Introduction
What is one of the most important and core concepts statistik, které nám umožňují prediktivní modelování, a přesto to často zaměňuje začínající datové vědce? Ano, mluvím o centrální limitní větě.
Jedná se o silný statistický koncept, který MUSÍ znát každý datový vědec. Proč je tomu tak?
No, centrální limitní věta (CLT) je jádrem testování hypotéz – kritická součást životního cyklu datové vědy. To je pravda, myšlenka, která nám umožňuje prozkoumat obrovské možnosti dat, která dostáváme, pramení z CLT. Je to vlastně jednoduchá představa, kterou je třeba pochopit, přesto se většina vědců zabývajících se touto otázkou během rozhovorů zmýlila.
Rozumíme konceptu of Central Limit Theorem (CLT) in this article. Uvidíme, proč je to důležité, kde se používá, a pak se naučíme, jak to použít v R.
Doporučuji projít si níže uvedený článek, pokud potřebujete rychlé osvěžení distribuce a jejích různých typů:
- 6 běžných rozdělení pravděpodobnosti, které by měl každý odborník v oblasti vědy o datech znát
obsah
- Co je to Central Limit Theorem (CLT) )?
- Význam centrální věty o limitu
- Statistická významnost
- Praktické aplikace
- Předpoklady za Centrální limitní věta
- Implementace centrální limitní věty v R
Co je centrální limitní věta (CLT)?
Pochopme centrální limitní teorém pomocí příkladu. To vám pomůže intuitivně pochopit, jak CLT funguje pod ním.
Vezměte v úvahu, že ve vědeckém oddělení univerzity je 15 sekcí a každá sekce hostí kolem 100 studentů. Naším úkolem je vypočítat průměrnou hmotnost studentů v přírodovědném oddělení. Zní to jednoduše, že?
Přístup, který získávám od aspirujících datových vědců, je jednoduše vypočítat průměr:
- Nejprve změřte váhy všech studentů ve vědeckém oddělení
- Přidejte všechny váhy
- Nakonec rozdělte celkový součet vah na celkový počet studentů, abyste získali průměr.
Ale co když velikost dat je obrovská? Má tento přístup smysl? Ve skutečnosti ne – měření hmotnosti všech studentů bude velmi únavný a dlouhý proces. Co tedy můžeme dělat? Podívejme se na alternativní přístup.
- Nejprve z třídy náhodně nakreslete skupiny studentů. Budeme tomu říkat ukázka. Nakreslíme několik vzorků, každý se skládá z 30 studentů.

Zdroj: http://www.123rf.com
- Vypočítejte průměr jednotlivých těchto vzorků
- Vypočítejte průměr těchto průměrů
- Tato hodnota nám poskytne přibližnou střední váhu studentů ve vědeckém oddělení.
- Kromě toho bude histogram vzorových středních hmotností studentů připomínat křivku zvonu (nebo normální rozdělení)
Ve zkratce o tom je centrální limitní věta. Pokud se naučíte učit se prostřednictvím videí, podívejte se na níže uvedený úvod do věty o centrálním limitu. Toto je součást komplexního statistického modulu v kurzu „Úvod do vědy o datech“:
Formální definování centrální limitní věty
Pojďme formálně definovat CLT:
Vzhledem k datové sadě s neznámým rozdělením (může to být jednotné, binomické nebo zcela náhodné), bude průměr vzorku přibližně odpovídat normálnímu rozdělení.
Velikost těchto vzorků by měla být dostatečná. Distribuce průměrů vzorků, počítaná z opakovaného vzorkování, bude mít tendenci k normálnosti, jak se zvětší velikost vašich vzorků.
