Introduktion
Hvad er et af de vigtigste og centrale begreber af statistikker, der gør det muligt for os at foretage forudsigelig modellering, og alligevel forvirrer det ofte håbefulde dataforskere? Ja, jeg taler om den centrale grænsesætning.
Det er et stærkt statistisk koncept, som enhver dataforsker SKAL kende. Hvorfor er det nu?
Nå, den centrale grænsesætning (CLT) er kernen i hypotesetest – en kritisk komponent i datalogiets livscyklus. Det er rigtigt, ideen, der lader os udforske de store muligheder for de data, vi får, kommer fra CLT. Det er faktisk en simpel opfattelse at forstå, men de fleste dataforskere skrubber over dette spørgsmål under interviews.
Vi vil forstå konceptet af Central Limit Theorem (CLT) i denne artikel. Vi vil se, hvorfor det er vigtigt, hvor det bruges, og derefter lære at anvende det i R.
Jeg anbefaler at gå igennem nedenstående artikel, hvis du har brug for en hurtig opdatering på distribution og dens forskellige typer:
- 6 Almindelige sandsynlighedsfordelinger, som enhver datalogisk fagmand skal kende
Indholdsfortegnelse
- Hvad er den centrale grænsesætning (CLT )?
- Betydningen af den centrale grænsesætning
- Statistisk betydning
- Praktiske anvendelser
- Antagelser bag Central Limit Theorem
- Implementering af Central Limit Theorem i R
Hvad er Central Limit Theorem (CLT)?
Lad os forstå den centrale grænse sætning ved hjælp af et eksempel. Dette hjælper dig med intuitivt at forstå, hvordan CLT fungerer nedenunder.
Overvej, at der er 15 sektioner i et videnskabsafdeling på et universitet, og at hver sektion er vært for omkring 100 studerende. Vores opgave er at beregne gennemsnitsvægten for studerende i videnskabsafdelingen. Det lyder simpelt, ikke?
Den tilgang, jeg får fra håbende dataforskere, er simpelthen at beregne gennemsnittet:
- Først måler du vægten af alle studerende i videnskabsafdelingen
- Tilføj alle vægte
- Del endelig den samlede sum af vægte med et samlet antal studerende for at få gennemsnittet
Men hvad hvis størrelsen på dataene er enorme? Giver denne tilgang mening? Ikke rigtig – at måle vægten af alle studerende vil være en meget trættende og lang proces. Så hvad kan vi gøre i stedet? Lad os se på en alternativ tilgang.
- Træk først grupper af studerende tilfældigt fra klassen. Vi kalder dette for en prøve. Vi tegner flere prøver, der hver består af 30 studerende.

Kilde: http://www.123rf.com
- Beregn det individuelle gennemsnit af disse prøver
- Beregn gennemsnittet af disse prøveværdier
- Denne værdi giver os den omtrentlige gennemsnitsvægt for de studerende i videnskabsafdelingen
- Derudover vil histogrammet for prøveens gennemsnitlige vægte for studerende ligne en klokkekurve (eller normalfordeling)
Dette er i en nøddeskal det, som den centrale grænsesætning handler om. Hvis du tager din læring gennem videoer, skal du tjekke nedenstående introduktion til den centrale grænsesætning. Dette er en del af det omfattende statistikmodul i kurset ‘Introduktion til datalogi’:
Formelt definerer den centrale grænsesætning
Lad os sætte en formel definition på CLT:
Givet et datasæt med ukendt fordeling (det kan være ensartet, binomialt eller helt tilfældigt), vil prøveeksemplet tilnærme normalfordelingen.
Disse prøver skal have tilstrækkelig størrelse. Fordelingen af eksempler betyder, beregnet ud fra gentagen prøveudtagning, har tendens til normalitet, når størrelsen på dine prøver bliver større.
