Introductie
Wat is een van de belangrijkste en belangrijkste concepten van statistieken die ons in staat stellen om voorspellende modellen te maken, en toch brengt het aspirant-datawetenschappers vaak in verwarring? Ja, ik heb het over de centrale limietstelling.
Het is een krachtig statistisch concept dat elke datawetenschapper MOET kennen. Waarom is dat nu?
Welnu, de centrale limietstelling (CLT) vormt de kern van het testen van hypothesen – een cruciaal onderdeel van de levenscyclus van data science. Dat klopt, het idee waarmee we de enorme mogelijkheden van de gegevens die we krijgen, kunnen verkennen, komt voort uit CLT. Het is eigenlijk een eenvoudig begrip om te begrijpen, maar de meeste datawetenschappers worstelen tijdens interviews met deze vraag.
We zullen het concept begrijpen van Central Limit Theorem (CLT) in dit artikel. We zullen zien waarom het belangrijk is, waar het wordt gebruikt en dan leren hoe het toe te passen in R.
Ik raad aan om het onderstaande artikel door te nemen als je een snelle opfriscursus nodig hebt over distributie en de verschillende soorten:
- 6 gemeenschappelijke waarschijnlijkheidsverdelingen die elke datawetenschapper zou moeten kennen
Inhoudsopgave
- Wat is de centrale limietstelling (CLT )?
- Betekenis van de centrale limietstelling
- Statistische betekenis
- Praktische toepassingen
- Veronderstellingen achter de Centrale limietstelling
- Implementatie van de centrale limietstelling in R
Wat is de centrale limietstelling (CLT)?
Laten we de centrale limiet begrijpen stelling met behulp van een voorbeeld. Dit zal je helpen om intuïtief te begrijpen hoe CLT daaronder werkt.
Bedenk dat er 15 secties zijn in de wetenschappelijke afdeling van een universiteit en dat elke sectie ongeveer 100 studenten herbergt. Het is onze taak om het gemiddelde gewicht van studenten op de afdeling bèta te berekenen. Klinkt simpel, toch?
De benadering die ik krijg van aspirant-datawetenschappers is om simpelweg het gemiddelde te berekenen:
- Meet eerst de gewichten van alle studenten in de wetenschappelijke afdeling
- Alle gewichten optellen
- Ten slotte, deel de totale som van gewichten door een totaal aantal leerlingen om het gemiddelde te krijgen
Maar wat als de omvang van de gegevens is gigantisch? Heeft deze benadering zin? Niet echt – het meten van het gewicht van alle studenten zal een erg vermoeiend en langdurig proces zijn. Dus, wat kunnen we in plaats daarvan doen? Laten we eens kijken naar een alternatieve benadering.
- Trek eerst willekeurig groepen leerlingen uit de klas. We zullen dit een voorbeeld noemen. We trekken meerdere voorbeelden, elk bestaande uit 30 leerlingen.

Bron: http://www.123rf.com
- Bereken het individuele gemiddelde van deze steekproeven
- Bereken het gemiddelde van deze steekproefgemiddelden
- Deze waarde geeft ons het geschatte gemiddelde gewicht van de studenten in de wetenschappelijke afdeling
- Bovendien zal het histogram van het gemiddelde gewicht van de steekproef van studenten lijken op een belcurve (of normale verdeling)
Dit, in een notendop, is waar de centrale limietstelling over gaat. Als je je leren door middel van video’s maakt, bekijk dan de onderstaande inleiding tot de centrale limietstelling. Dit maakt deel uit van de uitgebreide statistiekmodule in de cursus ‘Inleiding tot Data Science’:
Formeel definiëren van de centrale limietstelling
Laten we een formele definitie geven aan CLT:
Gegeven een dataset met onbekende distributie (deze kan uniform, binominaal of volledig willekeurig zijn), zal het steekproefgemiddelde de normale distributie benaderen.
Deze voorbeelden zouden voldoende groot moeten zijn. De verdeling van steekproefgemiddelden, berekend op basis van herhaalde steekproeven, zal normaliseren naarmate de omvang van uw steekproeven groter wordt.