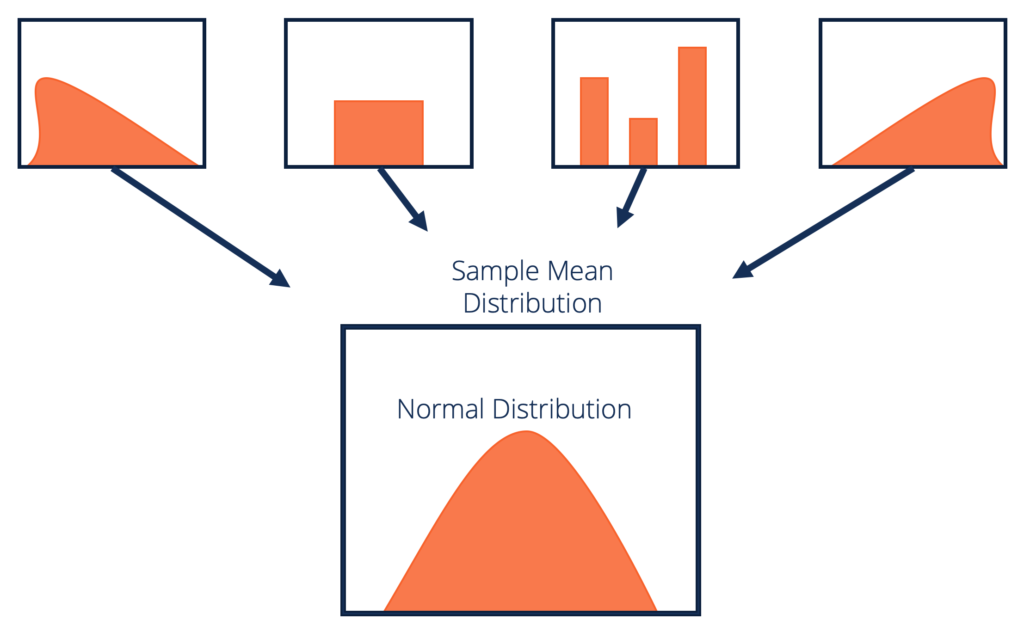
Zdroj: corporatefinanceinstitute.com
Věta o mezním limitu má širokou škálu aplikací v mnoha oblastech. Podívejme se na ně v následující části.
Význam centrální věty o limitu
Ústřední věta o meze má statistickou významnost i praktické aplikace . Není to to sladké místo, na které se zaměřujeme, když se učíme nový koncept?
Podíváme se na oba aspekty, abychom zjistili, kde je můžeme použít.
Statistická významnost CLT

Zdroj: http://srjcstaff.santarosa.edu
- Analýza dat zahrnuje statistické metody, jako je testování hypotéz a vytváření intervalů spolehlivosti. Tyto metody předpokládají, že populace je normálně distribuována.V případě neznámých nebo neobvyklých distribucí zacházíme s distribucí vzorkování jako s normální podle věty o mezním limitu.
- Pokud zvýšíme vzorky odebrané z populace, standardní odchylka průměrů vzorku se sníží. To nám pomáhá mnohem přesněji odhadnout populační průměr.
- K výběru rozsahu hodnot známých jako interval spolehlivosti (který se pravděpodobně bude skládat ze střední hodnoty populace) lze také použít průměr vzorku.
Praktické aplikace CLT
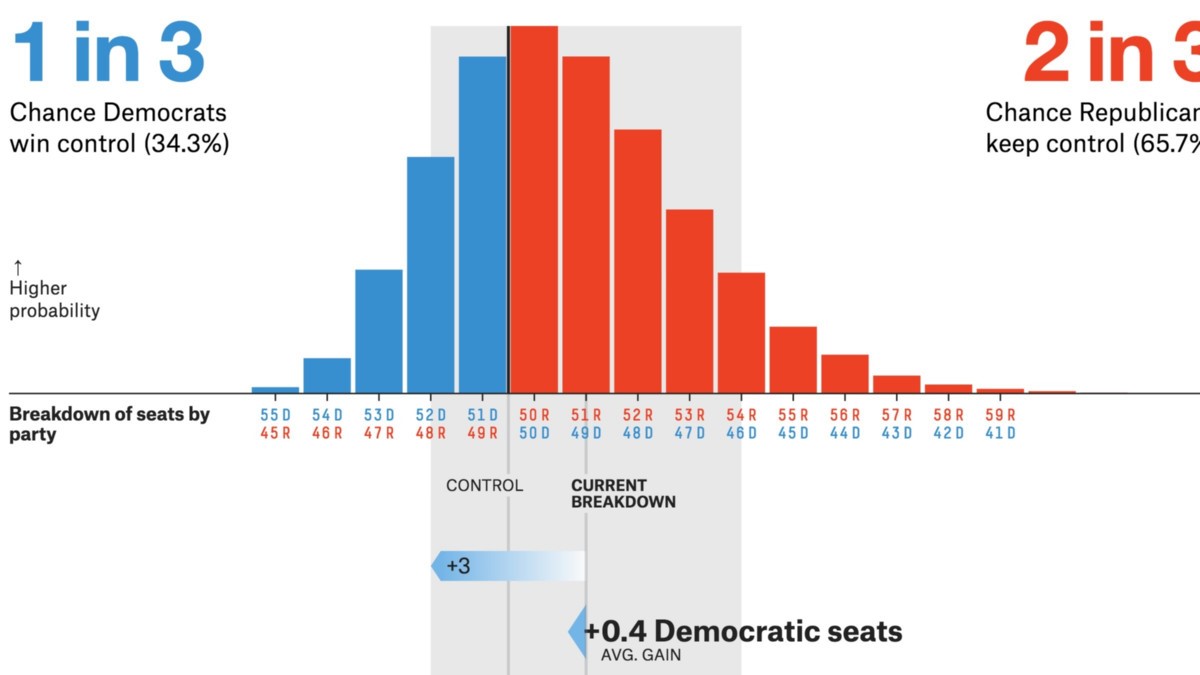
Zdroj: projekty .fivethirtyeight.com
- Politické / volební průzkumy jsou hlavními aplikacemi CLT. Tyto průzkumy odhadují procento lidí, kteří podporují konkrétního kandidáta. Tyto výsledky jste možná viděli na zpravodajských kanálech, které přicházejí s intervaly spolehlivosti. Centrální limitní věta pomáhá vypočítat, že
- Interval spolehlivosti, aplikace CLT, se používá k výpočtu průměrného rodinného příjmu pro konkrétní region
Centrální limitní věta má mnoho aplikací v různých oblastech. Napadá vás více příkladů? Dejte mi vědět v sekci komentářů pod článkem – uvedu je zde.
Předpoklady za teorémem centrální limitu
Než se ponoříme do implementace věty o centrální limitě, je to důležité pochopit předpoklady za touto technikou:
