Ce este un fișier robots.txt?
Robots.txt este un fișier text creat de webmasteri pentru a instrui roboții web ( de obicei roboți ai motoarelor de căutare) cum să acceseze cu crawlere paginile de pe site-ul lor web. Fișierul robots.txt face parte din protocolul de excludere a roboților (REP), un grup de standarde web care reglementează modul în care roboții accesează cu crawlere webul, accesează și indexează conținutul și servesc acel conținut până la utilizatori. REP include, de asemenea, directive, cum ar fi meta-roboți, precum și instrucțiuni la nivel de pagină, subdirector sau site-ul pentru modul în care motoarele de căutare ar trebui să trateze linkurile (cum ar fi „urmați” sau „nofollow”).
În practică, fișierele robots.txt indică dacă anumiți agenți de utilizator (software de accesare cu crawlere web) pot sau nu accesarea cu crawlere a unor părți ale unui site web. Aceste instrucțiuni de accesare cu crawlere sunt specificate prin „interzicerea” sau „permiterea” comportamentului anumitor (sau a tuturor) agenților utilizator.
Format de bază:
User-agent: Disallow:
Împreună, aceste două linii sunt considerate un fișier complet robots.txt – deși un fișier robot poate conține mai multe linii de agenți de utilizatori și directive (de exemplu, interzice, permite, întârzieri cu crawlere etc.).
În cadrul unui fișier robots.txt, fiecare set de directive utilizator-agent apare ca un set discret, separat printr-o întrerupere de linie:
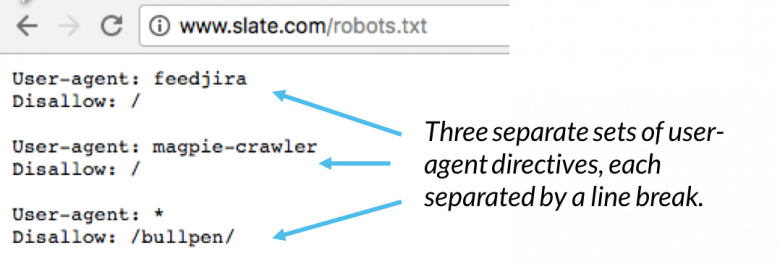
Într-un fișier robots.txt cu mai multe directive user-agent, fiecare regulă de interzicere sau permisie se aplică doar agentului utilizator ( s) specificate în acel set de linii separate. Dacă fișierul conține o regulă care se aplică mai multor utilizatori-agent, un crawler va acorda atenție (și va urma directivele) numai celui mai specific grup de instrucțiuni.
Iată un exemplu:
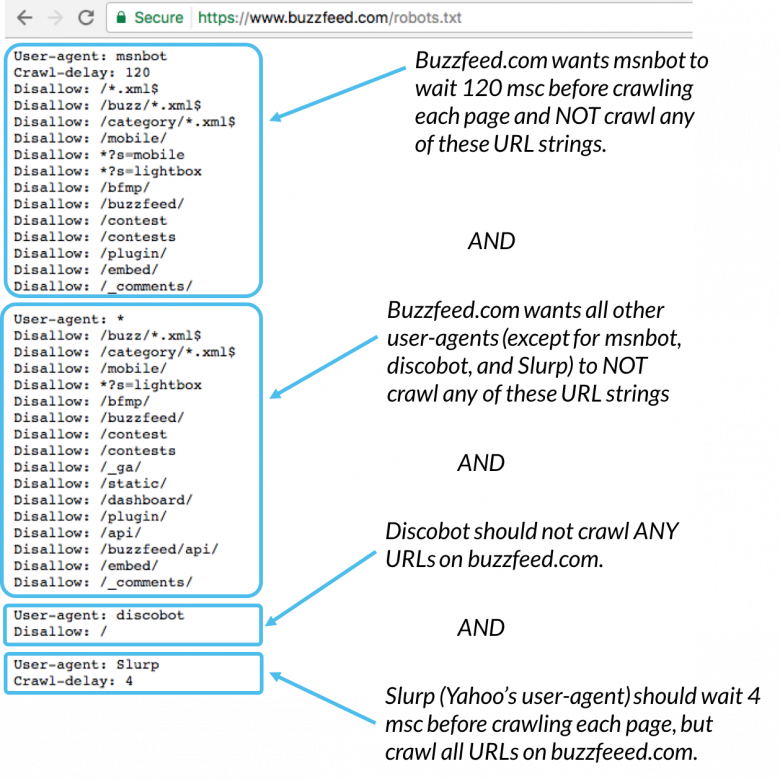
Msnbot, discobot și Slurp sunt toate numite în mod specific, astfel încât acei utilizatori-agenți să acorde atenție doar directivelor din secțiunile lor din fișierul robots.txt. Toți ceilalți agenți utilizator vor urma directivele din grupul utilizator-agent: *.
