Was ist eine robots.txt-Datei?
Robots.txt ist eine Textdatei, die Webmaster erstellen, um Webroboter anzuweisen ( in der Regel Suchmaschinenroboter), wie Seiten auf ihrer Website gecrawlt werden. Die robots.txt-Datei ist Teil des Robots Exclusion Protocol (REP), einer Gruppe von Webstandards, die regeln, wie Roboter das Web crawlen, auf Inhalte zugreifen und diese indizieren und diese Inhalte den Benutzern zur Verfügung stellen. Das REP enthält auch Anweisungen wie Metaroboter sowie seiten-, unterverzeichnis- oder siteweite Anweisungen, wie Suchmaschinen Links behandeln sollen (z. B. „Folgen“ oder „Nicht folgen“).
In In der Praxis geben robots.txt-Dateien an, ob bestimmte Benutzeragenten (Web-Crawler-Software) Teile einer Website crawlen können oder nicht. Diese Crawling-Anweisungen werden angegeben, indem das Verhalten bestimmter (oder aller) Benutzeragenten „nicht zugelassen“ oder „zugelassen“ wird.
Grundformat:
User-agent: Disallow:
Zusammen werden diese beiden Zeilen als vollständige robots.txt-Datei betrachtet. Eine Robots-Datei kann jedoch mehrere Zeilen mit Benutzeragenten und Anweisungen enthalten (dh nicht zulassen, zulassen, Crawling-Verzögerungen usw.).
In einer robots.txt-Datei wird jeder Satz von Benutzeragentenanweisungen als diskreter Satz angezeigt, der durch einen Zeilenumbruch getrennt ist:
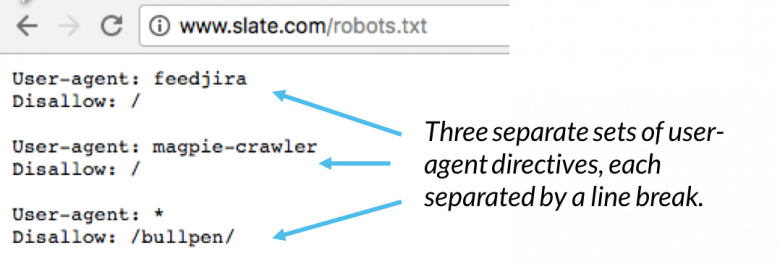
In einer robots.txt-Datei mit mehreren Benutzeragentenanweisungen gilt jede Nichtzulassungs- oder Zulassungsregel nur für den Benutzeragenten ( s) in diesem bestimmten Satz mit getrenntem Zeilenumbruch angegeben. Wenn die Datei eine Regel enthält, die für mehr als einen Benutzeragenten gilt, beachtet ein Crawler nur die spezifischste Gruppe von Anweisungen (und befolgt die Anweisungen in).
Hier ein Beispiel:
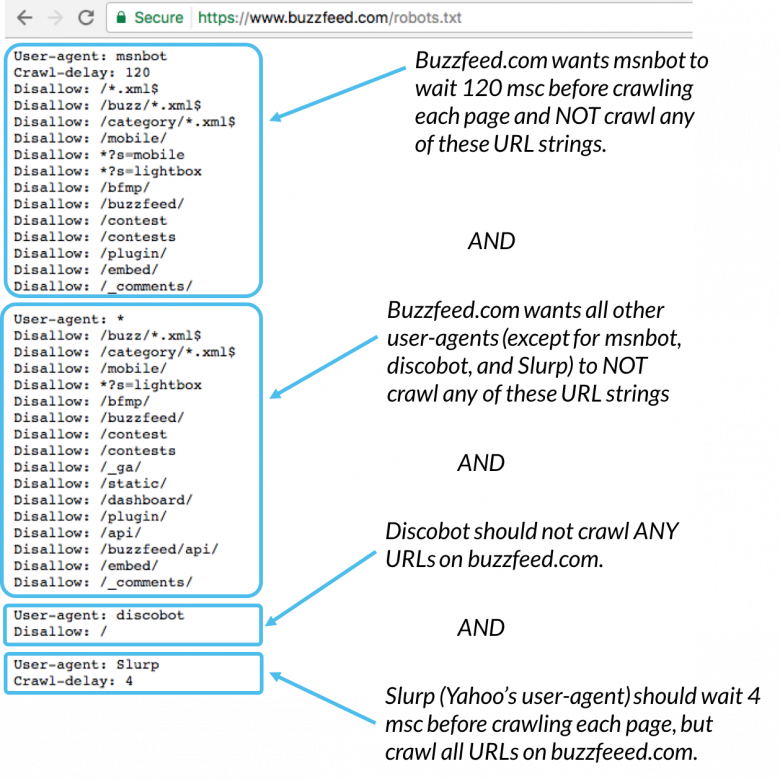
Msnbot, Discobot und Slurp werden alle aufgerufen Diese Benutzeragenten beachten daher nur die Anweisungen in ihren Abschnitten der robots.txt-Datei. Alle anderen Benutzeragenten folgen den Anweisungen in der Benutzeragentengruppe: *.
