Johdanto
Mikä on yksi tärkeimmistä ja keskeisimmistä käsitteistä tilastoja, joiden avulla voimme tehdä ennakoivaa mallintamista, ja silti se usein hämmentää pyrkiviä datatieteilijöitä? Kyllä, puhun keskeisestä rajalausekkeesta.
Se on tehokas tilastollinen käsite, jonka jokaisen datatieteilijän PITÄÄ tietää. Miksi niin on?
No, keskeinen rajalauseke (CLT) on hypoteesitestauksen ydin – kriittinen osa datatieteen elinkaarta. Aivan, ajatus, jonka avulla voimme tutkia saamiemme tietojen valtavia mahdollisuuksia, lähtee CLT: stä. Se on oikeastaan yksinkertainen käsitys ymmärtää, mutta useimmat tiedetieteilijät kiertävät tätä kysymystä haastattelujen aikana.
Ymmärrämme konseptin tässä artikkelissa. Saamme selville, miksi se on tärkeää, missä sitä käytetään, ja opimme sitten soveltamaan sitä R. p>
- 6 yhteistä todennäköisyysjakaumaa, jonka jokaisen datatieteellisen ammattilaisen tulisi tietää
Sisällysluettelo
- Mikä on keskirajalause (CLT) )?
- Keskirajalauseen merkitys
- Tilastollinen merkitys
- Käytännön sovellukset
- Oletukset Keskirajalause
- Keskirajalauseen toteutus R: ssä
Mikä on keskirajalause (CLT)?
Ymmärretään keskiraja lause lauseen avulla. Tämä auttaa sinua ymmärtämään intuitiivisesti, kuinka CLT toimii alapuolella.
Ota huomioon, että yliopiston tiedeosastolla on 15 osastoa ja kussakin osastossa on noin 100 opiskelijaa. Tehtävämme on laskea luonnontieteiden opiskelijoiden keskimääräinen paino. Kuulostaa yksinkertaiselta, eikö niin?
Pyrkiviltä tiedetieteilijöiltä saamani tavan on laskea keskiarvo:
- Mittaa ensin kaikkien tiedeosaston opiskelijoiden painot
- Lisää kaikki painot
- Jaa lopuksi painojen kokonaismäärä opiskelijoiden kokonaismäärällä saadaksesi keskiarvon.
Mutta entä jos tietojen koko on humongous? Onko tällä lähestymistavalla järkevää? Ei oikeastaan – kaikkien opiskelijoiden painon mittaaminen on erittäin väsyttävä ja pitkä prosessi. Joten mitä voimme tehdä sen sijaan? Tarkastellaan vaihtoehtoista lähestymistapaa.
- Piirrä ensin luokan oppilaita satunnaisesti. Kutsumme tätä näytteeksi. Piirrämme useita näytteitä, joista kukin koostuu 30 opiskelijasta.

Lähde: http://www.123rf.com
- Laske näiden näytteiden yksittäinen keskiarvo
- Laske näiden keskiarvojen keskiarvo
- Tämä arvo antaa meille luonnontieteiden osaston opiskelijoiden likimääräisen keskimääräisen painon
- Lisäksi opiskelijoiden näytekeskiarvojen histogrammi muistuttaa kellokäyrää (tai normaalijakaumaa)
Pähkinänkuoressa tämä on keskeinen rajalauseke. Jos otat oppimisen videoiden läpi, tutustu alla olevaan esittelyyn keskeisen raja-lauseen johdannossa. Tämä on osa Johdatus tietotieteeseen -kurssin kattavaa tilastomoduulia:
Keskirajalauseen virallinen määrittely
Laitetaan virallinen määritelmä CLT: lle:
Kun tietojoukko on tuntematon (se voi olla yhtenäinen, binominen tai täysin satunnainen), näytekeskiarvot arvioivat normaalijakauman.
Näyte on riittävän suuri. Toistetun näytteenoton perusteella laskettu näytekeskiarvojen jakauma pyrkii normalisoitumaan näytteiden koon kasvaessa.
