Hva er en robots.txt-fil?
Robots.txt er en tekstfil som nettredaktører lager for å instruere webroboter ( vanligvis søkemotorroboter) hvordan man skal gjennomsøke sider på nettstedet deres. Roboten.txt-filen er en del av robots ekskluderingsprotokollen (REP), en gruppe nettstandarder som regulerer hvordan roboter gjennomsøker nettet, får tilgang til og indekserer innhold, og serverer innholdet opp til brukerne. REP inkluderer også direktiver som metaroboter, samt side-, underkatalog- eller nettstedsinstruksjoner for hvordan søkemotorer skal behandle lenker (for eksempel «følg» eller «nofollow»).
I praksis, robots.txt-filer indikerer om visse brukeragenter (web-crawling software) kan eller ikke kan gjennomsøke deler av et nettsted. Disse gjennomsøkingsinstruksjonene er spesifisert ved å «ikke tillate» eller «tillate» atferden til visse (eller alle) brukeragenter.
Grunnleggende format:
User-agent: Disallow:
Til sammen blir disse to linjene betraktet som en komplett robots.txt-fil – selv om en robotfil kan inneholde flere linjer med brukeragenter og -direktiver (dvs. ikke tillater, tillater, gjennomgangsforsinkelser osv.).
Innen en robots.txt-fil vises hvert sett med brukeragentdirektiv som et diskret sett, atskilt med et linjeskift:
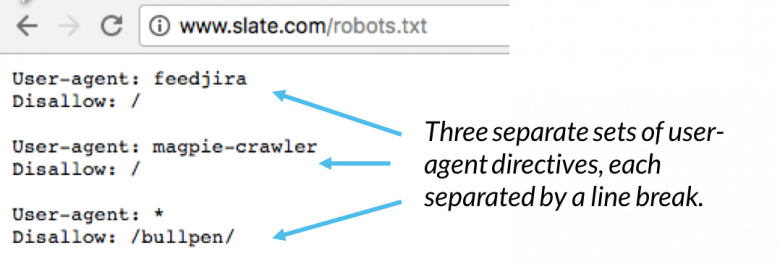
I en robots.txt-fil med flere brukeragentdirektiv, gjelder hver ikke-tillatelses- eller tillatelsesregel kun brukeragenten ( s) spesifisert i det spesifikke linjeskiftesettet. Hvis filen inneholder en regel som gjelder mer enn én brukeragent, vil en søkerobot bare ta hensyn til (og følge instruksjonene i) den mest spesifikke gruppen av instruksjoner.
Her er et eksempel:
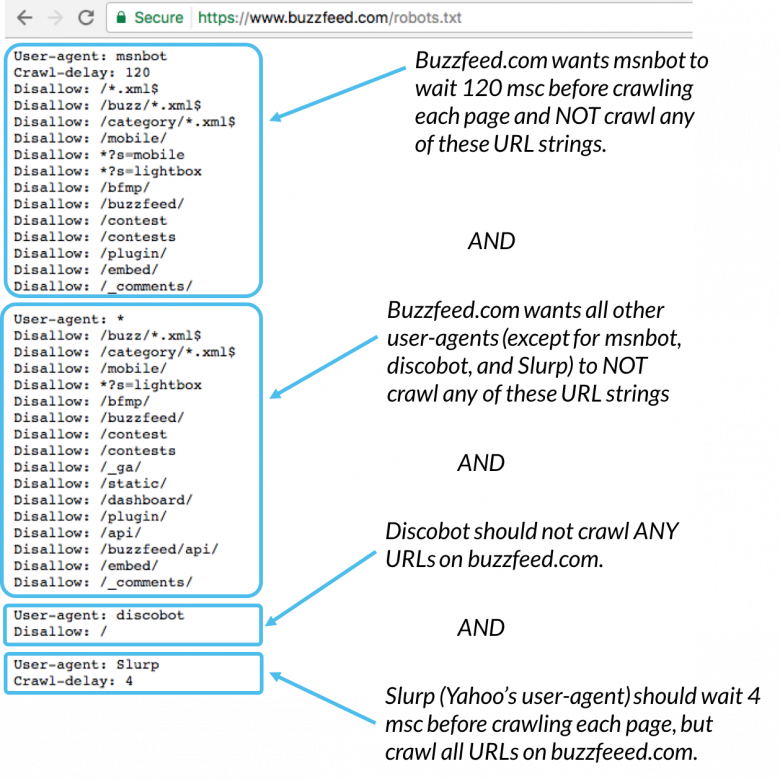
Msnbot, discobot og Slurp kalles alle spesifikt, slik at disse brukeragentene bare tar hensyn til direktivene i deres seksjoner av robots.txt-filen. Alle andre brukeragenter følger retningslinjene i brukeragenten: * -gruppen.
