Mi az a robots.txt fájl?
A Robots.txt egy szöveges fájl, amelyet a webmesterek létrehoznak a webrobotok utasítására ( általában keresőmotoros robotok) hogyan lehet feltérképezni a weboldalukon található oldalakat. A robots.txt fájl a robotok kizárási protokolljának (REP) része, az internetes szabványok csoportja, amely szabályozza, hogy a robotok hogyan térképezik fel az internetet, hogyan férhetnek hozzá és indexelik a tartalmat, és hogyan szolgálják ki ezt a tartalmat a felhasználók számára. A REP olyan irányelveket is tartalmaz, mint a metarobotok, valamint oldal-, alkönyvtár- vagy webhelyszintű utasításokat arra vonatkozóan, hogy a keresőmotoroknak hogyan kell kezelniük a linkeket (például “follow” vagy “nofollow”).
gyakorlatban a robots.txt fájlok jelzik, hogy bizonyos felhasználói ügynökök (web-feltérképező szoftverek) képesek-e feltérképezni a webhely egyes részeit. Ezeket a feltérképezési utasításokat bizonyos (vagy az összes) felhasználói ügynökök viselkedésének “megtiltásával” vagy “engedélyezésével” adják meg.
Alapformátum:
User-agent: Disallow:
Ez a két sor együttesen teljes robots.txt fájlnak számít – bár egy robotfájl több felhasználói ügynököt és utasítást tartalmazhat (azaz nem engedélyez, engedélyez, feltérképezési késleltetéseket stb.).
A robots.txt fájlban a user-agent direktívák minden halmaza diszkrét halmazként jelenik meg, sortöréssel elválasztva:
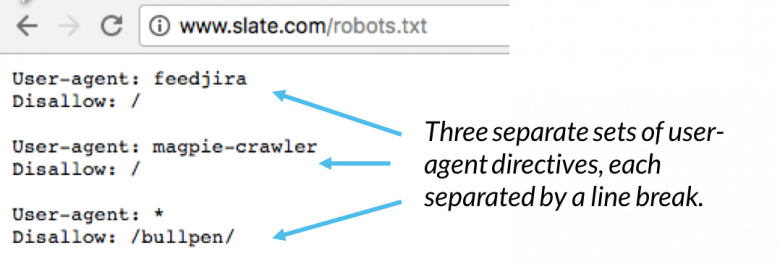
A több user-agent direktívát tartalmazó robots.txt fájlban minden tiltás vagy engedélyezés csak a useragentre vonatkozik ( s) meghatározott az adott sortöréssel elválasztott halmazban. Ha a fájl egy olyan szabályt tartalmaz, amely egynél több felhasználói ügynökre vonatkozik, akkor a bejáró csak a legspecifikusabb utasításcsoportra figyel (és követi az irányelveket).
Íme egy példa:
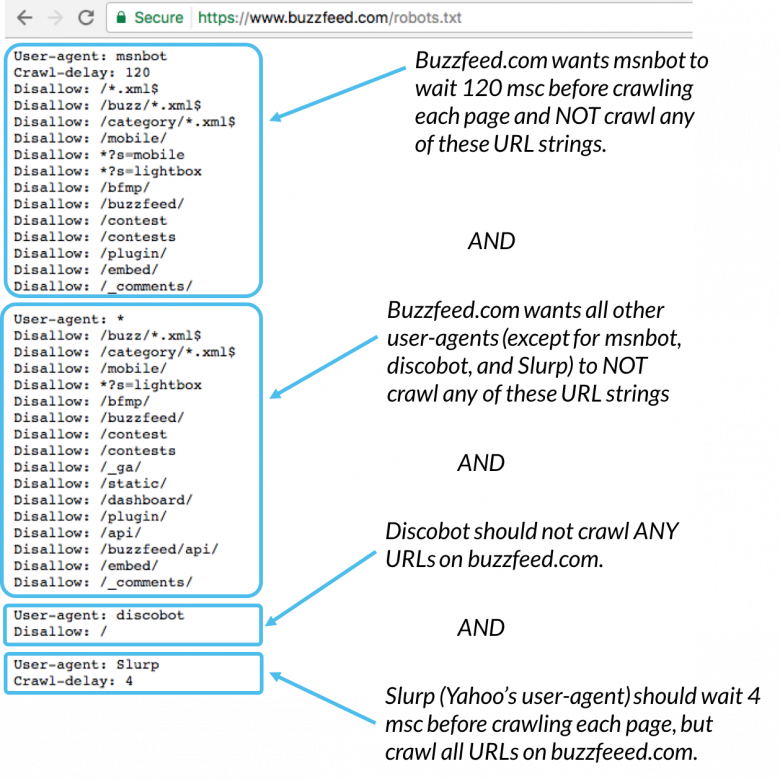
Az Msnbot, a discobot és a Slurp egyaránt kifejezetten, így ezek a felhasználói ügynökök csak az irányelvekre figyelnek a robots.txt fájl szakaszaiban. Az összes többi felhasználói ügynök követni fogja a user-agent: * csoport utasításait.