Beispiel robots.txt:
Hier einige Beispiele für robots.txt in Aktion für a Website www.example.com:
URL der Robots.txt-Datei: www.example.com/robots.txt
Blockieren aller Webcrawler für alle Inhalte
User-agent: * Disallow: /
Die Verwendung dieser Syntax in einer robots.txt-Datei weist alle Webcrawler an, keine Seiten auf www.example.com, einschließlich der Startseite, zu crawlen.
Zulassen Alle Webcrawler greifen auf alle Inhalte zu.
User-agent: * Disallow:
Die Verwendung dieser Syntax in einer robots.txt-Datei weist Webcrawler an, alle Seiten auf www.example.com zu crawlen, einschließlich die Startseite.
Blockieren eines bestimmten Webcrawlers aus einem bestimmten Ordner
User-agent: Googlebot Disallow: /example-subfolder/
Diese Syntax gibt nur den Crawler von Google an (Name des Benutzeragenten Googlebot) ) keine Seiten zu crawlen, die die URL-Zeichenfolge www.example.com/example-subfolder/ enthalten.
Blockieren eines bestimmten Webcrawlers von einer bestimmten Webseite
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Diese Syntax weist nur den Crawler von Bing (Name des Benutzeragenten Bing) an, das Crawlen der spezifischen Seite unter www.example.com/example-subfolder/blocked-page zu vermeiden .html.
Wie funktioniert robots.txt?
Suchmaschinen haben zwei Hauptaufgaben:
- Durchsuchen des Webs, um Inhalte zu entdecken;
- Indizieren Sie diesen Inhalt, damit er Suchenden bereitgestellt werden kann, die nach Informationen suchen.
Um Websites zu crawlen, folgen Suchmaschinen Links, um von einer Website zur anderen zu gelangen – letztendlich zum Crawlen über viele Milliarden von Links und Websites. Dieses Crawling-Verhalten wird manchmal als „Spidering“ bezeichnet.
Nach dem Aufrufen einer Website, jedoch vor dem Spidering, sucht der Such-Crawler nach einer robots.txt-Datei. Wenn er eine findet, liest der Crawler diese Datei zuerst, bevor Sie mit der Seite fortfahren. Da die robots.txt-Datei Informationen darüber enthält, wie die Suchmaschine crawlen soll, weisen die dort gefundenen Informationen weitere Crawleraktionen auf dieser bestimmten Site an. Wenn die robots.txt-Datei keine Anweisungen enthält, die Wenn Sie die Aktivität eines Benutzeragenten nicht zulassen (oder wenn die Site keine robots.txt-Datei hat), werden andere Informationen auf der Site gecrawlt.
Andere schnelle robots.txt-Informationen müssen:
(weiter unten ausführlicher beschrieben)
-
Um gefunden zu werden, muss eine robots.txt-Datei im obersten Verzeichnis einer Website abgelegt werden.
-
Bei Robots.txt wird zwischen Groß- und Kleinschreibung unterschieden: Die Datei muss den Namen „robots.txt“ haben (nicht Robots.txt, robots.TXT oder andere).
-
Einige Benutzeragenten (Roboter) m Sie können Ihre robots.txt-Datei ignorieren. Dies ist besonders häufig bei schändlicheren Crawlern wie Malware-Robotern oder E-Mail-Adressschabern der Fall.
