Hvad er en robots.txt-fil?
Robots.txt er en tekstfil, som webmastere opretter for at instruere webrobotter ( typisk søgemaskine-robotter) hvordan man gennemsøger sider på deres websted. Robotten.txt-filen er en del af protokollen til ekskludering af robotter (REP), en gruppe webstandarder, der regulerer, hvordan robotter gennemsøger internettet, får adgang til og indekserer indhold og serverer dette indhold op til brugerne. REP inkluderer også direktiver som meta-robotter såvel som side-, underkatalog- eller webstedsinstruktioner til, hvordan søgemaskiner skal behandle links (såsom “følg” eller “nofollow”).
I praksis angiver robots.txt-filer, om bestemte brugeragenter (web-gennemgangssoftware) kan eller ikke kan gennemgå dele af et websted. Disse gennemgangsinstruktioner specificeres ved at “afvise” eller “tillade” adfærd for visse (eller alle) brugeragenter.
Grundlæggende format:
User-agent: Disallow:
Tilsammen betragtes disse to linjer som en komplet robots.txt-fil – selvom en robotfil kan indeholde flere linjer med brugeragenter og direktiver (dvs. ikke tillader, tillader, gennemgangsforsinkelser osv.).
Inden for en robots.txt-fil vises hvert sæt brugeragentdirektiver som et diskret sæt adskilt af et linjeskift:
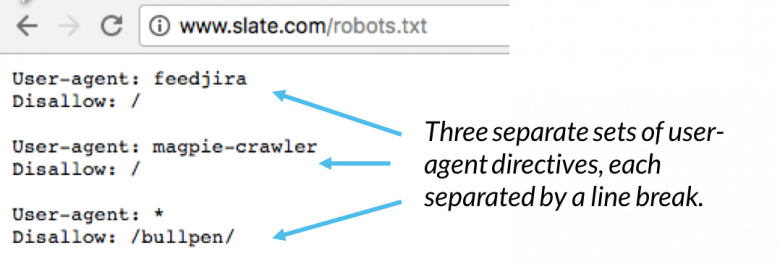
I en robots.txt-fil med flere bruger-agent-direktiver gælder hver tilladelses- eller tilladelsesregel kun for brugeragenten ( s) specificeret i det bestemte linjeskiftede sæt. Hvis filen indeholder en regel, der gælder for mere end en brugeragent, vil en crawler kun være opmærksom på (og følge direktiverne i) den mest specifikke gruppe instruktioner.
Her er et eksempel:
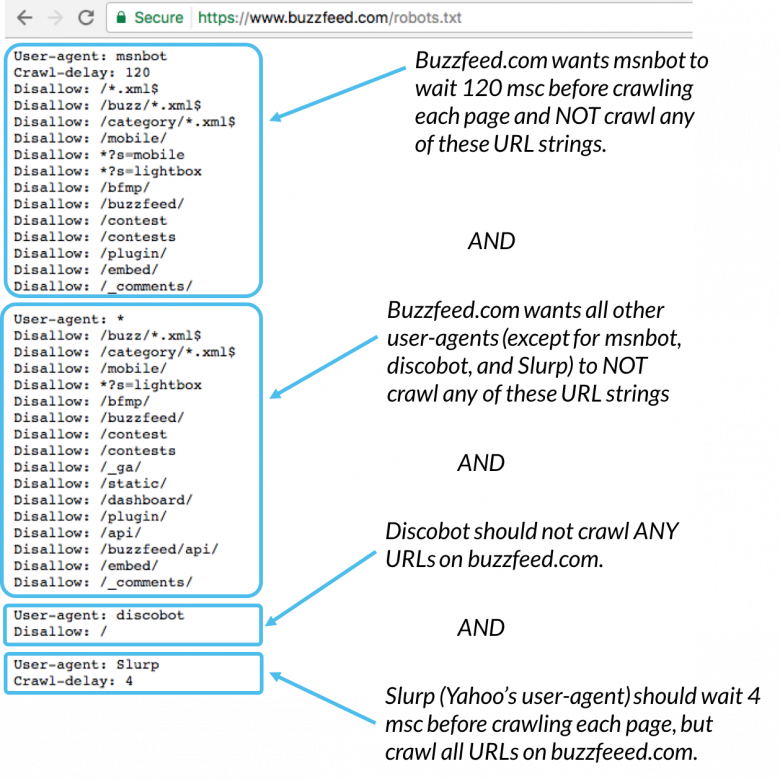
Msnbot, discobot og Slurp kaldes alle sammen specifikt ud, så disse brugeragenter vil kun være opmærksomme på direktiverne i deres sektioner i robots.txt-filen. Alle andre brugeragenter følger retningslinjerne i brugeragenten: * -gruppen.
