Mikä on robots.txt-tiedosto?
Robots.txt on tekstitiedosto, jonka verkkovastaavat luovat ohjaamaan web-robotteja ( yleensä hakukoneiden robotit) kuinka indeksoida sivuja verkkosivustollaan. Robots.txt-tiedosto on osa robottien poissulkemisprotokollaa (REP), joukko verkkostandardeja, jotka säätelevät kuinka robotit indeksoivat verkkoa, käyttävät ja indeksoivat sisältöä ja palvelevat kyseisen sisällön käyttäjille. REP sisältää myös direktiivejä, kuten metarobotit, sekä sivu-, alihakemisto- tai koko sivuston ohjeita siitä, miten hakukoneiden tulisi käsitellä linkkejä (kuten ”seuraa” tai ”nofollow”).
Käytännössä robots.txt-tiedostot osoittavat, voivatko tietyt käyttäjäagentit (web-indeksointiohjelmisto) indeksoida osan verkkosivustosta. Nämä indeksointiohjeet määritetään ”kieltämällä” tai ”sallimalla” tiettyjen (tai kaikkien) käyttäjäagenttien käyttäytyminen.
Perusmuoto:
User-agent: Disallow:
Näitä kahta riviä pidetään yhdessä täydellisenä robots.txt-tiedostona – vaikka yksi robottitiedosto voi sisältää useita käyttäjäagentteja ja direktiivejä (ts. estää, sallii, indeksointiviiveet jne.).
Robots.txt-tiedostossa kukin käyttäjäagenttikäskyjen joukko näkyy erillisenä joukona rivinvaihdolla erotettuna:
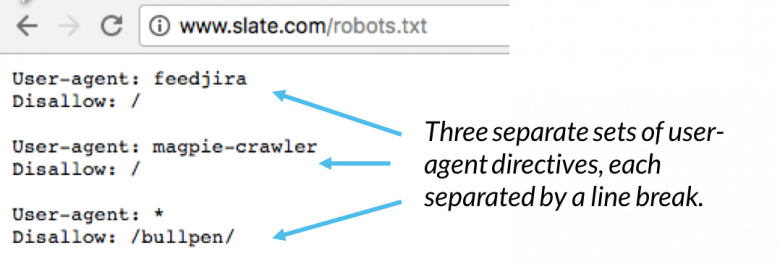
Robots.txt-tiedostossa, jossa on useita user-agent-direktiivejä, kukin disallow- tai allow-sääntö koskee vain useragent ( s) määritelty kyseisessä tietyssä rivinvaihdossa erotetussa sarjassa. Jos tiedosto sisältää säännön, joka koskee useampaa kuin yhtä käyttäjäagenttia, indeksointirobotti kiinnittää huomiota (ja noudattaa direktiivejä) vain tarkimpaan ohjeiden ryhmään.
Tässä on esimerkki:
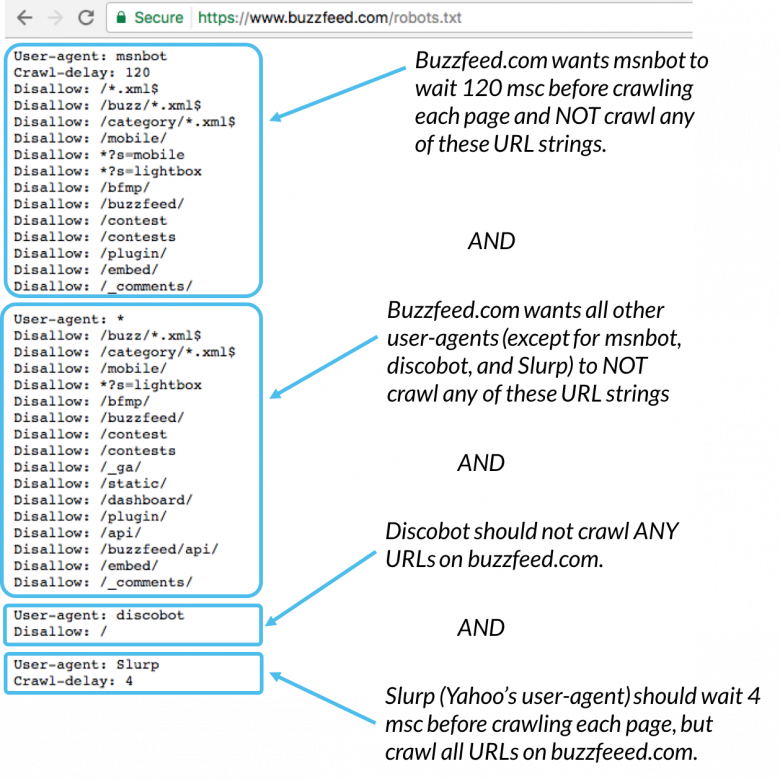
Msnbot, discobot ja Slurp kutsutaan kaikki nimenomaan, joten nämä käyttäjäagentit kiinnittävät huomiota vain robots.txt-tiedoston osioissa oleviin direktiiveihin. Kaikki muut käyttäjäagentit noudattavat user-agent: * -ryhmän ohjeita.
