O que é um arquivo robots.txt?
Robots.txt é um arquivo de texto que os webmasters criam para instruir os robôs da web ( normalmente robôs de mecanismo de pesquisa) como rastrear páginas em seu site. O arquivo robots.txt faz parte do protocolo de exclusão de robôs (REP), um grupo de padrões da web que regulamenta como os robôs rastreiam a web, acessam e indexam conteúdo e disponibilizam esse conteúdo aos usuários. O REP também inclui diretivas como meta-robôs, bem como instruções em toda a página, subdiretório ou site sobre como os mecanismos de pesquisa devem tratar os links (como “seguir” ou “nofollow”).
Em Na prática, os arquivos robots.txt indicam se certos agentes de usuário (software de rastreamento da web) podem ou não rastrear partes de um site. Essas instruções de rastreamento são especificadas por “desautorizar” ou “permitir” o comportamento de determinados (ou todos) os agentes do usuário.
Formato básico:
User-agent: Disallow:
Juntas, essas duas linhas são consideradas um arquivo robots.txt completo – embora um arquivo de robôs possa conter várias linhas de agentes e diretivas do usuário (ou seja, bloqueia, permite, atrasos de rastreamento, etc.).
Em um arquivo robots.txt, cada conjunto de diretivas do agente do usuário aparece como um conjunto discreto, separado por uma quebra de linha:
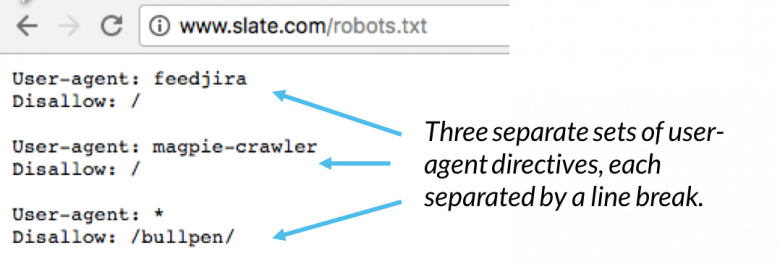
Em um arquivo robots.txt com várias diretivas de agente de usuário, cada regra de proibição ou permissão se aplica apenas ao agente de usuário ( s) especificado nesse conjunto particular separado por quebra de linha. Se o arquivo contiver uma regra que se aplica a mais de um agente de usuário, um rastreador só prestará atenção (e seguirá as diretivas) ao grupo mais específico de instruções.
Aqui está um exemplo:
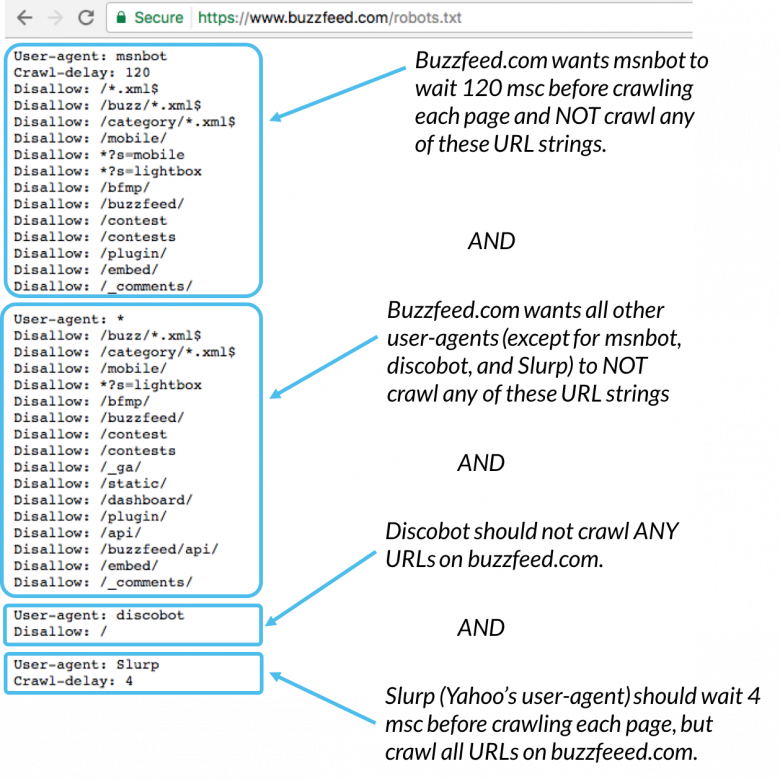
Msnbot, discobot e Slurp são todos chamados especificamente, para que esses agentes de usuário prestem atenção apenas às diretivas em suas seções do arquivo robots.txt. Todos os outros user agents seguirão as diretivas do user-agent: * group.
robots.txt de exemplo:
Aqui estão alguns exemplos de robots.txt em ação para um Site www.example.com:
URL do arquivo Robots.txt: www.example.com/robots.txt
Bloqueando todos os rastreadores da web de todo o conteúdo
User-agent: * Disallow: /
O uso dessa sintaxe em um arquivo robots.txt diria a todos os rastreadores da web para não rastrear nenhuma página em www.example.com, incluindo a página inicial.