Eksempel på robots.txt:
Her er et par eksempler på robots.txt i aktion for en www.example.com-websted:
Robots.txt-fil-URL: www.example.com/robots.txt
Blokering af alle webcrawlere fra alt indhold
User-agent: * Disallow: /
Brug af denne syntaks i en robots.txt-fil vil bede alle webcrawlere ikke at gennemgå nogen sider på www.example.com, inklusive hjemmesiden.
Tillader alle webcrawlere har adgang til alt indhold
User-agent: * Disallow:
Brug af denne syntaks i en robots.txt-fil fortæller webcrawlere at gennemgå alle sider på www.example.com, inklusive startsiden.
Blokering af en bestemt webcrawler fra en bestemt mappe
User-agent: Googlebot Disallow: /example-subfolder/
Denne syntaks fortæller kun Googles webcrawler (brugeragentens navn Googlebot ) ikke at gennemgå sider, der indeholder URL-strengen www.example.com/example-subfolder/.
Blokering af en bestemt webcrawler fra en bestemt webside
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Denne syntaks fortæller kun Bings crawler (bruger-agentnavn Bing) for at undgå at gennemgå den specifikke side på www.example.com/example-subfolder/blocked-page .html.
Hvordan fungerer robots.txt?
Søgemaskiner har to hovedopgaver:
- Gennemgang af internettet for at finde indhold;
- Indeksering af dette indhold, så det kan serveres til søgere, der leder efter information.
For at gennemgå websteder følger søgemaskiner links for at komme fra et websted til et andet – i sidste ende, gennemgang på tværs af mange milliarder af links og websteder. Denne gennemsøgningsadfærd kaldes undertiden “spidering”.
Efter at have ankommet et websted, men inden spidering af det, vil søgecrawleren søge efter en robots.txt-fil. Hvis den finder en, læser crawleren det først før du fortsætter gennem siden. Da robots.txt-filen indeholder oplysninger om, hvordan søgemaskinen skal gennemgå, vil de oplysninger, der findes der, instruere yderligere crawlerhandlinger på dette bestemte websted. Hvis robots.txt-filen ikke indeholder nogen direktiver, der ikke tillade en brugeragents aktivitet (eller hvis webstedet ikke har en robots.txt-fil), fortsætter den med at gennemgå andre oplysninger på webstedet.
Andre hurtige robots.txt-must-know:
(diskuteret mere detaljeret nedenfor)
-
For at blive fundet skal en robots.txt-fil placeres i et websides topkatalog.
-
Robots.txt skelner mellem store og små bogstaver: filen skal have navnet “robots.txt” (ikke Robots.txt, robots.TXT eller andet).
-
Nogle brugeragenter (robotter) m ay vælg at ignorere din robots.txt-fil. Dette er især almindeligt med mere uhyggelige crawlere som malware-robotter eller e-mail-adresseskrabere.
-
/robots.txt-filen er en offentligt tilgængelig: bare tilføj /robots.txt til slutningen af ethvert roddomæne for at se webstedets direktiver (hvis webstedet har en robots.txt-fil!).Dette betyder, at alle kan se, hvilke sider du laver eller ikke ønsker at blive gennemgået, så brug dem ikke til at skjule private brugeroplysninger.
-
Hvert underdomæne på en rod domæne bruger separate robots.txt-filer. Dette betyder, at både blog.example.com og example.com skal have deres egne robots.txt-filer (på blog.example.com/robots.txt og example.com/robots.txt).
