Introduction
Quel est l’un des concepts les plus importants et fondamentaux des statistiques qui nous permettent de faire de la modélisation prédictive, et pourtant cela confond souvent les scientifiques en herbe? Oui, je parle du théorème de la limite centrale.
C’est un concept statistique puissant que chaque data scientist DOIT connaître. Maintenant, pourquoi est-ce?
Eh bien, le théorème de limite central (CLT) est au cœur des tests d’hypothèses – un composant critique du cycle de vie de la science des données. C’est vrai, l’idée qui nous permet d’explorer les vastes possibilités des données qui nous sont fournies provient de CLT. C’est en fait une notion simple à comprendre, mais la plupart des data scientists se débattent à cette question lors des entretiens.
Nous comprendrons le concept of Central Limit Theorem (CLT) dans cet article. Nous verrons pourquoi il est important, où il est utilisé, puis nous apprendrons comment l’appliquer dans R.
Je vous recommande de parcourir l’article ci-dessous si vous avez besoin d’un rappel rapide sur la distribution et ses différents types:
- 6 distributions de probabilité communes que tout professionnel de la science des données devrait connaître
Table des matières
- Qu’est-ce que le théorème central des limites (CLT )?
- Importance du théorème central des limites
- Importance statistique
- Applications pratiques
- Hypothèses derrière les Théorème de limite central
- Implémentation du théorème de limite centrale dans R
Qu’est-ce que le théorème de limite centrale (CLT)?
Comprenons la limite centrale théorème à l’aide d’un exemple. Cela vous aidera à comprendre intuitivement comment CLT fonctionne en dessous.
Considérez qu’il y a 15 sections dans le département des sciences d’une université et que chaque section accueille environ 100 étudiants. Notre tâche est de calculer le poids moyen des étudiants du département des sciences. Cela semble simple, n’est-ce pas?
L’approche que j’obtiens des aspirants data scientists consiste simplement à calculer la moyenne:
- Premièrement, mesurez le poids de tous les étudiants du département des sciences
- Additionnez tous les poids
- Enfin, divisez la somme totale des poids par le nombre total d’élèves pour obtenir la moyenne
Mais que faire si la taille des données est énorme? Cette approche a-t-elle un sens? Pas vraiment – mesurer le poids de tous les élèves sera un processus très fastidieux et long. Alors, que pouvons-nous faire à la place? Examinons une autre approche.
- D’abord, tirez au sort des groupes d’élèves de la classe. Nous appellerons cela un échantillon. Nous allons dessiner plusieurs échantillons, chacun composé de 30 élèves.

Source: http://www.123rf.com
- Calculez la moyenne individuelle de ces échantillons
- Calculez la moyenne de ces moyennes d’échantillon
- Cette valeur nous donnera le poids moyen approximatif des étudiants du département de sciences
- De plus, l’histogramme de l’échantillon des poids moyens des étudiants ressemblera à une courbe en cloche (ou distribution normale)
C’est, en un mot, ce qu’est le théorème de la limite centrale. Si vous suivez votre apprentissage à travers des vidéos, consultez l’introduction ci-dessous du théorème de limite central. Cela fait partie du module de statistiques complet du cours «Introduction à la science des données»:
Définition formelle du théorème central des limites
Mettons une définition formelle à CLT:
Étant donné un ensemble de données avec une distribution inconnue (il peut être uniforme, binomial ou complètement aléatoire), les moyennes de l’échantillon se rapprocheront de la distribution normale.
Ces échantillons doivent être de taille suffisante. La distribution des moyennes d’échantillons, calculées à partir d’échantillons répétés, tendra vers la normalité à mesure que la taille de vos échantillons augmente.