Permitindo todos os rastreadores da web acessam todo o conteúdo
User-agent: * Disallow:
O uso dessa sintaxe em um arquivo robots.txt instrui os rastreadores da web a rastrear todas as páginas em www.example.com, incluindo a página inicial.
Bloqueando um rastreador da web específico de uma pasta específica
User-agent: Googlebot Disallow: /example-subfolder/
Esta sintaxe informa apenas o rastreador do Google (nome de user-agent Googlebot ) para não rastrear nenhuma página que contenha a sequência de URL www.example.com/example-subfolder/.
Bloqueio de um rastreador da web específico em uma página da web específica
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Esta sintaxe diz apenas ao rastreador do Bing (nome do agente de usuário Bing) para evitar o rastreamento da página específica em www.example.com/example-subfolder/blocked-page .html.
Como funciona o robots.txt?
Os mecanismos de pesquisa têm duas tarefas principais:
- Rastrear a web para descobrir conteúdo;
- Indexação desse conteúdo para que possa ser veiculado para usuários que buscam informações.
Para rastrear sites, os mecanismos de pesquisa seguem links para ir de um site para outro – basicamente, rastreamento em muitos bilhões de links e sites. Esse comportamento de rastreamento é às vezes conhecido como “indexação”.
Depois de chegar a um site, mas antes de indexá-lo, o rastreador de pesquisa procurará um arquivo robots.txt. Se encontrar um, o rastreador lerá isso antes de continuar na página. Como o arquivo robots.txt contém informações sobre como o mecanismo de pesquisa deve rastrear, as informações lá encontradas instruirão a ação do rastreador neste site específico. Se o arquivo robots.txt não contiver nenhuma diretiva que não permitir a atividade de um agente de usuário (ou se o site não tiver um arquivo robots.txt), ele continuará a rastrear outras informações no site.
Outros arquivos robots.txt rápidos que você deve saber:
(discutido com mais detalhes abaixo)
-
Para ser encontrado, um arquivo robots.txt deve ser colocado no diretório de nível superior de um site.
-
Robots.txt diferencia maiúsculas de minúsculas: o arquivo deve ser denominado “robots.txt” (não Robots.txt, robots.TXT ou outro).
-
Alguns agentes de usuário (robôs) m Você pode optar por ignorar seu arquivo robots.txt. Isso é especialmente comum com rastreadores mais nefastos, como robôs de malware ou raspadores de endereço de e-mail.
-
O arquivo /robots.txt está disponível publicamente: basta adicionar /robots.txt ao final de qualquer domínio raiz para ver as diretivas desse site (se esse site tiver um arquivo robots.txt!).Isso significa que qualquer pessoa pode ver quais páginas você deseja ou não rastreia, então não as use para ocultar informações privadas do usuário.
-
Cada subdomínio em uma raiz domínio usa arquivos robots.txt separados. Isso significa que blog.example.com e example.com devem ter seus próprios arquivos robots.txt (em blog.example.com/robots.txt e example.com/robots.txt).
