Vad är en robots.txt-fil?
Robots.txt är en textfil som webbansvariga skapar för att instruera webbrobotar ( vanligtvis sökmotorrobotar) hur man genomsöker sidor på deras webbplats. Robots.txt-filen är en del av protokollet för uteslutning av robotar (REP), en grupp webbstandarder som reglerar hur robotar genomsöker webben, får åtkomst till och indexerar innehåll och serverar innehållet upp till användarna. REP innehåller också direktiv som meta-robotar, samt instruktioner för sid-, underkatalog- eller webbplatsövergripande instruktioner för hur sökmotorer ska behandla länkar (som ”följ” eller ”nofollow”).
I I praktiken anger robots.txt-filer om vissa användaragenter (webbgenomsökande programvara) kan eller inte kan genomsöka delar av en webbplats. Dessa genomsökningsinstruktioner specificeras genom att ”tillåta” eller ”tillåta” beteendet hos vissa (eller alla) användaragenter.
Grundformat:
User-agent: Disallow:
Tillsammans betraktas dessa två rader som en komplett robots.txt-fil – även om en robotfil kan innehålla flera rader med användaragenter och -direktiv (dvs. tillåter, tillåter, genomsökningsfördröjningar etc.).
Inom en robots.txt-fil visas varje uppsättning användaragentdirektiv som en diskret uppsättning, åtskild av en radbrytning:
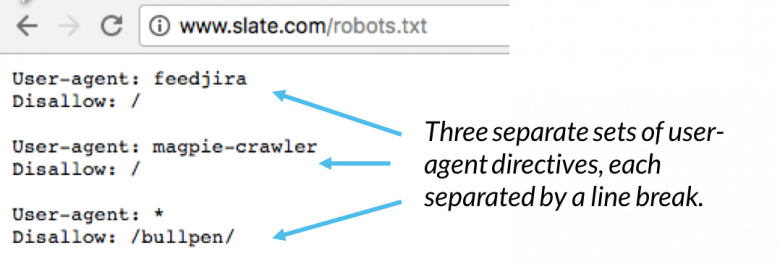
I en robots.txt-fil med flera användaragentdirektiv gäller varje tillåtna eller tillåtna regel endast användaragenten ( s) specificerad i den specifika radbrytningsuppsättningen. Om filen innehåller en regel som gäller för mer än en användaragent, kommer en sökrobot bara att ta hänsyn till (och följa direktiven i) den mest specifika gruppen av instruktioner.
Här är ett exempel:
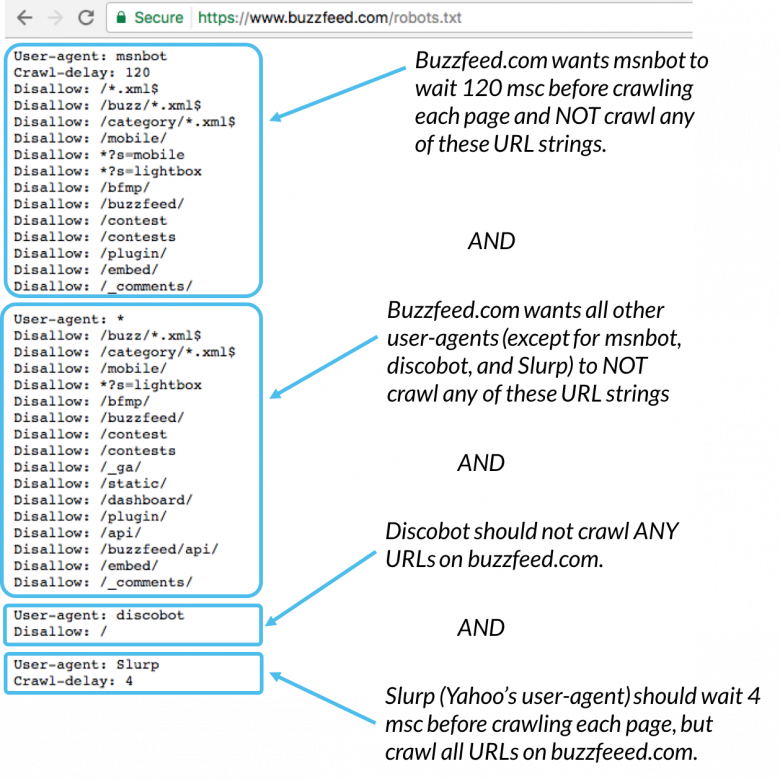
Msnbot, discobot och Slurp kallas alla specifikt, så dessa användaragenter kommer bara att uppmärksamma riktlinjerna i deras avsnitt i filen robots.txt. Alla andra användaragenter följer anvisningarna i användaragenten: * -gruppen.