-
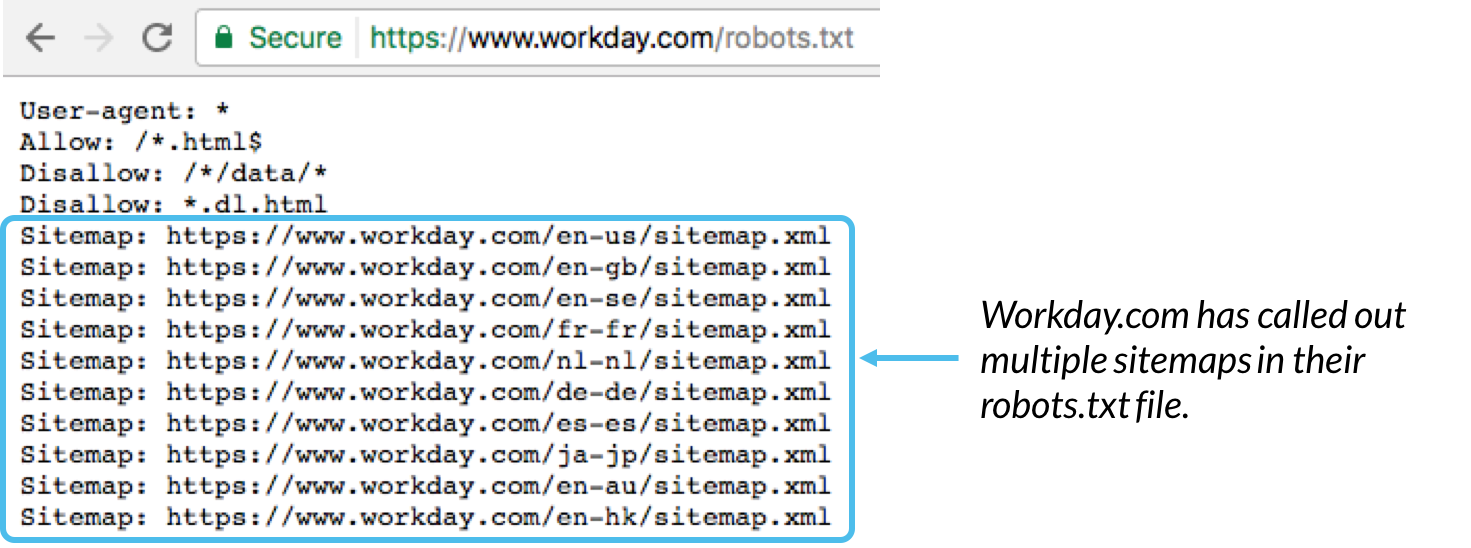
Det er generelt en god praksis at angive placeringen af eventuelle sitemaps tilknyttet dette domæne i bunden af robots.txt-filen. Her er et eksempel:
Teknisk robots.txt-syntaks
Robots.txt-syntaks kan betragtes som “sproget” for robots.txt-filer. Der er fem almindelige udtryk, som du sandsynligvis støder på i en robot De inkluderer:
-
Brugeragent: Den specifikke webcrawler, som du giver crawlinstruktioner til (normalt en søgemaskine). En liste over de fleste brugeragenter kan findes her.
-
Disallow: Kommandoen, der bruges til at bede en brugeragent om ikke at gennemgå en bestemt URL. Kun en “Disallow:” -linje er tilladt for hver URL.
-
Tillad (gælder kun for Googlebot): Kommandoen til at fortælle Googlebot, at den kan få adgang til en side eller undermappe, selvom dens overordnede side eller undermappe muligvis ikke er tilladt.
-
Crawl-delay: Hvor mange sekunder en crawler skal vente, før der indlæses og crawles sideindhold. Bemærk, at Googlebot ikke anerkender denne kommando, men crawlhastighed kan indstilles i n Google Search Console.
-
Sitemap: Bruges til at kalde placeringen af ethvert XML-sitemap (er), der er knyttet til denne URL. Bemærk, at denne kommando kun understøttes af Google, Ask, Bing og Yahoo.
Mønster-matching
Når det kommer til de faktiske webadresser, der skal blokeres eller tillad, robots.txt-filer kan blive temmelig komplekse, da de tillader brug af mønster-matching til at dække en række mulige URL-indstillinger. Google og Bing respekterer begge to regulære udtryk, der kan bruges til at identificere sider eller undermapper, som en SEO ønsker udelukket. Disse to tegn er stjernen (*) og dollartegnet ($).
- * er et jokertegn, der repræsenterer en hvilken som helst rækkefølge af tegn
- $ matcher slutningen af URL
Google tilbyder en fantastisk liste over mulige mønstermatchende syntaks og eksempler her.
Hvor går robots.txt på et websted?
Når de kommer til et websted, ved søgemaskiner og andre webcrawling-robotter (som Facebooks crawler, Facebot) at kigge efter en robots.txt-fil. Men de vil kun kigge efter den pågældende fil et bestemt sted: hovedmappen (typisk dit roddomæne eller din startside). Hvis en brugeragent besøger www.example.com/robots.txt og ikke finder en robotfil der, antager den, at webstedet ikke har en, og fortsætter med at gennemgå alt på siden (og måske endda på hele webstedet). Selvom robots.txt-siden eksisterede på f.eks. Eksempel.com/index/robots.txt eller www.example.com/homepage/robots.txt, ville den ikke blive opdaget af brugeragenter, og webstedet ville således blive behandlet som om den slet ikke havde nogen robotfil.
For at sikre at din robots.txt-fil findes, skal du altid inkludere den i dit hovedkatalog eller roddomæne.
Hvorfor gør du har du brug for robots.txt?
