Quando se trata de aprendizagem, geralmente há duas abordagens que podem ser adotadas: você pode ir amplo e tente cobrir o máximo possível do espectro de um campo, ou você pode ir fundo e tentar ser muito, muito específico com o tópico que está aprendendo. A maioria dos bons alunos sabe que, até certo ponto, tudo o que você aprende na vida – de algoritmos a habilidades básicas de vida – envolve alguma combinação dessas duas abordagens.
O mesmo vale para ciência da computação, resolução de problemas, e estruturas de dados. Na semana passada, mergulhamos profundamente na pesquisa em profundidade e aprendemos o que significa atravessar uma árvore de pesquisa binária. Agora que nos aprofundamos, faz sentido irmos além e entender a outra estratégia comum de travessia de árvore.
Em outras palavras, é o momento que todos vocês estavam esperando: é hora para quebrar os fundamentos da pesquisa em largura!
Uma das melhores maneiras de entender o que é a pesquisa em largura (BFS) exatamente é entender o que não é. Ou seja, se compararmos BFS com DFS, será muito mais fácil mantê-los em nossas cabeças. Portanto, vamos refrescar nossa memória da pesquisa em profundidade antes de prosseguirmos.
Sabemos que a pesquisa em profundidade é o processo de descer por um galho de uma árvore até chegar a uma folha, e depois voltando ao “tronco” da árvore. Em outras palavras, implementar um DFS significa percorrer as subárvores de uma árvore de pesquisa binária.
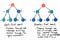
Ok, então como a pesquisa em largura primeiro pesquisar comparar a isso? Bem, se pensarmos sobre isso, a única alternativa real para descer um galho de uma árvore e depois outro é descer a árvore seção por seção – ou nível por nível. E é exatamente isso que BFS é !
A pesquisa abrangente envolve a pesquisa em uma árvore, um nível de cada vez.
Nós atravessar um nível inteiro de nós filhos primeiro, antes de passar para atravessar os nós netos. E atravessamos um nível inteiro de nós de netos antes de passarmos por nós de bisnetos.
Tudo bem, isso parece bastante claro. O que mais diferencia os dois tipos diferentes de algoritmos de travessia de árvore? Bem, já cobrimos as diferenças nos procedimentos desses dois algoritmos. Vamos pensar sobre outro aspecto importante sobre o qual ainda não falamos: implementação.
Primeiro, vamos começar com o que sabemos. Como implementamos a pesquisa em profundidade na semana passada? Você deve se lembrar que aprendemos três métodos diferentes – pedido, pós-pedido e pré-pedido – de pesquisar em uma árvore usando DFS. No entanto, havia algo muito legal sobre como essas três implementações eram semelhantes; cada um deles poderia ser empregado usando recursão. Também sabemos que, como o DFS pode ser escrito como uma função recursiva, eles podem fazer com que a pilha de chamadas aumente e seja tão grande quanto o caminho mais longo na árvore.
No entanto, havia uma coisa que deixei na semana passada que parece bom trazer à tona agora (e talvez seja até um pouco óbvio!): a pilha de chamadas na verdade implementa uma estrutura de dados da pilha. Lembra disso? Aprendemos sobre as pilhas há algum tempo, mas aqui estão elas de novo, aparecendo em todos os lugares!
A coisa realmente interessante sobre a implementação da pesquisa em profundidade usando uma pilha é que, à medida que atravessamos as subárvores de um árvore de pesquisa binária, cada um dos nós que “verificamos” ou “visitamos” é adicionado à pilha. Assim que chegarmos a um nó folha – um nó que não tem filhos – começamos a destacar os nós do topo da pilha. Terminamos no nó raiz novamente e, em seguida, podemos continuar a percorrer a próxima subárvore.

No exemplo da árvore DFS acima, você notará que os nós 2, 3 e 4 são todos adicionados a o topo da pilha. Quando chegamos ao “fim” dessa subárvore – ou seja, quando alcançamos os nós de folha de 3 e 4 – começamos a destacar esses nós de nossa pilha de “nós a visitar”.Você pode ver o que acontecerá eventualmente com a subárvore certa: os nós a visitar serão colocados na pilha de chamadas, nós os visitaremos e sistematicamente retirá-los da pilha.
Eventualmente, assim que visitamos as subárvores esquerda e direita, estaremos de volta ao nó raiz sem mais nada para verificar e nossa pilha de chamadas estará vazia.
Portanto, devemos ser capazes de usar um empilhar a estrutura e fazer algo semelhante com nossa implementação BFS … certo? Bem, não sei se funcionará, mas acho que será útil pelo menos começar desenhando o algoritmo que queremos implementar e ver até onde podemos chegar com ele.