Exemplu robots.txt:
Iată câteva exemple de robots.txt în acțiune pentru un Site-ul www.example.com:
Adresa URL a fișierului Robots.txt: www.example.com/robots.txt
Blocarea tuturor crawlerelor web din tot conținutul
User-agent: * Disallow: /
Utilizarea acestei sintaxi într-un fișier robots.txt le-ar spune tuturor crawlerelor web să nu acceseze cu crawlere nicio pagină de pe www.example.com, inclusiv pagina de pornire.
Permiterea accesul tuturor crawlerelor web la tot conținutul
User-agent: * Disallow:
Utilizarea acestei sintaxe într-un fișier robots.txt le permite crawlerelor web să acceseze cu crawlere toate paginile de pe www.example.com, inclusiv pagina de pornire.
Blocarea unui anumit crawler web dintr-un anumit folder
User-agent: Googlebot Disallow: /example-subfolder/
Această sintaxă indică numai crawlerul Google (numele agentului utilizator Googlebot ) să nu acceseze cu crawlere paginile care conțin șirul URL www.example.com/example-subfolder/.
Blocarea unui anumit crawler web dintr-o anumită pagină web
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Această sintaxă spune numai crawlerului Bing (numele utilizatorului agent Bing) să evite accesarea cu crawlere a paginii specifice la www.example.com/example-subfolder/blocked-page .html.
Cum funcționează robots.txt?
Motoarele de căutare au două lucrări principale:
- Crawlere pe web pentru a descoperi conținut;
- Indexarea conținutului respectiv, astfel încât să poată fi difuzat către căutătorii care caută informații.
Pentru accesarea cu crawlere a site-urilor, motoarele de căutare urmează linkuri pentru a ajunge de la un site la altul – în cele din urmă, accesând cu crawlere pe mai multe miliarde de linkuri și site-uri web. Acest comportament de accesare cu crawlere este uneori cunoscut sub numele de „spidering”.
După ce a ajuns la un site web, dar înainte de a-l pătrunde, crawlerul de căutare va căuta un fișier robots.txt. Dacă găsește unul, crawlerul va citi că fișierul mai întâi înainte de a continua pagina. Deoarece fișierul robots.txt conține informații despre modul în care motorul de căutare ar trebui să acceseze cu crawlere, informațiile găsite acolo vor instrui acțiunea ulterioară a crawlerului pe acest site. interzice activitatea unui agent de utilizator (sau dacă site-ul nu are un fișier robots.txt), acesta va continua să acceseze cu crawlere alte informații de pe site.
Alte informații despre robots.txt rapide:
(discutat mai detaliat mai jos)
-
Pentru a fi găsit, un fișier robots.txt trebuie plasat în directorul de nivel superior al unui site web.
-
Robots.txt este sensibil la majuscule și minuscule: fișierul trebuie să fie denumit „robots.txt” (nu Robots.txt, robots.TXT sau altfel).