-
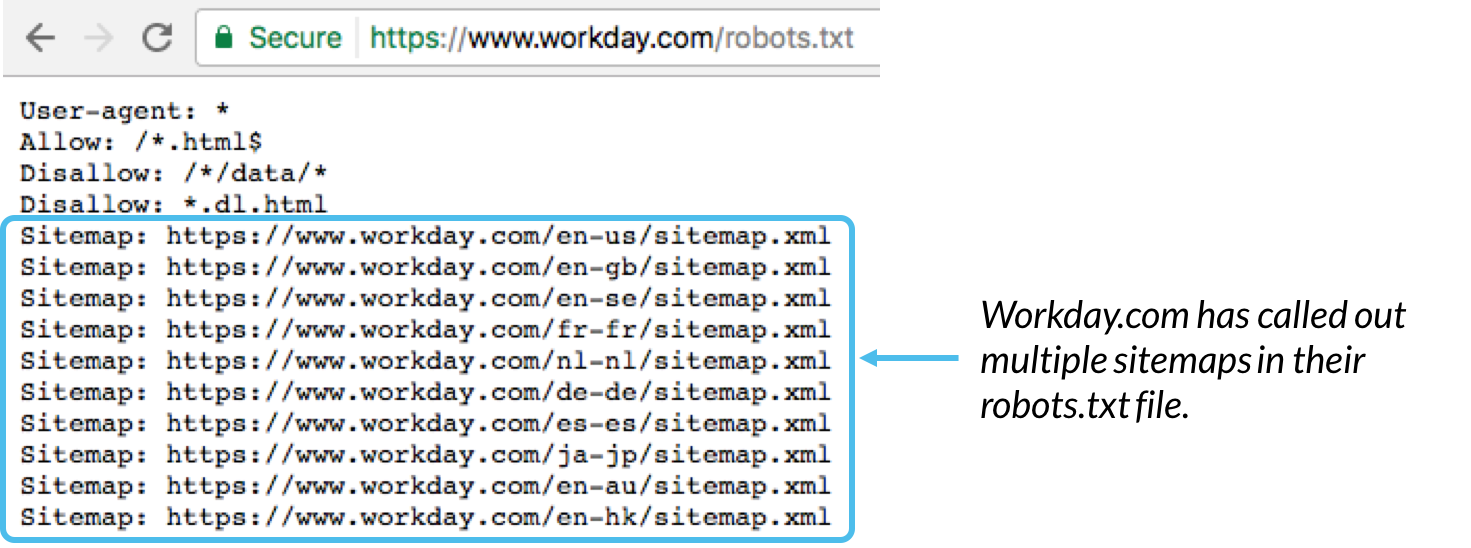
Geralmente, é uma prática recomendada indicar a localização de quaisquer mapas de site associados a este domínio na parte inferior do arquivo robots.txt. Aqui está um exemplo:
Sintaxe técnica do robots.txt
A sintaxe do Robots.txt pode ser considerada a “linguagem” dos arquivos robots.txt. Existem cinco termos comuns que você provavelmente encontrará em robôs . Eles incluem:
-
User-agent: O rastreador da web específico para o qual você está fornecendo instruções de rastreamento (geralmente um mecanismo de pesquisa). Uma lista da maioria dos agentes de usuário pode ser encontrada aqui.
-
Disallow: O comando usado para dizer a um user-agent para não rastrear um URL específico. Apenas uma linha “Disallow:” é permitida para cada URL.
-
Permitir (aplicável apenas para o Googlebot): o comando para informar ao Googlebot que ele pode acessar uma página ou subpasta, mesmo que sua página ou subpasta principal não seja permitida.
-
Atraso do rastreamento: quantos segundos um rastreador deve esperar antes de carregar e rastrear o conteúdo da página. Observe que o Googlebot não reconhece esse comando, mas a taxa de rastreamento pode ser definida i n Google Search Console.
-
Sitemap: Usado para destacar a localização de qualquer sitemap XML associado a este URL. Observe que este comando só é compatível com Google, Ask, Bing e Yahoo.
Correspondência de padrões
Quando se trata dos URLs reais a serem bloqueados ou permitir, os arquivos robots.txt podem se tornar bastante complexos, pois permitem o uso de correspondência de padrões para cobrir uma gama de opções de URL possíveis. O Google e o Bing respeitam duas expressões regulares que podem ser usadas para identificar páginas ou subpastas que um SEO deseja excluir. Esses dois caracteres são o asterisco (*) e o cifrão ($).
- * é um curinga que representa qualquer sequência de caracteres
- $ corresponde ao final do URL
O Google oferece uma grande lista de possíveis sintaxes de correspondência de padrões e exemplos aqui.
Para onde vai o robots.txt em um site?
Sempre que acessam um site, os mecanismos de pesquisa e outros robôs de rastreamento da web (como o rastreador do Facebook, o Facebot) sabem que devem procurar um arquivo robots.txt. Mas, eles só procurarão esse arquivo em um local específico: o diretório principal (normalmente seu domínio raiz ou página inicial). Se um agente de usuário visitar www.example.com/robots.txt e não encontrar um arquivo de robôs lá, ele presumirá que o site não tem um e continuará rastreando tudo na página (e talvez até mesmo em todo o site). Mesmo se a página do robots.txt existisse em, digamos, example.com/index/robots.txt ou www.example.com/homepage/robots.txt, ela não seria descoberta pelos agentes do usuário e, portanto, o site seria tratado como se ele não tivesse nenhum arquivo de robôs.
Para garantir que seu arquivo robots.txt seja encontrado, sempre inclua-o em seu diretório principal ou domínio raiz.
Por que você precisa do robots.txt?
