Wat is een robots.txt-bestand?
Robots.txt is een tekstbestand dat webmasters maken om webrobots ( meestal robots van zoekmachines) hoe ze pagina’s op hun website kunnen crawlen. Het robots.txt-bestand maakt deel uit van het robots exclusion protocol (REP), een groep webstandaarden die regelen hoe robots het web crawlen, inhoud openen en indexeren, en die inhoud aan gebruikers aanbieden. De REP bevat ook richtlijnen zoals meta-robots, evenals pagina-, subdirectory- of site-brede instructies voor hoe zoekmachines links moeten behandelen (zoals “volgen” of “nofollow”).
In praktijk, geven robots.txt-bestanden aan of bepaalde user agents (webcrawling-software) delen van een website wel of niet kunnen crawlen. Deze crawlinstructies worden gespecificeerd door het gedrag van bepaalde (of alle) user agents “niet toe te staan” of “toe te staan”.
Basisformaat:
User-agent: Disallow:
Samen worden deze twee regels beschouwd als een compleet robots.txt-bestand – hoewel één robots-bestand meerdere regels met user agents en richtlijnen kan bevatten (dat wil zeggen, disallow, allow, crawl-vertragingen, enz.).
Binnen een robots.txt-bestand wordt elke set user-agent-instructies weergegeven als een discrete set, gescheiden door een regeleinde:
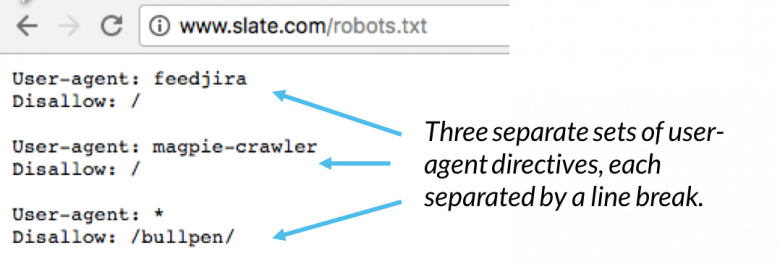
In een robots.txt-bestand met meerdere user-agent-instructies is elke disallow- of allow-regel alleen van toepassing op de useragent ( s) gespecificeerd in die specifieke set met regelafbreking. Als het bestand een regel bevat die van toepassing is op meer dan één user-agent, zal een crawler alleen letten op (en de richtlijnen volgen in) de meest specifieke groep instructies.
Hier is een voorbeeld:
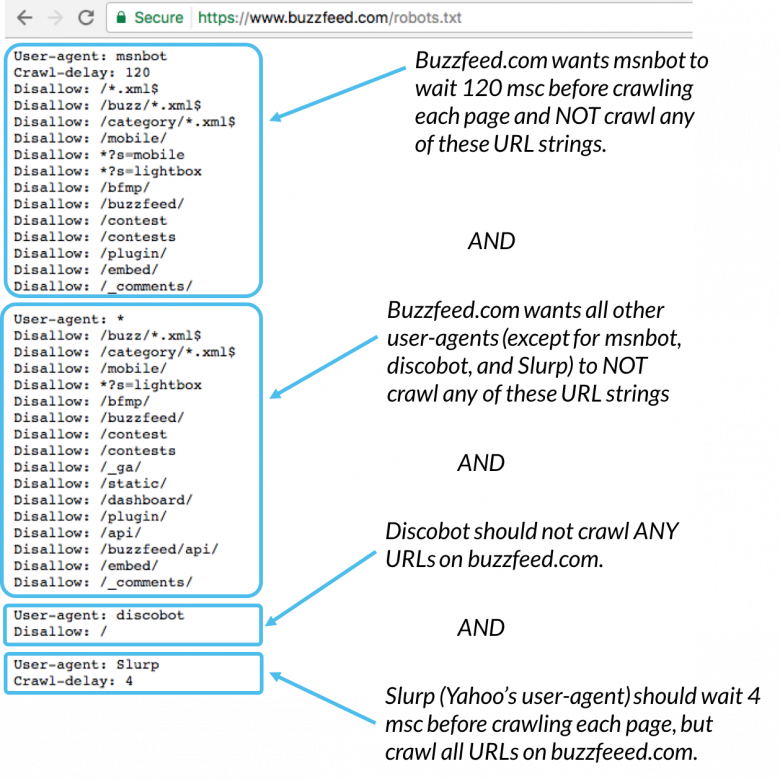
Msnbot, discobot en Slurp worden allemaal genoemd specifiek uit, zodat die user-agents alleen aandacht besteden aan de richtlijnen in hun secties van het robots.txt-bestand. Alle andere user-agents volgen de richtlijnen in de user-agent: * groep.
