Che cos’è un file robots.txt?
Robots.txt è un file di testo creato dai webmaster per istruire i robot web ( tipicamente robot dei motori di ricerca) come eseguire la scansione delle pagine del proprio sito web. Il file robots.txt fa parte del protocollo di esclusione dei robot (REP), un gruppo di standard Web che regolano il modo in cui i robot eseguono la scansione del Web, accedono e indicizzano i contenuti e forniscono tali contenuti agli utenti. Il REP include anche direttive come meta robots, nonché istruzioni a livello di pagina, sottodirectory o sito su come i motori di ricerca dovrebbero trattare i link (come “follow” o “nofollow”).
In pratica, i file robots.txt indicano se determinati programmi utente (software di scansione del Web) possono o meno eseguire la scansione di parti di un sito web. Queste istruzioni di scansione vengono specificate “disabilitando” o “consentendo” il comportamento di alcuni (o tutti) gli agenti utente.
Formato di base:
User-agent: Disallow:
Insieme, queste due righe sono considerate un file robots.txt completo, sebbene un file robots possa contenere più righe di programmi utente e direttive (ad esempio, non consente, consente, ritardi di scansione e così via).
All’interno di un file robots.txt, ogni insieme di direttive dell’agente utente viene visualizzato come un insieme distinto, separato da un’interruzione di riga:
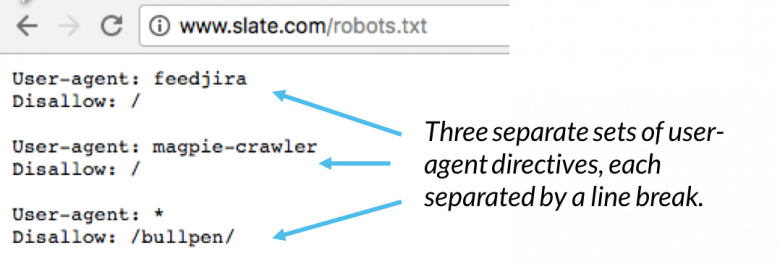
In un file robots.txt con più direttive user-agent, ciascuna regola di non consentire o consentire si applica solo all’agente utente ( s) specificato in quel particolare insieme separato da interruzioni di riga. Se il file contiene una regola che si applica a più di uno user-agent, un crawler presterà attenzione (e seguirà le direttive) solo nel gruppo di istruzioni più specifico.
Ecco un esempio:
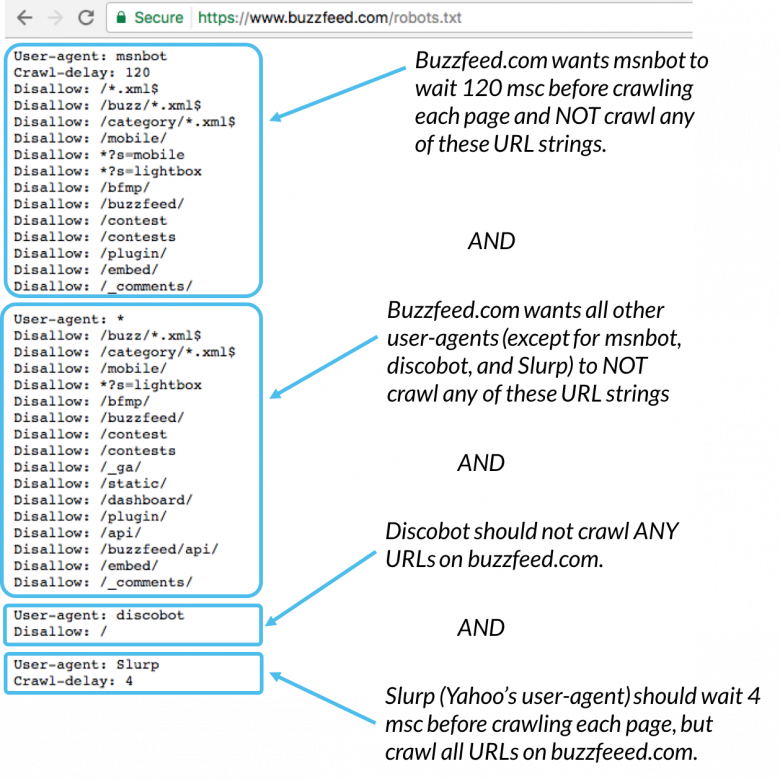
Msnbot, discobot e Slurp sono tutti chiamati in particolare, quindi quegli user-agent presteranno attenzione solo alle direttive nelle loro sezioni del file robots.txt. Tutti gli altri user-agent seguiranno le direttive nello user-agent: * group.