Exempel på robots.txt:
Här är några exempel på robots.txt i aktion för en www.example.com-webbplats:
Robots.txt-fil-URL: www.example.com/robots.txt
Blockering av alla webbsökare från allt innehåll
User-agent: * Disallow: /
Att använda denna syntax i en robots.txt-fil skulle säga att alla webbsökare inte ska genomsöka några sidor på www.example.com, inklusive hemsidan.
Tillåter alla webbsökare har tillgång till allt innehåll
User-agent: * Disallow:
Med hjälp av denna syntax i en robots.txt-fil ber webbsökare att genomsöka alla sidor på www.example.com, inklusive hemsidan.
Blockera en specifik webbsökare från en specifik mapp
User-agent: Googlebot Disallow: /example-subfolder/
Denna syntax berättar endast Googles sökrobot (användaragentnamn Googlebot ) att inte genomsöka några sidor som innehåller URL-strängen www.example.com/exempel-submapp/.
Blockera en specifik webbsökare från en viss webbsida
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Denna syntax berättar bara Bings sökrobot (användaragentnamn Bing) för att undvika att genomsöka den specifika sidan på www.example.com/exempel-submapp/spärrad sida .html.
Hur fungerar robots.txt?
Sökmotorer har två huvudjobb:
- Genomsökning på nätet för att upptäcka innehåll;
- Indexera innehållet så att det kan visas för sökare som letar efter information.
För att genomsöka webbplatser följer sökmotorer länkar för att komma från en webbplats till en annan – i slutändan genomsökning över många miljarder länkar och webbplatser. Detta genomsökningsbeteende kallas ibland ”spidering.”
Efter att ha kommit till en webbplats men innan den spiderar den, kommer sökroboten att leta efter en robots.txt-fil. Om den hittar en, kommer sökroboten att läsa den först innan du fortsätter genom sidan. Eftersom robots.txt-filen innehåller information om hur sökmotorn ska genomsöka kommer den information som finns där att instruera ytterligare sökrobotåtgärder på den här webbplatsen. Om robots.txt-filen inte innehåller några direktiv som tillåta en användaragents aktivitet (eller om webbplatsen inte har en robots.txt-fil) fortsätter den att genomsöka annan information på webbplatsen.
Andra snabba robots.txt måste-veta:
(diskuteras mer detaljerat nedan)
-
För att kunna hittas måste en robots.txt-fil placeras i en webbplats toppkatalog. / p>
-
Robots.txt är skiftlägeskänsligt: filen måste ha namnet ”robots.txt” (inte Robots.txt, robots.TXT eller på annat sätt).
-
Vissa användaragenter (robotar) m ay välj att ignorera din robots.txt-fil. Detta är särskilt vanligt med mer otrevliga sökrobotar som skadliga robotar eller e-postadressskrapor.
-
Filen /robots.txt är en allmänt tillgänglig: lägg bara till /robots.txt till slutet av vilken rotdomän som helst för att se webbplatsens direktiv (om den webbplatsen har en robots.txt-fil!).Det betyder att vem som helst kan se vilka sidor du gör eller inte vill genomsökas, så använd dem inte för att dölja privat användarinformation.
-
Varje underdomän på en rot domänen använder separata robots.txt-filer. Detta innebär att både blog.example.com och example.com ska ha sina egna robots.txt-filer (på blog.example.com/robots.txt och example.com/robots.txt).