Eksempel på robots.txt:
Her er noen eksempler på robots.txt i aksjon for en www.example.com-nettsted:
Robots.txt-fil URL: www.example.com/robots.txt
Blokkerer alle web-crawlere fra alt innhold
User-agent: * Disallow: /
Hvis du bruker denne syntaksen i en robots.txt-fil, vil alle web-søkerobber ikke gjennomsøke noen sider på www.example.com, inkludert hjemmesiden.
Tillater all web-crawlere har tilgang til alt innhold
User-agent: * Disallow:
Ved å bruke denne syntaksen i en robots.txt-fil, blir web-crawlere bedt om å gjennomsøke alle sidene på www.example.com, inkludert hjemmesiden.
Blokkering av en bestemt nettleser fra en bestemt mappe
User-agent: Googlebot Disallow: /example-subfolder/
Denne syntaksen forteller bare Googles søkerobot (brukeragentens navn Googlebot ) ikke å gjennomsøke sider som inneholder URL-strengen www.example.com/example-subfolder/.
Blokkering av en spesifikk web-crawler fra en spesifikk webside
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Denne syntaksen forteller bare Bings søkerobot (brukeragentens navn Bing) for å unngå å gjennomsøke den spesifikke siden på www.example.com/example-subfolder/blocked-page .html.
Hvordan fungerer robots.txt?
Søkemotorer har to hovedjobber:
- Gjennomsøking på nettet for å oppdage innhold;
- Indeksere det innholdet slik at det kan serveres til søkere som leter etter informasjon.
For å gjennomsøke nettsteder følger søkemotorer lenker for å komme fra ett nettsted til et annet – til slutt, gjennomgang på tvers av mange milliarder lenker og nettsteder. Denne gjennomsøkingsatferden er noen ganger kjent som «spidering.»
Etter at du har kommet til et nettsted, men før du spider den, vil søkeroboten søke etter en robots.txt-fil. Hvis den finner en, vil søkeroboten lese den først før du fortsetter gjennom siden. Fordi robots.txt-filen inneholder informasjon om hvordan søkemotoren skal gjennomsøke, vil informasjonen du finner der, instruere videre crawlerhandlinger på dette nettstedet. Hvis robots.txt-filen ikke inneholder noen direktiver som tillat aktivitet fra en brukeragent (eller hvis nettstedet ikke har en robots.txt-fil), vil den fortsette å gjennomsøke annen informasjon på nettstedet.
Andre raske robots.txt-må-vite:
(diskutert mer detaljert nedenfor)
-
For å bli funnet, må en robots.txt-fil plasseres i nettstedets katalog på øverste nivå.
-
Robots.txt skiller mellom store og små bokstaver: filen må ha navnet «robots.txt» (ikke Robots.txt, robots.TXT eller annet).
-
Noen brukeragenter (roboter) m ay velger å ignorere robots.txt-filen. Dette er spesielt vanlig med mer skumle crawlere som malware-roboter eller e-postadresseskrapere.
-
/robots.txt-filen er en offentlig tilgjengelig: bare legg til /robots.txt til slutten av et hvilket som helst rotdomener for å se nettstedets direktiver (hvis nettstedet har en robots.txt-fil!).Dette betyr at alle kan se hvilke sider du gjør eller ikke vil bli gjennomsøkt, så ikke bruk dem til å skjule privat brukerinformasjon.
-
Hvert underdomener på en rot domenet bruker separate robots.txt-filer. Dette betyr at både blog.example.com og example.com skal ha sine egne robots.txt-filer (på blog.example.com/robots.txt og example.com/robots.txt).
