Einführung
Was ist eines der wichtigsten und wichtigsten Konzepte? von Statistiken, die es uns ermöglichen, Vorhersagemodelle zu erstellen, und dennoch aufstrebende Datenwissenschaftler oft verwirren? Ja, ich spreche über den zentralen Grenzwertsatz.
Es ist ein leistungsfähiges statistisches Konzept, das jeder Datenwissenschaftler kennen muss. Warum ist das so?
Nun, der zentrale Grenzwertsatz (CLT) steht im Mittelpunkt des Hypothesentests – eine kritische Komponente des datenwissenschaftlichen Lebenszyklus. Das ist richtig, die Idee, mit der wir die enormen Möglichkeiten der Daten erkunden können, die wir erhalten, stammt von CLT. Es ist eigentlich ein einfacher Begriff zu verstehen, aber die meisten Datenwissenschaftler scheitern bei Interviews an dieser Frage.
Wir werden das Konzept verstehen des zentralen Grenzwertsatzes (CLT) in diesem Artikel. Wir werden sehen, warum es wichtig ist, wo es verwendet wird, und dann lernen, wie man es in R anwendet.
Ich empfehle, den folgenden Artikel durchzugehen, wenn Sie eine kurze Auffrischung der Verteilung und ihrer verschiedenen Typen benötigen:
- 6 Allgemeine Wahrscheinlichkeitsverteilungen, die jeder Data Science-Experte kennen sollte
Inhaltsverzeichnis
- Was ist der zentrale Grenzwertsatz (CLT)? )?
- Signifikanz des zentralen Grenzwertsatzes
- Statistische Signifikanz
- Praktische Anwendungen
- Annahmen hinter dem Zentraler Grenzwertsatz
- Implementieren des zentralen Grenzwertsatzes in R
Was ist der zentrale Grenzwertsatz (CLT)?
Lassen Sie uns den zentralen Grenzwert verstehen Satz mit Hilfe eines Beispiels. Auf diese Weise können Sie intuitiv nachvollziehen, wie CLT darunter funktioniert.
Beachten Sie, dass es in der naturwissenschaftlichen Abteilung einer Universität 15 Abteilungen gibt und jede Abteilung etwa 100 Studenten beherbergt. Unsere Aufgabe ist es, das Durchschnittsgewicht der Studenten in der naturwissenschaftlichen Abteilung zu berechnen. Klingt einfach, oder?
Der Ansatz, den ich von angehenden Datenwissenschaftlern bekomme, besteht darin, einfach den Durchschnitt zu berechnen:
- Messen Sie zunächst die Gewichte aller Studenten in der naturwissenschaftlichen Abteilung
- Addiere alle Gewichte
- Teilen Sie schließlich die Gesamtsumme der Gewichte durch die Gesamtzahl der Schüler, um den Durchschnitt zu erhalten.
Aber was wäre wenn Die Größe der Daten ist enorm? Ist dieser Ansatz sinnvoll? Nicht wirklich – das Gewicht aller Schüler zu messen wird ein sehr mühsamer und langer Prozess sein. Was können wir stattdessen tun? Schauen wir uns einen alternativen Ansatz an.
- Zeichnen Sie zunächst zufällig Gruppen von Schülern aus der Klasse. Wir werden dies ein Beispiel nennen. Wir werden mehrere Stichproben mit jeweils 30 Schülern ziehen.

Quelle: http://www.123rf.com
- Berechnen Sie den individuellen Mittelwert dieser Stichproben
- Berechnen Sie den Mittelwert dieser Stichprobenmittelwerte
- Dieser Wert gibt uns das ungefähre Durchschnittsgewicht der Studenten in der naturwissenschaftlichen Abteilung an.