-
Unii agenți utilizator (roboți) m alegeți să ignorați fișierul robots.txt. Acest lucru este frecvent întâlnit în special cu crawlerele mai nefaste, cum ar fi roboții malware sau dispozitivele de eliminare a adreselor de e-mail.
-
Fișierul /robots.txt este disponibil public: trebuie doar să adăugați /robots.txt la final din orice domeniu rădăcină pentru a vedea directivele acelui site web (dacă acel site are un fișier robots.txt!).Aceasta înseamnă că oricine poate vedea ce pagini faceți sau nu doriți să fie accesate cu crawlere, așa că nu le folosiți pentru a ascunde informațiile de utilizator privat.
-
Fiecare subdomeniu dintr-o rădăcină domeniul folosește fișiere robots.txt separate. Aceasta înseamnă că atât blog.example.com, cât și example.com ar trebui să aibă propriile fișiere robots.txt (la blog.example.com/robots.txt și example.com/robots.txt).
-
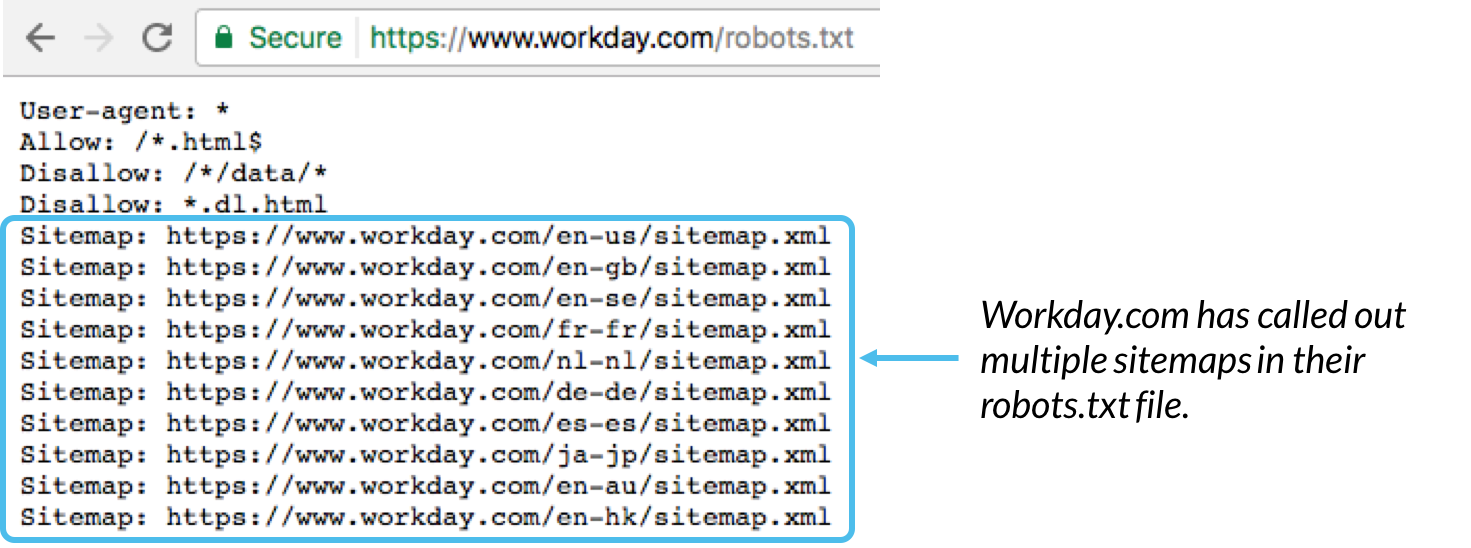
În general, este o bună practică să indicați locația oricăror sitemap-uri asociate cu acest domeniu în partea de jos a fișierului robots.txt. Iată un exemplu:
Sintaxa tehnică robots.txt
Sintaxa Robots.txt poate fi considerată „limbajul” fișierelor robots.txt. Există cinci termeni comuni pe care probabil îi întâlniți într-un robot fișier. Acestea includ:
-
User-agent: crawlerul web specific căruia îi dați instrucțiuni de crawlere (de obicei un motor de căutare). Puteți găsi o listă cu majoritatea agenților utilizator aici.