-
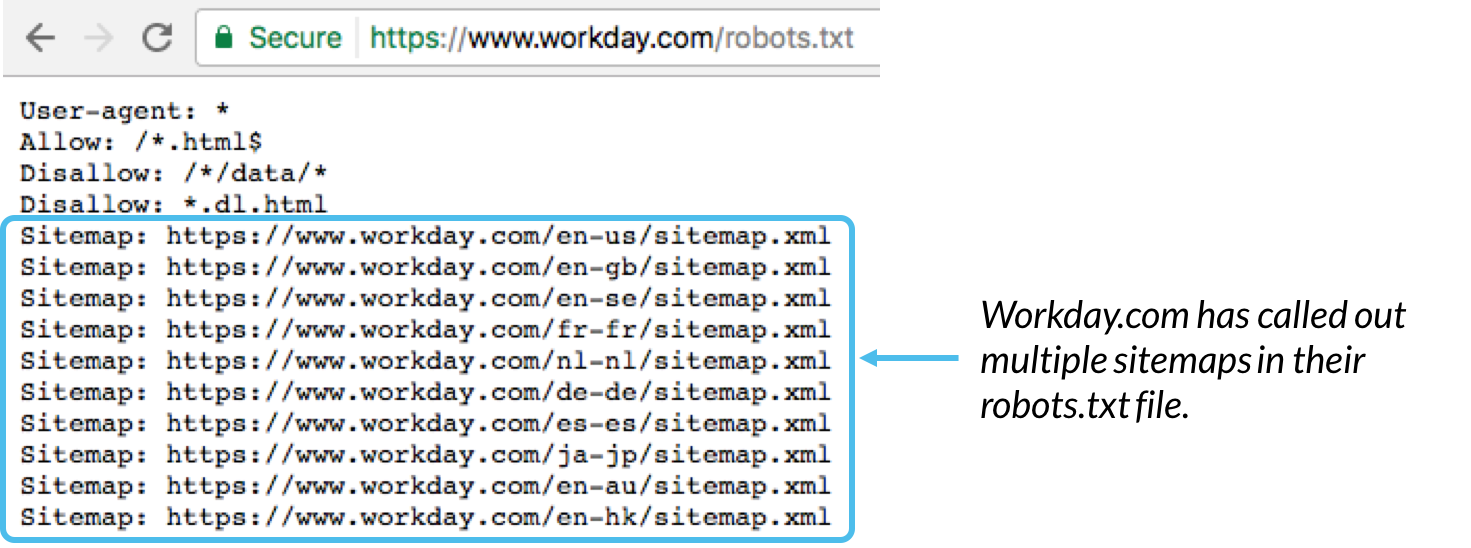
Det er vanligvis en god praksis å indikere plasseringen til eventuelle nettstedskart tilknyttet dette domenet nederst i robots.txt-filen. Her er et eksempel:
Syntaks for robots.txt
Syntaks for Robots.txt kan betraktes som «språket» for robots.txt-filer. Det er fem vanlige termer du sannsynligvis kommer over i roboter De inkluderer:
-
User-agent: Den spesifikke web-crawleren du gir gjennomsøkingsinstruksjoner til (vanligvis en søkemotor). En liste over de fleste brukeragentene finner du her.
-
Ikke tillat: Kommandoen som ble brukt til å fortelle en brukeragent om ikke å gjennomsøke en bestemt nettadresse. Bare én «Ikke tillat:» -linje er tillatt for hver nettadresse.
-
Tillat (gjelder bare for Googlebot): Kommandoen som forteller Googlebot at den kan få tilgang til en side eller undermappe, selv om den overordnede siden eller undermappen kan være tillatt.
-
Gjennomsøkingsforsinkelse: Hvor mange sekunder en søkerobot skal vente før sideinnhold lastes inn og gjennomsøkes. Vær oppmerksom på at Googlebot ikke anerkjenner denne kommandoen, men gjennomsøkningshastighet kan n Google Search Console.
-
Sitemap: Brukes til å ringe ut plasseringen til et XML-sitemap (er) som er tilknyttet denne URL-en. Merk at denne kommandoen bare støttes av Google, Ask, Bing og Yahoo.
Mønstermatching
Når det gjelder de faktiske nettadressene som skal blokkeres eller tillat, robots.txt-filer kan bli ganske kompliserte ettersom de tillater bruk av mønstermatching for å dekke en rekke mulige URL-alternativer. Google og Bing respekterer begge to vanlige uttrykk som kan brukes til å identifisere sider eller undermapper som en SEO ønsker ekskludert. Disse to tegnene er stjernen (*) og dollartegnet ($).
- * er et jokertegn som representerer en hvilken som helst sekvens av tegn
- $ samsvarer med slutten av URL
Google tilbyr en flott liste over mulige mønstermatchende syntakser og eksempler her.
Hvor går robots.txt på et nettsted?
Når de kommer til et nettsted, vet søkemotorer og andre nettgjennomføringsroboter (som Facebooks crawler, Facebot) å lete etter en robots.txt-fil. Men de vil bare se etter den filen på et bestemt sted: hovedkatalogen (vanligvis rotdomenet eller hjemmesiden din). Hvis en brukeragent besøker www.example.com/robots.txt og ikke finner en robotfil der, vil den anta at nettstedet ikke har en og fortsette med å gjennomsøke alt på siden (og kanskje til og med på hele nettstedet). Selv om robots.txt-siden eksisterte på eksempelvis.com/index/robots.txt eller www.example.com/homepage/robots.txt, ville den ikke bli oppdaget av brukeragenter, og dermed ville nettstedet bli behandlet som om den ikke hadde noen robotfil i det hele tatt.
For å sikre at robots.txt-filen din blir funnet, må du alltid inkludere den i hovedkatalogen eller rotdomenet.
Hvorfor gjør du det trenger robots.txt?