- Zusätzlich ähnelt das Histogramm der Durchschnittsgewichte der Studenten einer Glockenkurve (oder Normalverteilung)
Kurz gesagt, darum geht es im zentralen Grenzwertsatz. Wenn Sie durch Videos lernen, lesen Sie die folgende Einführung zum zentralen Grenzwertsatz. Dies ist Teil des umfassenden Statistikmoduls im Kurs ‚Einführung in die Datenwissenschaft‘:
Formales Definieren des zentralen Grenzwertsatzes
Lassen Sie uns CLT formal definieren:
Bei einem Datensatz mit unbekannter Verteilung (er kann einheitlich, binomial oder vollständig zufällig sein) nähert sich das Stichprobenmittel der Normalverteilung an.
Diese Proben sollten ausreichend groß sein. Die aus wiederholten Stichproben berechnete Verteilung der Stichprobenmittelwerte tendiert zur Normalität, wenn die Größe Ihrer Stichproben größer wird.
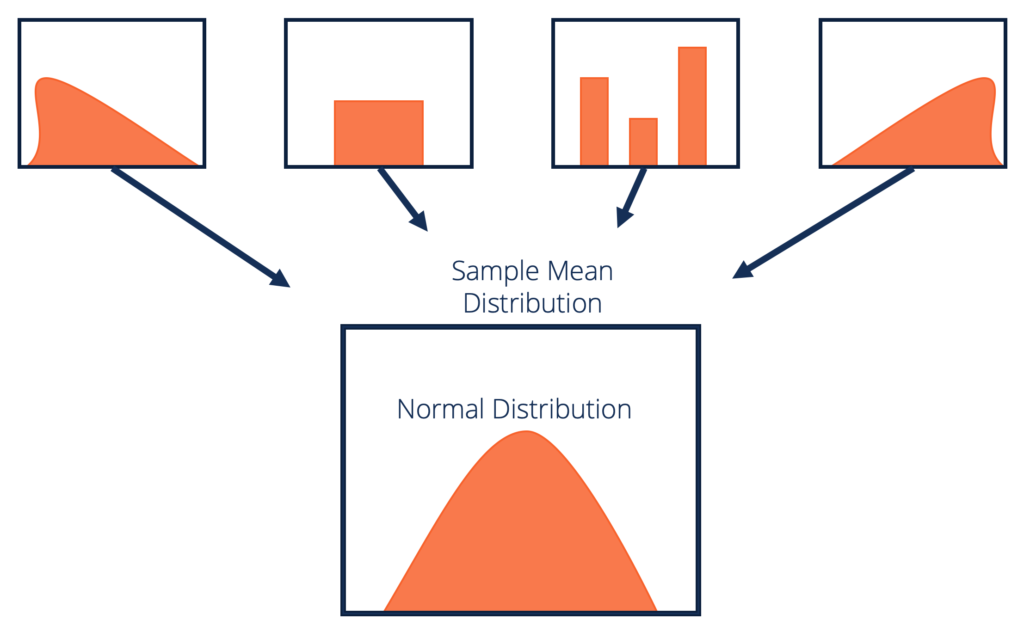
Quelle: companyfinanceinstitute.com
Der zentrale Grenzwertsatz hat eine Vielzahl von Anwendungen in vielen Bereichen. Schauen wir uns diese im nächsten Abschnitt an.
Bedeutung des zentralen Grenzwertsatzes
Der zentrale Grenzwertsatz hat sowohl statistische Signifikanz als auch praktische Anwendungen . Ist das nicht der Sweet Spot, den wir anstreben, wenn wir ein neues Konzept lernen?
Wir werden beide Aspekte untersuchen, um festzustellen, wo wir sie verwenden können.
Statistische Bedeutung von CLT

Quelle: http://srjcstaff.santarosa.edu
- Das Analysieren von Daten umfasst statistische Methoden wie das Testen von Hypothesen und das Erstellen von Konfidenzintervallen. Diese Methoden setzen voraus, dass die Bevölkerung normal verteilt ist.Bei unbekannten oder nicht normalen Verteilungen behandeln wir die Stichprobenverteilung gemäß dem zentralen Grenzwertsatz
- als normal. Wenn wir die aus der Grundgesamtheit gezogenen Stichproben erhöhen, nimmt die Standardabweichung der Stichprobenmittelwerte ab. Dies hilft uns, den Populationsmittelwert viel genauer abzuschätzen.
