Co to jest plik robots.txt?
Robots.txt to plik tekstowy tworzony przez webmasterów w celu instruowania robotów internetowych ( zazwyczaj roboty wyszukiwarek), jak indeksować strony w ich witrynie. Plik robots.txt jest częścią protokołu wykluczania robotów (REP), grupy standardów sieciowych, które regulują sposób, w jaki roboty przeszukują sieć, uzyskują dostęp do treści i indeksują ją oraz udostępniają ją użytkownikom. REP zawiera również dyrektywy, takie jak meta roboty, a także instrukcje dotyczące całej strony, podkatalogu lub całej witryny, które pokazują, jak wyszukiwarki powinny traktować linki (takie jak „obserwuj” lub „nofollow”).
W W praktyce pliki robots.txt wskazują, czy określone programy klienckie (oprogramowanie do indeksowania sieci) mogą lub nie mogą indeksować części witryny. Te instrukcje indeksowania są określone przez „blokowanie” lub „zezwalanie” na zachowanie niektórych (lub wszystkich) klientów użytkownika.
Podstawowy format:
User-agent: Disallow:
Razem te dwa wiersze są uważane za kompletny plik robots.txt – chociaż jeden plik robots może zawierać wiele wierszy klientów użytkownika i dyrektyw (tj. niedozwolone, zezwalające, opóźnienia indeksowania itp.).
W pliku robots.txt każdy zestaw dyrektyw klienta użytkownika pojawia się jako oddzielny zestaw oddzielony znakiem podziału wiersza:
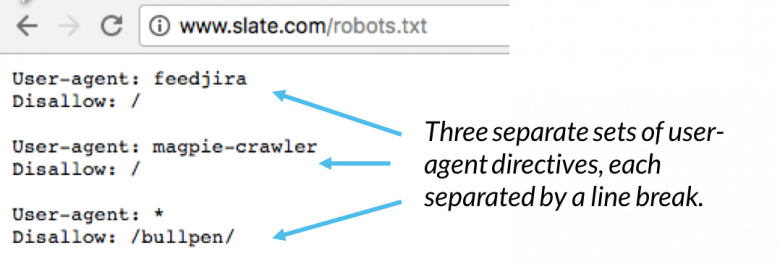
W pliku robots.txt z wieloma dyrektywami klienta użytkownika każda reguła zabrania lub zezwalania dotyczy tylko agenta użytkownika ( s) określone w tym konkretnym zestawie rozdzielanym znakami podziału. Jeśli plik zawiera regułę, która ma zastosowanie do więcej niż jednego klienta użytkownika, robot indeksujący zwróci uwagę tylko na najbardziej szczegółową grupę instrukcji (i zastosuje się do nich).
Oto przykład:
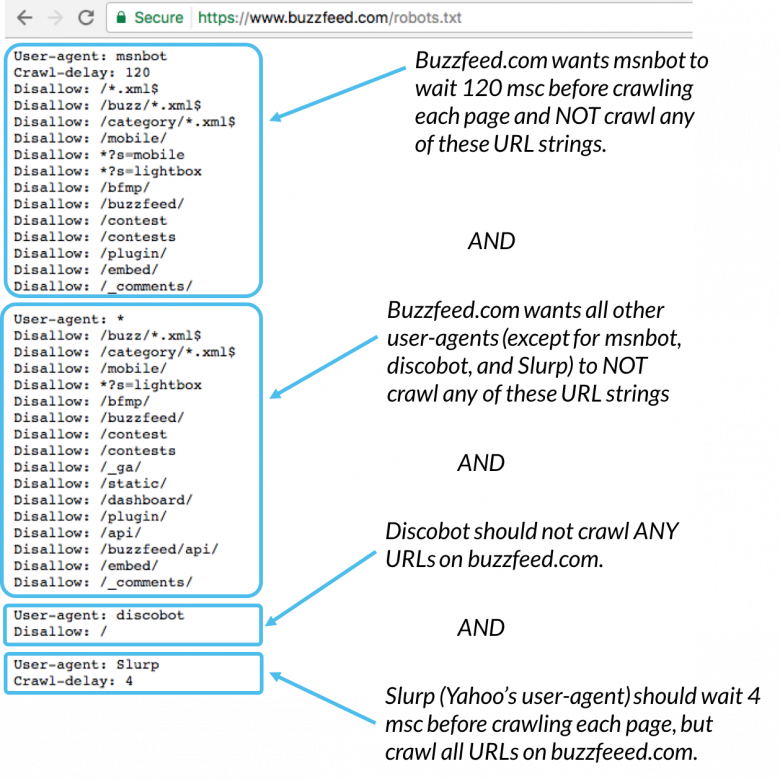
Msnbot, discobot i Slurp to nazywane w szczególności, więc ci klienci użytkownika będą zwracać uwagę tylko na dyrektywy w swoich sekcjach pliku robots.txt. Wszystkie inne klienty użytkownika będą postępować zgodnie z dyrektywami z grupy user-agent: *.