-
Disallow: Comanda utilizată pentru a spune unui utilizator-agent să nu acceseze cu crawlere o anumită adresă URL. Este permisă o singură linie „Disallow:” pentru fiecare adresă URL.
-
Permite (aplicabil numai pentru Googlebot): comanda pentru a spune Googlebot că poate accesa o pagină sau un subfolder, chiar dacă pagina sau subfolderul său părinte poate fi interzis.
-
Crawl-delay: Câte secunde ar trebui să aștepte un crawler înainte de încărcarea și accesarea cu crawlere a conținutului paginii. Rețineți că Googlebot nu recunoaște această comandă, dar rata de crawl poate fi setată i n Google Search Console.
-
Sitemap: folosit pentru a apela locația oricărui sitemap XML asociat cu această adresă URL. Rețineți că această comandă este acceptată numai de Google, Ask, Bing și Yahoo.
Potrivirea modelelor
Când vine vorba de blocarea adreselor URL reale sau permiteți, fișierele robots.txt pot deveni destul de complexe, deoarece permit utilizarea potrivirii modelelor pentru a acoperi o serie de opțiuni URL posibile. Google și Bing respectă ambele expresii regulate care pot fi utilizate pentru a identifica pagini sau subfoldere pe care un SEO le dorește excluse. Aceste două caractere sunt asteriscul (*) și semnul dolarului ($).
- * este un wildcard care reprezintă orice secvență de caractere
- $ se potrivește cu sfârșitul URL
Google oferă aici o listă excelentă de posibile sintaxe și exemple de potrivire a modelelor.
Unde merge robot.txt pe un site?
Ori de câte ori ajung pe un site, motoarele de căutare și alți roboți care accesează cu crawlere web (cum ar fi crawlerul Facebook, Facebot) știu să caute un fișier robots.txt. Dar vor căuta fișierul numai într-un anumit loc: directorul principal (de obicei domeniul rădăcină sau pagina principală). Dacă un agent de utilizator vizitează www.example.com/robots.txt și nu găsește un fișier robot acolo, va presupune că site-ul nu are unul și va continua cu accesarea cu crawlere a tuturor paginilor (și poate chiar a întregului site). Chiar dacă pagina robots.txt ar exista la, să zicem, example.com/index/robots.txt sau www.example.com/homepage/robots.txt, aceasta nu ar fi descoperită de către agenții utilizator și astfel site-ul ar fi tratat ca și cum nu ar avea deloc fișier roboți.
Pentru a vă asigura că fișierul dvs. robots.txt este găsit, includeți-l întotdeauna în directorul principal sau în domeniul rădăcină.
De ce aveți nevoie de robots.txt?
Fișierele Robots.txt controlează accesul crawlerului la anumite zone ale site-ului dvs. Deși acest lucru poate fi foarte periculos dacă nu permiteți Googlebot să acceseze cu crawlere întregul site (!!), există câteva situații în care un fișier robots.txt poate fi foarte util.
Unele cazuri de utilizare obișnuite includ:
- Prevenirea apariției conținutului duplicat în SERP (rețineți că meta-roboții sunt adesea o alegere mai bună pentru acest lucru)
- Păstrarea secțiunilor întregi ale unui site privat (de exemplu, ingineria dvs. site-ul de etapă al echipei)
- Păstrarea paginilor de rezultate ale căutării interne să nu apară pe un SERP public
- Specificarea locației sitemap-urilor
- Prevenirea indexării motoarelor de căutare anumite fișiere de pe site-ul dvs. (imagini, PDF-uri etc.)
- Specificarea unei întârzieri de accesare cu crawlere pentru a preveni supraîncărcarea serverelor dvs. atunci când crawlerele încarcă mai multe conținuturi simultan
Dacă pe site-ul dvs. nu există zone în care doriți să controlați accesul utilizator-agent, este posibil să nu aveți deloc nevoie de un fișier robots.txt.
