学習に関しては、一般的に2つのアプローチがあります。どちらかを選択できます。広い範囲で、できるだけ多くの分野をカバーするようにしてください。そうしないと、深く掘り下げて、学習しているトピックを本当に具体的にすることができます。ほとんどの優れた学習者は、アルゴリズムから基本的なライフスキルまで、人生で学ぶすべてのことには、これら2つのアプローチの組み合わせがある程度含まれることを知っています。
コンピュータサイエンス、問題解決、およびデータ構造。先週、深さ優先探索について深く掘り下げ、バイナリ探索木を実際にトラバースすることの意味を学びました。深く掘り下げたので、広く行き、他の一般的なツリートラバーサル戦略を理解することは理にかなっています。
言い換えれば、それは皆さんが待っていた瞬間です。それは時間です。幅優先探索の基本を理解するために!
幅優先探索(BFS)が何であるかを正確に理解するための最良の方法のひとつは、それが何でないかを理解することです。つまり、BFSとDFSを比較すると、それらを頭の中でまっすぐに保つことがはるかに簡単になります。それでは、先に進む前に、深さ優先探索の記憶を更新しましょう。
深さ優先探索は、葉に到達するまで木の1つの枝を下に移動するプロセスであることがわかっています。次に、ツリーの「トランク」に戻ります。つまり、DFSを実装すると、バイナリ検索ツリーのサブツリーを下に移動することになります。
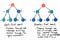
では、幅優先はどうですか検索と比較してみてください。考えてみると、ツリーの1つのブランチを下に移動してから別のブランチを下に移動する唯一の実際の代替手段は、セクションごと、またはレベルごとにツリーを下に移動することです。これがまさにBFSです。 !
幅優先探索では、一度に1レベルずつツリーを検索します。
子ノードの1つのレベル全体を最初にトラバースしてから、孫ノードをトラバースします。そして、ひ孫ノードをトラバースする前に、孫ノードのレベル全体をトラバースします。
わかりました、それはかなり明確に思えます。 2つの異なるタイプのツリートラバーサルアルゴリズムを他に区別するものは何ですか?さて、これら2つのアルゴリズムの手順の違いについてはすでに説明しました。まだ話していないもう1つの重要な側面、つまり実装について考えてみましょう。
まず、私たちが知っていることから始めましょう。先週、深さ優先探索をどのように実装しましたか? DFSを使用してツリーを検索する3つの異なる方法(順序付け、後順序付け、および事前順序付け)を学習したことを覚えているかもしれません。しかし、これら3つの実装がどれほど似ているかについては非常にクールなことがありました。それらはそれぞれ再帰を使用して使用できます。また、DFSは再帰関数として記述できるため、呼び出しスタックがツリー内の最長パスと同じくらい大きくなる可能性があることもわかっています。
しかし、私が残したことが1つありました。先週、今すぐ取り上げるのは良いことのようです(そして、少しでも明らかです!):呼び出しスタックは、実際にはスタックデータ構造を実装しています。それらを覚えていますか?スタックについては少し前に学びましたが、ここでもまた、あちこちに現れています!
スタックを使用して深さ優先探索を実装することの本当に興味深い点は、スタックのサブツリーをトラバースすることです。二分探索木では、「チェック」または「訪問」した各ノードがスタックに追加されます。リーフノード(子を持たないノード)に到達すると、スタックの最上位からノードをポップオフし始めます。再びルートノードに到達し、次のサブツリーをトラバースし続けることができます。

上記のDFSツリーの例では、ノード2、3、および4がすべてに追加されていることがわかります。スタックの一番上。そのサブツリーの「終わり」に到達すると、つまり3と4のリーフノードに到達すると、「訪問するノード」のスタックからそれらのノードをポップオフし始めます。適切なサブツリーで最終的に何が起こるかを確認できます。アクセスするノードがコールスタックにプッシュされ、それらにアクセスして、体系的にスタックからポップします。
最終的には、左と右の両方のサブツリーにアクセスすると、チェックするものが何もない状態でルートノードに戻り、呼び出しスタックは空になります。
したがって、を使用できるはずです。スタック構造を作成し、BFS実装と同様のことを行います…そうですか?まあ、それがうまくいくかどうかはわかりませんが、少なくとも、実装したいアルゴリズムを引き出して、それをどこまで実現できるかを確認することから始めると役立つと思います。
試してみましょう:

わかりました。左側に、先週DFSを実装したグラフがあります。代わりに、BFSアルゴリズムをどのように使用できますか?