Voorbeeld robots.txt:
Hier zijn een paar voorbeelden van robots.txt in actie voor een www.example.com site:
URL van Robots.txt-bestand: www.example.com/robots.txt
Alle webcrawlers blokkeren voor alle inhoud
User-agent: * Disallow: /
Het gebruik van deze syntaxis in een robots.txt-bestand zou alle webcrawlers vertellen om geen pagina’s op www.example.com te crawlen, inclusief de startpagina.
Toestaan alle webcrawlers hebben toegang tot alle inhoud
User-agent: * Disallow:
Het gebruik van deze syntaxis in een robots.txt-bestand vertelt webcrawlers om alle pagina’s op www.example.com te crawlen, inclusief de startpagina.
Een specifieke webcrawler blokkeren uit een specifieke map
User-agent: Googlebot Disallow: /example-subfolder/
Deze syntaxis vertelt alleen de crawler van Google (user-agentnaam Googlebot ) om geen pagina’s te crawlen die de URL-reeks www.example.com/example-subfolder/ bevatten.
Een specifieke webcrawler blokkeren van een specifieke webpagina
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Deze syntaxis vertelt alleen de crawler van Bing (gebruikersnaam Bing) om te voorkomen dat de specifieke pagina op www.example.com/example-subfolder/blocked-page wordt gecrawld .html.
Hoe werkt robots.txt?
Zoekmachines hebben twee hoofdtaken:
- Het web crawlen om inhoud te ontdekken;
- Die inhoud indexeren zodat deze kan worden geserveerd aan zoekers die op zoek zijn naar informatie.
Om sites te crawlen, volgen zoekmachines links om van de ene site naar de andere te gaan – uiteindelijk crawlen op vele miljarden links en websites. Dit crawlgedrag wordt ook wel ‘spidering’ genoemd.
Nadat de zoekcrawler op een website is aangekomen, maar voordat deze wordt gespid, zoekt hij naar een robots.txt-bestand. Als hij er een vindt, leest de crawler dat -bestand voordat u doorgaat op de pagina. Omdat het robots.txt-bestand informatie bevat over hoe de zoekmachine moet crawlen, geeft de informatie die daar wordt gevonden instructies voor verdere crawleractie op deze specifieke site. Als het robots.txt-bestand geen richtlijnen bevat die de activiteit van een user-agent niet toestaan (of als de site geen robots.txt-bestand heeft), gaat deze verder met het crawlen van andere informatie op de site.
Andere snelle robots.txt-bestanden die je moet kennen:
(hieronder in meer detail besproken)
-
Om gevonden te worden, moet een robots.txt-bestand in de hoofddirectory van een website worden geplaatst.
-
Robots.txt is hoofdlettergevoelig: het bestand moet de naam “robots.txt” hebben (niet Robots.txt, robots. TXT of anderszins).
-
Sommige user agents (robots) m Kies ervoor om uw robots.txt-bestand te negeren. Dit komt vooral voor bij snode crawlers zoals malware-robots of e-mailadresschrapers.