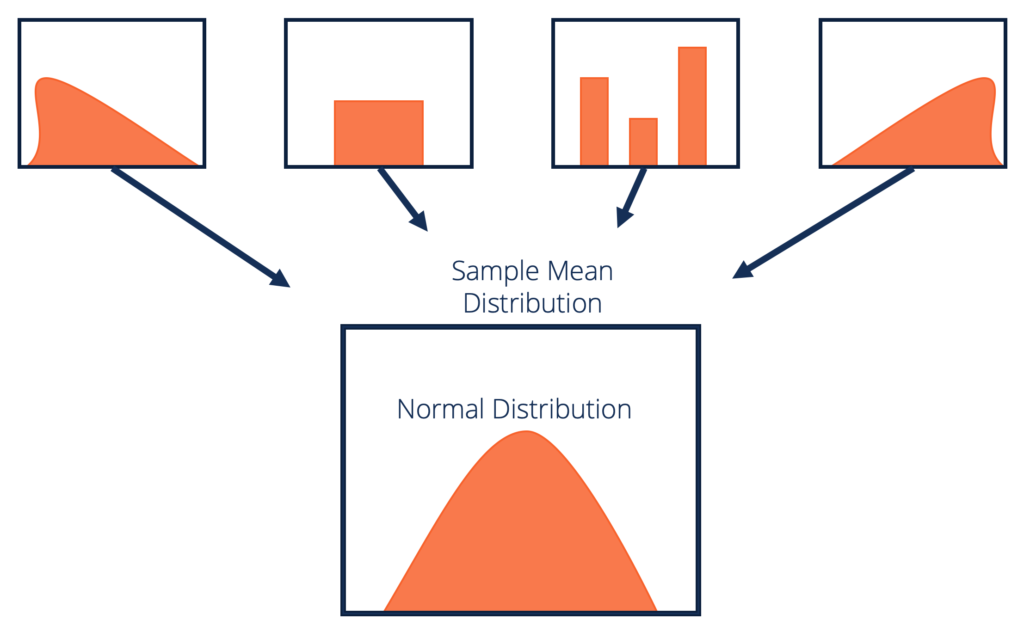
Bron: corporatefinanceinstitute.com
De centrale limietstelling heeft een grote verscheidenheid aan toepassingen op vele gebieden. Laten we ze in de volgende sectie bekijken.
Betekenis van de centrale limietstelling
De centrale limietstelling heeft zowel statistische significantie als praktische toepassingen . Is dat niet de goede plek waar we naar streven als we een nieuw concept aan het leren zijn?
We zullen beide aspecten bekijken om te peilen waar we ze kunnen gebruiken.
Statistische significantie van CLT

Bron: http://srjcstaff.santarosa.edu
- Het analyseren van gegevens omvat statistische methoden zoals het testen van hypothesen en het construeren van betrouwbaarheidsintervallen. Deze methoden gaan ervan uit dat de populatie normaal verdeeld is.In het geval van onbekende of niet-normale verdelingen behandelen we de steekproefverdeling als normaal volgens de centrale limietstelling.
- Als we de steekproeven uit de populatie vergroten, zal de standaarddeviatie van steekproefgemiddelden afnemen. Dit helpt ons om het populatiegemiddelde veel nauwkeuriger te schatten.
- Ook kan het steekproefgemiddelde worden gebruikt om het bereik van waarden te creëren dat bekend staat als een betrouwbaarheidsinterval (dat waarschijnlijk bestaat uit het populatiegemiddelde)
Praktische toepassingen van CLT
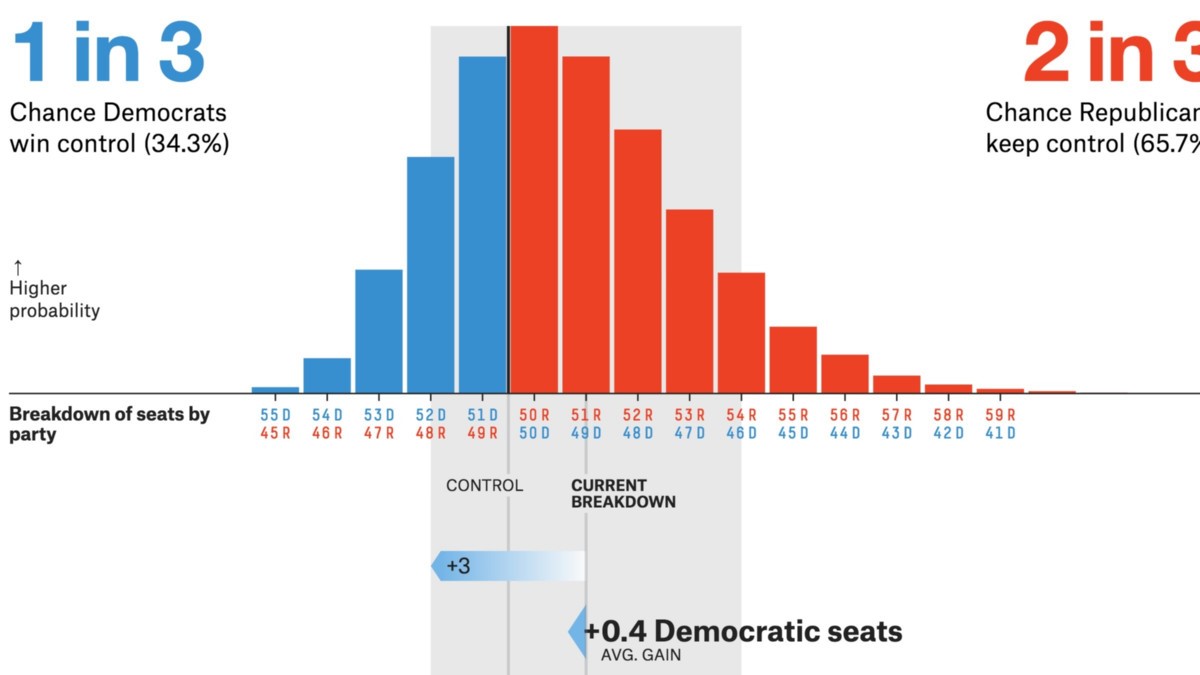
Bron: projecten .fivethirtyeight.com
- Politieke / verkiezingsonderzoeken zijn belangrijke CLT-toepassingen. Deze peilingen schatten het percentage mensen dat een bepaalde kandidaat ondersteunt. Mogelijk hebt u deze resultaten gezien op nieuwskanalen met betrouwbaarheidsintervallen. De centrale limietstelling helpt bij het berekenen dat
- Betrouwbaarheidsinterval, een toepassing van CLT, wordt gebruikt om het gemiddelde gezinsinkomen voor een bepaalde regio te berekenen
De centrale limietstelling heeft veel toepassingen op verschillende gebieden. Kun je nog meer voorbeelden bedenken? Laat het me weten in de commentarensectie onder het artikel – ik zal ze hier opnemen.
Veronderstellingen achter de centrale limietstelling