Os arquivos Robots.txt controlam o acesso do rastreador a certas áreas do seu site. Embora isso possa ser muito perigoso se você impedir acidentalmente o Googlebot de rastrear todo o seu site (!!), existem algumas situações em que um arquivo robots.txt pode ser muito útil.
Alguns casos de uso comuns incluem:
- Impedir que conteúdo duplicado apareça em SERPs (observe que meta-robôs costumam ser a melhor escolha para isso)
- Manter seções inteiras de um site privadas (por exemplo, sua engenharia site de teste da equipe)
- Impedindo que as páginas de resultados de pesquisa internos apareçam em um SERP público
- Especificando a localização do (s) mapa (s) do site
- Impedindo que os mecanismos de pesquisa indexem certos arquivos em seu site (imagens, PDFs, etc.)
- Especificar um atraso de rastreamento para evitar que seus servidores sejam sobrecarregados quando os rastreadores carregam vários pedaços de conteúdo de uma vez
Se não houver áreas em seu site nas quais você deseja controlar o acesso do agente do usuário, talvez você não precise de um arquivo robots.txt.
Verificando se você tem um robô arquivo s.txt
Não tem certeza se possui um arquivo robots.txt? Basta digitar seu domínio raiz e adicionar /robots.txt ao final do URL. Por exemplo, o arquivo de robôs do Moz está localizado em moz.com/robots.txt.
Se nenhuma página .txt aparecer, você não tem uma página robots.txt (ativa) no momento.
Como criar um arquivo robots.txt
Se você descobriu que não tem um arquivo robots.txt ou deseja alterar o seu, criar um é um processo simples. Este artigo do Google percorre o processo de criação do arquivo robots.txt, e essa ferramenta permite que você teste se o seu arquivo está configurado corretamente.
Procurando um pouco de prática na criação de arquivos de robôs?Esta postagem do blog apresenta alguns exemplos interativos.
Práticas recomendadas de SEO
-
Certifique-se de não bloquear nenhum conteúdo ou seção do seu site que deseja rastrear.
-
Links em páginas bloqueadas por robots.txt não serão seguidos. Isso significa 1.) A menos que também estejam vinculados a outras páginas acessíveis por mecanismo de pesquisa (ou seja, páginas não bloqueadas por meio de robots.txt, meta-robôs ou outro), os recursos vinculados não serão rastreados e podem não ser indexados. 2.) Nenhum link equity pode ser passado da página bloqueada para o destino do link. Se você tiver páginas para as quais deseja que o patrimônio seja passado, use um mecanismo de bloqueio diferente do robots.txt.
-
Não use o robots.txt para evitar dados confidenciais (como informações privadas do usuário) apareçam nos resultados do SERP. Como outras páginas podem ter um link direto para a página que contém informações privadas (ignorando as diretivas do robots.txt em seu domínio raiz ou página inicial), ela ainda pode ser indexada. Se você deseja bloquear sua página de resultados de pesquisa, use um método diferente, como proteção por senha ou a meta diretiva noindex.
-
Alguns mecanismos de pesquisa têm vários agentes de usuário. Por exemplo, o Google usa o Googlebot para pesquisa orgânica e o Googlebot-Image para pesquisa de imagens. A maioria dos agentes de usuário do mesmo mecanismo de pesquisa segue as mesmas regras, então não há necessidade de especificar diretivas para cada um dos vários rastreadores de um mecanismo de pesquisa, mas ter a capacidade de fazer isso permite que você ajuste como o conteúdo do seu site é rastreado.
-
Um mecanismo de pesquisa armazenará em cache o conteúdo do robots.txt, mas geralmente atualiza o conteúdo armazenado em cache pelo menos uma vez por dia. Se você alterar o arquivo e quiser atualizá-lo mais rapidamente do que está ocorrendo, pode enviar seu url de robots.txt para o Google.
Robots.txt vs meta robôs vs x -robôs
Tantos robôs! Qual é a diferença entre esses três tipos de instruções do robô? Em primeiro lugar, o robots.txt é um arquivo de texto real, enquanto os meta e os x-robôs são meta diretivas. Além do que realmente são, os três têm funções diferentes. Robots.txt determina o comportamento de rastreamento em todo o site ou diretório, enquanto os robôs meta e x podem ditar o comportamento de indexação no nível de página individual (ou elemento de página).
Continue aprendendo
- Meta diretivas de robôs
- canonização
- redirecionamento
- Protocolo de exclusão de robôs
Coloque suas habilidades para trabalhar
O Moz Pro pode identificar se o seu arquivo robots.txt está bloqueando nosso acesso ao seu site. Experimente > >