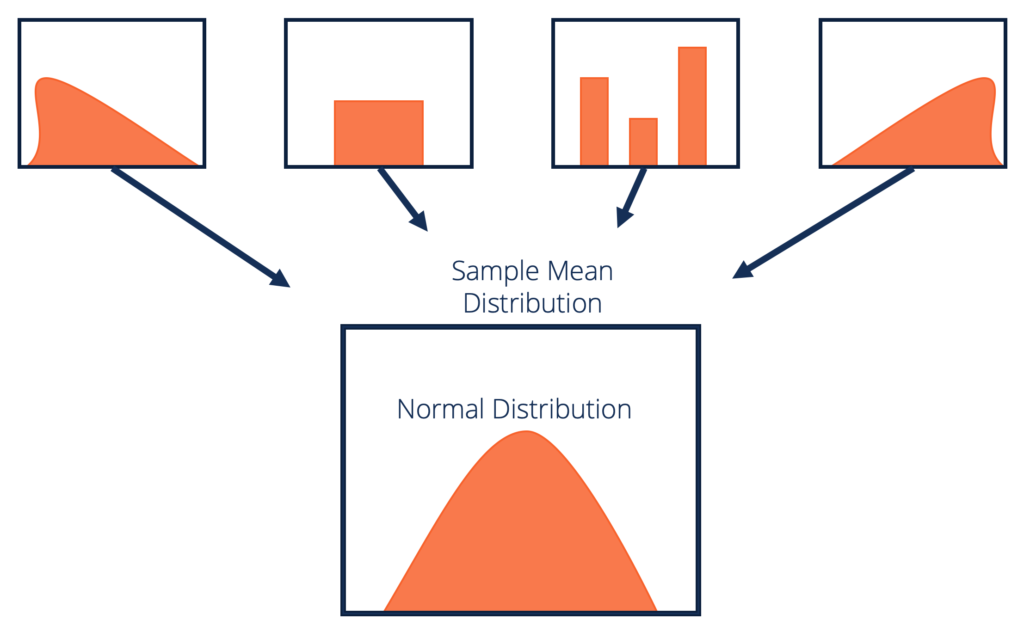
Source: corporatefinanceinstitute.com
Le théorème de limite centrale a une grande variété d’applications dans de nombreux domaines. Examinons-les dans la section suivante.
Signification du théorème central limite
Le théorème central limite a à la fois une signification statistique et des applications pratiques . N’est-ce pas le point idéal que nous visons lorsque nous apprenons un nouveau concept?
Nous examinerons les deux aspects pour déterminer où nous pouvons les utiliser.
Importance statistique de CLT

Source: http://srjcstaff.santarosa.edu
- L’analyse des données implique des méthodes statistiques telles que le test d’hypothèse et la construction d’intervalles de confiance. Ces méthodes supposent que la population est normalement distribuée.Dans le cas de distributions inconnues ou non normales, nous traitons la distribution d’échantillonnage comme normale selon le théorème central limite
- Si nous augmentons les échantillons prélevés dans la population, l’écart type des moyennes d’échantillons diminuera. Cela nous aide à estimer la moyenne de la population avec beaucoup plus de précision
- En outre, la moyenne de l’échantillon peut être utilisée pour créer la plage de valeurs connue sous le nom d’intervalle de confiance (qui est probablement constituée de la moyenne de la population)
Applications pratiques du CLT
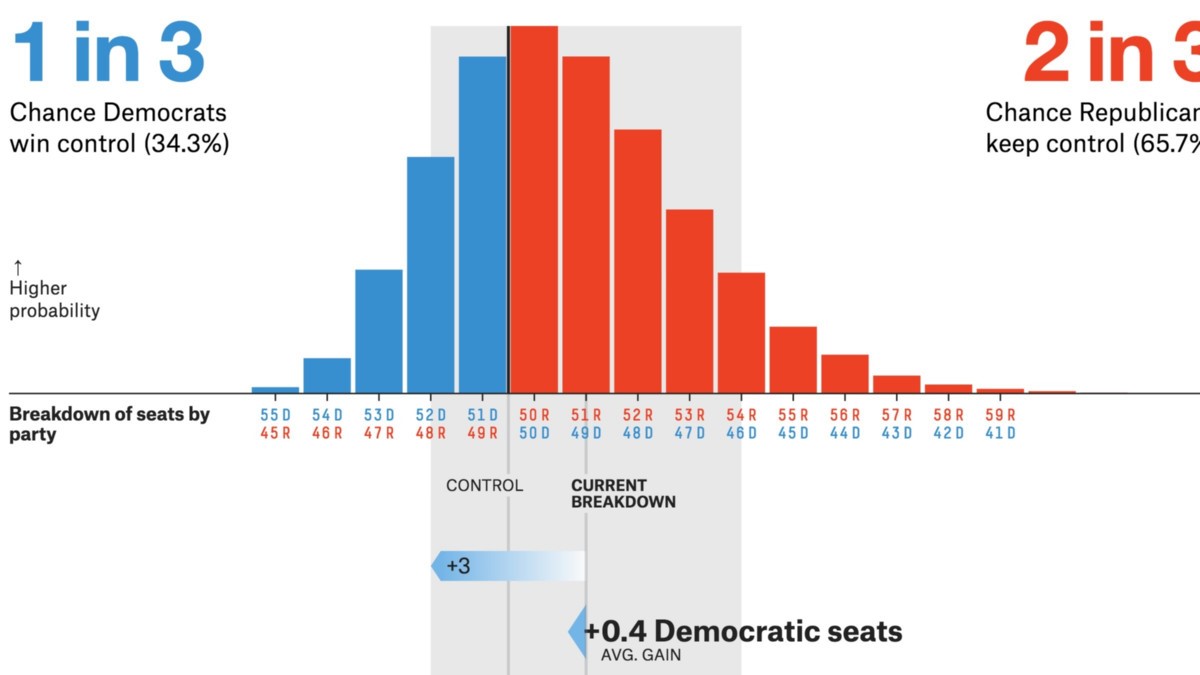
Source: projets .fivethirtyeight.com
- Les sondages politiques / électoraux sont les principales applications CLT. Ces sondages estiment le pourcentage de personnes qui soutiennent un candidat en particulier. Vous avez peut-être vu ces résultats sur les chaînes d’information qui ont des intervalles de confiance. Le théorème de la limite centrale permet de calculer que
- L’intervalle de confiance, une application du CLT, est utilisé pour calculer le revenu familial moyen pour une région particulière
Le théorème de la limite centrale a de nombreuses applications dans différents domaines. Pouvez-vous penser à d’autres exemples? Faites-le moi savoir dans la section des commentaires sous l’article – je vais les inclure ici.
Hypothèses derrière le théorème de la limite centrale
Avant de plonger dans l’implémentation du théorème de la limite centrale, c’est important pour comprendre les hypothèses derrière cette technique:
- Les données doivent suivre la condition de randomisation. Il doit être échantillonné au hasard.
- Les échantillons doivent être indépendants les uns des autres. Un échantillon ne doit pas influencer les autres échantillons
- La taille de l’échantillon ne doit pas dépasser 10% de la population lorsque l’échantillonnage est effectué sans remplacement
- La taille de l’échantillon doit être suffisamment grande. Maintenant, comment allons-nous déterminer la taille de cette taille? Eh bien, cela dépend de la population. Lorsque la population est asymétrique ou asymétrique, la taille de l’échantillon doit être importante. Si la population est symétrique, alors nous pouvons également tirer de petits échantillons
En général, une taille d’échantillon de 30 est considérée comme suffisante lorsque la population est symétrique.
Le la moyenne des moyennes de l’échantillon est notée:
µ X̄ = µ
où,
- µ X̄ = Moyenne des moyennes de l’échantillon
- µ = Moyenne de la population
Et, l’écart type de la moyenne de l’échantillon est noté:
σ X̄ = σ / sqrt (n)
où,
- σ X̄ = écart-type de la moyenne de l’échantillon
- σ = écart type de la population
- n = taille de l’échantillon
Et c’est tout pour le concept derrière le théorème de la limite centrale. Il est temps de lancer RStudio et de creuser dans l’implémentation de CLT!
Implémentation du théorème de limite central dans R
Excité de voir comment nous pouvons coder le théorème de limite central dans R? Voyons maintenant.
Comprendre l’énoncé du problème
Une organisation de fabrication de tuyaux produit différents types de tuyaux. On nous donne les données mensuelles de l’épaisseur de paroi de certains types de tuyaux. Vous pouvez télécharger les données ici.
L’organisation souhaite analyser les données en effectuant des tests d’hypothèses et en construisant des intervalles de confiance pour mettre en œuvre certaines stratégies à l’avenir. Le défi est que la distribution des données n’est pas normale.
Remarque: Cette analyse fonctionne sur quelques hypothèses et l’une d’entre elles est que les données doivent être normalement distribuées.
Solution Méthodologie
Le théorème central limite nous aidera à contourner le problème de ces données où la population n’est pas normale. Par conséquent, nous simulerons le théorème de la limite centrale sur le jeu de données donné dans R étape par étape. Alors, commençons.