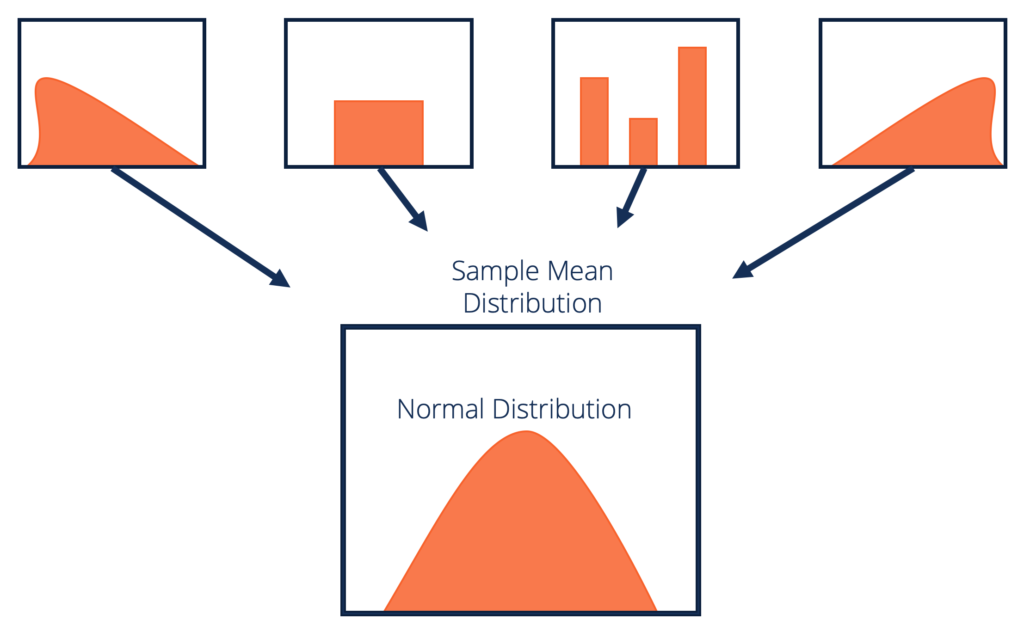
Lähde: corporatefinanceinstitute.com
Keskirajalauseessa on laaja valikoima sovelluksia monilla aloilla. Katsotaanpa niitä seuraavassa osassa.
Keskirajalauseen merkitys
Keskirajalausekkeella on sekä tilastollista merkitystä että käytännön sovelluksia . Eikö se ole se makea kohta, johon pyrimme oppimaan uutta konseptia?
Tarkastelemme molempia näkökohtia arvioidaksemme, missä voimme niitä käyttää.
Tilastollinen merkitys CLT: stä

Lähde: http://srjcstaff.santarosa.edu
- Tietojen analysointiin sisältyy tilastollisia menetelmiä, kuten hypoteesien testaus ja luottamusvälien muodostaminen. Näissä menetelmissä oletetaan, että populaatio on normaalisti jakautunut.Tuntemattomien tai epänormaalien jakaumien tapauksessa kohtelemme otosjakaumaa normaalina keskirajalauseen mukaisesti.
- Jos kasvatamme populaatiosta otettuja näytteitä, näytekeskiarvojen keskihajonta pienenee. Tämä auttaa meitä arvioimaan populaation keskiarvon paljon tarkemmin
- Myös otoskeskiarvoa voidaan käyttää luottamusväliksi kutsuttujen arvojen alueen muodostamiseen (joka todennäköisesti koostuu populaation keskiarvosta)
CLT: n käytännön sovellukset
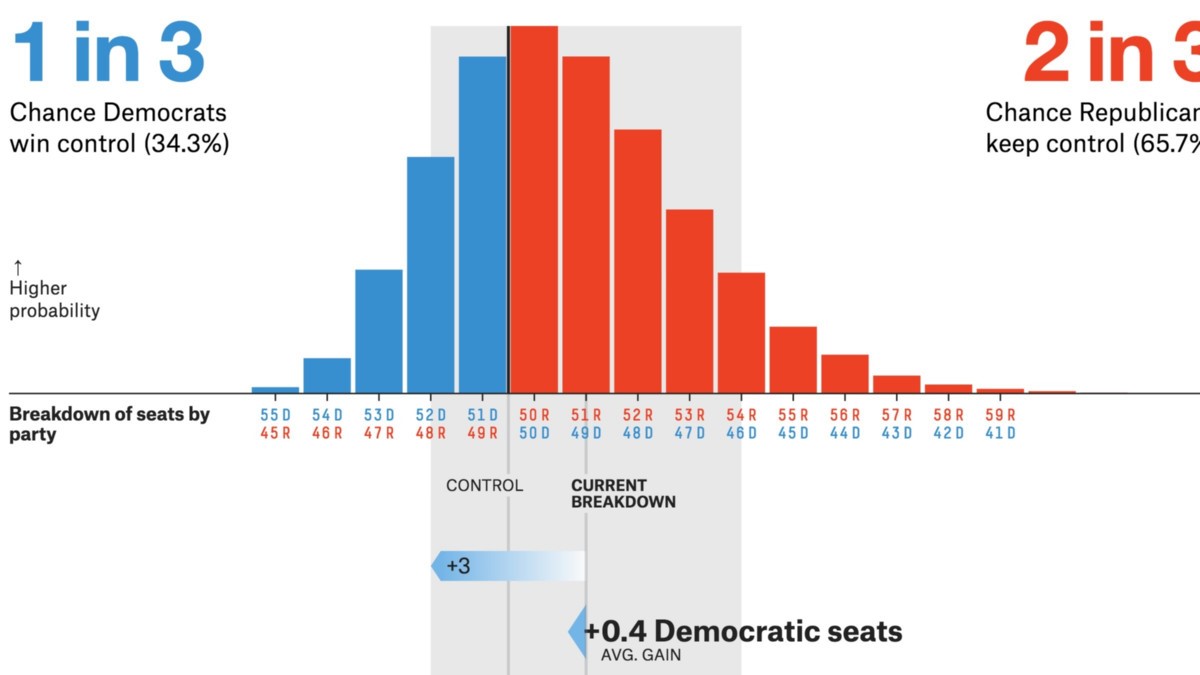
Lähde: projektit .fivethirtyeight.com
- Poliittiset / vaalikyselyt ovat tärkeimpiä CLT-sovelluksia. Näissä kyselyissä arvioidaan tiettyä ehdokasta tukevien ihmisten prosenttiosuus. Olet ehkä nähnyt nämä tulokset uutiskanavilla, joihin liittyy luottamusväli. Keskirajalause auttaa laskemaan, että
- CLT: n soveltamaa luottamusväliä käytetään tietyn alueen keskimääräisten perhetulojen laskemiseen.
Keskirajan lause on monia sovelluksia eri aloilla. Voitko miettiä lisää esimerkkejä? Kerro minulle artikkelin alapuolella olevasta kommenttiosasta – sisällytän ne tähän.
Oletukset keskeisen rajalausekkeen takana
