robots.txtファイルとは
Robots.txtは、ウェブマスターがウェブロボットに指示するために作成するテキストファイルです(通常、検索エンジンロボット)Webサイトのページをクロールする方法。 robots.txtファイルは、ロボットがWebをクロールし、コンテンツにアクセスしてインデックスを作成し、そのコンテンツをユーザーに提供する方法を規制するWeb標準のグループであるロボット除外プロトコル(REP)の一部です。 REPには、メタロボットなどのディレクティブのほか、検索エンジンがリンクを処理する方法(「follow」や「nofollow」など)に関するページ全体、サブディレクトリ、またはサイト全体の指示も含まれています。
In実際には、robots.txtファイルは、特定のユーザーエージェント(Webクロールソフトウェア)がWebサイトの一部をクロールできるかどうかを示します。これらのクロール手順は、特定の(またはすべての)ユーザーエージェントの動作を「禁止」または「許可」することで指定されます。
基本形式:
User-agent: Disallow:
まとめると、これら2行は完全なrobots.txtファイルと見なされます。ただし、1つのrobotsファイルには、複数行のユーザーエージェントとディレクティブ(つまり、disallows、allows、crawl-delaysなど)を含めることができます。
robots.txtファイル内では、ユーザーエージェントディレクティブの各セットは、改行で区切られた個別のセットとして表示されます。
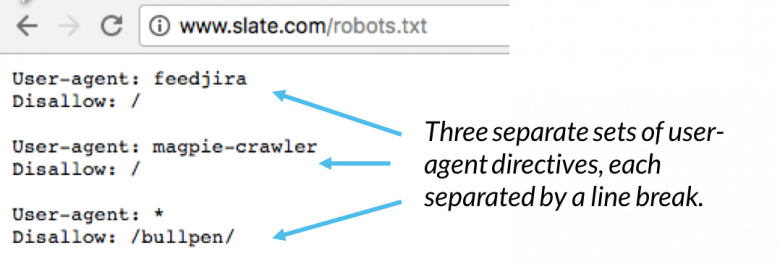
複数のuser-agentディレクティブを含むrobots.txtファイルでは、それぞれのdisallowまたはallowルールはuseragent(にのみ適用されます。 s)その特定の改行で区切られたセットで指定されています。ファイルに複数のユーザーエージェントに適用されるルールが含まれている場合、クローラーは最も具体的な命令のグループにのみ注意を払います(そしてその指示に従います)。
例を次に示します。
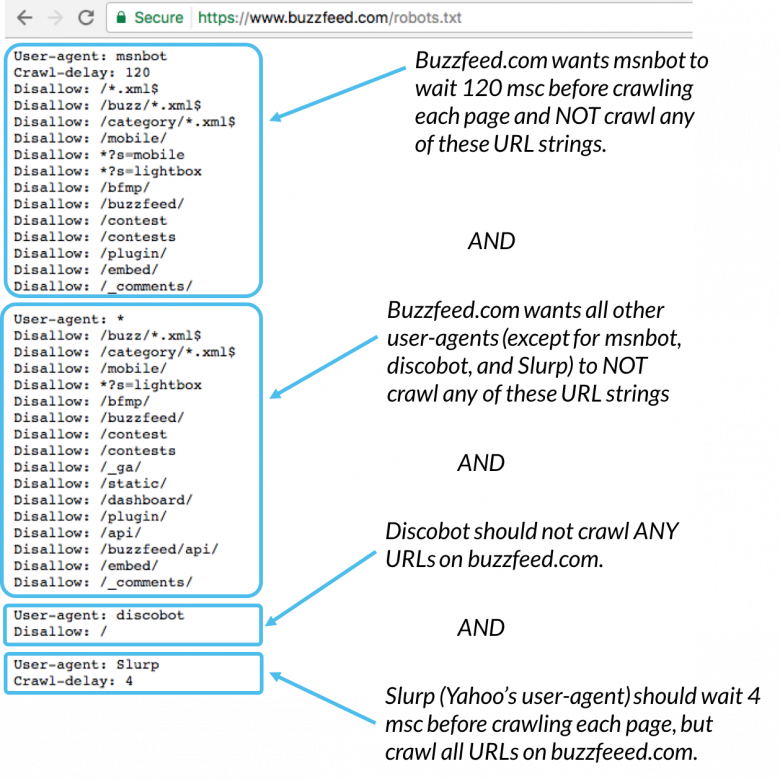
Msnbot、discobot、Slurpはすべて呼び出されます具体的には、これらのユーザーエージェントはrobots.txtファイルのセクションにあるディレクティブにのみ注意を払います。他のすべてのuser-agentは、user-agent:* groupのディレクティブに従います。
robots.txtの例:
ここでは、robots.txtの動作例をいくつか示します。 www.example.comサイト:
Robots.txtファイルのURL:www.example.com/robots.txt
すべてのコンテンツからすべてのWebクローラーをブロックする
User-agent: * Disallow: /
robots.txtファイルでこの構文を使用すると、すべてのWebクローラーに、ホームページを含むwww.example.comのページをクロールしないように指示します。
許可すべてのWebクローラーがすべてのコンテンツにアクセスする
User-agent: * Disallow:
robots.txtファイルでこの構文を使用すると、Webクローラーはwww.example.comのすべてのページをクロールするようになります。ホームページ。
特定のフォルダから特定のウェブクローラーをブロックする
