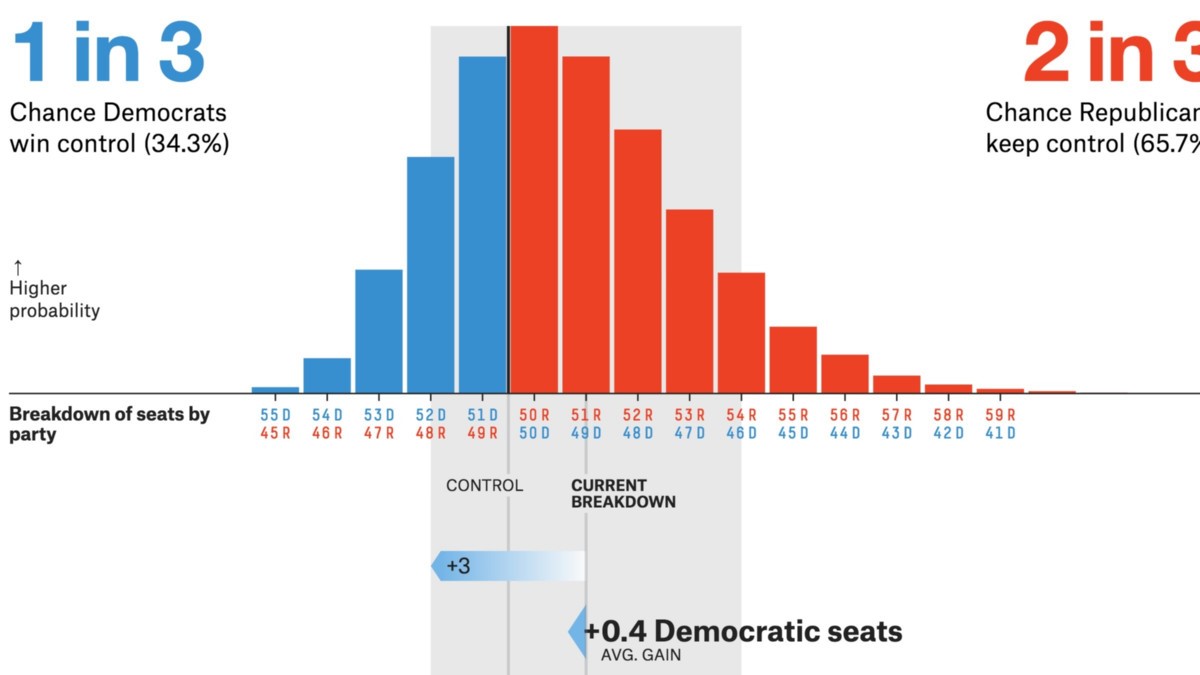
Źródło: projekty .fivethirtyeight.com
- Sondaże polityczne / wyborcze to główne zastosowania CLT. Sondaże te szacują odsetek osób, które wspierają danego kandydata. Być może widzieliście te wyniki w kanałach informacyjnych z przedziałami ufności. Centralne twierdzenie graniczne pomaga obliczyć, że
- Przedział ufności, zastosowanie CLT, jest używany do obliczenia średniego dochodu rodziny dla określonego regionu.
Centralne twierdzenie graniczne ma wiele zastosowań w różnych dziedzinach. Czy możesz wymyślić więcej przykładów? Daj mi znać w sekcji komentarzy pod artykułem – zamieszczę je tutaj.
Założenia za centralnym twierdzeniem granicznym
Zanim zagłębimy się w implementację centralnego twierdzenia granicznego, ważne jest zrozumienie założeń stojących za tą techniką:
- Dane muszą spełniać warunek randomizacji. Musi być losowo próbkowany.
- Próbki powinny być od siebie niezależne. Jedna próbka nie powinna wpływać na inne próbki.
- Wielkość próby nie powinna przekraczać 10% populacji, gdy pobieranie próbek odbywa się bez wymiany
- Wielkość próby powinna być wystarczająco duża. Teraz, jak ustalimy, jak duży powinien być ten rozmiar? Cóż, to zależy od populacji. Gdy populacja jest wypaczona lub asymetryczna, wielkość próby powinna być duża. Jeśli populacja jest symetryczna, możemy również narysować małe próbki.
Ogólnie rzecz biorąc, wielkość próby 30 jest uważana za wystarczającą, gdy populacja jest symetryczna.
średnia z próby oznacza się jako:
µ X̄ = µ
gdzie,
- µ X̄ = Średnia średniej próbki
- µ = Średnia populacji
A odchylenie standardowe średniej próbki jest oznaczone jako:
σ X̄ = σ / sqrt (n)
gdzie,
- σ X̄ = odchylenie standardowe średniej próbki
- σ = Odchylenie standardowe populacji
- n = wielkość próby
I to wszystko w przypadku koncepcji leżącej u podstaw centralnego twierdzenia granicznego. Czas odpalić RStudio i zagłębić się w implementację CLT!
Implementacja centralnego twierdzenia granicznego w R
Podekscytowany, jak możemy zakodować centralne twierdzenie o granicach w R? Zagłębmy się więc w tym.