Vamos tentar:

Ok, então temos um gráfico à esquerda que implementamos DFS na semana passada. Como podemos usar um algoritmo BFS nele, em vez disso?
Bem, para começar, sabemos que queremos verificar o nó raiz primeiro. Esse é o único nó ao qual teremos acesso inicialmente, então estaremos “apontando” para o nó f.
Tudo bem, agora teremos que verificar os filhos deste nó raiz. p>
Queremos verificar um filho após o outro, então vamos primeiro ao filho esquerdo – o nó d é o nó para o qual estamos “apontando” agora (e o único nó ao qual temos acesso).
Em seguida, queremos ir para o nó filho certo.
Uh oh. Espere, o nó raiz nem está mais disponível para nós! E não podemos nos mover ao contrário, porque as árvores binárias não têm links reversos! Como vamos chegar ao nó filho certo? E … oh não, o nó filho esquerdo d e o nó filho direito k não estão vinculados de forma alguma. Então, isso significa que é impossível para nós pular de um filho para outro, porque não temos acesso a nada, exceto para os filhos do nó d.
Oh, querida. Não fomos muito longe, pois não? Teremos que descobrir um método diferente de resolver este problema. Precisamos descobrir uma maneira de implementar uma travessia de árvore que nos permita caminhar na árvore em ordem nivelada. A coisa mais importante que precisamos ter em mente é isso:
Precisamos manter uma referência para todos os nós filhos de cada nó que visitamos. Caso contrário, nunca poderemos voltar a eles mais tarde e visitá-los!
Quanto mais penso nisso, mais sinto vontade é como se quiséssemos manter uma lista de todos os nós que ainda precisamos verificar, não é? E no momento em que quero manter uma lista de algo, minha mente pula imediatamente para uma estrutura de dados em particular: uma fila, é claro!
Vamos ver se as filas podem nos ajudar com nossa implementação de BFS.
Filas para o resgate!
Como se constatou, a principal diferença na pesquisa em profundidade e na pesquisa em largura é a estrutura de dados usada para implementar esses dois algoritmos muito diferentes.
Enquanto o DFS usa uma estrutura de dados de pilha, o BFS se apóia na estrutura de dados de fila. O bom de usar filas é que isso resolve o problema que descobrimos anteriormente: permite-nos manter uma referência aos nós aos quais queremos voltar, mesmo que ainda não os tenhamos verificado / visitado.
Adicionamos nós que descobrimos – mas ainda não visitamos – à nossa fila e voltamos a eles mais tarde.
Um termo comum para nós que adicionamos à nossa fila é nós descobertos; um nó descoberto é aquele que adicionamos à nossa fila, cuja localização conhecemos, mas ainda não visitamos de fato. Na verdade, é exatamente isso que torna uma fila a estrutura perfeita para resolver o problema do BFS.

No gráfico à esquerda, começamos adicionando o nó raiz à nossa fila, já que esse é o único nó que já tem acesso (pelo menos, inicialmente) em uma árvore. Isso significa que o nó raiz é o único nó descoberto a ser iniciado.
Assim que tivermos pelo menos um nó enfileirado, podemos iniciar o processo de visitar os nós e adicionar referências aos seus nós filhos em nossa fila.
Ok, então tudo isso pode parecer um pouco confuso. E tudo bem! Acho que será muito mais fácil de entender se dividirmos em etapas mais simples.
Para cada nó em nossa fila – sempre começando com o nó raiz – queremos fazer três coisas:
- Visite o nó, o que normalmente significa apenas imprimir seu valor.
- Adicione o filho esquerdo do nó à nossa fila.
- Adicione o nó direito filho para nossa fila.
Depois de fazermos essas três coisas, podemos remover o nó de nossa fila, porque não precisamos mais dele!Basicamente, precisamos continuar fazendo isso repetidamente até chegarmos ao ponto em que nossa fila está vazia.
Ok, vamos ver isso em ação!
No gráfico abaixo, começamos off com o nó raiz, nó f, como o único nó descoberto. Lembre-se de nossos três passos? Vamos fazê-los agora:
- Iremos visitar o nó fe imprimir seu valor.
- Enfileiraremos uma referência para seu filho esquerdo, nó d.
- Vamos enfileirar uma referência ao filho certo, o nó k.
E então, removeremos o nó f da nossa fila!

O próximo nó na frente da fila é o nó d. Novamente, as mesmas três etapas aqui: imprimir seu valor, adicionar seu filho esquerdo, adicionar seu filho direito e, em seguida, removê-lo da fila.
Nossa fila agora tem referências aos nós k, b e e . Se continuarmos repetindo esse processo sistematicamente, notaremos que estamos, na verdade, percorrendo o gráfico e imprimindo os nós em ordem nivelada. Hooray! Isso é exatamente o que queríamos fazer em primeiro lugar.
