Co je soubor robots.txt?
Robots.txt je textový soubor, který webmasteři vytvářejí, aby instruovali webové roboty ( obvykle roboti vyhledávačů), jak procházet stránky na jejich webu. Soubor robots.txt je součástí protokolu Robots Exclusion Protocol (REP), což je skupina webových standardů, které regulují, jak roboti procházejí web, přistupují k němu a indexují jej a poskytují tento obsah uživatelům. REP obsahuje také směrnice, jako jsou meta roboty, a také pokyny pro stránku, podadresář nebo celý web, jak mají vyhledávače zacházet s odkazy (například „následovat“ nebo „nofollow“).
V v praxi soubory robots.txt ukazují, zda určité uživatelské agenty (software pro procházení webu) mohou nebo nemohou procházet části webových stránek. Tyto pokyny pro procházení jsou specifikovány „zakázáním“ nebo „povolením“ chování určitých (nebo všech) uživatelských agentů.
Základní formát:
User-agent: Disallow:
Tyto dva řádky jsou společně považovány za kompletní soubor robots.txt – i když jeden soubor robotů může obsahovat více řádků uživatelských agentů a směrnic (tj. zakazuje, povoluje, procházení, zpoždění atd.).
V souboru robots.txt se každá sada direktiv uživatelských agentů jeví jako samostatná sada oddělená zalomením řádku:
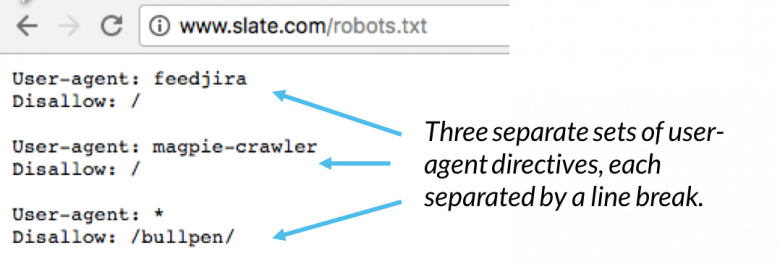
V souboru robots.txt s více direktivami user-agent platí každé pravidlo zakázat nebo povolit pouze pro agenta uživatele ( s) uvedené v konkrétní sadě oddělené řádky. Pokud soubor obsahuje pravidlo, které platí pro více než jednoho agenta uživatele, prohledávač věnuje pozornost (a bude postupovat podle pokynů) nejkonkrétnější skupiny pokynů.
Zde je příklad:
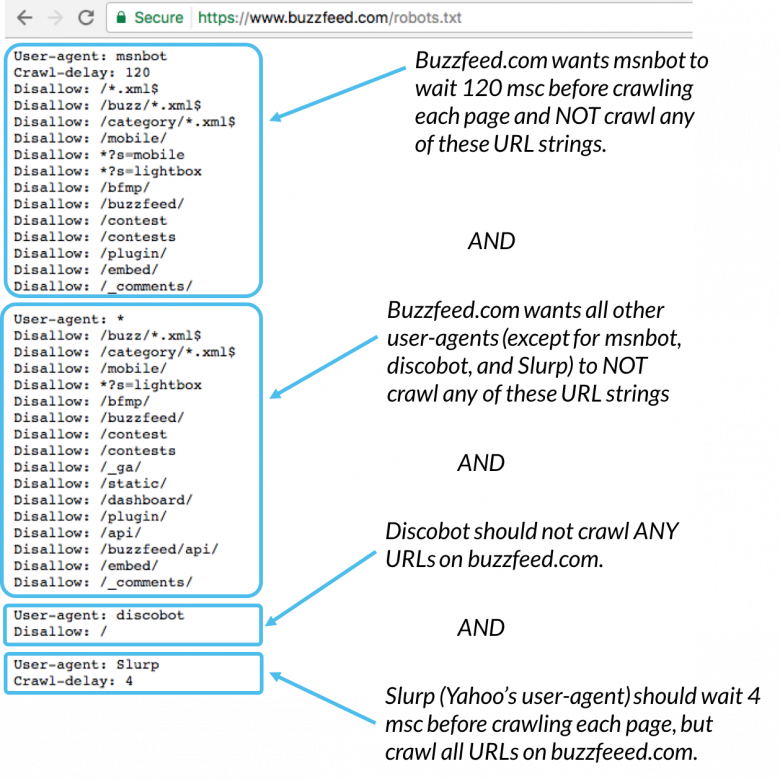
Všichni se nazývají Msnbot, discobot a Slurp konkrétně, takže tito uživatelští agenti budou věnovat pozornost pouze směrnicím v jejich částech souboru robots.txt. Všichni ostatní user-agenti se budou řídit pokyny ve skupině user-agent: *.