User-agent: Googlebot Disallow: /example-subfolder/
この構文は、Googleのクローラー(ユーザーエージェント名Googlebot)のみに通知します。 )URL文字列www.example.com/example-subfolder/を含むページをクロールしないでください。
特定のWebページから特定のWebクローラーをブロックする
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
この構文は、Bingのクローラー(ユーザーエージェント名Bing)にのみ、www.example.com / example-subfolder / blocked-pageの特定のページをクロールしないように指示します。 .html。
robots.txtはどのように機能しますか?
検索エンジンには2つの主要な仕事があります:
- コンテンツを見つけるためにウェブをクロールする;
- 情報を探している検索者に配信できるように、そのコンテンツにインデックスを付けます。
サイトをクロールするには、検索エンジンはリンクをたどって、あるサイトから別のサイトに移動します。最終的にはクロールします。何十億ものリンクやウェブサイトにまたがって。このクロール動作は「スパイダリング」と呼ばれることもあります。
ウェブサイトにアクセスした後、スパイダリングする前に、検索クローラーはrobots.txtファイルを探します。ファイルが見つかると、クローラーはそれを読み取ります。 robots.txtファイルには検索エンジンがクロールする方法に関する情報が含まれているため、そこで見つかった情報は、この特定のサイトでのクローラーアクションをさらに指示します。robots.txtファイルに次のようなディレクティブが含まれていない場合ユーザーエージェントのアクティビティを禁止すると(またはサイトにrobots.txtファイルがない場合)、サイト上の他の情報のクロールに進みます。
その他のクイックrobots.txtの必知事項:
(以下で詳しく説明します)
-
検索するには、robots.txtファイルをウェブサイトの最上位ディレクトリに配置する必要があります。
-
Robots.txtは大文字と小文字が区別されます。ファイルには、「robots.txt」という名前を付ける必要があります(Robots.txt、robots.TXTなどではありません)。
-
一部のユーザーエージェント(ロボット)m robots.txtファイルを無視することを選択できます。これは、マルウェアロボットやメールアドレススクレーパーなどのより悪質なクローラーで特に一般的です。
-
/robots.txtファイルは公開されています。末尾に/robots.txtを追加するだけです。そのウェブサイトのディレクティブを確認するための任意のルートドメインの(そのサイトにrobots.txtファイルがある場合!)。つまり、誰もがあなたが行っているページやクロールしたくないページを見ることができるので、それらを使用して個人ユーザー情報を非表示にしないでください。
-
ルート上の各サブドメインドメインは個別のrobots.txtファイルを使用します。つまり、blog.example.comとexample.comの両方に独自のrobots.txtファイル(blog.example.com/robots.txtとexample.com/robots.txt)が必要です。