-
Het /robots.txt-bestand is openbaar beschikbaar: voeg gewoon /robots.txt toe aan het einde van een hoofddomein om de richtlijnen van die website te zien (als die site een robots.txt-bestand heeft!).Dit betekent dat iedereen kan zien welke pagina’s je wel of niet gecrawld wilt hebben, dus gebruik ze niet om privégebruikersinformatie te verbergen.
-
Elk subdomein op een root domein gebruikt aparte robots.txt-bestanden. Dit betekent dat zowel blog.example.com als example.com hun eigen robots.txt-bestanden moeten hebben (op blog.example.com/robots.txt en example.com/robots.txt).
-
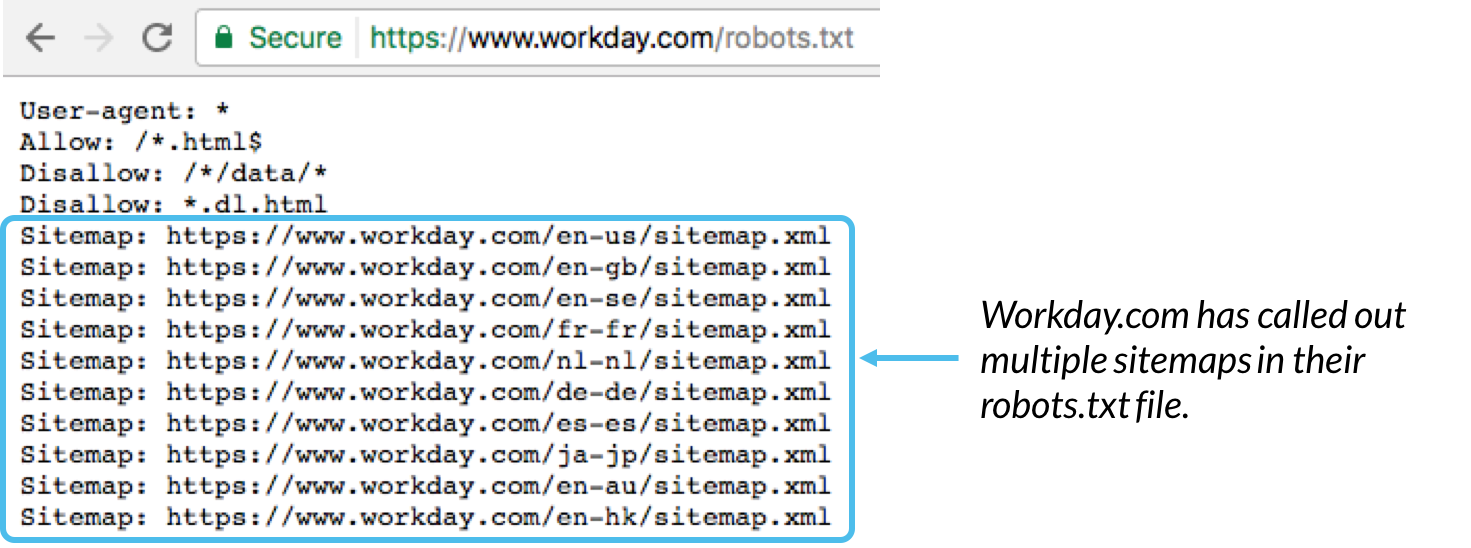
Het is over het algemeen een goede gewoonte om de locatie van alle sitemaps die aan dit domein zijn gekoppeld, onder aan het robots.txt-bestand aan te geven. Hier is een voorbeeld:
Technische robots.txt-syntaxis
Robots.txt-syntaxis kan worden gezien als de “taal” van robots.txt-bestanden. Er zijn vijf veelgebruikte termen die u waarschijnlijk tegenkomt in robots Dit zijn onder meer:
-
User-agent: de specifieke webcrawler waaraan u crawlinstructies geeft (meestal een zoekmachine). Er kan een lijst met de meeste user-agents worden gevonden hier.