- Außerdem kann der Stichprobenmittelwert verwendet werden, um den Wertebereich zu erstellen, der als Konfidenzintervall bezeichnet wird (das wahrscheinlich aus dem Populationsmittelwert besteht)
Praktische Anwendungen von CLT
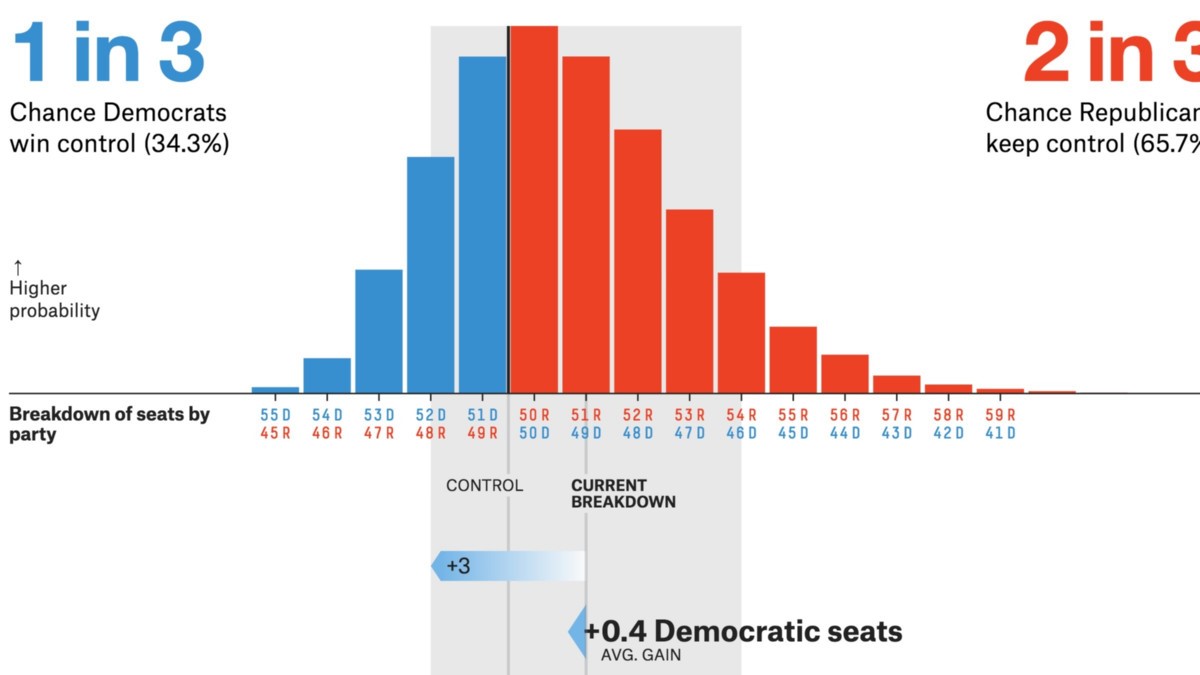
Quelle: Projekte .fivethirtyeight.com
- Politische / Wahlumfragen sind erstklassige CLT-Anwendungen. Diese Umfragen schätzen den Prozentsatz der Personen, die einen bestimmten Kandidaten unterstützen. Möglicherweise haben Sie diese Ergebnisse auf Nachrichtenkanälen mit Konfidenzintervallen gesehen. Der zentrale Grenzwertsatz hilft bei der Berechnung, dass das
- Konfidenzintervall, eine Anwendung von CLT, verwendet wird, um das mittlere Familieneinkommen für eine bestimmte Region zu berechnen.