-
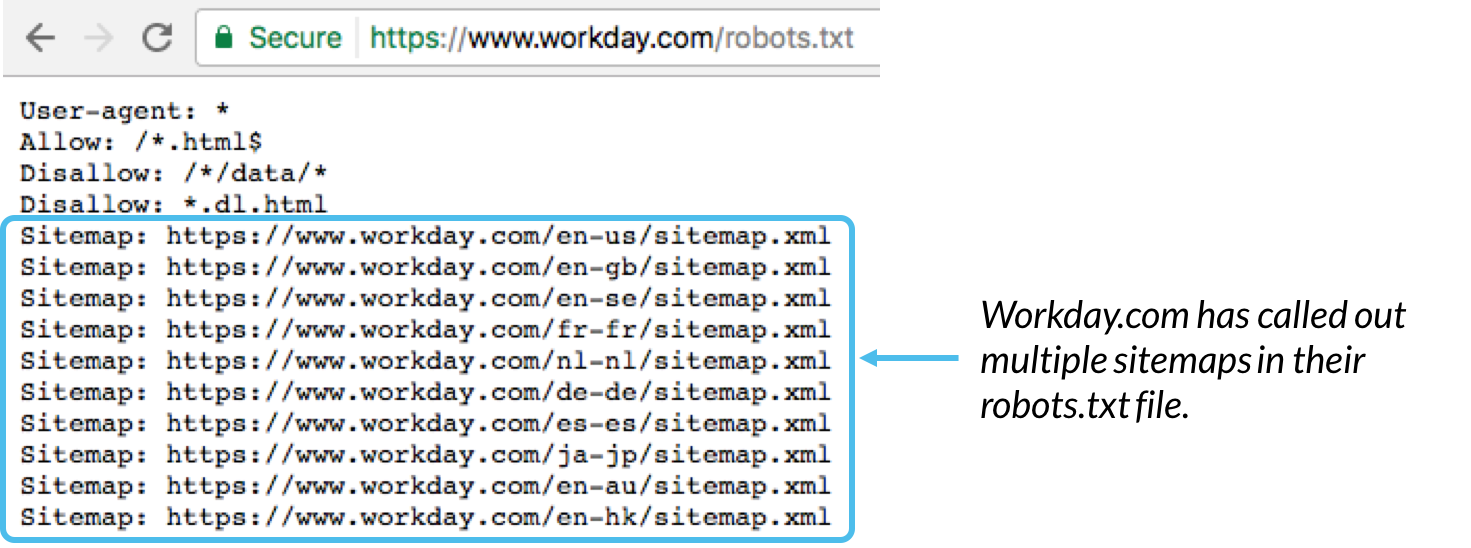
Det är i allmänhet en bästa praxis att ange platsen för eventuella webbplatskartor som är kopplade till den här domänen längst ner i filen robots.txt. Här är ett exempel:
Teknisk robots.txt-syntax
Robots.txt-syntax kan betraktas som ”språket” för robots.txt-filer. Det finns fem vanliga termer som du troligtvis stöter på i en robot De inkluderar:
-
User-agent: Den specifika webbsökaren som du ger genomsökningsinstruktioner till (vanligtvis en sökmotor). En lista över de flesta användaragenter finns här.
-
Avvisa: Kommandot som används för att berätta för en användaragent att inte genomsöka en viss webbadress. Endast en rad ”Tillåt:” är tillåten för varje webbadress.
-
Tillåt (Gäller endast för Googlebot): Kommandot att berätta för Googlebot att det kan komma åt en sida eller undermapp även om dess överordnade sida eller undermapp kan tillåtas.
-
Genomsökningsfördröjning: Hur många sekunder en sökrobot ska vänta innan sidan laddas och genomsöks. Observera att Googlebot inte bekräftar detta kommando, men genomsökningshastigheten kan ställas in n Google Search Console.
-
Sitemap: Används för att anropa platsen för alla XML-webbplatskartor som är associerade med denna URL. Observera att det här kommandot endast stöds av Google, Ask, Bing och Yahoo.
Mönstermatchning
När det gäller de faktiska webbadresserna att blockera eller tillåt, robots.txt-filer kan bli ganska komplexa eftersom de tillåter användning av mönstermatchning för att täcka en rad möjliga URL-alternativ. Google och Bing hedrar båda två reguljära uttryck som kan användas för att identifiera sidor eller undermappar som en SEO vill utesluta. Dessa två tecken är asterisken (*) och dollartecknet ($).
- * är ett jokertecken som representerar vilken teckenföljd som helst
- $ matchar slutet på URL
Google erbjuder en bra lista över möjliga mönstermatchande syntax och exempel här.
Var går robots.txt på en webbplats?
När de kommer till en webbplats vet sökmotorer och andra webb-genomsökande robotar (som Facebooks sökrobot, Facebot) att leta efter en robots.txt-fil. Men de letar bara efter den filen på en viss plats: huvudkatalogen (vanligtvis din rotdomän eller startsida). Om en användaragent besöker www.example.com/robots.txt och inte hittar en robotfil där, antar den att webbplatsen inte har en och fortsätter med att genomsöka allt på sidan (och kanske till och med på hela webbplatsen). Även om robots.txt-sidan fanns på exempelvis.com/index/robots.txt eller www.example.com/homepage/robots.txt, skulle den inte upptäckas av användaragenter och därmed skulle webbplatsen behandlas som om den inte hade någon robotfil alls.