Przykład pliku robots.txt:
Oto kilka przykładów pliku robots.txt w działaniu Witryna www.example.com:
Adres URL pliku Robots.txt: www.example.com/robots.txt
Blokowanie dostępu wszystkich robotów internetowych do wszystkich treści
User-agent: * Disallow: /
Użycie tej składni w pliku robots.txt oznaczałoby, że wszystkie roboty indeksujące nie mają indeksować żadnych stron w witrynie www.example.com, w tym strony głównej.
Zezwalanie dostęp wszystkich robotów internetowych do całej treści
User-agent: * Disallow:
Użycie tej składni w pliku robots.txt informuje roboty internetowe o zaindeksowaniu wszystkich stron w witrynie www.example.com, w tym stronie głównej.
Blokowanie określonego robota sieciowego przed dostępem do określonego folderu
User-agent: Googlebot Disallow: /example-subfolder/
Ta składnia informuje tylko robota Google (nazwa klienta Googlebot ), aby nie indeksować żadnych stron zawierających ciąg adresu URL www.example.com/example-subfolder/.
Blokowanie określonego robota sieciowego przed dostępem do określonej strony internetowej
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Ta składnia informuje tylko robota Bing (nazwa klienta użytkownika Bing), aby unikał indeksowania określonej strony pod adresem www.example.com/example-subfolder/blocked-page .html.
Jak działa plik robots.txt?
Wyszukiwarki mają dwa główne zadania:
- Przeszukiwanie sieci w celu znalezienia treści;
- Indeksowanie tej treści, aby można było ją udostępnić osobom wyszukującym informacje.
W celu przeszukiwania witryn wyszukiwarki korzystają z linków, aby przejść z jednej witryny do drugiej – ostatecznie przeszukując w wielu miliardach linków i witryn. To zachowanie związane z indeksowaniem jest czasami określane jako „spining”.
Po wejściu na stronę internetową, ale przed jej przeszukaniem, robot wyszukiwania będzie szukał pliku robots.txt. Jeśli znajdzie taki plik, robot to przeczyta plik przed przejściem dalej przez stronę. Ponieważ plik robots.txt zawiera informacje o tym, jak wyszukiwarka powinna indeksować, informacje tam znalezione będą poinstruować robota do dalszych działań w tej konkretnej witrynie. Jeśli plik robots.txt nie zawiera żadnych dyrektyw, zabronić działania klienta użytkownika (lub jeśli witryna nie ma pliku robots.txt), rozpocznie indeksowanie innych informacji w witrynie.
Inne szybkie pliki robots.txt, które trzeba znać:
(bardziej szczegółowo omówione poniżej)
-
Aby można było go znaleźć, plik robots.txt musi znajdować się w katalogu najwyższego poziomu witryny.
-
W pliku Robots.txt rozróżniana jest wielkość liter: plik musi mieć nazwę „robots.txt” (nie Robots.txt, robots.TXT ani inne).
-
Niektóre programy użytkownika (roboty) m możesz zignorować plik robots.txt. Jest to szczególnie częste w przypadku bardziej nikczemnych robotów, takich jak złośliwe roboty lub skrobaki adresów e-mail.