Importez l’ensemble de données CSV et validez-le
Tout d’abord, importez le fichier CSV dans R, puis validez l’exactitude des données:
Résultat:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
Ensuite, calculez la moyenne de la population et tracez toutes les observations des données:
Sortie:
#Calculate the population mean 12.80205
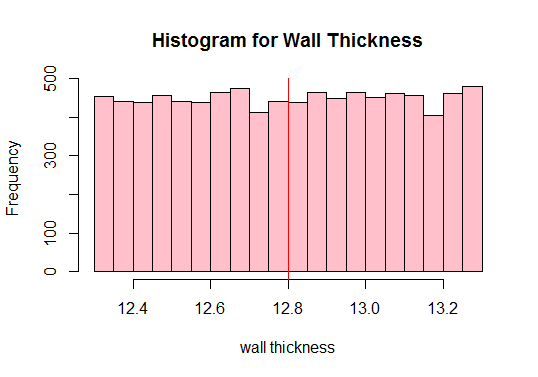
Voir le rouge ligne verticale au-dessus? C’est la moyenne de la population. Nous pouvons également voir sur le graphique ci-dessus que la population n’est pas normale, non? Par conséquent, nous devons prélever suffisamment d’échantillons de différentes tailles et calculer leurs moyennes (appelées moyennes d’échantillonnage). Nous allons ensuite tracer ces moyennes d’échantillons pour obtenir une distribution normale.
Dans notre exemple, nous allons dessiner suffisamment d’échantillons de taille 10, calculer leurs moyennes et les tracer dans R. Je sais que la taille minimale de l’échantillon pris devrait être 30 mais voyons simplement ce qui se passe lorsque nous en tirons 10:
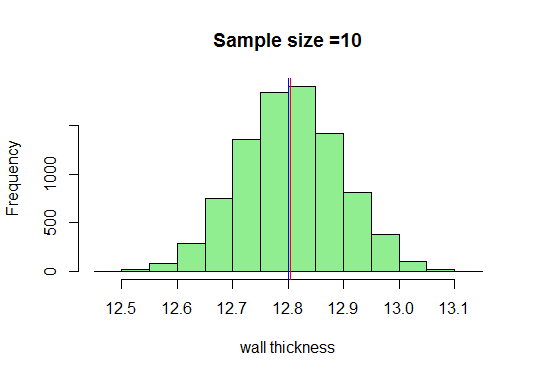
Maintenant, nous savons que nous obtiendrons une très belle courbe en forme de cloche à mesure que la taille des échantillons augmentera. Augmentons maintenant la taille de notre échantillon et voyons ce que nous obtenons:
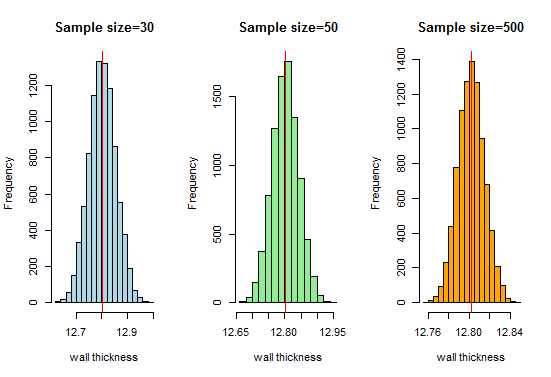
Ici, nous obtenons une bonne courbe en forme de cloche et la distribution d’échantillonnage se rapproche de la distribution normale à mesure que la taille des échantillons augmente.Par conséquent, nous pouvons considérer les distributions d’échantillonnage comme normales et l’organisation de fabrication de tuyaux peut utiliser ces distributions pour une analyse plus approfondie.
Vous pouvez également jouer en prenant différentes tailles d’échantillons et en tirant un nombre différent d’échantillons. Faites-moi savoir comment cela fonctionne pour vous!
Notes de fin
Le théorème de limite central est un concept assez important en statistique, et par conséquent en science des données. Je ne saurais trop insister sur le fait qu’il est essentiel de rafraîchir vos connaissances en statistiques avant de vous lancer dans la science des données ou même de vous asseoir pour une entrevue en science des données.
Je recommande de suivre le cours Introduction à la science des données – c’est un examen complet des statistiques avant d’introduire la science des données.