A chave para isso funcionar tão bem é a própria natureza da estrutura da fila. As filas seguem o princípio do primeiro a entrar, primeiro a sair (FIFO), o que significa que tudo o que foi enfileirado primeiro é o primeiro item que será lido e removido da fila.
Por último, já que estamos no tópico de filas, é importante mencionar que a complexidade espaço-temporal de um algoritmo BFS também está relacionada à fila que usamos para implementá-lo – quem diria que as filas voltariam para ser tão útil, certo?
A complexidade de tempo de um algoritmo BFS depende diretamente de quanto tempo leva para visitar um nó. Uma vez que o tempo que leva para ler o valor de um nó e enfileirar seus filhos não muda com base no nó, podemos dizer que visitar um nó leva um tempo constante, ou, tempo O (1). Uma vez que só visitamos cada nó em uma árvore de passagem BFS exatamente uma vez, o tempo que levaremos para ler cada nó realmente depende de quantos nós existem na árvore! Se nossa árvore tiver 15 nós, nos levará O (15); mas se nossa árvore tiver 1.500 nós, nos levará O (1.500). Assim, a complexidade de tempo de um algoritmo de busca em largura leva tempo linear, ou O (n), onde n é o número de nós na árvore.
A complexidade do espaço é semelhante a isso, tem mais a fazer com o quanto nossa fila aumenta e diminui à medida que adicionamos os nós que precisamos verificar a ela. Na pior das hipóteses, poderíamos potencialmente estar enfileirando todos os nós em uma árvore se eles fossem todos filhos uns dos outros, o que significa que possivelmente poderíamos estar usando tanta memória quanto o número de nós na árvore. Se o tamanho da fila pode crescer até ser o número de nós na árvore, a complexidade do espaço para um algoritmo BFS também é tempo linear, ou O (n), onde n é o número de nós na árvore.
Tudo isso é muito bom, mas você sabe o que eu realmente gostaria de fazer agora? Eu gostaria de escrever um desses algoritmos! Vamos finalmente colocar toda essa teoria em prática.
Codificando nosso primeiro algoritmo de pesquisa abrangente
Conseguimos! Finalmente iremos codificar nosso primeiro algoritmo BFS. Fizemos um pouco disso na semana passada com algoritmos DFS, então vamos tentar escrever uma implementação de pesquisa abrangente disso também.
Você deve se lembrar que escrevemos isso em JavaScript vanilla na semana passada, então vamos continuar com isso por uma questão de consistência. No caso de você precisar de uma atualização rápida, decidimos mantê-lo simples e escrever nossos objetos de nó como Objetos Plain Old JavaScript (POJO’s), como este:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
Ok, legal. Uma etapa concluída.
Mas agora que sabemos sobre filas e temos certeza de que precisaremos usar uma para implementar esse algoritmo … provavelmente devemos descobrir como fazer isso em JavaScript, certo? Bem, ao que parece, é realmente fácil criar um objeto semelhante a uma fila em JS!
Podemos usar um array, o que faz o truque muito bem:
Se quiséssemos tornar isso um pouco mais sofisticado, provavelmente também poderíamos criar um objeto Queue, que pode ter funções úteis como top ou isEmpty; mas, por enquanto, vamos contar com uma funcionalidade muito simples.
Ok, vamos escrever este cachorrinho! Criaremos uma função levelOrderSearch, que leva em um rootNode objeto.
Incrível! Na verdade, isso é … bastante simples. Ou pelo menos, muito mais simples do que eu esperava que fosse. Tudo o que estamos fazendo aqui é usar um loop while para continuar fazendo essas três etapas de verificação de um nó, adicionando seu filho esquerdo e adicionando seu filho direito.Continuamos iterando por meio da matriz queue até que tudo tenha sido removido dela e seu comprimento seja 0.
Surpreendente. Nossa experiência em algoritmos disparou em apenas um dia! Não apenas sabemos como escrever algoritmos de travessia de árvore recursivos, mas agora também sabemos como escrever algoritmos iterativos. Quem diria que pesquisas algorítmicas poderiam ser tão fortalecedoras!
Recursos
Ainda há muito o que aprender sobre pesquisa abrangente e quando ela pode ser útil. Felizmente, existem toneladas de recursos que cobrem informações que eu não poderia incluir nesta postagem. Confira alguns dos realmente bons abaixo.
- Algoritmos DFS e BFS usando pilhas e filas, Professor Lawrence L. Larmore
- O algoritmo de pesquisa em amplitude primeiro, Khan Academy
- Estrutura de dados – Breadth-First Traversal, TutorialsPoint
- Árvore binária: Level Order Traversal, mycodeschool
- Breadth-First Traversal de uma árvore, Departamento de Ciência da Computação de Boston University