まず、ルートノードを最初にチェックする必要があることがわかります。これが最初にアクセスできる唯一のノードなので、ノードfを「ポイント」します。
さて、このルートノードの子を確認する必要があります。
子を次々にチェックしたいので、最初に左の子に移動しましょう。ノードdは、現在「ポイント」しているノード(およびアクセスできる唯一のノード)です。
次に、適切な子ノードに移動します。
ええと。待ってください、ルートノードはもう利用できません!また、二分木には逆リンクがないため、逆方向に移動することはできません。どのようにして適切な子ノードに到達しますか?そして…いや、左の子ノードdと右の子ノードkはまったくリンクされていません。つまり、ノードdの子以外にはアクセスできないため、ある子から別の子にジャンプすることは不可能です。
ああ。あまり遠くまで行かなかったでしょう?この問題を解決する別の方法を考え出す必要があります。レベル順にツリーをウォークできるようにするツリートラバーサルを実装する方法を理解する必要があります。覚えておく必要がある最も重要なことは次のとおりです。
アクセスするすべてのノードのすべての子ノードへの参照を保持する必要があります。そうしないと、後で戻って訪問することができなくなります!
考えれば考えるほど、気分が良くなります。まだチェックする必要のあるすべてのノードのリストを保持したいのではないでしょうか。そして、何かのリストを保持したい瞬間、私の心はすぐに特に1つのデータ構造にジャンプします。もちろんキューです!
キューがBFSの実装に役立つかどうかを見てみましょう。
救助のためのキュー!
結局のところ、深さ優先探索と幅優先探索の主な違いは、これらの非常に異なるアルゴリズムの両方を実装するために使用されるデータ構造です。
DFSはスタックデータ構造を使用しますが、BFSはキューデータ構造に依存します。キューを使用することの良い点は、以前に発見した問題を解決できることです。つまり、まだチェック/アクセスしていない場合でも、戻りたいノードへの参照を保持できます。
検出したがまだアクセスしていないノードをキューに追加し、後でそれらに戻します。
キューに追加するノードの一般的な用語は、検出されたノードです。検出されたノードは、キューに追加するノードであり、その場所はわかっていますが、実際にはまだアクセスしていません。実際、これこそが、キューをBFS問題を解決するための完璧な構造にしている理由です。

左のグラフでは、ルートノードをキューに追加することから始めます。これはこれまでで唯一のノードだからです。ツリー内で(少なくとも最初は)アクセスできます。これは、ルートノードが開始する唯一の検出されたノードであることを意味します。
少なくとも1つのノードがキューに入れられると、ノードにアクセスし、それらの子ノードへの参照をキューに追加するプロセスを開始できます。
わかりました。これは、少し混乱するように聞こえるかもしれません。そしてそれは大丈夫です!単純なステップに分割すると、把握しやすくなると思います。
キュー内のすべてのノード(常にルートノードから開始)について、次の3つのことを実行する必要があります。
- ノードにアクセスします。これは通常、値を出力することを意味します。
- ノードの左の子をキューに追加します。
- ノードの右を追加します。キューの子。
これら3つのことを実行したら、ノードは不要になったため、キューから削除できます。基本的に、キューが空になるまでこれを繰り返し行う必要があります。
さて、これを実際に見てみましょう!
以下のグラフから始めます。検出された唯一のノードとして、ルートノードであるノードfをオフにします。私たちの3つのステップを覚えていますか?今すぐ実行しましょう:
- ノードfにアクセスして、その値を出力します。
- 左の子であるノードdへの参照をキューに入れます。
- その右の子であるノードkへの参照をキューに入れます。
次に、ノードfをキューから削除します!

キューの先頭にある次のノードはノードdです。ここでも、同じ3つの手順を実行します。値を出力し、左の子を追加し、右の子を追加してから、キューから削除します。
キューにノードk、b、eへの参照が含まれるようになりました。 。このプロセスを体系的に繰り返し続けると、実際にグラフをトラバースし、ノードをレベル順に出力していることがわかります。やったー!それがまさに私たちが最初にやりたかったことです。
これがうまく機能するための鍵は、キュー構造の本質です。キューは先入れ先出し(FIFO)の原則に従います。つまり、最初にキューに入れられたものはすべて、キューから読み取られて削除される最初のアイテムです。
最後に、キューのトピックについて説明しますが、BFSアルゴリズムの時空間計算量は、それを実装するために使用するキューにも関連していることを言及する価値があります。キューが戻ってくることを知っていたのです。非常に便利ですよね?