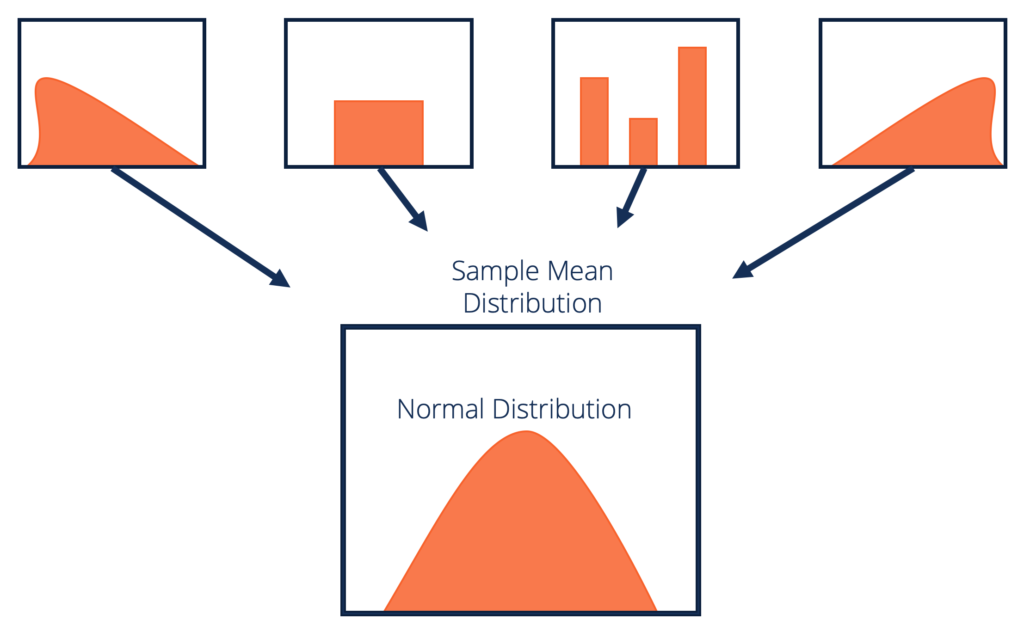
Kilde: corporatefinanceinstitute.com
Den centrale grænsesætning har en lang række applikationer inden for mange områder. Lad os se på dem i næste afsnit.
Betydningen af den centrale grænsesætning
Den centrale grænsesætning har både statistisk betydning såvel som praktiske anvendelser . Er det ikke det søde sted, vi sigter mod, når vi lærer et nyt koncept?
Vi ser på begge aspekter for at måle, hvor vi kan bruge dem.
Statistisk betydning af CLT

Kilde: http://srjcstaff.santarosa.edu
- Analyse af data involverer statistiske metoder som hypotesetest og konstruktion af konfidensintervaller. Disse metoder antager, at befolkningen er normalt fordelt.I tilfælde af ukendte eller ikke-normale fordelinger behandler vi samplingsfordelingen som normal i henhold til den centrale grænsesætning
- Hvis vi øger prøverne trukket fra populationen, vil standardafvigelsen for prøveorganerne falde. Dette hjælper os med at estimere populationens gennemsnit meget mere nøjagtigt
- Også prøve gennemsnit kan bruges til at skabe det interval af værdier, der er kendt som et konfidensinterval (der sandsynligvis vil bestå af populationens gennemsnit)
Praktiske anvendelser af CLT
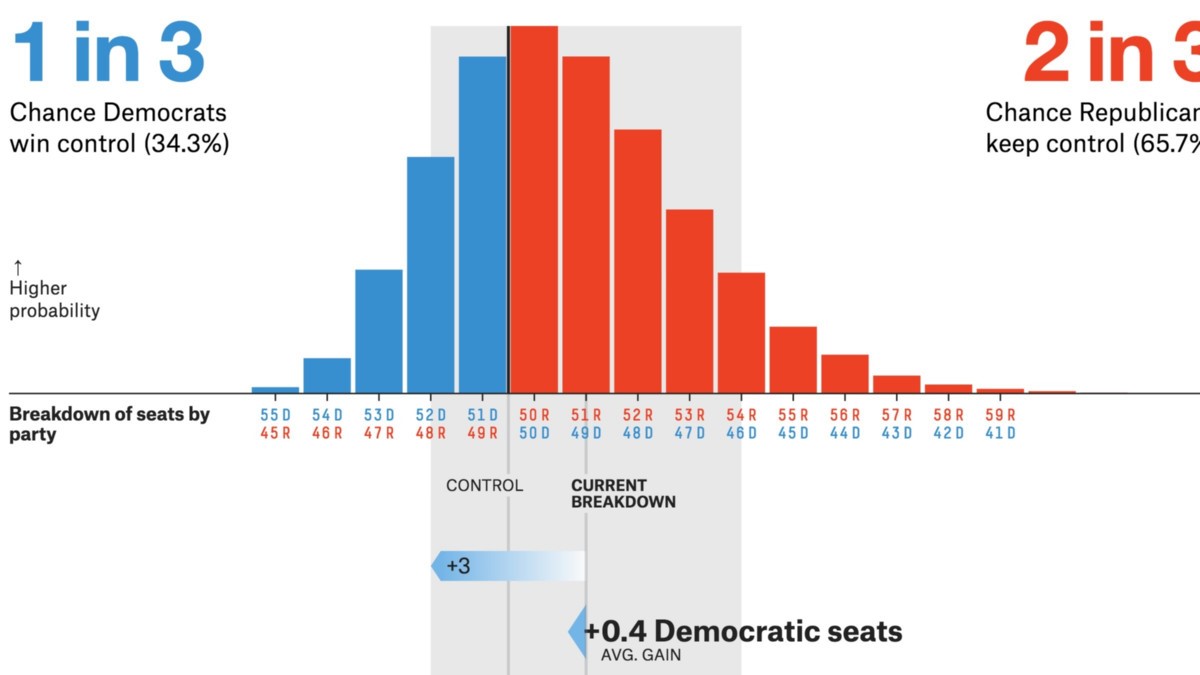
Kilde: projekter .fivethirtyeight.com
- Politiske valg / afstemninger er primære CLT-applikationer. Disse afstemninger estimerer procentdelen af mennesker, der støtter en bestemt kandidat. Du har måske set disse resultater på nyhedskanaler, der kommer med tillidsintervaller. Den centrale grænsesætning hjælper med at beregne, at
- Tillidsinterval, en anvendelse af CLT, bruges til at beregne den gennemsnitlige familieindkomst for en bestemt region
Den centrale grænsesætning har mange applikationer inden for forskellige områder. Kan du tænke på flere eksempler? Lad mig vide i kommentarfeltet under artiklen – jeg vil inkludere dem her.
Antagelser bag den centrale grænsesætning
Før vi dykker ned i implementeringen af den centrale grænsesætning, er det vigtigt at forstå antagelserne bag denne teknik:
- Dataene skal følge randomiseringsbetingelsen. Det skal samples tilfældigt
- Prøver skal være uafhængige af hinanden. Én prøve bør ikke påvirke de andre prøver
- Prøvestørrelsen bør ikke være mere end 10% af populationen, når prøveudtagningen udføres uden erstatning
- Prøvestørrelsen skal være tilstrækkelig stor. Nu hvordan vi finder ud af, hvor stor denne størrelse skal være? Det afhænger af befolkningen. Når populationen er skæv eller asymmetrisk, skal stikprøvestørrelsen være stor. Hvis populationen er symmetrisk, kan vi også tegne små prøver
Generelt betragtes en stikprøvestørrelse på 30 som tilstrækkelig, når populationen er symmetrisk.
middelværdien af prøveorganet betegnes som:
µ X̄ = µ
hvor
- µ X̄ = Middelværdien af prøven betyder
- µ = Befolkningens middelværdi
Og standardafvigelsen for prøvegenomsnittet betegnes som:
σ X̄ = σ / sqrt (n)
hvor,
- σ X̄ = Standardafvigelse for prøven betyder
- σ = Befolkningsstandardafvigelse
- n = stikprøvestørrelse
Og det er det for konceptet bag den centrale grænsesætning. Tid til at fyre op i RStudio og grave i CLT’s implementering!
Implementering af den centrale grænsesætning i R
Glade for at se, hvordan vi kan kode den centrale grænsesætning i R? Lad os grave ind derefter.
Forståelse af problemstillingen
En rørproducentorganisation producerer forskellige typer rør. Vi får de månedlige data om vægtykkelsen på visse typer rør. Du kan downloade dataene her.
Organisationen ønsker at analysere dataene ved at udføre hypotesetest og konstruere tillidsintervaller for at implementere nogle strategier i fremtiden. Udfordringen er, at distributionen af data ikke er normal.
Bemærk: Denne analyse fungerer på et par antagelser, og en af dem er, at dataene skal distribueres normalt.
Løsning Metode
Den centrale grænsesætning vil hjælpe os med at omgå problemet med disse data, hvor befolkningen ikke er normal. Derfor simulerer vi den centrale grænsesætning på det givne datasæt i R trin for trin. Så lad os komme i gang.