-
Plik /robots.txt jest publicznie dostępny: wystarczy dodać /robots.txt na końcu dowolnej domeny głównej, aby zobaczyć dyrektywy tej witryny (jeśli ta witryna ma plik robots.txt!).Oznacza to, że każdy może zobaczyć, które strony robisz lub nie chcesz, aby były indeksowane, więc nie używaj ich do ukrywania prywatnych informacji o użytkowniku.
-
Każda subdomena w katalogu głównym domena używa oddzielnych plików robots.txt. Oznacza to, że zarówno blog.example.com, jak i example.com powinny mieć własne pliki robots.txt (na blog.example.com/robots.txt i example.com/robots.txt).
-
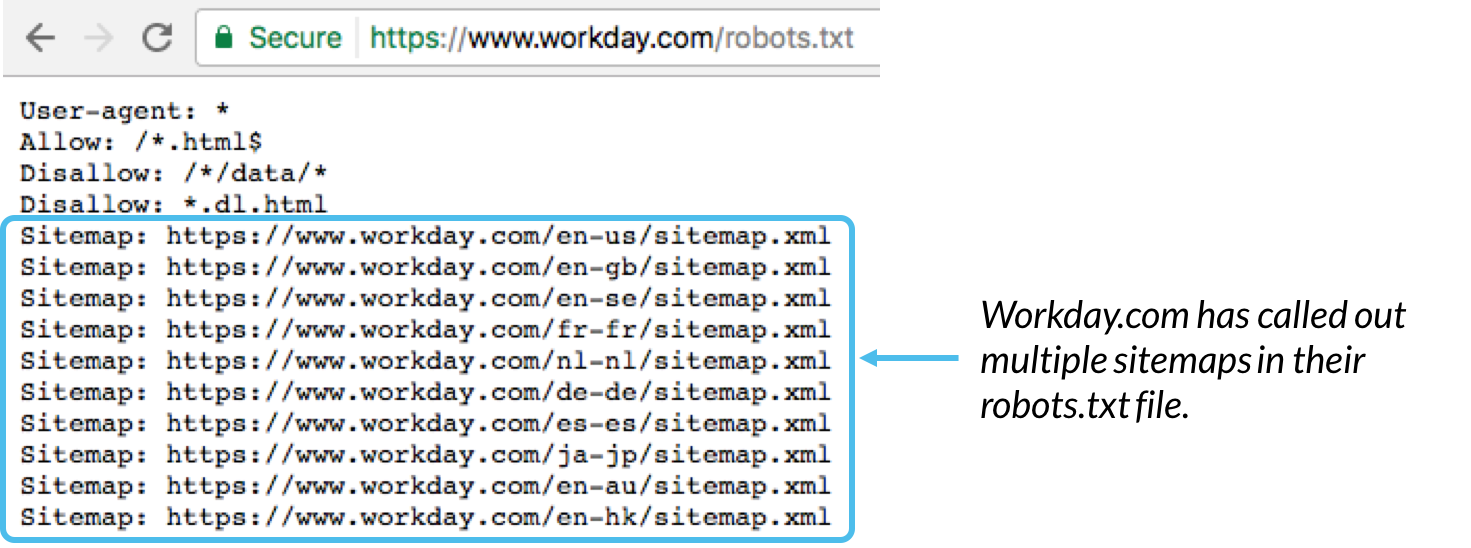
Ogólnie sprawdzoną metodą jest wskazywanie lokalizacji wszelkich map witryn powiązanych z tą domeną u dołu pliku robots.txt. Oto przykład:
Techniczna składnia pliku robots.txt
Składnię pliku robots.txt można traktować jako „język” plików robots.txt. Istnieje pięć typowych terminów, które można spotkać w pliku robots Plik. Obejmują one:
-
Klient użytkownika: konkretny robot indeksujący, któremu przekazujesz instrukcje dotyczące indeksowania (zazwyczaj jest to wyszukiwarka). Listę większości klientów użytkownika można znaleźć tutaj.