-
Disallow: de opdracht die wordt gebruikt om een user-agent te vertellen een bepaalde URL niet te crawlen. Slechts één regel “Disallow:” is toegestaan voor elke URL.
-
Toestaan (alleen van toepassing op Googlebot): de opdracht om Googlebot te vertellen dat het toegang heeft tot een pagina of submap, ook al is de bovenliggende pagina of submap mogelijk niet toegestaan.
-
Crawlvertraging: hoeveel seconden moet een crawler wachten voordat de pagina-inhoud wordt geladen en gecrawld. Houd er rekening mee dat Googlebot deze opdracht niet accepteert, maar de crawlsnelheid kan worden ingesteld n Google Search Console.
-
Sitemap: wordt gebruikt om de locatie op te roepen van XML-sitemap (s) die aan deze URL zijn gekoppeld. Merk op dat dit commando alleen wordt ondersteund door Google, Ask, Bing en Yahoo.
Patroonaanpassing
Als het gaat om de daadwerkelijke URL’s die moeten worden geblokkeerd of toestaan, robots.txt-bestanden kunnen behoorlijk complex worden omdat ze het gebruik van patroonherkenning toestaan om een reeks mogelijke URL-opties te dekken. Google en Bing respecteren beide twee reguliere expressies die kunnen worden gebruikt om pagina’s of submappen te identificeren die een SEO wil uitsluiten. Deze twee tekens zijn de asterisk (*) en het dollarteken ($).
- * is een jokerteken dat een willekeurige reeks tekens vertegenwoordigt
- $ komt overeen met het einde van de URL
Google biedt hier een geweldige lijst met mogelijke syntaxis voor patroonovereenkomst en voorbeelden.
Waar gaat robots.txt op een site naartoe?
Wanneer ze naar een site komen, weten zoekmachines en andere webcrawling-robots (zoals de crawler van Facebook, Facebot) te zoeken naar een robots.txt-bestand. Maar ze zoeken dat bestand alleen op één specifieke plaats: de hoofddirectory (meestal uw hoofddomein of startpagina). Als een user-agent www.example.com/robots.txt bezoekt en daar geen robots-bestand vindt, gaat hij ervan uit dat de site er geen heeft en gaat hij verder met het crawlen van alles op de pagina (en misschien zelfs van de hele site). Zelfs als de robots.txt-pagina zou bestaan op bijvoorbeeld example.com/index/robots.txt of www.example.com/homepage/robots.txt, zou deze niet worden ontdekt door user agents en zou de site dus worden behandeld alsof het helemaal geen robots-bestand bevat.
Om ervoor te zorgen dat uw robots.txt-bestand wordt gevonden, neemt u het altijd op in uw hoofddirectory of hoofddomein.
Waarom robots.txt nodig?
Robots.txt-bestanden bepalen de crawlertoegang tot bepaalde delen van uw site. Hoewel dit erg gevaarlijk kan zijn als u per ongeluk Googlebot niet toestaat uw hele site te crawlen (!!), zijn er enkele situaties waarin een robots.txt-bestand erg handig kan zijn.
Enkele veelvoorkomende gebruikssituaties zijn:
- Voorkomen dat dubbele inhoud in SERP’s verschijnt (merk op dat meta-robots hiervoor vaak een betere keuze zijn)
- Houden hele delen van een website privé (bijvoorbeeld uw engineering teamstaging-site)
- Voorkomen dat pagina’s met interne zoekresultaten op een openbare SERP verschijnen
- De locatie van sitemap (s) specificeren
- Voorkomen dat zoekmachines indexeren bepaalde bestanden op uw website (afbeeldingen, pdf’s, enz.)
- Een crawlvertraging specificeren om te voorkomen dat uw servers overbelast raken wanneer crawlers meerdere stukken inhoud tegelijk laden
Als er geen gebieden op uw site zijn waarvoor u de toegang tot user-agent wilt beheren, heeft u mogelijk helemaal geen robots.txt-bestand nodig.