Voordat we ingaan op de implementatie van de centrale limietstelling, is het belangrijk om de aannames achter deze techniek te begrijpen:
- De gegevens moeten de randomiseringsvoorwaarde volgen. Het moet willekeurig worden bemonsterd.
- Monsters moeten onafhankelijk van elkaar zijn. De ene steekproef mag de andere steekproeven niet beïnvloeden.
- De steekproefomvang mag niet meer dan 10% van de populatie bedragen wanneer de steekproef zonder vervanging wordt uitgevoerd
- De steekproefomvang moet voldoende groot zijn. Nu, hoe zullen we erachter komen hoe groot deze maat moet zijn? Nou, het hangt af van de bevolking. Als de populatie scheef of asymmetrisch is, moet de steekproefomvang groot zijn. Als de populatie symmetrisch is, kunnen we ook kleine steekproeven nemen.
In het algemeen wordt een steekproefomvang van 30 als voldoende beschouwd als de populatie symmetrisch is.
De gemiddelde van de steekproefgemiddelden wordt aangegeven als:
µ Xawiki = µ
waar,
- µ Xmingham = Gemiddelde van de steekproefgemiddelden
- µ = Populatiegemiddelde
En de standaarddeviatie van het steekproefgemiddelde wordt aangegeven als:
σ X† = σ / sqrt (n)
waar,
- σ X† = Standaarddeviatie van het steekproefgemiddelde
- σ = Standaarddeviatie van de populatie
- n = steekproefomvang
En dat is het voor het concept achter de centrale limietstelling. Tijd om RStudio te starten en in de implementatie van CLT te graven!
Implementatie van de centrale limietstelling in R
Opgewonden om te zien hoe we de centrale limietstelling kunnen coderen in R? Laten we dan maar eens kijken.
De probleemstelling begrijpen
Een pijpfabrikant produceert verschillende soorten pijpen. Van bepaalde soorten buizen krijgen we maandelijks de gegevens van de wanddikte. U kunt de gegevens hier downloaden.
De organisatie wil de gegevens analyseren door hypothesetests uit te voeren en betrouwbaarheidsintervallen te construeren om bepaalde strategieën in de toekomst te implementeren. De uitdaging is dat de distributie van de gegevens niet normaal is.
Opmerking: deze analyse werkt op basis van een paar aannames en een daarvan is dat de gegevens normaal verdeeld moeten zijn.