-
Disallow: Polecenie używane do poinstruowania klienta użytkownika, aby nie indeksował określonego adresu URL. Dla każdego adresu URL dozwolony jest tylko jeden wiersz „Disallow:”.
-
Zezwól (dotyczy tylko Googlebota): polecenie informujące Googlebota, że może uzyskać dostęp do strony lub podfolderu, nawet jeśli jego strona nadrzędna lub podfolder mogą być niedozwolone.
-
Opóźnienie indeksowania: ile sekund robot powinien odczekać przed załadowaniem i zindeksowaniem zawartości strony. Należy pamiętać, że Googlebot nie akceptuje tego polecenia, ale szybkość indeksowania można ustawić i n Google Search Console.
-
Mapa witryny: służy do określenia lokalizacji wszelkich map witryn XML powiązanych z tym adresem URL. Zauważ, że to polecenie jest obsługiwane tylko przez Google, Ask, Bing i Yahoo.
Dopasowywanie wzorców
Jeśli chodzi o rzeczywiste adresy URL do zablokowania lub zezwalaj, pliki robots.txt mogą być dość skomplikowane, ponieważ umożliwiają dopasowanie do wzorca w celu pokrycia szeregu możliwych opcji adresów URL. Google i Bing stosują dwa wyrażenia regularne, których można użyć do identyfikacji stron lub podfolderów, które SEO chce wykluczyć. Te dwa znaki to gwiazdka (*) i znak dolara ($).
- * to symbol wieloznaczny, który reprezentuje dowolną sekwencję znaków.
- $ pasuje do końca URL
Google oferuje tutaj świetną listę możliwych składni dopasowywania wzorców oraz przykłady.
Gdzie w witrynie znajduje się plik robots.txt?
Zawsze, gdy odwiedzają witrynę, wyszukiwarki i inne roboty indeksujące sieć (takie jak robot Facebooka, Facebot) wiedzą, że muszą szukać pliku robots.txt. Będą jednak szukać tego pliku tylko w jednym określonym miejscu: w katalogu głównym (zwykle w domenie głównej lub na stronie głównej). Jeśli klient użytkownika odwiedzi www.example.com/robots.txt i nie znajdzie tam pliku robots, założy, że witryna go nie ma i rozpocznie indeksowanie wszystkiego na stronie (a może nawet w całej witrynie). Nawet gdyby strona robots.txt istniała pod adresem, powiedzmy, przykład.com/index/robots.txt lub www.example.com/homepage/robots.txt, nie zostałaby wykryta przez klientów użytkownika, a zatem witryna byłaby traktowana jakby w ogóle nie zawierał pliku robots.
Aby mieć pewność, że plik robots.txt zostanie znaleziony, zawsze umieszczaj go w katalogu głównym lub domenie głównej.
Dlaczego potrzebujesz pliku robots.txt?
Pliki robots.txt kontrolują dostęp robotów do określonych obszarów witryny. Chociaż może to być bardzo niebezpieczne, jeśli przypadkowo zabronisz Googlebotowi indeksowania całej witryny (!!), w niektórych sytuacjach plik robots.txt może być bardzo przydatny.
Typowe przypadki użycia obejmują:
- Zapobieganie pojawianiu się zduplikowanych treści w SERPach (pamiętaj, że meta roboty są do tego często lepszym wyborem)
- Utrzymywanie całych sekcji witryny jako prywatnych (na przykład inżynieria witryny testowej zespołu)
- Zapobieganie wyświetlaniu wewnętrznych stron wyników wyszukiwania w publicznym SERP
- Określanie lokalizacji map witryn
- Zapobieganie indeksowaniu przez wyszukiwarki określone pliki w Twojej witrynie (obrazy, pliki PDF itp.)
- Określenie opóźnienia indeksowania, aby zapobiec przeciążeniu serwerów, gdy roboty indeksujące ładują wiele elementów treści naraz
Jeśli w Twojej witrynie nie ma obszarów, do których chcesz kontrolować dostęp klienta użytkownika, możesz w ogóle nie potrzebować pliku robots.txt.