Robots.txt-filer styrer crawleradgang til bestemte områder på dit websted. Selvom dette kan være meget farligt, hvis du ved et uheld forhindrer Googlebot i at gennemgå hele dit websted (!!), er der nogle situationer, hvor en robots.txt-fil kan være meget praktisk.
Nogle almindelige anvendelsestilfælde inkluderer:
- Forebyggelse af, at duplikatindhold vises i SERP’er (bemærk, at meta-robotter ofte er et bedre valg til dette)
- At holde hele sektioner på et websted privat (for eksempel din teknik teamets iscenesættelseswebsted)
- At forhindre, at interne søgeresultatsider vises på en offentlig SERP
- Angivelse af placeringen af sitemap (er)
- Forhindring af søgemaskiner fra indeksering bestemte filer på dit websted (billeder, PDF-filer osv.)
- Angivelse af en gennemgangsforsinkelse for at forhindre, at dine servere bliver overbelastede, når webcrawlere indlæser flere stykker indhold på én gang
Hvis der ikke er områder på dit websted, som du vil kontrollere brugeragentadgang til, har du muligvis slet ikke brug for en robots.txt-fil.
Kontrollerer, om du har en robot s.txt-fil
Er du ikke sikker på, om du har en robots.txt-fil? Indtast blot dit roddomæne, og tilføj derefter /robots.txt til slutningen af URL’en. For eksempel er Mozs robots-fil placeret på moz.com/robots.txt.
Hvis der ikke vises nogen .txt-side, har du ikke i øjeblikket en (live) robots.txt-side.
Sådan oprettes en robots.txt-fil
Hvis du fandt ud af, at du ikke havde en robots.txt-fil eller ønsker at ændre din, er det nemt at oprette en. Denne artikel fra Google gennemgår processen til oprettelse af robots.txt-filer, og dette værktøj giver dig mulighed for at teste, om din fil er konfigureret korrekt.
Leder du efter en øvelse i at oprette robots-filer?Dette blogindlæg gennemgår nogle interaktive eksempler.
Bedste fremgangsmåder for SEO
-
Sørg for, at du ikke blokerer for noget indhold eller dele af dit websted, du vil gennemgå.
-
Links på sider, der er blokeret af robots.txt, følges ikke. Dette betyder 1.) Medmindre de også er linket fra andre sider, der er tilgængelige for søgemaskiner (dvs. sider, der ikke er blokeret via robots.txt, meta-robotter eller på anden måde), gennemgås de linkede ressourcer ikke og indekseres muligvis ikke. 2.) Ingen linkkapital kan overføres fra den blokerede side til linkdestinationen. Hvis du har sider, som du vil have egenkapital til, skal du bruge en anden blokeringsmekanisme end robots.txt.
-
Brug ikke robots.txt til at forhindre følsomme data (f.eks. private brugeroplysninger) fra at blive vist i SERP-resultater. Fordi andre sider muligvis linker direkte til siden, der indeholder private oplysninger (og dermed omgår robots.txt-direktiverne på dit roddomæne eller startside), bliver de muligvis stadig indekseret. Hvis du vil blokere din side fra søgeresultater, skal du bruge en anden metode som adgangskodebeskyttelse eller noindex-metadirektivet.
-
Nogle søgemaskiner har flere brugeragenter. For eksempel bruger Google Googlebot til organisk søgning og Googlebot-Image til billedsøgning. De fleste brugeragenter fra den samme søgemaskine følger de samme regler, så der er ikke behov for at specificere direktiver for hver af en søgemaskines flere crawlere, men at have evnen til at gøre det giver dig mulighed for at finjustere, hvordan dit webstedsindhold crawles.
-
En søgemaskine cachelagrer robots.txt-indholdet, men opdaterer normalt det cachelagrede indhold mindst en gang om dagen. Hvis du ændrer filen og vil opdatere den hurtigere, end der sker, kan du indsende din robots.txt-url til Google.
Robots.txt vs meta-robots vs x -roboter
Så mange robotter! Hvad er forskellen mellem disse tre typer robotinstruktioner? For det første er robots.txt en egentlig tekstfil, mens meta og x-robotter er metadirektiver. Ud over hvad de faktisk er, tjener de tre forskellige funktioner. Robots.txt dikterer crawladfærd på hele webstedet eller biblioteket, hvorimod meta- og x-robotter kan diktere indekseringsadfærd på niveauet for det enkelte side (eller sideelement).
Fortsæt med at lære
- Metadirektiver for robotter
- Canonicalization
- Omdirigering
- Robotens eksklusionsprotokol
Sæt dine færdigheder i gang
Moz Pro kan identificere, om din robots.txt-fil blokerer vores adgang til dit websted. Prøv det > >