-
Die Datei /robots.txt ist öffentlich verfügbar: Fügen Sie am Ende einfach /robots.txt hinzu einer Root-Domain, um die Anweisungen dieser Website zu sehen (wenn diese Site eine robots.txt-Datei hat!).Dies bedeutet, dass jeder sehen kann, welche Seiten Sie crawlen oder nicht, also verwenden Sie sie nicht, um private Benutzerinformationen auszublenden.
-
Jede Subdomain in einem Stammverzeichnis Domain verwendet separate robots.txt-Dateien. Dies bedeutet, dass sowohl blog.example.com als auch example.com ihre eigenen robots.txt-Dateien haben sollten (unter blog.example.com/robots.txt und example.com/robots.txt).
-
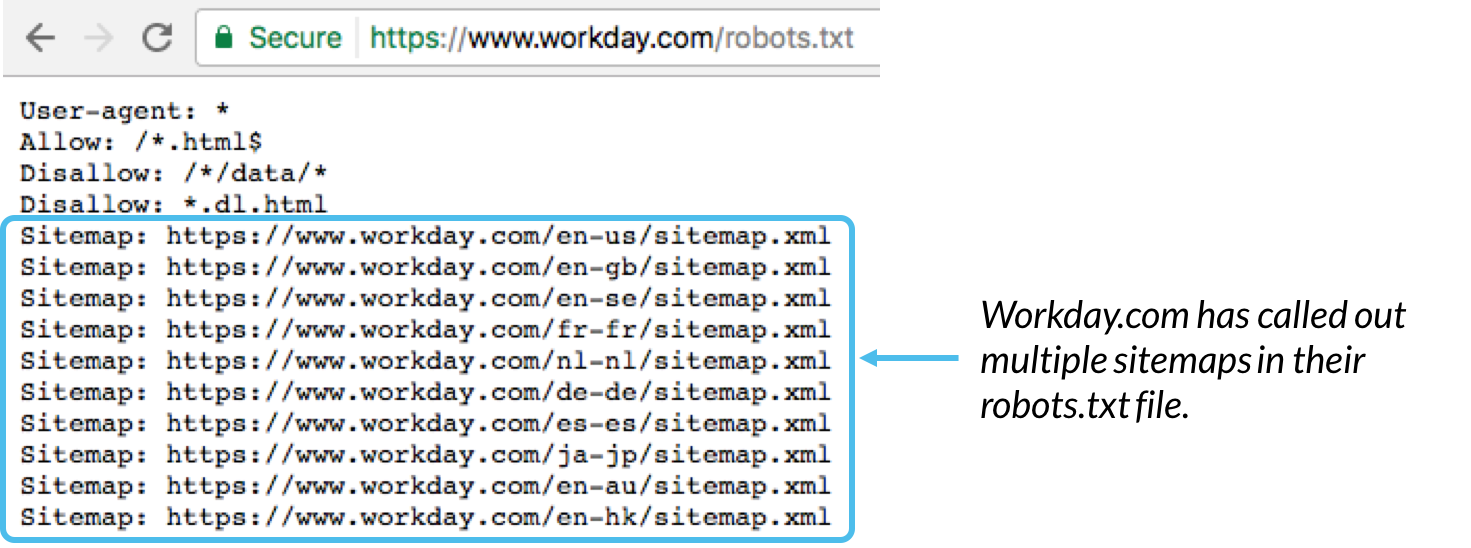
Es wird im Allgemeinen empfohlen, den Speicherort aller Sitemaps, die dieser Domäne zugeordnet sind, am Ende der robots.txt-Datei anzugeben. Hier ein Beispiel:
Technische robots.txt-Syntax
Die Robots.txt-Syntax kann als „Sprache“ von robots.txt-Dateien angesehen werden. Es gibt fünf gebräuchliche Begriffe, auf die Sie wahrscheinlich bei Robotern stoßen Dazu gehören:
-
Benutzeragent: Der spezifische Webcrawler, dem Sie Crawling-Anweisungen geben (normalerweise eine Suchmaschine). Eine Liste der meisten Benutzeragenten finden Sie hier.
-
Nicht zulassen: Der Befehl, mit dem ein Benutzeragent angewiesen wird, eine bestimmte URL nicht zu crawlen. Für jede URL ist nur eine Zeile „Nicht zulassen:“ zulässig.