Verificarea dacă aveți un robot fișier s.txt
Nu sunteți sigur dacă aveți un fișier robots.txt? Pur și simplu introduceți domeniul rădăcină, apoi adăugați /robots.txt la sfârșitul adresei URL. De exemplu, fișierul roboților Moz se află la moz.com/robots.txt.
Dacă nu apare nicio pagină .txt, în prezent nu aveți o pagină robots.txt (live).
Cum să creați un fișier robots.txt
Dacă ați constatat că nu aveți un fișier robots.txt sau doriți să îl modificați, creați unul este un proces simplu. Acest articol de la Google trece prin procesul de creare a fișierului robots.txt, iar acest instrument vă permite să testați dacă fișierul dvs. este configurat corect.
Căutați practică în crearea fișierelor roboți?Această postare pe blog parcurge câteva exemple interactive.
Cele mai bune practici SEO
-
Asigurați-vă că nu blocați conținutul sau secțiunile site-ului dvs. web pe care doriți să le accesați cu crawlere.
-
Linkurile de pe paginile blocate de robots.txt nu vor fi urmărite. Aceasta înseamnă 1.) Dacă nu sunt conectate și din alte pagini accesibile motorului de căutare (adică pagini care nu sunt blocate prin robots.txt, meta-roboți sau altfel), resursele conectate nu vor fi accesate cu crawlere și s-ar putea să nu fie indexate. 2.) Nu se poate transmite nicio echitate de legătură de la pagina blocată la destinația legăturii. Dacă aveți pagini pe care doriți să le transmiteți echitatea, utilizați un alt mecanism de blocare, altul decât robots.txt.
-
Nu utilizați robots.txt pentru a preveni datele sensibile (cum ar fi informații despre utilizator privat) de la apariția în rezultatele SERP. Deoarece alte pagini pot face legătura direct cu pagina care conține informații private (ocolind astfel directivele robots.txt din domeniul dvs. rădăcină sau pagina principală), este posibil să fie totuși indexat. Dacă doriți să vă blocați pagina de rezultatele căutării, utilizați o metodă diferită, cum ar fi protecția prin parolă sau meta-directiva noindex.
-
Unele motoare de căutare au mai mulți utilizatori-agenți. De exemplu, Google folosește Googlebot pentru căutarea organică și Googlebot-Image pentru căutarea de imagini. Majoritatea agenților de utilizatori din același motor de căutare respectă aceleași reguli, astfel încât nu este necesar să specificați directive pentru fiecare dintre crawlerele multiple ale unui motor de căutare, dar posibilitatea de a face acest lucru vă permite să reglați cu precizie modul în care este accesat cu crawlere conținutul site-ului dvs.
-
Un motor de căutare va memora în cache conținutul robots.txt, dar de obicei actualizează conținutul în cache cel puțin o dată pe zi. Dacă modificați fișierul și doriți să îl actualizați mai repede decât se întâmplă, puteți trimite adresa URL robots.txt la Google.
Robots.txt vs meta robots vs x -roboti
Atât de mulți roboți! Care este diferența dintre aceste trei tipuri de instrucțiuni despre robot? În primul rând, robots.txt este un fișier text propriu-zis, în timp ce meta și robotii x sunt meta directive. Dincolo de ceea ce sunt de fapt, toate trei îndeplinesc funcții diferite. Robots.txt dictează comportamentul de accesare cu crawlere la nivel de site sau director, în timp ce meta-roboții și robotii x pot dicta comportamentul de indexare la nivel de pagină individuală (sau element de pagină).
Continuă să înveți
- Meta Directive pentru roboți
- Canonicalizare
- Redirecționare
- Protocol de excludere a roboților
Puneți-vă abilitățile la lucru
Moz Pro poate identifica dacă fișierul dvs. robots.txt ne blochează accesul la site-ul dvs. web. Încercați > >