Controleren of u een robot heeft s.txt-bestand
Weet u niet zeker of u een robots.txt-bestand heeft? Typ gewoon uw hoofddomein in en voeg vervolgens /robots.txt toe aan het einde van de URL. Het robots-bestand van Moz bevindt zich bijvoorbeeld op moz.com/robots.txt.
Als er geen .txt-pagina verschijnt, heb je momenteel geen (live) robots.txt-pagina.
Hoe maak je een robots.txt-bestand aan
Als je merkt dat je geen robots.txt-bestand hebt of je wilt wijzigen, is het een eenvoudig proces om er een te maken. Dit artikel van Google doorloopt het proces van het maken van robots. Txt-bestanden, en met deze tool kun je testen of je bestand correct is ingesteld.
Wil je oefenen met het maken van robots-bestanden?In deze blogpost worden enkele interactieve voorbeelden besproken.
Praktische tips voor SEO
-
Zorg ervoor dat u geen inhoud of delen van uw website blokkeert die u wilt laten crawlen.
-
Links op pagina’s die door robots.txt zijn geblokkeerd, worden niet gevolgd. Dit betekent: 1.) Tenzij ze ook zijn gelinkt vanaf andere door zoekmachines toegankelijke pagina’s (d.w.z. pagina’s die niet zijn geblokkeerd via robots.txt, meta-robots of anderszins), worden de gelinkte bronnen niet gecrawld en mogen ze niet worden geïndexeerd. 2.) Er kan geen link equity worden doorgegeven van de geblokkeerde pagina naar de linkbestemming. Als u pagina’s heeft waarnaar u equity wilt doorgeven, gebruik dan een ander blokkeermechanisme dan robots.txt.
-
Gebruik geen robots.txt om gevoelige gegevens (zoals persoonlijke gebruikersinformatie) van het verschijnen in SERP-resultaten. Omdat andere pagina’s mogelijk rechtstreeks linken naar de pagina met privé-informatie (waardoor de robots.txt-richtlijnen op uw hoofddomein of homepage worden omzeild), kan deze nog steeds worden geïndexeerd. Als je je pagina wilt blokkeren voor zoekresultaten, gebruik dan een andere methode zoals wachtwoordbeveiliging of de noindex meta-instructie.
-
Sommige zoekmachines hebben meerdere user-agents. Google gebruikt bijvoorbeeld Googlebot voor organisch zoeken en Googlebot-Image voor het zoeken naar afbeeldingen. De meeste user agents van dezelfde zoekmachine volgen dezelfde regels, dus het is niet nodig om richtlijnen op te geven voor elk van de meerdere crawlers van een zoekmachine, maar als je de mogelijkheid hebt om dit te doen, kun je nauwkeurig afstemmen hoe de inhoud van je site wordt gecrawld. / p>
-
Een zoekmachine zal de inhoud van het robots.txt-bestand in de cache opslaan, maar werkt de inhoud in het cachegeheugen meestal minstens één keer per dag bij. Als u het bestand wijzigt en het sneller wilt bijwerken dan het is, kunt u uw robots.txt-URL indienen bij Google.
Robots.txt versus meta-robots versus x -robots
Zoveel robots! Wat is het verschil tussen deze drie soorten robotinstructies? Ten eerste is robots.txt een echt tekstbestand, terwijl meta en x-robots meta-directives zijn. Behalve wat ze werkelijk zijn, vervullen de drie allemaal verschillende functies. Robots.txt dicteert het crawlgedrag van de site of directory, terwijl meta en x-robots indexatiegedrag kunnen dicteren op het niveau van de individuele pagina (of pagina-element).
Blijf leren
- Robots Meta Directives
- Canonicalization
- Redirection
- Robots Exclusion Protocol
Zet je vaardigheden aan het werk
Moz Pro kan vaststellen of uw robots.txt-bestand onze toegang tot uw website blokkeert. Probeer het > >