Esimerkki robots.txt:
Tässä on muutamia esimerkkejä robots.txt-tiedostosta toiminnassa www.esimerkki.fi -sivusto:
Robots.txt-tiedoston URL-osoite: www.esimerkki.fi/robotit.txt
Estä kaikki indeksointirobotit kaikesta sisällöstä
User-agent: * Disallow: /
Tämän syntaksin käyttö robots.txt-tiedostossa käskisi kaikkia indeksointirobotteja olemaan indeksoimatta mitään www.example.com -sivuja, mukaan lukien etusivu.
Salliminen kaikkien indeksointirobottien pääsy kaikkeen sisältöön
User-agent: * Disallow:
Tämän syntaksin käyttäminen robots.txt-tiedostossa käskee indeksointirobotteja indeksoimaan kaikki www.example.com-sivut, mukaan lukien etusivu.
Tietyn indeksoijan estäminen tietystä kansiosta
User-agent: Googlebot Disallow: /example-subfolder/
Tämä syntakse kertoo vain Googlen indeksoijalle (käyttäjäagentin nimi Googlebot ) olla indeksoimatta sivuja, jotka sisältävät URL-merkkijonon www.esimerkki.fi/esimerkki-alikansio/.
Tietyn indeksoijan estäminen tietyltä verkkosivulta
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Tämä syntaksi kertoo vain Bingin indeksoijalle (käyttäjäagentin nimi Bing), jotta vältetään indeksoimasta tiettyä sivua osoitteessa www.example.com/example-subfolder/blocked-page .html.
Kuinka robots.txt toimii?
Hakukoneilla on kaksi päätehtävää:
- Verkon indeksointi sisällön löytämiseksi;
- Indeksoi kyseinen sisältö niin, että sitä voidaan käyttää hakijoille, jotka etsivät tietoa.
Indeksoidessaan sivustoja hakukoneet seuraavat linkkejä siirtyäkseen sivustolta toiselle – lopulta indeksoimalla monien miljardien linkkien ja verkkosivustojen kautta. Tätä indeksointikäyttäytymistä kutsutaan joskus nimellä ”hämähäkkiminen”.
Saapuessaan verkkosivustolle, mutta ennen sen löytämistä, hakurobotti etsii robots.txt-tiedoston. Jos se löytää sellaisen, indeksoija lukee sen tiedosto ennen kuin jatkat sivun läpi. Koska robots.txt-tiedosto sisältää tietoja hakukoneen indeksoinnista, siellä olevat tiedot ohjaavat muita indeksointitoimia tällä sivustolla. Jos robots.txt-tiedosto ei sisällä direktiivejä, kieltäydy käyttäjäagentin toiminnasta (tai jos sivustolla ei ole robots.txt-tiedostoa), se jatkaa indeksoimaan muita tietoja sivustosta.
Muiden pikaisten robots.txt-tiedostojen täytyy tietää:
(käsitellään tarkemmin jäljempänä)
-
Löytämiseksi robots.txt-tiedosto on sijoitettava verkkosivuston ylätason hakemistoon.
-
Robots.txt erottaa isot ja pienet kirjaimet: tiedoston nimi on ”robots.txt” (ei Robots.txt, robots.TXT tai muu).