Der zentrale Grenzwertsatz hat viele Anwendungen in verschiedenen Bereichen. Können Sie sich weitere Beispiele vorstellen? Lassen Sie es mich im Kommentarbereich unter dem Artikel wissen – ich werde sie hier aufnehmen.
Annahmen hinter dem zentralen Grenzwertsatz
Bevor wir uns mit der Implementierung des zentralen Grenzwertsatzes befassen, ist es Es ist wichtig, die Annahmen hinter dieser Technik zu verstehen:
- Die Daten müssen der Randomisierungsbedingung folgen. Es muss zufällig ausgewählt werden.
- Die Stichproben sollten unabhängig voneinander sein. Eine Stichprobe sollte die anderen Stichproben nicht beeinflussen.
- Die Stichprobengröße sollte nicht mehr als 10% der Bevölkerung betragen, wenn die Stichprobe ersatzlos durchgeführt wird.
- Die Stichprobengröße sollte ausreichend groß sein. Wie werden wir nun herausfinden, wie groß diese Größe sein sollte? Nun, es hängt von der Bevölkerung ab. Wenn die Population schief oder asymmetrisch ist, sollte die Stichprobengröße groß sein. Wenn die Population symmetrisch ist, können wir auch kleine Stichproben ziehen.
Im Allgemeinen wird eine Stichprobengröße von 30 als ausreichend angesehen, wenn die Population symmetrisch ist.
Die Der Mittelwert des Probenmittels wird bezeichnet als:
µ X̄ = µ
wobei
- µ X̄ = Mittelwert des Stichprobenmittelwerts
- µ = Populationsmittelwert
Die Standardabweichung des Stichprobenmittelwerts wird wie folgt bezeichnet:
σ X̄ = σ / sqrt (n)
wobei
- σ X̄ = Standardabweichung des Stichprobenmittelwerts
- σ = Populationsstandardabweichung
- n = Stichprobengröße
Und das ist es für das Konzept hinter dem zentralen Grenzwertsatz. Zeit, RStudio zu starten und sich mit der Implementierung von CLT zu befassen!
Implementierung des zentralen Grenzwertsatzes in R
Wir sind gespannt, wie wir den zentralen Grenzwertsatz codieren können in R? Lassen Sie uns dann näher darauf eingehen.
Problemstellung verstehen
Eine Rohrherstellungsorganisation stellt verschiedene Arten von Rohren her. Wir erhalten die monatlichen Daten zur Wandstärke bestimmter Rohrtypen. Sie können die Daten hier herunterladen.
Die Organisation möchte die Daten analysieren, indem sie Hypothesentests durchführt und Konfidenzintervalle erstellt, um einige Strategien in Zukunft umzusetzen. Die Herausforderung besteht darin, dass die Verteilung der Daten nicht normal ist.
Hinweis: Diese Analyse basiert auf einigen Annahmen, und eine davon besteht darin, dass die Daten normal verteilt werden sollten.
Lösung Methodik
Der zentrale Grenzwertsatz hilft uns, das Problem dieser Daten zu umgehen, bei denen die Grundgesamtheit nicht normal ist. Daher simulieren wir Schritt für Schritt den zentralen Grenzwertsatz für den angegebenen Datensatz in R. Beginnen wir also.
Importieren Sie den CSV-Datensatz und validieren Sie ihn.