Příklad robots.txt:
Zde je několik příkladů robots.txt v akci pro web www.example.com:
URL souboru Robots.txt: www.example.com/robots.txt
blokování všech webových prohledávačů z veškerého obsahu
User-agent: * Disallow: /
Použití této syntaxe v souboru robots.txt by všem webovým prohledávačům řeklo, aby neprocházely žádné stránky na www.example.com, včetně domovské stránky.
Povolení všechny webové prohledávače přístup k veškerému obsahu
User-agent: * Disallow:
Použití této syntaxe v souboru robots.txt řekne webovým prohledávačům, aby prolezly všechny stránky na www.example.com, včetně domovskou stránku.
Blokování konkrétního webového prohledávače ze konkrétní složky
User-agent: Googlebot Disallow: /example-subfolder/
Tato syntaxe říká pouze prohledávači Google (název agenta Googlebot) ) neprocházet žádné stránky, které obsahují řetězec URL www.example.com/example-subfolder/.
Blokování konkrétního webového prohledávače z konkrétní webové stránky
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Tato syntaxe říká pouze prohledávači Bing (název agenta Bing), aby se vyhnul procházení konkrétní stránky na adrese www.example.com/example-subfolder/blocked-page .html.
Jak funguje soubor robots.txt?
Vyhledávače mají dvě hlavní úlohy:
- Procházení webu za účelem objevování obsahu;
- Indexování tohoto obsahu, aby mohl být poskytován vyhledávačům, kteří hledají informace.
Chcete-li procházet weby, vyhledávací stroje sledují odkazy, aby se dostaly z jednoho webu na druhý – nakonec procházení napříč mnoha miliardami odkazů a webových stránek. Toto chování při procházení se někdy označuje jako „spidering“.
Po příchodu na web, ale před jeho spiderem, prohledávací prohledávač vyhledá soubor robots.txt. Pokud takový soubor najde, přečte jej Před pokračováním stránkou nejprve soubor. Protože soubor robots.txt obsahuje informace o tom, jak má vyhledávač procházet, nalezené informace budou instruovat další akci prohledávače na tomto konkrétním webu. Pokud soubor robots.txt neobsahuje žádné směrnice, které zakáže aktivitu agenta uživatele (nebo pokud web nemá soubor robots.txt), bude pokračovat v procházení dalších informací na webu.
Ostatní rychlé soubory robots.txt musí znát:
(podrobněji popsáno níže)
-
Aby bylo možné soubor najít, musí být soubor robots.txt umístěn v adresáři nejvyšší úrovně webu.
-
V souboru Robots.txt se rozlišují velká a malá písmena: soubor musí mít název „robots.txt“ (nikoli Robots.txt, robots.TXT nebo jiný).
-
Někteří uživatelští agenti (roboti) m můžete se rozhodnout ignorovat soubor robots.txt. To je obzvláště běžné u hanebnějších prohledávačů, jako jsou roboti škodlivého softwaru nebo škrabky e-mailových adres.
-
Soubor /robots.txt je veřejně dostupný: stačí přidat /robots.txt na konec kterékoli kořenové domény, abyste viděli směrnice tohoto webu (pokud tento web obsahuje soubor robots.txt!).To znamená, že kdokoli může vidět, jaké stránky procházíte nebo nechcete procházet, takže je nepoužívejte ke skrytí soukromých informací o uživateli.
-
Každá subdoména v kořenovém adresáři doména používá samostatné soubory robots.txt. To znamená, že blog.example.com i example.com by měly mít své vlastní soubory robots.txt (na blog.example.com/robots.txt a example.com/robots.txt).