- Data musí splňovat podmínku randomizace. Musí být vzorkovány náhodně.
- Vzorky by měly být na sobě nezávislé. Jeden vzorek by neměl ovlivňovat ostatní vzorky.
- Velikost vzorku by neměla činit více než 10% populace, pokud je odběr prováděn bez náhrady.
- Velikost vzorku by měla být dostatečně velká. Jak nyní zjistíme, jak velká by měla být tato velikost? Závisí to na populaci. Pokud je populace zkosená nebo asymetrická, velikost vzorku by měla být velká. Pokud je populace symetrická, můžeme nakreslit i malé vzorky.
Obecně je velikost vzorku 30 považována za dostatečnou, pokud je populace symetrická.
průměr vzorku znamená se označuje jako:
µ X̄ = µ
kde,
- µ X̄ = Průměr výběrového průměru
- µ = Průměr populace
A směrodatná odchylka průměrného vzorku je označena jako:
σ X̄ = σ / sqrt (n)
kde,
- σ X̄ = standardní odchylka střední hodnoty vzorku
- σ = Populační směrodatná odchylka
- n = velikost vzorku
A to je vše pro koncept za teorémem centrální limity. Je čas zapálit RStudio a vrhnout se na implementaci CLT!
Implementace věty o centrálním limitu v R
S nadšením vidíme, jak můžeme kódovat větu o mezním limitu v R? Pojďme se do toho pustit.
Porozumění problémovému prohlášení
Organizace vyrábějící potrubí vyrábí různé druhy potrubí. Dostáváme měsíční údaje o tloušťce stěny určitých typů trubek. Data si můžete stáhnout zde.
Organizace chce data analyzovat provedením testování hypotéz a vytvořením intervalů spolehlivosti pro implementaci některých strategií v budoucnu. Úkolem je, že distribuce dat není normální.
Poznámka: Tato analýza funguje na několika předpokladech a jedním z nich je, že data by měla být distribuována normálně.
Řešení Metodika
Centrální limitní věta nám pomůže obejít problém těchto dat, kde populace není normální. Proto budeme v R krok za krokem simulovat centrální limitní větu na dané datové sadě. Pojďme tedy začít.