Ennen kuin sukellamme keskeisen rajalausekkeen toteutukseen, se on tärkeää ymmärtää tämän tekniikan taustalla olevat oletukset:
- tietojen on noudatettava satunnaistamistilannetta. Se on otettava näytteistä satunnaisesti
- Näytteiden tulee olla toisistaan riippumattomia. Yhden näytteen ei pitäisi vaikuttaa muihin näytteisiin.
- Otoksen koon tulee olla enintään 10% populaatiosta, kun näyte otetaan ilman korvaamista.
- Otoksen koon tulee olla riittävän suuri. Kuinka selvitämme, kuinka suuren tämän koon tulisi olla? No, se riippuu väestöstä. Kun populaatio on vinossa tai epäsymmetrinen, otoksen koon tulisi olla suuri. Jos populaatio on symmetrinen, voimme tehdä myös pieniä otoksia.
Yleensä 30 otoksen kokoa pidetään riittävänä, kun populaatio on symmetrinen.
näytekeskiarvojen keskiarvo on merkitty seuraavasti:
µ X̄ = µ
missä,
- µ X̄ = Näytekeskiarvojen keskiarvo
- µ = Populaation keskiarvo
Ja näytekeskiarvon keskihajonta on merkitty seuraavasti:
σ X̄ = σ / sqrt (n)
missä,
- σ X̄ = otoskeskiarvon keskihajonta
- σ = Populaation keskihajonta
- n = otoskoko
Ja se on keskirajalauseen takana olevalle käsitteelle. Aika käynnistää RStudio ja selvittää CLT: n toteutus!
Keskirajalauseen toteutus R: ssä
Innostunut siitä, kuinka voimme koodata keskirajalauseen R: ssä? Kaivetaan sitten.
Ongelman selvittäminen
Putkienvalmistaja tuottaa erilaisia putkia. Meille annetaan kuukausittaiset tiedot tietyntyyppisten putkien seinämän paksuudesta. Voit ladata tiedot täältä.
Organisaatio haluaa analysoida tiedot suorittamalla hypoteesitestauksen ja rakentamalla luottamusvälit joidenkin strategioiden toteuttamiseksi tulevaisuudessa. Haasteena on, että tietojen jakelu ei ole normaalia.
Huomaa: Tämä analyysi toimii muutaman oletuksen perusteella ja yksi niistä on, että tiedot tulisi jakaa normaalisti.