-
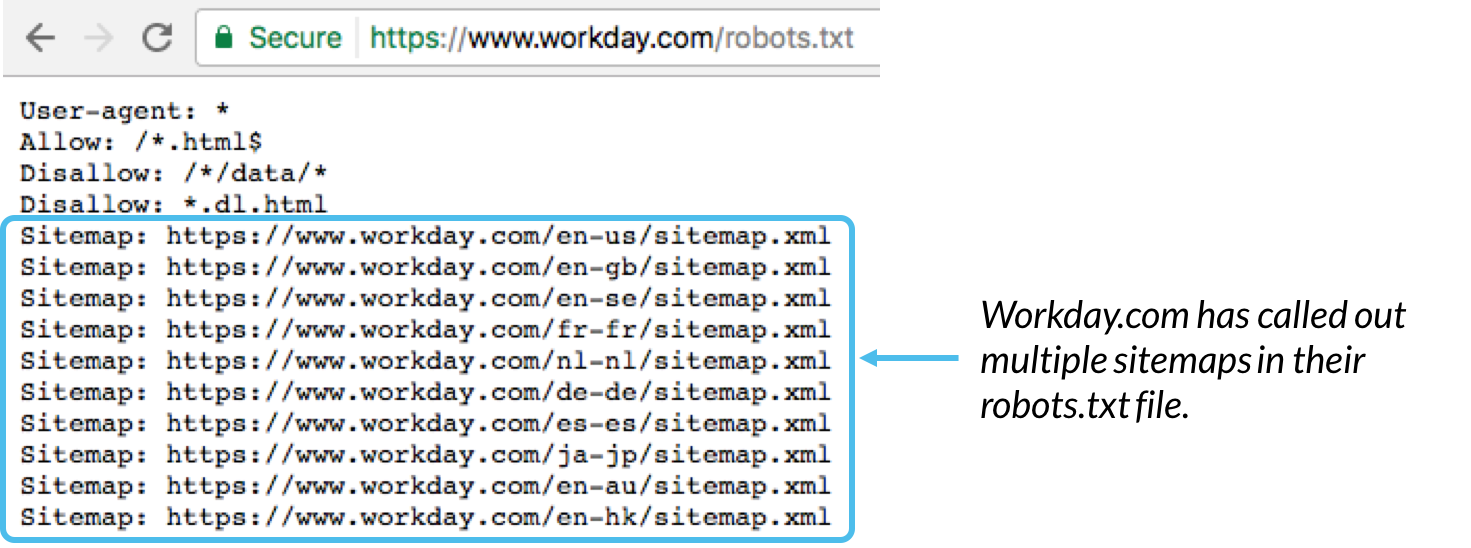
Osvědčeným postupem je obecně označit umístění všech souborů Sitemap přidružených k této doméně v dolní části souboru robots.txt. Zde je příklad:
Technická syntaxe robots.txt
Syntaxi robots.txt lze považovat za „jazyk“ souborů robots.txt. Existuje pět běžných výrazů, se kterými se v robotech pravděpodobně setkáte Soubor: Zahrnují:
-
User-agent: Konkrétní webový prohledávač, kterému dáváte pokyny k procházení (obvykle vyhledávač). Seznam většiny uživatelských agentů naleznete zde.
-
Zakázat: Příkaz používaný k tomu, aby uživatelský agent prohledával konkrétní adresu URL. Pro každou adresu URL je povolen pouze jeden řádek „Zakázat:“.
-
Povolit (Platí pouze pro Googlebota): Příkaz, který robotovi Googlebot říká, že má přístup na stránku nebo podsložku, i když její nadřazená stránka nebo podsložka může být zakázána.
-
Zpoždění procházení: Kolik sekund má prohledávač počkat před načtením a procházením obsahu stránky. Upozorňujeme, že Googlebot tento příkaz neuznává, ale lze nastavit rychlost procházení i n Google Search Console.
-
Soubor Sitemap: Používá se k vyvolání umístění libovolného souboru Sitemap XML spojeného s touto adresou URL. Tento příkaz podporují pouze Google, Ask, Bing a Yahoo.
Porovnávání vzorů
Pokud jde o skutečné adresy URL, které chcete blokovat nebo povolit, soubory robots.txt mohou být poměrně složité, protože umožňují použití porovnávání vzorů k pokrytí řady možných možností adres URL. Google i Bing ctí dva regulární výrazy, které lze použít k identifikaci stránek nebo podsložek, které chce SEO vyloučit. Tyto dva znaky jsou hvězdička (*) a znak dolaru ($).
- * je zástupný znak, který představuje libovolnou posloupnost znaků
- $ odpovídá konci znaku URL
Google zde nabízí skvělý seznam možných syntaxí shody vzorů a příklady.
Kam jde soubor robots.txt na web?
Kdykoli přijdou na web, vyhledávače a další roboti prohledávající web (jako prohledávač Facebooku, Facebot) vědí, že hledají soubor robots.txt. Tento soubor však budou hledat pouze na jednom konkrétním místě: hlavním adresáři (obvykle kořenové doméně nebo domovské stránce). Pokud uživatelský agent navštíví www.example.com/robots.txt a nenajde tam soubor robotů, bude předpokládat, že web žádný nemá a bude pokračovat v procházení všeho na stránce (a možná i na celém webu). I kdyby stránka robots.txt skutečně existovala na, řekněme example.com/index/robots.txt nebo www.example.com/homepage/robots.txt, uživatelští agenti by ji nezjistili, a proto by se s webem zacházelo jako by vůbec neměl žádný soubor robotů.
Abyste zajistili, že bude soubor robots.txt nalezen, vždy jej zahrňte do svého hlavního adresáře nebo kořenové domény.
Proč potřebujete soubor robots.txt?