Importieren Sie zuerst die CSV-Datei in R und überprüfen Sie dann die Daten auf Richtigkeit:
Ausgabe:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
Berechnen Sie als Nächstes den Populationsmittelwert und zeichnen Sie alle Beobachtungen der Daten auf:
Ausgabe:
#Calculate the population mean 12.80205
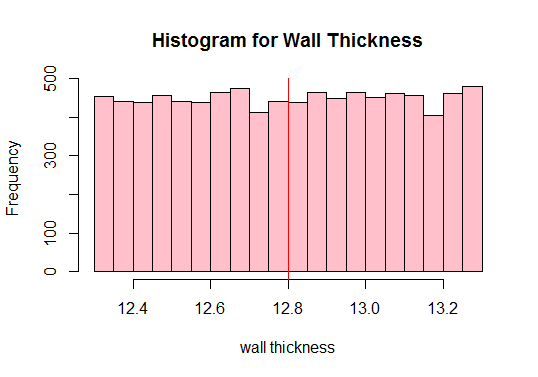
Siehe rot vertikale Linie oben? Das ist die Bevölkerungszahl. Wir können auch aus der obigen Darstellung ersehen, dass die Bevölkerung nicht normal ist, oder? Daher müssen wir genügend Stichproben unterschiedlicher Größe ziehen und ihre Mittelwerte berechnen (sogenannte Stichprobenmittelwerte). Wir werden dann diese Stichprobenmittelwerte zeichnen, um eine Normalverteilung zu erhalten.
In unserem Beispiel werden wir genügend Stichproben der Größe 10 zeichnen, ihre Mittelwerte berechnen und sie in R darstellen. Ich weiß, dass die minimale Stichprobengröße genommen sollte 30 sein, aber mal sehen, was passiert, wenn wir 10 zeichnen:
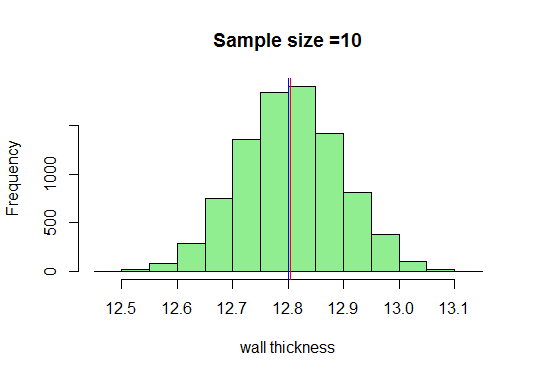
Nun, Wir wissen, dass wir mit zunehmender Stichprobengröße eine sehr schöne glockenförmige Kurve erhalten. Lassen Sie uns nun unsere Stichprobengröße erhöhen und sehen, was wir erhalten:
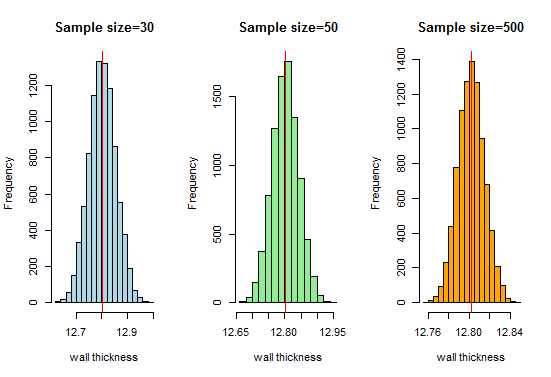
Hier erhalten wir Eine gute glockenförmige Kurve und die Stichprobenverteilung nähern sich der Normalverteilung an, wenn die Stichprobengröße zunimmt.Daher können wir die Stichprobenverteilungen als normal betrachten und die Rohrherstellungsorganisation kann diese Verteilungen für die weitere Analyse verwenden.
Sie können auch herumspielen, indem Sie unterschiedliche Stichprobengrößen entnehmen und eine unterschiedliche Anzahl von Stichproben ziehen. Lassen Sie mich wissen, wie es für Sie funktioniert!
End Notes
Der zentrale Grenzwertsatz ist ein ziemlich wichtiges Konzept in der Statistik und folglich in der Datenwissenschaft. Ich kann nicht genug betonen, wie wichtig es ist, dass Sie Ihr Statistikwissen auffrischen, bevor Sie in die Datenwissenschaft einsteigen oder sogar ein Data Science-Interview führen.
Ich empfehle den Kurs Einführung in die Datenwissenschaft – es ist ein Umfassender Blick auf Statistiken vor Einführung der Datenwissenschaft.