Esempio robots.txt:
Di seguito sono riportati alcuni esempi di robots.txt in azione per un sito www.example.com:
URL file Robots.txt: www.example.com/robots.txt
Blocco di tutti i web crawler da tutti i contenuti
User-agent: * Disallow: /
L’utilizzo di questa sintassi in un file robots.txt indica a tutti i web crawler di non eseguire la scansione di alcuna pagina su www.example.com, inclusa la home page.
Consentire tutti i web crawler accedono a tutti i contenuti
User-agent: * Disallow:
L’utilizzo di questa sintassi in un file robots.txt indica ai web crawler di eseguire la scansione di tutte le pagine su www.example.com, comprese la home page.
Blocco di un web crawler specifico da una cartella specifica
User-agent: Googlebot Disallow: /example-subfolder/
Questa sintassi dice solo al crawler di Google (nome agente utente Googlebot ) per non eseguire la scansione di pagine che contengono la stringa URL www.example.com/example-sottocartella/.
Blocco di un crawler web specifico da una pagina web specifica
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Questa sintassi indica solo al crawler di Bing (nome agente utente Bing) di evitare di eseguire la scansione della pagina specifica all’indirizzo www.example.com/example-subfolder/blocked-page .html.
Come funziona il file robots.txt?
I motori di ricerca hanno due compiti principali:
- Scansione del Web per scoprire i contenuti;
- Indicizzazione del contenuto in modo che possa essere offerto agli utenti che cercano informazioni.
Per eseguire la scansione dei siti, i motori di ricerca seguono i link per spostarsi da un sito all’altro, in ultima analisi, la scansione attraverso molti miliardi di link e siti web. Questo comportamento di scansione è talvolta noto come “spidering”.
Dopo essere arrivato a un sito web ma prima di eseguirlo, il crawler di ricerca cercherà un file robots.txt. Se ne trova uno, lo leggerà file prima di continuare attraverso la pagina. Poiché il file robots.txt contiene informazioni su come il motore di ricerca deve eseguire la scansione, le informazioni trovate indicheranno ulteriori azioni del crawler su questo particolare sito. Se il file robots.txt non contiene alcuna direttiva che non consentire l’attività di uno user-agent (o se il sito non dispone di un file robots.txt), procederà alla scansione di altre informazioni sul sito.
Altre informazioni rapide da conoscere su robots.txt:
(discusso più dettagliatamente di seguito)
-
Per essere trovato, un file robots.txt deve essere inserito nella directory di primo livello di un sito web.
-
Robots.txt distingue tra maiuscole e minuscole: il file deve essere denominato “robots.txt” (non Robots.txt, robots.TXT o altro).
-
Alcuni programmi utente (robot) m scegli di ignorare il tuo file robots.txt. Questo è particolarmente comune con i crawler più malvagi come i robot malware o gli scraper di indirizzi e-mail.
-
Il file /robots.txt è disponibile pubblicamente: basta aggiungere /robots.txt alla fine di qualsiasi dominio principale per vedere le direttive di quel sito web (se quel sito ha un file robots.txt!).Ciò significa che chiunque può vedere quali pagine si desidera o non si desidera sottoporre a scansione, quindi non utilizzarle per nascondere le informazioni degli utenti privati.
-
Ogni sottodominio su una radice dominio utilizza file robots.txt separati. Ciò significa che sia blog.example.com che example.com dovrebbero avere i propri file robots.txt (su blog.example.com/robots.txt e example.com/robots.txt).