-
Jotkut käyttäjäagentit (robotit) m ne voivat jättää robots.txt-tiedostosi huomiotta. Tämä on erityisen yleistä pahantahtoisempien indeksointirobottien, kuten haittaohjelmarobottien tai sähköpostiosoitteiden kaapimien, kanssa.
-
/robots.txt -tiedosto on julkisesti saatavilla: lisää /robots.txt vain loppuun minkä tahansa juuriverkkotunnuksen kautta nähdäksesi kyseisen sivuston ohjeet (jos kyseisellä sivustolla on robots.txt-tiedosto!)Tämä tarkoittaa sitä, että kuka tahansa voi nähdä, mitä sivuja teet tai et halua indeksoitavaksi, joten älä käytä niitä yksityisten käyttäjätietojen piilottamiseen.
-
Jokainen juurihakemisto domain käyttää erillisiä robots.txt-tiedostoja. Tämä tarkoittaa, että sekä blog.example.com- että example.com -palvelulla tulisi olla omat robots.txt-tiedostot (osoitteissa blog.example.com/robots.txt ja example.com/robots.txt).
-
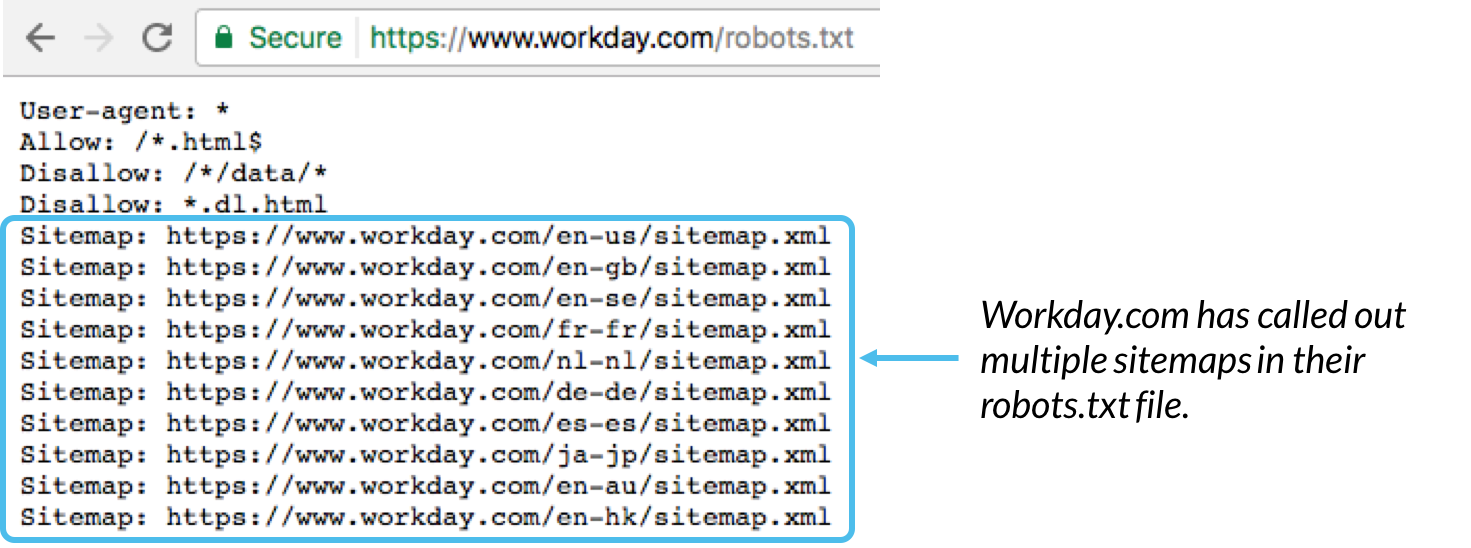
Yleensä on suositeltavaa ilmoittaa tähän verkkotunnukseen liittyvien sivustokarttojen sijainti robots.txt-tiedoston alaosassa. Tässä esimerkki:
Tekninen robots.txt-syntakse
Robots.txt-syntaksia voidaan pitää robots.txt-tiedostojen ”kielenä”. Roboteissa on todennäköisesti viisi tavallista termiä tiedosto. Niitä ovat:
-
User-agent: Erityinen indeksointirobotti, jolle annat indeksointiohjeita (yleensä hakukone). Luettelo useimmista käyttäjäagenteista löytyy täällä.