példa robots.txt:
Íme néhány példa a robots.txt fájl működésére www.example.com webhely:
Robots.txt fájl URL: www.example.com/robots.txt
Az összes webrobot letiltása az összes tartalomról
User-agent: * Disallow: /
A szintaxis robots.txt fájlban való használata minden webrobotnak megmondja, hogy ne feltérképezzenek egyetlen oldalt sem a www.example.com oldalon, beleértve a kezdőlapot sem.
Engedélyezés az összes webrobot hozzáfér az összes tartalomhoz
User-agent: * Disallow:
A szintaxis robots.txt fájlban történő használatával a webrobotok megadják a www.example.com összes oldalának feltérképezését. a kezdőlap.
Egy adott webrobot blokkolása egy adott mappából
User-agent: Googlebot Disallow: /example-subfolder/
Ez a szintaxis csak a Google robotját mondja meg (Googlebot felhasználói ügynök neve ), hogy ne feltérképezzen olyan oldalakat, amelyek a www.example.com/example-subfolder/ URL karaktersorozatot tartalmazzák.
Egy adott webrobot blokkolása egy adott weboldalról
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Ez a szintaxis csak a Bing bejárójának (Bing felhasználói ügynök neve) mondja meg, hogy kerülje az adott oldal feltérképezését a www.example.com/example-subfolder/blocked-page oldalon .html.
Hogyan működik a robots.txt?
A keresőmotoroknak két fő feladata van:
- Internet feltérképezése a tartalom felfedezéséhez;
- A tartalom indexelése, hogy az információt kereső keresők számára is megjelenhessen.
A webhelyek feltérképezéséhez a keresőmotorok linkeket követve jutnak el egyik webhelyről a másikra – végül feltérképezve sok milliárd linken és webhelyen. Ezt a bejárási viselkedést néha “pókolásnak” is nevezik.
Miután megérkezett egy webhelyre, de mielőtt pókba helyezné azt, a kereső robot egy robots.txt fájlt keres. Ha talál ilyet, akkor a bejáró ezt olvassa fájlba, mielőtt folytatná az oldalt. Mivel a robots.txt fájl információkat tartalmaz arról, hogy a keresőnek miként kell feltérképeznie, az ott található információk további feltérképezési műveleteket fognak végezni ezen a webhelyen. Ha a robots.txt fájl nem tartalmaz olyan irányelveket, amelyek megtiltja a felhasználói ügynök tevékenységét (vagy ha a webhely nem rendelkezik robots.txt fájllal), folytatja a webhely egyéb információinak feltérképezését.
Egyéb gyors robots.txt fájlokat kell tudni:
(az alábbiakban részletesebben tárgyaljuk)
-
A fellépéshez egy robots.txt fájlt kell elhelyezni a webhely legfelső szintű könyvtárában.
-
A Robots.txt megkülönbözteti a kis- és nagybetűket: a fájlnak “robots.txt” nevet kell adnia (nem Robots.txt, robots.TXT vagy más módon).
-
Egyes felhasználói ügynökök (robotok) m úgy dönthet, hogy figyelmen kívül hagyja a robots.txt fájlt. Ez különösen gyakori olyan rosszindulatú robotoknál, mint például a rosszindulatú programok robotjai vagy az e-mail címek lehúzói.