Importer CSV-datasættet og valider det
Først skal du importere CSV-filen i R og derefter validere dataene for korrekthed:
Output:
#Count of Rows and columns9000 1#View top 10 rows of the dataset Wall.Thickness1 12.354872 12.617423 12.369724 13.223355 13.159196 12.675497 12.361318 12.444689 12.6297710 12.90381#View last 10 rows of the dataset Wall.Thickness8991 12.654448992 12.807448993 12.932958994 12.332718995 12.438568996 12.995328997 13.060038998 12.795008999 12.777429000 13.01416
Beregn derefter befolkningens gennemsnit og plott alle observationer af dataene:
Output:
#Calculate the population mean 12.80205
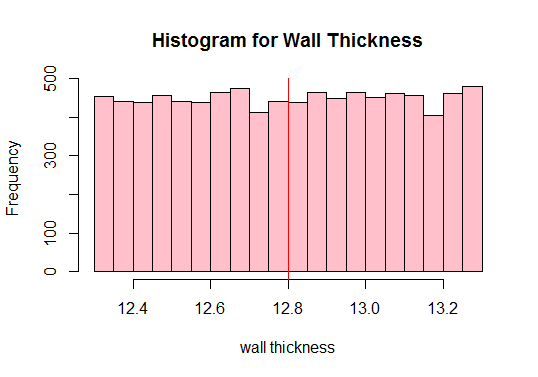
Se den røde lodret linje over? Det er befolkningens gennemsnit. Vi kan også se fra ovenstående plot, at befolkningen ikke er normal, ikke? Derfor er vi nødt til at tegne tilstrækkelige prøver i forskellige størrelser og beregne deres middel (kendt som prøve middel). Vi plotter derefter disse eksempler for at få en normalfordeling.
I vores eksempel tegner vi tilstrækkelige prøver af størrelse 10, beregner deres gennemsnit og plotter dem i R. Jeg ved, at den minimale prøvestørrelse taget skulle være 30, men lad os bare se, hvad der sker, når vi tegner 10:
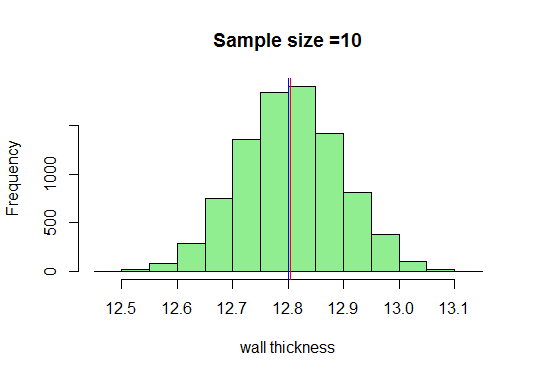
Nu, vi ved, at vi får en meget flot klokkeformet kurve, når prøvestørrelserne øges. Lad os nu øge vores stikprøvestørrelse og se, hvad vi får:
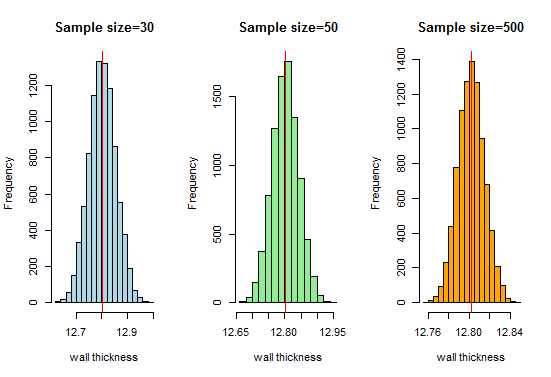
Her får vi en god klokkeformet kurve, og prøveuddelingen nærmer sig normalfordeling, efterhånden som prøvestørrelserne øges.Derfor kan vi betragte prøveuddelingen som normal, og rørproducentorganisationen kan bruge disse fordelinger til yderligere analyse.
Du kan også lege rundt ved at tage forskellige prøvestørrelser og tegne et andet antal prøver. Lad mig vide, hvordan det fungerer for dig!
Slutnoter
Central grænsesætning er et ganske vigtigt begreb inden for statistik og dermed datalogi. Jeg kan ikke understrege nok på, hvor kritisk det er, at du børster din statistiske viden, inden du går ind i datalogi eller endda sidder til et datalogisk interview.
Jeg anbefaler at tage kurset Introduktion til datalogi – det er en omfattende kig på statistikker inden introduktion af datalogi.