För att säkerställa att din robots.txt-fil hittas, inkludera den alltid i din huvudkatalog eller rotdomän.
Varför gör du behöver robots.txt?
Robots.txt-filer styr sökrobotens åtkomst till vissa områden på din webbplats. Även om detta kan vara mycket farligt om du av misstag avvisar Googlebot att genomsöka hela din webbplats (!!), finns det vissa situationer där en robots.txt-fil kan vara väldigt användbar.
Några vanliga användningsfall inkluderar:
- Att förhindra att duplicerat innehåll visas i SERP (observera att meta-robotar ofta är ett bättre val för detta)
- Att hålla hela delar av en webbplats privat (till exempel din teknik lagets iscensättningswebbplats)
- Förhindrar att interna sökresultatsidor visas på en offentlig SERP
- Ange plats för webbplatskartor vissa filer på din webbplats (bilder, PDF-filer etc.)
- Ange en genomsökningsfördröjning för att förhindra att dina servrar överbelastas när sökrobotar läser in flera delar av innehåll samtidigt
Om det inte finns några områden på din webbplats som du vill styra åtkomst till user-agent till, kanske du inte behöver en robots.txt-fil alls.
Kontrollerar om du har en robot s.txt-fil
Inte säker på om du har en robots.txt-fil? Skriv bara in din rotdomän och lägg sedan till /robots.txt i slutet av webbadressen. Mozs robotfil finns till exempel på moz.com/robots.txt.
Om ingen .txt-sida visas har du för närvarande inte en (live) robots.txt-sida.
Så här skapar du en robots.txt-fil
Om du upptäckte att du inte hade någon robots.txt-fil eller vill ändra din är det enkelt att skapa en. Den här artikeln från Google går igenom processen för skapande av robots.txt-fil, och det här verktyget låter dig testa om din fil är korrekt inställd.
Letar du efter övning på att skapa robotfiler?Det här blogginlägget går igenom några interaktiva exempel.
Bästa metoder för SEO
-
Se till att du inte blockerar något innehåll eller delar av din webbplats du vill genomsöka.
-
Länkar på sidor som blockeras av robots.txt följs inte. Detta betyder 1.) Om de inte också är länkade från andra sidor som är tillgängliga för sökmotorer (dvs. sidor som inte blockeras via robots.txt, metarobotar eller på annat sätt), genomsöks de länkade resurserna och kan inte indexeras. 2.) Inget länkkapital kan överföras från den blockerade sidan till länkdestinationen. Om du har sidor som du vill att eget kapital ska skickas till, använd en annan blockeringsmekanism än robots.txt.
-
Använd inte robots.txt för att förhindra känsliga data (som privat användarinformation) från att visas i SERP-resultat. Eftersom andra sidor kan länka direkt till sidan som innehåller privat information (därmed kringgå robots.txt-direktiven på din rotdomän eller startsida) kan den fortfarande indexeras. Om du vill blockera din sida från sökresultaten, använd en annan metod som lösenordsskydd eller noindex metadirektivet.
-
Vissa sökmotorer har flera användaragenter. Till exempel använder Google Googlebot för organisk sökning och Googlebot-Image för bildsökning. De flesta användaragenter från samma sökmotor följer samma regler så det finns inget behov av att ange riktlinjer för var och en av sökmotorns flera sökrobotar, men om du har förmågan att göra det kan du finjustera hur webbplatsens innehåll genomsöks.
-
En sökmotor cachar innehållet i robots.txt, men uppdaterar vanligtvis det cachade innehållet minst en gång om dagen. Om du ändrar filen och vill uppdatera den snabbare än vad som händer kan du skicka din robots.txt-webbadress till Google.
Robots.txt vs meta-robotar vs x -roboter
Så många robotar! Vad är skillnaden mellan dessa tre typer av robotinstruktioner? För det första är robots.txt en faktisk textfil, medan meta- och x-robotar är metadirektiv. Utöver vad de faktiskt är, har de tre olika funktioner. Robots.txt dikterar genomsökningsbeteende på webbplatsen eller katalogen, medan meta- och x-robotar kan diktera indexeringsbeteende på den enskilda sidornas (eller sidelement) nivå.
Fortsätt lära dig
- Robots metadirektiv
- Canonicalization
- Omdirigering
- Robots Exclusion Protocol
Sätt dina kunskaper i arbete
Moz Pro kan identifiera om din robots.txt-fil blockerar vår åtkomst till din webbplats. Prova > >