-
A /robots.txt fájl nyilvánosan elérhető: csak adja hozzá a /robots.txt fájlt a végéhez bármelyik gyökérdomainről az adott webhely irányelveinek megtekintéséhez (ha az adott webhely rendelkezik robots.txt fájllal!).Ez azt jelenti, hogy bárki láthatja, hogy milyen oldalakat csinál, vagy nem szeretne feltérképezni, ezért ne használja őket privát felhasználói információk elrejtésére.
-
A gyökér minden aldomainje domain külön robots.txt fájlokat használ. Ez azt jelenti, hogy mind a blog.example.com, mind az example.com-nak saját robots.txt fájlokkal kell rendelkeznie (a blog.example.com/robots.txt és example.com/robots.txt címeken).
-
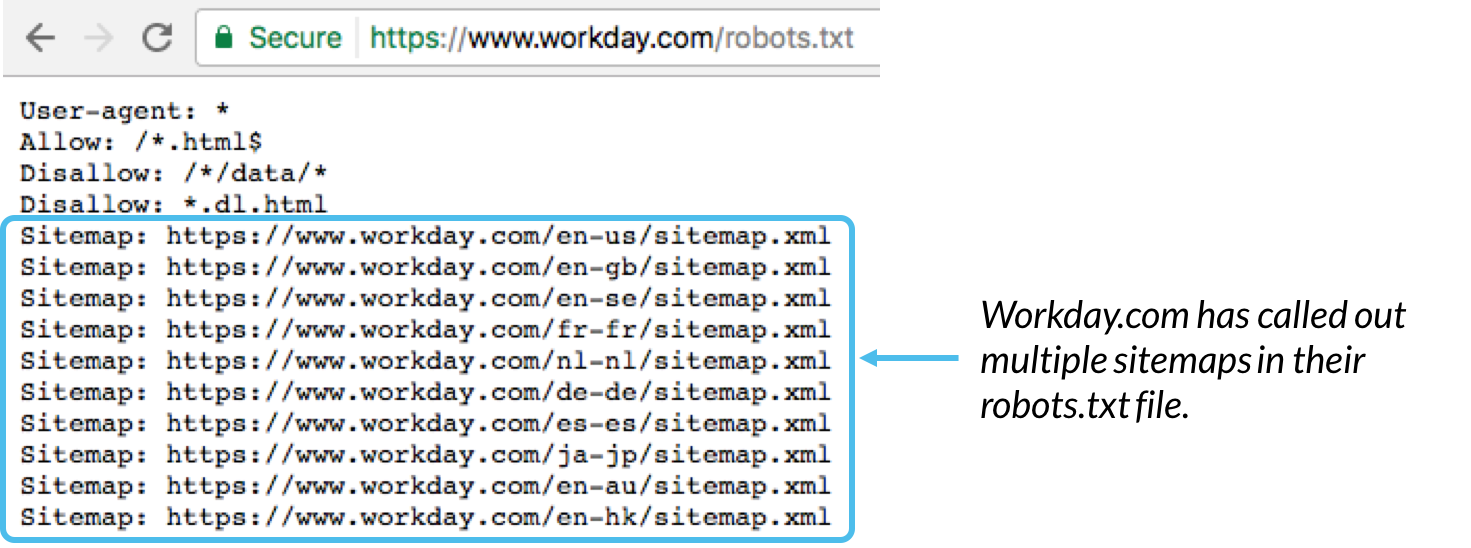
Általában bevált módszer a robots.txt fájl alján feltüntetni az ehhez a domainhez társított webhelytérképek helyét. Íme egy példa:
Műszaki robots.txt szintaxis
A robots.txt szintaxist a robots.txt fájlok “nyelveként” lehet elképzelni. Öt általános kifejezés létezik, amelyekkel valószínűleg találkozhat egy robotban fájl. Ezek a következőket tartalmazzák:
-
User-agent: Az a webes robot, amelyiknek feltérképezési utasításokat adsz (általában keresőmotor). A legtöbb felhasználói ügynök listája megtalálható itt.