-
Disallow: Komento, jolla käsketään käyttäjäagenttia olemaan indeksoimatta tiettyä URL-osoitetta. Kullekin URL-osoitteelle on sallittu vain yksi ”Disallow:” -rivi.
-
Salli (koskee vain Googlebotia): Komento, joka kertoo Googlebotille, että se voi käyttää sivua tai alikansiota, vaikka sen emosivu tai alikansio saatettaisiin estää.
-
Indeksointiviive: Kuinka monta sekuntia indeksoijan on odotettava ennen sivun sisällön lataamista ja indeksointia. Huomaa, että Googlebot ei tunnista tätä komentoa, mutta indeksointinopeus voidaan asettaa i n Google Search Console.
-
Sivustokartta: Käytetään kaikkien tähän URL-osoitteeseen liittyvien XML-sivustokarttojen sijainnin kutsumiseen. Huomaa, että tätä komentoa tukevat vain Google, Ask, Bing ja Yahoo.
Kuvion vastaavuus
Kun on kyse estettävistä URL-osoitteista tai sallia, robots.txt-tiedostot voivat olla melko monimutkaisia, koska ne sallivat kuvion vastaavuuden käytön kattamaan useita mahdollisia URL-vaihtoehtoja. Google ja Bing molemmat kunnioittavat kahta säännöllistä lauseketta, joita voidaan käyttää tunnistamaan sivut tai alikansiot, jotka hakukoneoptimoija haluaa sulkea pois. Nämä kaksi merkkiä ovat tähti (*) ja dollarin merkki ($).
- * on jokerimerkki, joka edustaa mitä tahansa merkkijonoa
- $ vastaa merkin loppua URL-osoite
Google tarjoaa loistavan luettelon mahdollisista kuvion vastaavista syntaksista ja esimerkkejä täältä.
Mihin robots.txt siirtyy sivustolla?
Aina kun he tulevat sivustolle, hakukoneet ja muut web-indeksointirobotit (kuten Facebookin indeksoija, Facebot) tietävät etsivän robots.txt-tiedostoa. Mutta he etsivät tiedostoa vain yhdessä paikassa: päähakemistossa (yleensä pääverkkotunnuksessasi tai etusivullasi). Jos käyttäjäagentti vierailee osoitteessa www.example.com/robots.txt eikä löydä robottitiedostoa, se olettaa, että sivustolla ei ole sellaista, ja se jatkaa indeksoimista kaikilla sivuilla (ja ehkä jopa koko sivustolla). Vaikka robots.txt-sivu olisi olemassa esimerkiksi osoitteessa example.com/index/robots.txt tai www.example.com/homepage/robots.txt, käyttäjäagentit eivät löytäisi sitä ja näin ollen sivustoa kohdeltaisiin ikään kuin sillä ei olisi lainkaan robottitiedostoa.
Varmistaaksesi, että robots.txt-tiedostosi löytyy, sisällytä se aina päähakemistoon tai juurialueeseen.
Miksi tarvitsetko robots.txt?
Robots.txt-tiedostot ohjaavat indeksoijan pääsyä tietyille sivustosi alueille. Vaikka tämä voi olla erittäin vaarallista, jos estät vahingossa Googlebotin indeksoimasta koko sivustoasi (!!), joissakin tilanteissa robots.txt-tiedosto voi olla erittäin kätevä.
Joitakin yleisiä käyttötapauksia ovat:
- Päällekkäisen sisällön esiintymisen estäminen SERP-tiedostoissa (huomaa, että meta-robotit ovat usein parempi valinta tähän)
- Pidä kokonaiset verkkosivuston osiot yksityisinä (esimerkiksi suunnittelu tiimin vaiheistussivusto)
- Sisäisten hakutulossivujen estäminen julkisesta SERP: stä
- Sivustokartan sijainnin määrittäminen
- Hakukoneiden indeksoinnin estäminen tietyt verkkosivustosi tiedostot (kuvat, PDF-tiedostot jne.)
- Indeksointiviiveen määrittäminen, jotta palvelimesi eivät ylikuormitu, kun indeksointirobotit lataavat useita sisältöjä kerralla
Jos sivustollasi ei ole alueita, joille haluat hallita käyttäjäagenttien käyttöä, et ehkä tarvitse robots.txt-tiedostoa ollenkaan.