-
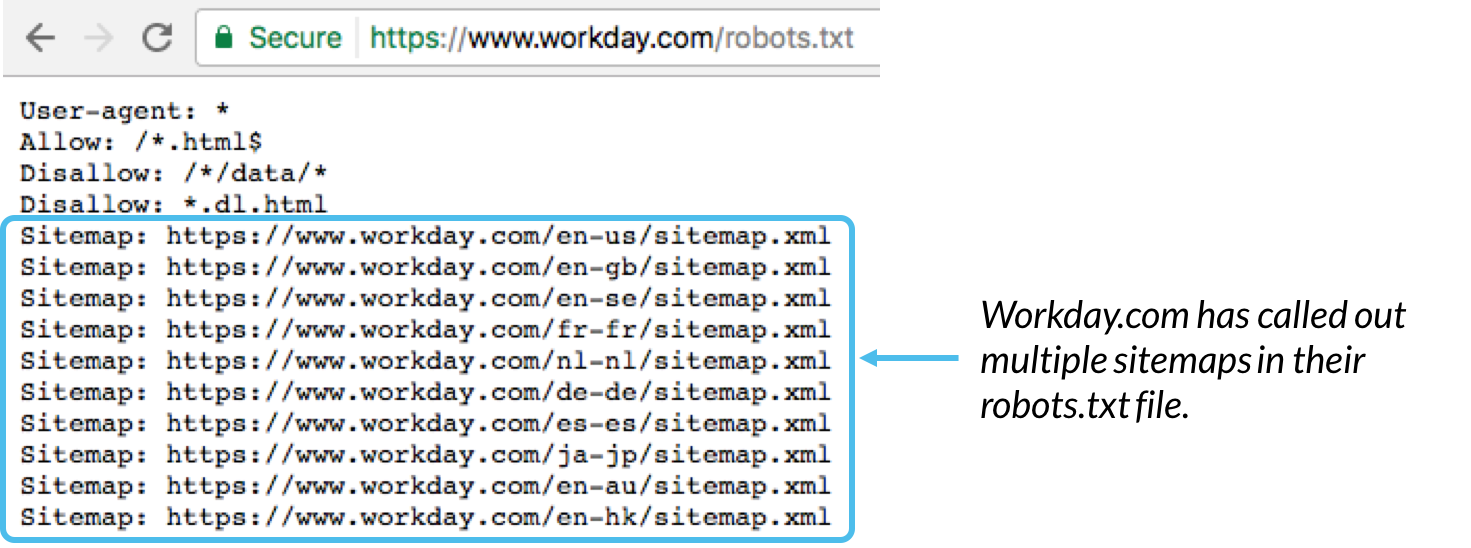
一般的に、robots.txtファイルの下部にこのドメインに関連付けられているサイトマップの場所を示すのがベストプラクティスです。次に例を示します。
技術的なrobots.txt構文
Robots.txt構文は、robots.txtファイルの「言語」と考えることができます。ロボットでよく見られる用語は5つあります。ファイル。次のものが含まれます。
-
ユーザーエージェント:クロール指示を送信する特定のウェブクローラー(通常は検索エンジン)。ほとんどのユーザーエージェントのリストがあります。ここ。
-
Disallow:特定のURLをクロールしないようにユーザーエージェントに指示するために使用されるコマンド。各URLに許可される「Disallow:」行は1つだけです。
-
許可(Googlebotにのみ適用可能):親ページまたはサブフォルダーが許可されていない場合でも、ページまたはサブフォルダーにアクセスできることをGooglebotに通知するコマンド。
-
Crawl-delay:ページコンテンツを読み込んでクロールする前にクローラーが待機する秒数。Googlebotはこのコマンドを認識しませんが、クロール速度は設定できます。 n Google SearchConsole。
-
サイトマップ:このURLに関連付けられているXMLサイトマップの場所を呼び出すために使用されます。このコマンドは、Google、Ask、Bing、Yahooでのみサポートされていることに注意してください。
パターンマッチング
ブロックする実際のURLに関してはまたは許可すると、robots.txtファイルは、パターンマッチングを使用して、可能なURLオプションの範囲をカバーできるため、かなり複雑になる可能性があります。 GoogleとBingはどちらも、SEOが除外したいページまたはサブフォルダーを識別するために使用できる2つの正規表現を尊重します。これらの2つの文字は、アスタリスク(*)とドル記号($)です。
- *は、任意の文字シーケンスを表すワイルドカードです
- $は、 URL
Googleは、パターンマッチングの可能な構文と例の優れたリストをここに提供しています。
robots.txtはサイトのどこにありますか?
サイトにアクセスするたびに、検索エンジンやその他のWebクロールロボット(FacebookのクローラーやFacebotなど)はrobots.txtファイルを探すことを知っています。ただし、そのファイルは、メインディレクトリ(通常はルートドメインまたはホームページ)という1つの特定の場所でのみ検索されます。ユーザーエージェントがwww.example.com/robots.txtにアクセスし、そこにロボットファイルが見つからない場合、サイトにロボットファイルがないと見なされ、ページ上のすべて(場合によってはサイト全体)のクロールが続行されます。 robots.txtページがexample.com/index/robots.txtやwww.example.com/homepage/robots.txtなどに存在していても、ユーザーエージェントによって検出されないため、サイトは扱われます。まるでrobotsファイルがまったくないかのように。
robots.txtファイルが確実に見つかるように、常にメインディレクトリまたはルートドメインに含めてください。
なぜですか。 robots.txtが必要ですか?