BFSアルゴリズムの時間計算量は、ノードにアクセスするのにかかる時間に直接依存します。ノードの値を読み取ってその子をキューに入れるのにかかる時間はノードに基づいて変化しないため、ノードへのアクセスには一定の時間、つまりO(1)時間がかかると言えます。 BFSツリートラバーサルの各ノードにアクセスするのは1回だけなので、すべてのノードを読み取るのにかかる時間は、ツリーにあるノードの数によって異なります。ツリーに15個のノードがある場合、O(15)が必要になります。しかし、ツリーに1500ノードがある場合、O(1500)が必要になります。したがって、幅優先探索アルゴリズムの時間計算量は線形時間、つまりO(n)を要します。ここで、nはツリー内のノードの数です。
空間計算量はこれに似ていますが、チェックする必要のあるノードを追加するときに、キューがどれだけ拡大および縮小するかを処理します。最悪の場合、すべてのノードが互いに子である場合、ツリー内のすべてのノードをキューに入れる可能性があります。つまり、ツリー内のノードと同じ数のメモリを使用している可能性があります。キューのサイズがツリー内のノード数になる可能性がある場合、BFSアルゴリズムの空間計算量も線形時間、つまりO(n)になります。ここで、nはツリー内のノード数です。
これはすべてうまくいっていますが、私が今本当にやりたいことを知っていますか?これらのアルゴリズムの1つを実際に作成したいと思います。最後に、この理論をすべて実践しましょう。
最初の幅優先探索アルゴリズムのコーディング
これで完了です。最後に、最初のBFSアルゴリズムをコーディングします。先週、DFSアルゴリズムを使って少しやりましたので、これの幅優先探索実装も書いてみましょう。
先週、バニラJavaScriptでこれを書いたことを覚えているかもしれません。一貫性を保つために、これを再度使用します。簡単な復習が必要な場合は、シンプルに保ち、ノードオブジェクトを次のようにPlain Old JavaScript Object(POJO)として記述することにしました。
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
わかりました、かっこいいです。 1つのステップが完了しました。
しかし、キューについて理解し、このアルゴリズムを実装するにはキューを使用する必要があると確信しているので、JavaScriptでそれを行う方法を理解する必要があります。実は、JSでキューのようなオブジェクトを作成するのは本当に簡単です!
配列を使用できます。これは非常にうまく機能します:
これを少し凝ったものにしたい場合は、おそらく作成することもできますQueueオブジェクト。topやisEmptyなどの便利な機能があります。ただし、今のところ、非常に単純な機能に依存します。
では、この子犬を書いてみましょう。 rootNodeオブジェクトを取り込むlevelOrderSearch関数を作成します。
すごい!これは実際には…かなり単純です。または、少なくとも、私が予想していたよりもはるかに単純です。ここで行っているのは、whileループを使用して、ノードのチェック、左の子の追加、右の子の追加の3つの手順を続行することだけです。queue配列からすべてが削除され、その長さが0になるまで、配列を繰り返し処理します。
すごい。私たちのアルゴリズムの専門知識はたった1日で急上昇しました!再帰的なツリー走査アルゴリズムを作成する方法を知っているだけでなく、反復的なアルゴリズムを作成する方法も知っています。アルゴリズム検索が非常に強力になる可能性があることを誰が知っていましたか。
リソース
幅優先探索について、そしてそれがいつ役立つかについて学ぶことはまだたくさんあります。幸いなことに、この投稿に収まらなかった情報をカバーするリソースはたくさんあります。以下の本当に良いもののいくつかをチェックしてください。
- スタックとキューを使用したDFSおよびBFSアルゴリズム、ローレンスL.ラーモア教授
- 幅優先探索アルゴリズム、カーンアカデミー
- データ構造—幅優先探索、TutorialsPoint
- バイナリツリー:レベル順序探索、mycodeschool
- 幅優先探索、コンピュータサイエンス学部ボストン大学