Ratkaisu Metodologia
Keskeinen rajalauseke auttaa meitä kiertämään näiden tietojen ongelman siellä, missä populaatio ei ole normaalia. Siksi simuloidaan annetun tietojoukon keskirajalause R: ssä vaihe vaiheelta. Aloitetaan siis.
Tuo CSV-tietojoukko ja vahvista se
Tuo ensin CSV-tiedosto R-tiedostoon ja vahvista sitten tietojen oikeellisuus:
Tulos:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
Laske seuraavaksi populaation keskiarvo ja piirrä kaikki tietojen havainnot:
Tulos:
#Calculate the population mean 12.80205
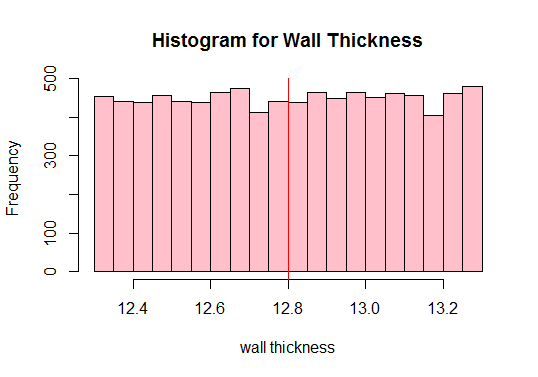
Katso punainen pystysuora viiva yläpuolella? Se on väestön keskiarvo. Voimme myös nähdä yllä olevasta juonesta, että väestö ei ole normaalia, eikö? Siksi meidän on otettava riittävä määrä erikokoisia näytteitä ja laskettava niiden keskiarvot (kutsutaan näytekeskuksiksi). Piirrämme sitten nämä otosvälineet normaalin jakauman saamiseksi.
Esimerkissämme piirrämme riittävät koot 10, laskemme niiden keskiarvot ja piirrämme ne R. Tiedän, että otoksen vähimmäiskoko otetun pitäisi olla 30, mutta katsotaanpa, mitä tapahtuu, kun piirrämme 10:
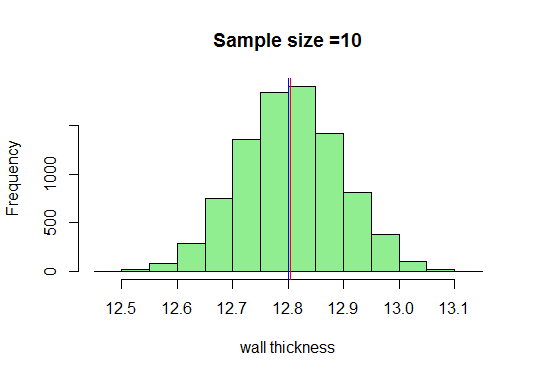
Nyt, tiedämme, että saamme erittäin mukavan kellon muotoisen käyrän näytekoon kasvaessa. Suurennetaan nyt otoskokoamme ja katsotaan, mitä saamme:
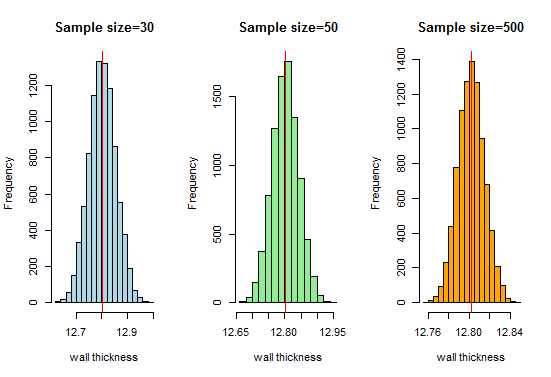
Täältä saat hyvä kellonmuotoinen käyrä ja näytteenottojakauma lähestyy normaalijakaumaa näytekoon kasvaessa.Siksi voimme pitää näytteenottojakaumia normaalina ja putkien valmistusorganisaatio voi käyttää näitä jakaumia jatkoanalyyseihin.
Voit myös leikkiä ottamalla erilaisia näytekokoja ja piirtämällä erilaisen määrän näytteitä. Kerro minulle, miten se sujuu sinulle!
Loppuhuomautukset
Keskitetty rajalauseke on melko tärkeä käsite tilastoissa ja siten datatieteessä. En voi korostaa tarpeeksi sitä, kuinka kriittistä on, että hyödynnät tilastotietojasi ennen kuin pääset tietojenkäsittelyyn tai edes istut tietojenkäsittelyhaastatteluun.
Suosittelen käymään Johdatus tietojenkäsittelyyn -kurssin – se on kattava tilastojen kuvaus ennen datatieteen käyttöönottoa.