Robots.txtファイルは、サイトの特定の領域へのクローラーアクセスを制御します。誤ってGooglebotによるサイト全体のクロールを禁止した場合(!!)、これは非常に危険ですが、robots.txtファイルが非常に便利な場合があります。
一般的な使用例は次のとおりです。
- 重複コンテンツがSERPに表示されないようにする(メタロボットの方が適している場合が多いことに注意してください)
- Webサイトのセクション全体を非公開にする(たとえば、エンジニアリングチームのステージングサイト)
- 内部検索結果ページが公開SERPに表示されないようにする
- サイトマップの場所を指定する
- 検索エンジンがインデックスに登録されないようにするウェブサイト上の特定のファイル(画像、PDFなど)
- クローラーが複数のコンテンツを一度にロードするときにサーバーが過負荷になるのを防ぐためにクロール遅延を指定します
サイトにユーザーエージェントアクセスを制御する領域がない場合は、robots.txtファイルはまったく必要ない可能性があります。
ロボットがあるかどうかを確認するs.txtファイル
robots.txtファイルがあるかどうかわかりませんか?ルートドメインを入力し、URLの末尾に/robots.txtを追加するだけです。たとえば、Mozのrobotsファイルはmoz.com/robots.txtにあります。
.txtページが表示されない場合、現在(ライブの)robots.txtページはありません。
robots.txtファイルを作成する方法
robots.txtファイルがない場合、またはファイルを変更したい場合は、簡単なプロセスで作成できます。 Googleのこの記事では、robots.txtファイルの作成プロセスについて説明します。このツールを使用すると、ファイルが正しく設定されているかどうかをテストできます。
ロボットファイルを作成する練習をお探しですか?このブログ投稿では、インタラクティブな例をいくつか紹介します。
SEOのベストプラクティス
-
クロールするウェブサイトのコンテンツやセクションをブロックしていないことを確認してください。
-
robots.txtによってブロックされたページのリンクはたどられません。つまり、1。)他の検索エンジンでアクセス可能なページ(robots.txtやメタロボットなどでブロックされていないページ)からもリンクされていない限り、リンクされたリソースはクロールされず、インデックスに登録されない可能性があります。 2.)ブロックされたページからリンク先にリンクエクイティを渡すことはできません。公平性を渡すページがある場合は、robots.txt以外の別のブロックメカニズムを使用してください。
-
機密データを防ぐためにrobots.txtを使用しないでください(例:プライベートユーザー情報)がSERP結果に表示されないようにします。他のページが個人情報を含むページに直接リンクしている可能性があるため(したがって、ルートドメインまたはホームページのrobots.txtディレクティブをバイパスする)、インデックスが作成される可能性があります。ページを検索結果からブロックする場合は、パスワード保護やnoindexメタディレクティブなどの別の方法を使用してください。
-
一部の検索エンジンには複数のユーザーエージェントがあります。たとえば、Googleはオーガニック検索にGooglebotを使用し、画像検索にGooglebot-Imageを使用しています。同じ検索エンジンのほとんどのユーザーエージェントは同じルールに従うため、検索エンジンの複数のクローラーごとにディレクティブを指定する必要はありませんが、そうする機能があると、サイトコンテンツのクロール方法を微調整できます。
-
検索エンジンはrobots.txtのコンテンツをキャッシュしますが、通常、キャッシュされたコンテンツは少なくとも1日に1回更新されます。ファイルを変更して、発生するよりも早く更新したい場合は、robots.txtのURLをGoogleに送信できます。
Robots.txt vs meta robots vs x -ロボット
非常に多くのロボット!これら3種類のロボット命令の違いは何ですか?まず、robots.txtは実際のテキストファイルですが、metaおよびx-robotsはメタディレクティブです。それらが実際に何であるかを超えて、3つはすべて異なる機能を果たします。 Robots.txtはサイト全体またはディレクトリ全体のクロール動作を指示しますが、メタロボットとxロボットは個々のページ(またはページ要素)レベルでインデックス作成動作を指示できます。
学習を続ける
- ロボットメタディレクティブ
- 正規化
- リダイレクト
- ロボット除外プロトコル
スキルを活用する
Moz Proは、robots.txtファイルがWebサイトへのアクセスをブロックしているかどうかを識別できます。試してみてください> >