Zrozumienie stwierdzenia problemu
Organizacja produkująca rury produkuje różne rodzaje rur. Podajemy miesięczne dane dotyczące grubości ścianek niektórych rodzajów rur. Możesz pobrać dane tutaj.
Organizacja chce przeanalizować dane, przeprowadzając testy hipotez i konstruując przedziały ufności, aby wdrożyć pewne strategie w przyszłości. Wyzwanie polega na tym, że rozkład danych nie jest normalny.
Uwaga: ta analiza opiera się na kilku założeniach, a jednym z nich jest normalny rozkład danych.
Rozwiązanie Metodologia
Centralne twierdzenie graniczne pomoże nam obejść problem tych danych, w których populacja nie jest normalna. Dlatego będziemy symulować centralne twierdzenie graniczne na danym zbiorze danych w R. krok po kroku. A więc zacznijmy.
Zaimportuj zestaw danych CSV i zweryfikuj go
Najpierw zaimportuj plik CSV w R, a następnie sprawdź poprawność danych:
Dane wyjściowe:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
Następnie oblicz średnią populacji i wykreśl wszystkie obserwacje danych:
Wyjście:
#Calculate the population mean 12.80205
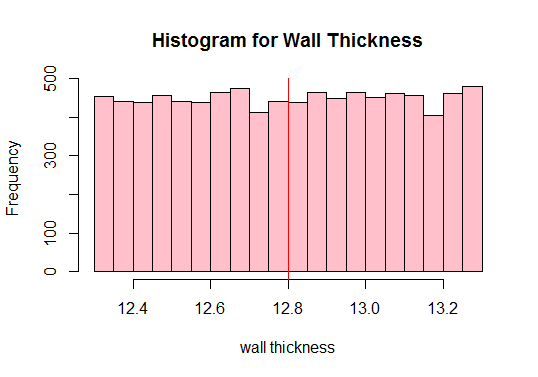
Zobacz czerwony pionowa linia powyżej? To jest średnia populacji. Z powyższego wykresu widać również, że populacja nie jest normalna, prawda? Dlatego musimy pobrać wystarczającą liczbę próbek o różnych rozmiarach i obliczyć ich średnie (znane jako średnie z próby). Następnie wykreślimy średnie z próby, aby uzyskać rozkład normalny.
W naszym przykładzie narysujemy wystarczającą liczbę próbek o rozmiarze 10, obliczymy ich średnie i wykreślimy je w R. Wiem, że minimalny rozmiar próbki wzięte powinno wynosić 30, ale zobaczmy, co się stanie, gdy narysujemy 10:
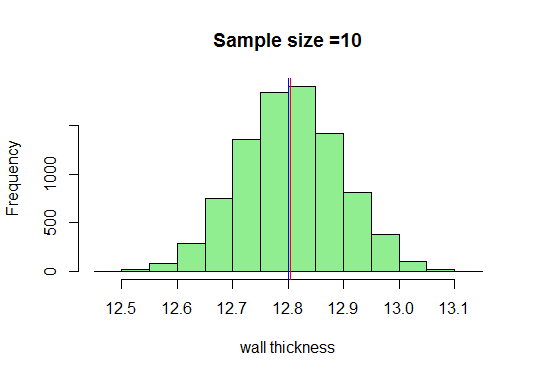
Teraz, wiemy, że wraz ze wzrostem wielkości próbki otrzymamy bardzo ładną krzywą w kształcie dzwonu. Zwiększmy teraz rozmiar naszej próbki i zobaczmy, co otrzymamy:
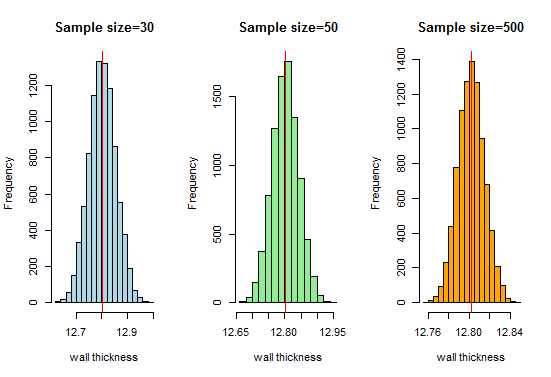
Tutaj otrzymujemy dobra krzywa w kształcie dzwonu, a rozkład próbkowania zbliża się do rozkładu normalnego wraz ze wzrostem wielkości próby.Dlatego możemy uznać rozkłady próbkowania za normalne, a organizacja produkująca rury może wykorzystać te rozkłady do dalszej analizy.
Możesz także pobawić się, pobierając różne rozmiary próbek i rysując inną liczbę próbek. Daj mi znać, jak to działa!
Uwagi końcowe
Centralne twierdzenie graniczne jest dość ważnym pojęciem w statystyce, a co za tym idzie w nauce o danych. Nie mogę wystarczająco podkreślić, jak ważne jest, aby odświeżyć swoją wiedzę statystyczną przed przystąpieniem do nauki o danych lub nawet przed przystąpieniem do rozmowy kwalifikacyjnej.
Polecam udział w kursie Wprowadzenie do nauki o danych – to kompleksowe spojrzenie na statystyki przed wprowadzeniem nauki o danych.