Tarkista, onko sinulla robotti s.txt-tiedosto
Etkö ole varma, onko sinulla robots.txt-tiedosto? Kirjoita yksinkertaisesti pääverkkotunnuksesi ja lisää sitten /robots.txt URL-osoitteen loppuun. Esimerkiksi Mozin robottitiedosto sijaitsee osoitteessa moz.com/robots.txt.
Jos .txt-sivua ei näy, sinulla ei tällä hetkellä ole (live) robots.txt-sivua.
robots.txt-tiedoston luominen
Jos huomaat, että sinulla ei ole robots.txt-tiedostoa tai haluat muuttaa omaa tiedostoa, sellaisen luominen on yksinkertainen prosessi. Tämä Googlen artikkeli käy läpi robots.txt-tiedoston luomisprosessin, ja tämän työkalun avulla voit testata, onko tiedosto asetettu oikein.
Etsitkö käytäntöä robottitiedostojen luomiseen?Tässä blogiviestissä käydään läpi joitain interaktiivisia esimerkkejä.
Hakukoneoptimoinnin parhaat käytännöt
-
Varmista, ettet estä indeksoitavaa verkkosivustosi sisältöä tai osioita.
-
Robots.txt-tiedoston estämien sivujen linkkejä ei seurata. Tämä tarkoittaa 1.) Jos linkitettyjä resursseja ei linkitetä myös muilta hakukoneiden käytettävissä olevilta sivuilta (eli sivuilta, joita ei ole estetty robots.txt-, meta-robottien tai muiden kautta), niitä ei indeksoida. 2.) Linkitettyä pääomaa ei voida siirtää estetyltä sivulta linkin kohteeseen. Jos sinulla on sivuja, joille haluat siirtää pääoma, käytä muuta estomekanismia kuin robots.txt.
-
Älä käytä robots.txt-tiedostoa arkaluontoisten tietojen (kuten yksityiset käyttäjätiedot) näkymästä SERP-tuloksissa. Koska muut sivut voivat linkittää suoraan yksityisiä tietoja sisältävälle sivulle (ohittaen siten robots.txt-ohjeet pääverkkotunnuksessasi tai etusivullasi), se voidaan silti indeksoida. Jos haluat estää sivusi hakutuloksista, käytä toista menetelmää, kuten salasanasuojausta tai noindex-metadirektiiviä.
-
Joillakin hakukoneilla on useita käyttäjäagentteja. Esimerkiksi Google käyttää Googlebotia orgaaniseen hakuun ja Googlebot-Image kuvahakuun. Useimmat saman hakukoneen käyttäjäagentit noudattavat samoja sääntöjä, joten ei tarvitse määrittää direktiivejä jokaiselle hakukoneen useille indeksointiroboteille, mutta mahdollisuus tehdä niin sallii sinun hienosäätää sivustosi sisällön indeksointia.
-
Hakukone välittää robots.txt-tiedoston välimuistiin, mutta päivittää välimuistissa olevan sisällön yleensä vähintään kerran päivässä. Jos muutat tiedostoa ja haluat päivittää sen nopeammin kuin tapahtuu, voit lähettää robots.txt-URL-osoitteesi Googlelle.
Robots.txt vs metarobotit vs x -robotit
Niin monia robotteja! Mitä eroa on näiden kolmen tyyppisten robottiohjeiden välillä? Ensinnäkin, robots.txt on todellinen tekstitiedosto, kun taas meta- ja x-robotit ovat metadirektiivejä. Sen lisäksi, mitä ne todellisuudessa ovat, nämä kolme palvelevat eri toimintoja. Robots.txt sanelee sivuston tai hakemiston indeksointikäyttäytymisen, kun taas meta- ja x-robotit voivat sanella indeksointikäyttäytymisen yksittäisen sivun (tai sivuelementin) tasolla.
Jatka oppimista
- Robottien metadirektiivit
- Kanalisointi
- Uudelleenohjaus
- Robottien poissulkemisprotokolla
Laita taitosi työhön
Moz Pro tunnistaa, estääkö robots.txt-tiedostosi pääsyn verkkosivustollesi. Kokeile sitä > >