Sprawdzanie, czy masz robota Plik s.txt
Nie masz pewności, czy masz plik robots.txt? Po prostu wpisz swoją domenę główną, a następnie dodaj /robots.txt na końcu adresu URL. Na przykład plik robots Moz znajduje się pod adresem moz.com/robots.txt.
Jeśli nie pojawi się żadna strona .txt, oznacza to, że aktualnie nie masz (aktywnej) strony robots.txt.
Jak utworzyć plik robots.txt
Jeśli stwierdzisz, że nie masz pliku robots.txt lub chcesz go zmienić, utworzenie takiego jest prostym procesem. Ten artykuł od Google przedstawia proces tworzenia pliku robots.txt, a to narzędzie pozwala sprawdzić, czy plik jest poprawnie skonfigurowany.
Szukasz praktyki w tworzeniu plików robotów?W tym poście na blogu przedstawiono kilka interaktywnych przykładów.
Sprawdzone metody SEO
-
Upewnij się, że nie blokujesz żadnych treści ani sekcji witryny, które chcesz indeksować.
-
Linki na stronach zablokowanych przez plik robots.txt nie będą śledzone. Oznacza to: 1.) O ile nie prowadzą do nich również linki z innych stron dostępnych dla wyszukiwarek (tj. Stron niezablokowanych w pliku robots.txt, meta robots lub w inny sposób), połączone zasoby nie będą przeszukiwane i nie mogą być indeksowane. 2.) Żadna własność linków nie może zostać przekazana z zablokowanej strony do miejsca docelowego linku. Jeśli masz strony, do których chcesz przekazywać kapitał, użyj innego mechanizmu blokowania niż plik robots.txt.
-
Nie używaj pliku robots.txt do ochrony poufnych danych (takich jak prywatne informacje o użytkowniku) z pojawiania się w wynikach SERP. Ponieważ inne strony mogą prowadzić bezpośrednio do strony zawierającej prywatne informacje (pomijając w ten sposób dyrektywy w pliku robots.txt w domenie głównej lub stronie głównej), nadal może zostać zindeksowana. Jeśli chcesz zablokować wyświetlanie swojej strony w wynikach wyszukiwania, użyj innej metody, takiej jak ochrona hasłem lub meta dyrektywa noindex.
-
Niektóre wyszukiwarki mają wielu klientów użytkownika. Na przykład Google używa Googlebota do bezpłatnych wyników wyszukiwania i Googlebot-Image do wyszukiwania grafiki. Większość programów użytkownika z tej samej wyszukiwarki stosuje te same reguły, więc nie ma potrzeby określania dyrektyw dla każdego z wielu robotów w wyszukiwarce, ale posiadanie takiej możliwości pozwala na precyzyjne dostrojenie sposobu indeksowania zawartości witryny.
-
Wyszukiwarka będzie buforować zawartość pliku robots.txt, ale zazwyczaj aktualizuje zawartość pamięci podręcznej co najmniej raz dziennie. Jeśli zmienisz plik i chcesz go zaktualizować szybciej niż ma to miejsce, możesz przesłać adres URL pliku robots.txt do Google.
Robots.txt vs meta Robots vs x -robots
Tyle robotów! Jaka jest różnica między tymi trzema typami instrukcji dla robotów? Po pierwsze, robots.txt to rzeczywisty plik tekstowy, podczas gdy meta i x-robots to meta dyrektywy. Poza tym, czym w rzeczywistości są, wszystkie trzy pełnią różne funkcje. Robots.txt dyktuje zachowanie podczas indeksowania całej witryny lub katalogu, podczas gdy roboty meta i x mogą dyktować zachowanie indeksacji na poziomie pojedynczej strony (lub elementu strony).
Kontynuuj naukę
- Meta dyrektywy robotów
- Kanonizacja
- Przekierowanie
- Protokół wykluczania robotów
Wykorzystaj swoje umiejętności w pracy
Moz Pro może zidentyfikować, czy plik robots.txt blokuje nam dostęp do Twojej witryny. Wypróbuj > >