-
Zulassen (gilt nur für Googlebot): Der Befehl, Googlebot mitzuteilen, dass er auf eine Seite oder einen Unterordner zugreifen kann, obwohl die übergeordnete Seite oder der übergeordnete Unterordner möglicherweise nicht zulässig sind.
-
Crawling-Verzögerung: Wie viele Sekunden sollte ein Crawler warten, bevor er Seiteninhalte lädt und crawlt. Beachten Sie, dass Googlebot diesen Befehl nicht bestätigt, die Crawling-Rate jedoch festgelegt werden kann. i n Google Search Console.
-
Sitemap: Wird verwendet, um den Speicherort aller XML-Sitemaps aufzurufen, die dieser URL zugeordnet sind. Beachten Sie, dass dieser Befehl nur von Google, Ask, Bing und Yahoo unterstützt wird.
Mustervergleich
Wenn es um die tatsächlich zu blockierenden URLs geht oder erlauben, robots.txt-Dateien können ziemlich komplex werden, da sie die Verwendung von Pattern Matching ermöglichen, um eine Reihe möglicher URL-Optionen abzudecken. Google und Bing berücksichtigen beide zwei reguläre Ausdrücke, mit denen Seiten oder Unterordner identifiziert werden können, die von einer SEO ausgeschlossen werden sollen. Diese beiden Zeichen sind das Sternchen (*) und das Dollarzeichen ($).
- * ist ein Platzhalter, der eine beliebige Folge von Zeichen darstellt.
- $ entspricht dem Ende von URL
Google bietet hier eine große Liste möglicher Syntax und Beispiele für den Mustervergleich.
Wohin geht robots.txt auf einer Website?
Suchmaschinen und andere Web-Crawler-Roboter (wie Facebooks Crawler Facebot) müssen immer nach einer robots.txt-Datei suchen, wenn sie auf eine Website gelangen. Sie suchen diese Datei jedoch nur an einem bestimmten Ort: im Hauptverzeichnis (normalerweise Ihrer Stammdomäne oder Homepage). Wenn ein Benutzeragent www.example.com/robots.txt besucht und dort keine Robots-Datei findet, geht er davon aus, dass die Site keine hat, und durchsucht dann alles auf der Seite (und möglicherweise sogar auf der gesamten Site). Selbst wenn die robots.txt-Seite beispielsweise unter example.com/index/robots.txt oder www.example.com/homepage/robots.txt vorhanden wäre, würde sie von Benutzeragenten nicht entdeckt und somit die Site behandelt Als ob es überhaupt keine Roboterdatei gäbe.
Um sicherzustellen, dass Ihre robots.txt-Datei gefunden wird, fügen Sie sie immer in Ihr Hauptverzeichnis oder Ihre Stammdomäne ein.
Warum tun Sie das? Benötigen Sie robots.txt?
Robots.txt-Dateien steuern den Crawlerzugriff auf bestimmte Bereiche Ihrer Site. Dies kann sehr gefährlich sein, wenn Sie Googlebot versehentlich daran hindern, Ihre gesamte Website zu crawlen (!!). In einigen Situationen kann eine robots.txt-Datei jedoch sehr praktisch sein.
Einige häufige Anwendungsfälle sind:
- Verhindern, dass doppelte Inhalte in SERPs angezeigt werden (beachten Sie, dass Metaroboter häufig die bessere Wahl sind)
- Halten Sie ganze Abschnitte einer Website privat (z. B. Ihr Engineering) Staging-Site des Teams)
- Verhindern, dass interne Suchergebnisseiten auf einem öffentlichen SERP angezeigt werden
- Festlegen des Speicherorts von Sitemap (s)
- Verhindern, dass Suchmaschinen indiziert werden Bestimmte Dateien auf Ihrer Website (Bilder, PDFs usw.)
- Festlegen einer Durchforstungsverzögerung, um zu verhindern, dass Ihre Server überlastet werden, wenn Crawler mehrere Inhalte gleichzeitig laden
Wenn es auf Ihrer Site keine Bereiche gibt, auf die Sie den Benutzeragentenzugriff steuern möchten, benötigen Sie möglicherweise überhaupt keine robots.txt-Datei.