-
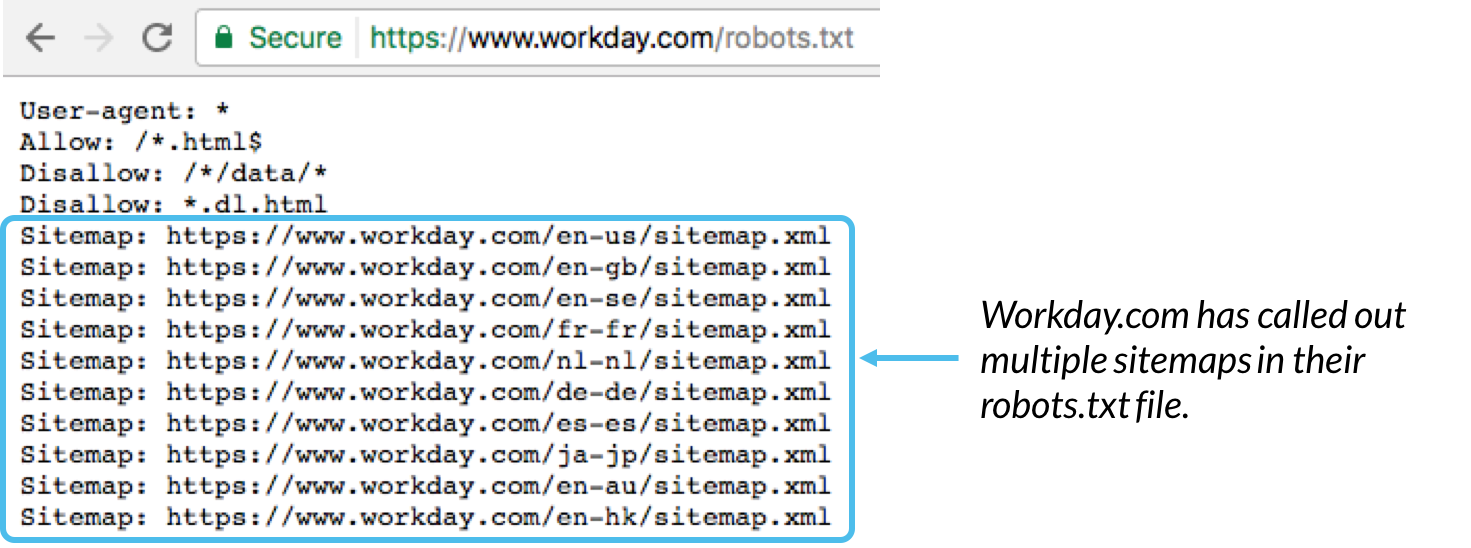
È generalmente una best practice indicare la posizione di qualsiasi Sitemap associata a questo dominio nella parte inferiore del file robots.txt. Ecco un esempio:
Sintassi tecnica del file robots.txt
La sintassi del file robots.txt può essere considerata la “lingua” dei file robots.txt. Ci sono cinque termini comuni che probabilmente incontrerai in un file robots file. Includono:
-
User-agent: il crawler web specifico a cui stai fornendo le istruzioni di scansione (di solito un motore di ricerca). È possibile trovare un elenco della maggior parte degli user agent qui.
-
Disallow: il comando utilizzato per indicare a un agente utente di non eseguire la scansione di un determinato URL. È consentita una sola riga “Disallow:” per ogni URL.
-
Consenti (applicabile solo a Googlebot): il comando per indicare a Googlebot che può accedere a una pagina o una sottocartella anche se la sua pagina principale o la sua sottocartella potrebbero non essere consentite.
-
Ritardo della scansione: quanti secondi un crawler deve attendere prima di caricare ed eseguire la scansione del contenuto della pagina. Tieni presente che Googlebot non riconosce questo comando, ma la velocità di scansione può essere impostata i n Google Search Console.
-
Sitemap: utilizzata per richiamare la posizione di qualsiasi Sitemap XML associata a questo URL. Tieni presente che questo comando è supportato solo da Google, Ask, Bing e Yahoo.
Corrispondenza pattern
Quando si tratta degli URL effettivi da bloccare o consenti, i file robots.txt possono diventare piuttosto complessi in quanto consentono l’uso della corrispondenza dei modelli per coprire una gamma di possibili opzioni URL. Google e Bing rispettano entrambi due espressioni regolari che possono essere utilizzate per identificare pagine o sottocartelle che un SEO vuole escludere. Questi due caratteri sono l’asterisco (*) e il simbolo del dollaro ($).
- * è un carattere jolly che rappresenta qualsiasi sequenza di caratteri
- $ corrisponde alla fine del URL
Google offre un ottimo elenco di possibili sintassi di corrispondenza dei modelli ed esempi qui.
Dove va il file robots.txt su un sito?
Ogni volta che arrivano su un sito, i motori di ricerca e altri robot di scansione del web (come il crawler di Facebook, Facebot) sanno di cercare un file robots.txt. Tuttavia, cercheranno quel file solo in un posto specifico: la directory principale (in genere il tuo dominio principale o la tua home page). Se un programma utente visita www.example.com/robots.txt e non trova un file robots lì, presumerà che il sito non ne abbia uno e procederà con la scansione di tutto sulla pagina (e forse anche dell’intero sito). Anche se la pagina robots.txt esistesse, ad esempio, example.com/index/robots.txt o www.example.com/homepage/robots.txt, non verrebbe scoperta dagli interpreti e quindi il sito verrebbe trattato come se non avesse alcun file robots.
Per assicurarti che il tuo file robots.txt venga trovato, includilo sempre nella directory principale o nel dominio principale.
Perché ti serve il file robots.txt?