Oplossing Methodologie
De centrale limietstelling zal ons helpen het probleem van deze gegevens te omzeilen wanneer de populatie niet normaal is. Daarom zullen we de centrale limietstelling op de gegeven dataset stap voor stap simuleren in R. Laten we dus aan de slag gaan.
Importeer de CSV-gegevensset en valideer deze
Importeer eerst het CSV-bestand in R en valideer vervolgens de gegevens op juistheid:
Uitvoer:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
Bereken vervolgens het populatiegemiddelde en plot alle waarnemingen van de gegevens:
Uitvoer:
#Calculate the population mean 12.80205
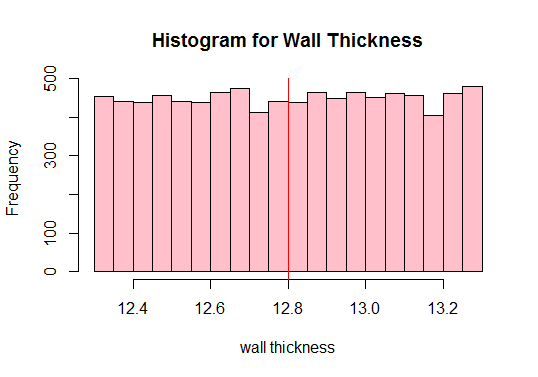
Zie de rode verticale lijn erboven? Dat is het gemiddelde van de bevolking. We kunnen ook aan de bovenstaande plot zien dat de populatie niet normaal is, toch? Daarom moeten we voldoende steekproeven van verschillende grootte nemen en hun gemiddelden berekenen (ook wel steekproefgemiddelden genoemd). We zullen dan die steekproefgemiddelden uitzetten om een normale verdeling te krijgen.
In ons voorbeeld zullen we voldoende steekproeven van grootte 10 nemen, hun gemiddelden berekenen en ze uitzetten in R. Ik weet dat de minimale steekproefomvang genomen zou 30 moeten zijn, maar laten we eens kijken wat er gebeurt als we 10 tekenen:
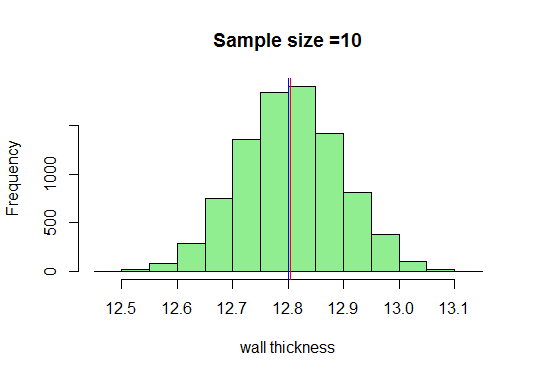
Nu, we weten dat we een heel mooie klokvormige curve krijgen naarmate de steekproefomvang toeneemt. Laten we nu onze steekproefomvang vergroten en kijken wat we krijgen:
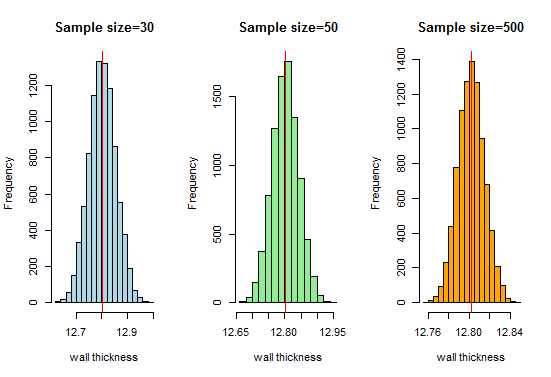
Hier krijgen we een goede klokvormige curve en de steekproefverdeling benadert de normale verdeling naarmate de steekproefomvang toeneemt.Daarom kunnen we de steekproefverdelingen als normaal beschouwen en kan de pijpfabrikant deze verdelingen gebruiken voor verdere analyse.
Je kunt ook spelen door verschillende steekproeven te nemen en een ander aantal steekproeven te trekken. Laat me weten hoe het voor je uitpakt!
Eindnoten
Centrale limietstelling is een vrij belangrijk concept in de statistiek, en bijgevolg in de datawetenschap. Ik kan niet genoeg benadrukken hoe belangrijk het is dat je je statistische kennis bijwerkt voordat je met data science begint of zelfs maar voor een data science interview zit.
Ik raad aan om de cursus Inleiding tot data science te volgen – het is een uitgebreide kijk op statistieken voordat data science wordt geïntroduceerd.