Überprüfen Sie, ob Sie einen Roboter haben s.txt-Datei
Sie sind sich nicht sicher, ob Sie eine robots.txt-Datei haben? Geben Sie einfach Ihre Stammdomäne ein und fügen Sie am Ende der URL /robots.txt hinzu. Die Roboterdatei von Moz befindet sich beispielsweise unter moz.com/robots.txt.
Wenn keine TXT-Seite angezeigt wird, verfügen Sie derzeit nicht über eine (Live-) Robots.txt-Seite.
So erstellen Sie eine robots.txt-Datei
Wenn Sie festgestellt haben, dass Sie keine robots.txt-Datei hatten oder Ihre ändern möchten, ist das Erstellen einer solchen Datei ein einfacher Vorgang. In diesem Artikel von Google wird der Erstellungsprozess der robots.txt-Datei beschrieben. Mit diesem Tool können Sie testen, ob Ihre Datei korrekt eingerichtet ist.
Suchen Sie nach einer Übung zum Erstellen von Robots-Dateien?In diesem Blog-Beitrag werden einige interaktive Beispiele vorgestellt.
Best Practices für SEO
-
Stellen Sie sicher, dass Sie keine Inhalte oder Abschnitte Ihrer Website blockieren, die gecrawlt werden sollen.
-
Links auf Seiten, die von robots.txt blockiert wurden, werden nicht verfolgt. Dies bedeutet 1.) Sofern sie nicht auch von anderen suchmaschinenzugänglichen Seiten verlinkt werden (d. H. Seiten, die nicht über robots.txt, Metaroboter oder auf andere Weise blockiert wurden), werden die verknüpften Ressourcen nicht gecrawlt und möglicherweise nicht indiziert. 2.) Von der blockierten Seite kann kein Link-Eigenkapital an das Link-Ziel übergeben werden. Wenn Sie Seiten haben, an die Eigenkapital übergeben werden soll, verwenden Sie einen anderen Blockierungsmechanismus als robots.txt.
-
Verwenden Sie robots.txt nicht, um vertrauliche Daten zu verhindern (z private Benutzerinformationen) werden nicht in den SERP-Ergebnissen angezeigt. Da andere Seiten möglicherweise direkt auf die Seite mit privaten Informationen verweisen (wodurch die Anweisungen robots.txt in Ihrer Stammdomäne oder Homepage umgangen werden), wird sie möglicherweise weiterhin indiziert. Wenn Sie Ihre Seite für Suchergebnisse blockieren möchten, verwenden Sie eine andere Methode wie den Kennwortschutz oder die Meta-Direktive noindex.
-
Einige Suchmaschinen verfügen über mehrere Benutzeragenten. Beispielsweise verwendet Google Googlebot für die organische Suche und Googlebot-Image für die Bildsuche. Die meisten Benutzeragenten derselben Suchmaschine folgen denselben Regeln, sodass keine Anweisungen für jeden der mehreren Crawler einer Suchmaschine angegeben werden müssen. Wenn Sie dies jedoch tun können, können Sie die Art und Weise, wie der Inhalt Ihrer Website gecrawlt wird, optimieren.
-
Eine Suchmaschine speichert den Inhalt von robots.txt zwischen, aktualisiert den zwischengespeicherten Inhalt jedoch normalerweise mindestens einmal am Tag. Wenn Sie die Datei ändern und sie schneller als möglich aktualisieren möchten, können Sie Ihre robots.txt-URL an Google senden.
Robots.txt vs meta robots vs x -robots
So viele Roboter! Was ist der Unterschied zwischen diesen drei Arten von Roboteranweisungen? Zunächst einmal ist robots.txt eine tatsächliche Textdatei, während Meta und X-Robots Meta-Direktiven sind. Über das hinaus, was sie tatsächlich sind, erfüllen alle drei unterschiedliche Funktionen. Robots.txt bestimmt das Site- oder verzeichnisweite Crawling-Verhalten, während Meta- und X-Robots das Indexierungsverhalten auf der Ebene der einzelnen Seiten (oder Seitenelemente) bestimmen können.
Lernen Sie weiter
- Roboter-Meta-Richtlinien
- Kanonisierung
- Umleitung
- Roboter-Ausschlussprotokoll
Setzen Sie Ihre Fähigkeiten ein
Moz Pro kann feststellen, ob Ihre robots.txt-Datei unseren Zugriff auf Ihre Website blockiert. Probieren Sie es aus > >