Robots.txt-filer kontrollerer gjennomsøkertilgang til bestemte områder på nettstedet ditt. Selv om dette kan være veldig farlig hvis du ved et uhell tillater Googlebot å gjennomsøke hele nettstedet ditt (!!), er det noen situasjoner der en robots.txt-fil kan være veldig nyttig.
Noen vanlige bruksområder inkluderer:
- Forhindre at duplikatinnhold vises i SERPer (merk at meta-roboter ofte er et bedre valg for dette)
- Å holde hele seksjoner på et nettsted private (for eksempel din engineering teamets iscenesettingsside)
- Å forhindre at interne søkeresultatsider vises på en offentlig SERP
- Spesifisere plasseringen til nettstedskart (er)
- Forhindre at søkemotorer indekserer bestemte filer på nettstedet ditt (bilder, PDF-filer osv.)
- Spesifiserer en gjennomsøkingsforsinkelse for å forhindre at serverne dine blir overbelastet når gjennomsøkere laster inn flere deler av innholdet samtidig
Hvis det ikke er noen områder på nettstedet du vil kontrollere brukeragenttilgang til, trenger du kanskje ikke en robots.txt-fil i det hele tatt.
Kontrollerer om du har en robot s.txt-fil
Er du ikke sikker på om du har en robots.txt-fil? Bare skriv inn rotdomenet ditt, og legg deretter til /robots.txt til slutten av URL-en. For eksempel ligger Mozs robots-fil på moz.com/robots.txt.
Hvis ingen .txt-side vises, har du for øyeblikket ikke en (live) robots.txt-side.
Hvordan lage en robots.txt-fil
Hvis du fant ut at du ikke hadde en robots.txt-fil eller vil endre din, er det enkelt å lage en. Denne artikkelen fra Google går gjennom prosessen med å opprette robots.txt, og dette verktøyet lar deg teste om filen din er konfigurert riktig.
Leter du etter noen øvelser med å lage roboter?Dette blogginnlegget går gjennom noen interaktive eksempler.
Beste fremgangsmåter for SEO
-
Forsikre deg om at du ikke blokkerer noe innhold eller deler av nettstedet du vil gjennomsøke.
-
Koblinger på sider blokkert av robots.txt følges ikke. Dette betyr 1.) Med mindre de også er lenket fra andre sider som er tilgjengelige for søkemotorer (dvs. sider som ikke er blokkert via robots.txt, metaroboter eller på annen måte), blir ikke de linkede ressursene gjennomsøkt og kan ikke indekseres. 2.) Ingen lenkekapital kan overføres fra den blokkerte siden til koblingsdestinasjonen. Hvis du har sider du vil overføre egenkapital til, bruk en annen blokkeringsmekanisme enn robots.txt.
-
Ikke bruk robots.txt for å forhindre sensitive data (som privat brukerinformasjon) fra å vises i SERP-resultater. Fordi andre sider kan lenke direkte til siden som inneholder privat informasjon (og dermed omgå robots.txt-direktivene på rotdomenet eller hjemmesiden din), kan den fremdeles bli indeksert. Hvis du vil blokkere siden din fra søkeresultatene, kan du bruke en annen metode som passordbeskyttelse eller noindex metadirektivet.
-
Noen søkemotorer har flere brukeragenter. For eksempel bruker Google Googlebot for organisk søk og Googlebot-Image for bildesøk. De fleste brukeragenter fra den samme søkemotoren følger de samme reglene, så det er ikke nødvendig å spesifisere retningslinjer for hver av søkemotorens flere gjennomsøkere, men hvis du har muligheten til det, kan du finjustere hvordan innholdet på nettstedet ditt blir gjennomsøkt. / p>
-
En søkemotor vil cache innholdet i robots.txt, men oppdaterer vanligvis hurtigbufret innhold minst en gang om dagen. Hvis du endrer filen og vil oppdatere den raskere enn det som skjer, kan du sende robots.txt-url til Google.
Robots.txt vs meta-robots vs x -roboter
Så mange roboter! Hva er forskjellen mellom disse tre typene robotinstruksjoner? For det første er robots.txt en faktisk tekstfil, mens meta og x-roboter er metadirektiv. Utover det de faktisk er, har de tre forskjellige funksjoner. Robots.txt dikterer gjennomsøkingsatferd på nettstedet eller katalogen, mens meta- og x-roboter kan diktere indekseringsatferd på det enkelte side- (eller sideelement) -nivå.
Fortsett å lære
- Robots metadirektiv
- Canonicalization
- Redirection
- Robots Exclusion Protocol
Sett ferdighetene dine i arbeid
Moz Pro kan identifisere om robots.txt-filen din blokkerer vår tilgang til nettstedet ditt. Prøv det > >