I file Robots.txt controllano l’accesso del crawler a determinate aree del tuo sito. Sebbene ciò possa essere molto pericoloso se impedisci accidentalmente a Googlebot di eseguire la scansione dell’intero sito (!!), in alcune situazioni un file robots.txt può essere molto utile.
Alcuni casi d’uso comuni includono:
- Impedire la visualizzazione di contenuti duplicati nelle SERP (tieni presente che i meta robot sono spesso una scelta migliore per questo)
- Mantenere private intere sezioni di un sito web (ad esempio, la tua ingegneria sito di staging del team)
- Impedire la visualizzazione delle pagine dei risultati di ricerca interna su una SERP pubblica
- Specificare la posizione delle Sitemap
- Impedire ai motori di ricerca di indicizzare alcuni file sul tuo sito web (immagini, PDF, ecc.)
- Specificare un ritardo di scansione per evitare che i tuoi server vengano sovraccaricati quando i crawler caricano più contenuti contemporaneamente
Se sul tuo sito non sono presenti aree per cui desideri controllare l’accesso dello user-agent, potresti non aver bisogno di un file robots.txt.
Controllare se hai un robot s.txt
Non sei sicuro di avere un file robots.txt? Digita semplicemente il tuo dominio principale, quindi aggiungi /robots.txt alla fine dell’URL. Ad esempio, il file robots di Moz si trova in moz.com/robots.txt.
Se non viene visualizzata alcuna pagina .txt, al momento non hai una pagina robots.txt (live).
Come creare un file robots.txt
Se hai scoperto di non avere un file robots.txt o desideri modificare il tuo, crearne uno è un processo semplice. Questo articolo di Google illustra il processo di creazione del file robots.txt e questo strumento ti consente di verificare se il tuo file è impostato correttamente.
Cerchi un po ‘di pratica nella creazione di file robots?Questo post del blog illustra alcuni esempi interattivi.
Best practice SEO
-
Assicurati di non bloccare alcun contenuto o sezione del tuo sito web che desideri sottoporre a scansione.
-
I link alle pagine bloccate da robots.txt non verranno seguiti. Ciò significa 1.) A meno che non siano collegati anche da altre pagine accessibili ai motori di ricerca (ad es. Pagine non bloccate tramite robots.txt, meta robots o altro), le risorse collegate non verranno sottoposte a scansione e potrebbero non essere indicizzate. 2.) Non è possibile trasferire l’equità del collegamento dalla pagina bloccata alla destinazione del collegamento. Se disponi di pagine a cui desideri trasferire l’equità, utilizza un meccanismo di blocco diverso da robots.txt.
-
Non utilizzare robots.txt per impedire dati sensibili (come informazioni utente privato) da apparire nei risultati SERP. Poiché altre pagine possono collegarsi direttamente alla pagina contenente informazioni private (aggirando così le direttive robots.txt sul tuo dominio principale o sulla home page), potrebbe comunque essere indicizzata. Se desideri bloccare la tua pagina dai risultati di ricerca, utilizza un metodo diverso come la protezione tramite password o la meta direttiva noindex.
-
Alcuni motori di ricerca hanno più agenti utente. Ad esempio, Google utilizza Googlebot per la ricerca organica e Googlebot-Image per la ricerca di immagini. La maggior parte degli interpreti dello stesso motore di ricerca segue le stesse regole, quindi non è necessario specificare direttive per ciascuno dei molteplici crawler di un motore di ricerca, ma avere la possibilità di farlo ti consente di mettere a punto il modo in cui il contenuto del tuo sito viene sottoposto a scansione.
-
Un motore di ricerca memorizzerà nella cache i contenuti del file robots.txt, ma di solito aggiorna i contenuti nella cache almeno una volta al giorno. Se modifichi il file e desideri aggiornarlo più rapidamente di quanto si stia verificando, puoi inviare il tuo URL robots.txt a Google.
Robots.txt vs meta robots vs x -robot
Quanti robot! Qual è la differenza tra questi tre tipi di istruzioni del robot? Prima di tutto, robots.txt è un vero file di testo, mentre meta e x-robots sono meta direttive. Al di là di quello che sono in realtà, i tre hanno tutte funzioni diverse. Robots.txt determina il comportamento di scansione del sito o dell’intera directory, mentre i meta e x-robots possono dettare il comportamento di indicizzazione a livello di singola pagina (o elemento di pagina).
Continua a imparare
- Meta direttive sui robot
- Canonicalizzazione
- Reindirizzamento
- Protocollo di esclusione dei robot
Metti al lavoro le tue capacità
Moz Pro può identificare se il tuo file robots.txt sta bloccando il nostro accesso al tuo sito web. Prova > >