Importujte datovou sadu CSV a ověřte ji
Nejprve importujte soubor CSV do R a poté ověřte správnost dat:
Výstup:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
Dále vypočítejte průměr populace a vyneste všechna pozorování dat:
Výstup:
#Calculate the population mean 12.80205
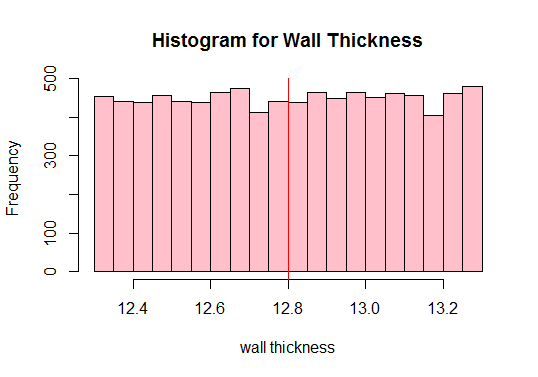
Viz červená svislá čára výše? To znamená počet obyvatel. Z výše uvedeného grafu také vidíme, že populace není normální, že? Proto musíme nakreslit dostatečné množství vzorků různých velikostí a vypočítat jejich průměry (známé jako ukázkové prostředky). Potom tyto vzorové prostředky vykreslíme, abychom získali normální rozdělení.
V našem příkladu nakreslíme dostatečné množství vzorků velikosti 10, vypočítáme jejich průměry a vykreslíme je do R. Vím, že minimální velikost vzorku přijato by mělo být 30, ale podívejme se, co se stane, když nakreslíme 10:
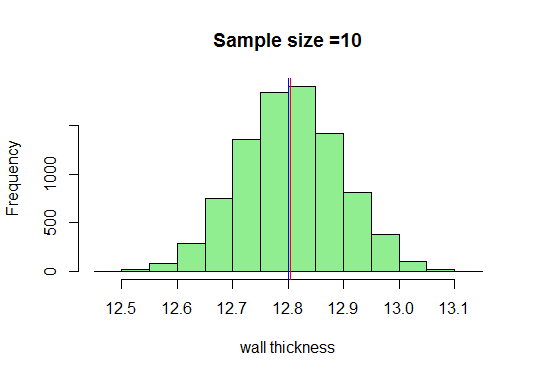
Nyní, víme, že se zvětšující se velikostí vzorku získáme velmi pěknou křivku ve tvaru zvonu. Pojďme nyní zvětšit naši velikost vzorku a uvidíme, co získáme:
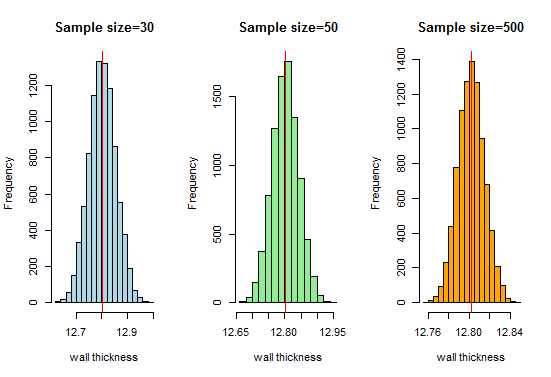
Zde získáme dobrá křivka ve tvaru zvonu a distribuce vzorkování se blíží normální distribuci, jak se zvětšují velikosti vzorků.Můžeme proto považovat distribuce vzorkování za normální a organizace výroby potrubí může tyto distribuce použít pro další analýzu.
Můžete si také pohrát tím, že odeberete různé velikosti vzorků a nakreslíte jiný počet vzorků. Dejte mi vědět, jak to pro vás funguje!
Koncové poznámky
Centrální limitní věta je velmi důležitý pojem ve statistice a následně v datové vědě. Nemohu dostatečně zdůraznit, jak kritické je to, že si oprášíte své statistické znalosti, než se pustíte do datové vědy nebo dokonce budete sedět na pohovoru o datové vědě.
Doporučuji absolvovat kurz Úvod do datové vědy komplexní pohled na statistiky před zavedením datové vědy.