-
Disallow: Az a parancs, amelyet arra használnak, hogy a felhasználó-ügynök ne feltérképezze az adott URL-t. Minden URL-hez csak egy “Disallow:” sor engedélyezett.
-
Engedélyezés (Csak a Googlebotra vonatkozik): A parancs, amely elmondja a Googlebotnak, hogy hozzáférhet egy oldalhoz vagy almappához, annak ellenére, hogy a szülőoldala vagy almappája nem engedélyezett.
-
Feltérképezés késleltetése: Hány másodpercet kell várnia a bejárónak az oldal tartalmának betöltése és feltérképezése előtt. Vegye figyelembe, hogy a Googlebot nem ismeri el ezt a parancsot, de a bejárási sebesség beállítható i n Google Search Console.
-
Webhelytérkép: Az URL-hez társított XML-webhelytérképek helyének meghívására szolgál. Ne feledje, hogy ezt a parancsot csak a Google, az Ask, a Bing és a Yahoo támogatja.
Mintaillesztés
A blokkolásra kerülő tényleges URL-ekről vagy engedélyezheti, hogy a robots.txt fájlok meglehetősen bonyolulttá válhatnak, mivel lehetővé teszik a mintaillesztés használatát, hogy lefedjék a lehetséges URL-beállítások egy sorát. A Google és a Bing egyaránt tiszteletben tart két reguláris kifejezést, amelyek felhasználhatók olyan oldalak vagy almappák azonosítására, amelyeket a SEO ki akar zárni. Ez a két karakter a csillag (*) és a dollárjel ($).
- * egy helyettesítő karakter, amely bármilyen karaktersorozatot képvisel.
- $ megegyezik a URL
A Google itt felsorolja a lehetséges mintaillesztési szintaxist és példákat.
Hová kerül a robots.txt egy webhelyen?
Amikor egy webhelyre érkeznek, a keresőmotorok és más webes robotok (például a Facebook bejárója, a Facebot) tudják keresni a robots.txt fájlt. De csak egy adott helyen keresik meg a fájlt: a fő könyvtárban (általában a gyökérdomainben vagy a kezdőlapon). Ha egy felhasználói ügynök meglátogatja a www.example.com/robots.txt webhelyet, és nem talál ott robotfájlt, akkor feltételezi, hogy a webhelynek nincs ilyen, és folytatja az oldal (és talán az egész webhely) minden feltérképezését. Még akkor is, ha a robots.txt oldal létezne, például az example.com/index/robots.txt vagy a www.example.com/homeepage/robots.txt címen, a felhasználói ügynökök nem fedeznék fel, és így a webhelyet kezelnék mintha egyáltalán nem lenne robotfájlja.
A robots.txt fájl megtalálása érdekében mindig vegye fel a fő könyvtárba vagy a gyökérdomainbe.
Miért szüksége van a robots.txt fájlra?
A Robots.txt fájlok ellenőrzik a robotok hozzáférését a webhely bizonyos területeihez. Bár ez nagyon veszélyes lehet, ha véletlenül megtiltja, hogy a Googlebot feltérképezze az egész webhelyét (!!), vannak olyan esetek, amikor a robots.txt fájl nagyon hasznos lehet.
Néhány általános használati eset a következő:
- A duplikált tartalom megjelenésének megakadályozása a SERP-kben (vegye figyelembe, hogy a metarobotok gyakran jobb választás erre)
- A weboldal teljes szakaszainak titokban tartása (például a mérnökök számára) csapat átmeneti webhelye)
- A belső keresési eredményoldalak megjelenésének megakadályozása egy nyilvános SERP-n
- a webhelytérkép (ek) helyének megadása
- a keresőmotorok indexelésének megakadályozása bizonyos fájlok a webhelyén (képek, PDF-fájlok stb.)
- Feltérképezési késleltetés megadása a szerverek túlterhelésének megakadályozása érdekében, amikor a robotok több tartalom darabját töltik be egyszerre
Ha a webhelyén nincs olyan terület, amelyhez ellenőrizni szeretné a felhasználói ügynökök hozzáférését, akkor lehet, hogy egyáltalán nincs szüksége robots.txt fájlra.