Soubory robots.txt řídí přístup prohledávače do určitých oblastí vašeho webu. I když to může být velmi nebezpečné, pokud omylem nedovolíte robotu Googlebot procházet celý váš web (!!), v některých případech může být soubor robots.txt velmi užitečný.
Mezi běžné případy použití patří:
- Zabránění tomu, aby se v SERPs objevil duplicitní obsah (všimněte si, že meta roboti jsou pro to často lepší volbou)
- Udržování celých částí webu v soukromí (například vaše inženýrství pracovní web týmu)
- Zabránění zobrazování interních stránek s výsledky vyhledávání na veřejném SERP
- Zadání umístění souborů Sitemap
- Zabránění indexování vyhledávačů určité soubory na vašem webu (obrázky, soubory PDF atd.)
- Zadání prodlevy procházení, aby se zabránilo přetížení serverů, když prohledávače načtou více částí obsahu najednou
Pokud na vašem webu nejsou žádné oblasti, do kterých chcete ovládat přístup agenta uživatele, možná nebudete vůbec potřebovat soubor robots.txt.
Kontrola, zda máte robota soubor s.txt
Nejste si jisti, zda máte soubor robots.txt? Jednoduše zadejte kořenovou doménu a na konec adresy URL přidejte soubor /robots.txt. Například soubor robotů Moz je umístěn na moz.com/robots.txt.
Pokud se neobjeví žádná stránka .txt, aktuálně nemáte (živou) stránku robots.txt.
Jak vytvořit soubor robots.txt
Pokud jste zjistili, že nemáte soubor robots.txt nebo chcete změnit svůj, je vytvoření jednoduchého procesu. Tento článek od Googlu prochází procesem vytváření souborů robots.txt a tento nástroj vám umožňuje otestovat, zda je váš soubor nastaven správně.
Hledáte postup při vytváření souborů robotů?Tento příspěvek v blogu prochází několika interaktivními příklady.
Doporučené postupy pro SEO
-
Ujistěte se, že neblokujete žádný obsah ani části svého webu, které chcete procházet.
-
Odkazy na stránky blokované souborem robots.txt nebudou sledovány. To znamená 1.) Pokud nebudou odkazovány také z jiných stránek přístupných pro vyhledávače (tj. Stránky neblokované prostřednictvím souboru robots.txt, meta roboty apod.), Propojené zdroje nebudou procházeny a nebudou indexovány. 2.) Ze zablokované stránky do cíle odkazu nelze přenést žádný kapitál na odkazy. Pokud máte stránky, na které chcete předat kapitál, použijte jiný blokovací mechanismus než robots.txt.
-
Nepoužívejte soubor robots.txt k prevenci citlivých dat (například informace o soukromém uživateli) z výsledků ve SERP. Protože jiné stránky mohou odkazovat přímo na stránku obsahující soukromé informace (čímž obcházejí direktivy robots.txt ve vaší kořenové doméně nebo domovské stránce), může se stále indexovat. Chcete-li zablokovat stránku ve výsledcích vyhledávání, použijte jinou metodu, například ochranu heslem nebo meta direktivu noindex.
-
Některé vyhledávače mají více uživatelských agentů. Google například používá Googlebot pro organické vyhledávání a Googlebot-Image pro vyhledávání obrázků. Většina uživatelských agentů ze stejného vyhledávače se řídí stejnými pravidly, takže není třeba určovat směrnice pro každý z více prohledávacích modulů vyhledávače, ale schopnost tak učinit vám umožní doladit způsob procházení obsahu vašeho webu.
-
Vyhledávací stroj uloží obsah robots.txt do mezipaměti, ale obsah v mezipaměti obvykle aktualizuje alespoň jednou denně. Pokud soubor změníte a chcete jej aktualizovat rychleji, než k jakému dochází, můžete odeslat adresu URL robots.txt společnosti Google.
Robots.txt vs meta robots vs x -roboti
Tolik robotů! Jaký je rozdíl mezi těmito třemi typy robotických pokynů? Za prvé, robots.txt je skutečný textový soubor, zatímco meta a x-robots jsou meta direktivy. Kromě toho, co ve skutečnosti jsou, mají všechny tři různé funkce. Soubor robots.txt určuje chování procházení webu nebo celého adresáře, zatímco roboti meta a x mohou určovat chování indexace na úrovni jednotlivé stránky (nebo prvku stránky).
Pokračujte v učení
- Směrnice pro roboty Meta
- Kanonizace
- Přesměrování
- Protokol pro vyloučení robotů
Využijte své dovednosti
Moz Pro dokáže zjistit, zda váš soubor robots.txt blokuje náš přístup na váš web. Vyzkoušejte > >