Annak ellenőrzése, hogy van-e robotja s.txt fájl
Nem biztos benne, hogy van robots.txt fájlja? Egyszerűen írja be a gyökérdomainjét, majd adja hozzá a /robots.txt fájlt az URL végéhez. Például a Moz robotfájlja a moz.com/robots.txt címen található.
Ha nem jelenik meg .txt oldal, akkor jelenleg nincs (élő) robots.txt oldala.
Robots.txt fájl létrehozása
Ha úgy találta, hogy nem rendelkezik robots.txt fájllal, vagy módosítani szeretné a fájlját, akkor annak létrehozása egyszerű folyamat. Ez a Google-i cikk végigvezeti a robots.txt fájl létrehozásának folyamatát, és ez az eszköz lehetővé teszi, hogy tesztelje, hogy a fájlja megfelelően van-e beállítva.
Keres gyakorlatot robotfájlok létrehozására?Ez a blogbejegyzés néhány interaktív példát mutat be.
A SEO bevált módszerei
-
Győződjön meg arról, hogy nem blokkolja webhelyének egyetlen olyan tartalmát vagy szakaszát, amelyet fel szeretne térképezni.
-
A robots.txt által blokkolt oldalak linkjeit nem követjük. Ez azt jelenti, hogy 1.) Hacsak nem más, a keresőmotor által elérhető oldalakról (azaz a robots.txt, meta robotok vagy más módon nem blokkolt oldalakról) is linkeltek, a kapcsolt erőforrások nem kerülnek feltérképezésre és nem indexelhetők. 2.) A blokkolt oldalról a link célpontjába nem kerülhet hivatkozás. Ha olyan oldalai vannak, amelyeknek át szeretné adni a saját tőkét, akkor a robots.txt fájltól eltérő blokkolási mechanizmust használjon.
-
Ne használja a robots.txt fájlt az érzékeny adatok (például magánfelhasználói információk) megjelenését a SERP eredményekben. Mivel más oldalak közvetlenül a privát információkat tartalmazó oldalra hivatkozhatnak (megkerülve ezzel a gyökérdomainen vagy a kezdőlapon található robots.txt irányelveket), előfordulhat, hogy indexelik. Ha blokkolni szeretné oldalát a keresési eredmények között, használjon más módszert, például jelszóvédelmet vagy noindex meta-irányelvet.
-
Egyes keresőmotorok több felhasználói ágenssel rendelkeznek. Például a Google a Googlebotot használja az organikus kereséshez, a Googlebot-Image pedig a képkereséshez. Azonos keresőmotor legtöbb felhasználói ügynöke ugyanazokat a szabályokat követi, így nincs szükség irányelvek megadására a keresőmotor egyes robotjaihoz, de ha erre képes, akkor finomhangolhatja a webhely tartalmának feltérképezését.
-
A keresőmotor gyorsítótárba helyezi a robots.txt tartalmát, de általában naponta legalább egyszer frissíti a gyorsítótárazott tartalmat. Ha megváltoztatja a fájlt, és gyorsabban szeretné frissíteni, mint az előfordulna, beküldheti a robots.txt URL-jét a Google-nak.
Robots.txt vs meta robotok vs x -robotok
Ennyi robot! Mi a különbség e három robotutasítás között? Először is, a robots.txt egy tényleges szövegfájl, míg a meta és az x-robot meta irányelv. Amellett, hogy valójában vannak, mind a három különböző funkciót tölt be. A Robots.txt diktálja a webhely vagy a könyvtár egészére kiterjedő feltérképezési viselkedést, míg a meta és az x-robotok az indexelési viselkedést az egyes oldalak (vagy oldalelemek) szintjén.
Tanuljon tovább
- Robotok metaadirektívái
- Kanalizálás
- Átirányítás
- Robotok kizárási protokoll
Használja képességeit
A Moz Pro felismerheti, hogy a robots.txt fájlja blokkolja-e a webhelyünkhöz való hozzáférést. Próbálja ki > >
