Când vine vorba de învățare, există în general două abordări pe care le poți lua: poți merge fie larg și încercați să acoperiți cât mai mult din spectrul unui câmp posibil, sau puteți merge mai adânc și încercați să fiți foarte, foarte specific cu subiectul pe care îl învățați. Majoritatea cursanților buni știu că, într-o oarecare măsură, tot ceea ce învățați în viață – de la algoritmi la abilități de bază de viață – implică o combinație a acestor două abordări.
Același lucru este valabil și pentru informatică, rezolvarea problemelor, și structuri de date. Săptămâna trecută, ne-am adâncit în prima căutare a adâncimii și am aflat ce înseamnă să traversăm de fapt un copac de căutare binar. Acum că ne-am adâncit, are sens să mergem pe larg și să înțelegem cealaltă strategie comună de traversare a copacilor.
Cu alte cuvinte, este momentul pe care l-ați așteptat cu toții: este timpul pentru a descompune noțiunile de bază ale căutării pe lățime întâi!
Una dintre cele mai bune modalități de a înțelege exact ce este căutarea pe lățime întâi (BFS) este, înțelegând ceea ce nu este. Adică, dacă comparăm BFS cu DFS, ne va fi mult mai ușor să le ținem drepte în cap. Deci, haideți să ne reîmprospătăm memoria căutării în adâncime înainte de a merge mai departe.
Știm că căutarea în adâncime-întâi este procesul de parcurgere în jos printr-o ramură a unui copac până ajungem la o frunză, și apoi ne îndreptăm spre „trunchiul” arborelui. Cu alte cuvinte, implementarea unui DFS înseamnă parcurgerea în jos prin subarborii unui arbore de căutare binar.
Căutarea în adâncime mai întâi în comparație cu căutarea în primul rând în lățime
Bine, deci cum funcționează în primul rând Căutarea se compară cu asta? Ei bine, dacă ne gândim la asta, singura alternativă reală de a călători pe o ramură a unui copac și apoi pe alta este să călătorești în jos arborele secțiune cu secțiune – sau, nivel cu nivel. Și exact asta este BFS !
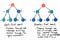
Căutarea în lățime implică căutarea printr-un arbore la un nivel la altul.
Noi parcurgeți mai întâi un nivel întreg de noduri ale copiilor, înainte de a trece prin nodurile nepoților. Și traversăm un nivel întreg de noduri ale nepoților înainte de a traversa nodurile strănepoților.
Bine, pare destul de clar. Ce altceva diferențiază cele două tipuri diferite de algoritmi de traversare a copacilor? Ei bine, am acoperit deja diferențele în procedurile acestor doi algoritmi. Să ne gândim la celălalt aspect important despre care nu am vorbit încă: implementarea.
În primul rând, să începem cu ceea ce știm. Cum ne-am descurcat săptămâna trecută în implementarea căutării în profunzime? S-ar putea să vă amintiți că am învățat trei metode diferite – inorder, postorder și preorder – de căutare printr-un copac folosind DFS. Cu toate acestea, a fost ceva extraordinar despre cât de asemănătoare sunt aceste trei implementări; fiecare ar putea fi angajați folosind recursivitate. Știm, de asemenea, că, din moment ce DFS poate fi scris ca o funcție recursivă, acestea pot face ca stiva de apeluri să crească la fel de mare ca cea mai lungă cale din arbore.
Cu toate acestea, am rămas un lucru săptămâna trecută, care pare bine să apară acum (și poate este chiar puțin evident!): stiva de apeluri implementează de fapt o structură de date a stivei. Îți amintești de acestea? Am aflat despre stive cu ceva timp în urmă, dar iată-le din nou, afișându-se peste tot!
Lucrul cu adevărat interesant despre implementarea căutării în profunzime folosind o stivă este că pe măsură ce traversăm subarborii unui arborele de căutare binar, fiecare dintre nodurile pe care le „verificăm” sau „vizităm” se adaugă la stivă. Odată ce ajungem la un nod frunză – un nod care nu are copii – începem să ieșim din noduri din partea de sus a stivei. Ajungem din nou la nodul rădăcină și apoi putem continua să parcurgem următorul subarbore.
Adâncimea de implementare -prima căutare utilizând o structură de date stivă
În exemplul arborelui DFS de mai sus, veți observa că nodurile 2, 3 și 4 se adaugă la partea de sus a stivei. Când ajungem la „sfârșitul” acelui subarboresc – adică, când ajungem la nodurile frunzei 3 și 4 – începem să scoatem aceste noduri din teancul nostru de „noduri de vizitat”.Puteți vedea ce se va întâmpla în cele din urmă cu subarborele potrivit: nodurile de vizitat vor fi împinse în teancul de apeluri, le vom vizita și le vom scoate sistematic din teanc.
În cele din urmă, odată ce Am vizitat ambele subarbori din stânga și din dreapta, ne vom întoarce la nodul rădăcină, fără a mai rămâne nimic de verificat, iar stiva noastră de apeluri va fi goală.
Deci, ar trebui să putem folosi stivați structura și faceți ceva similar cu implementarea noastră BFS … nu? Ei bine, nu știu dacă va funcționa, dar cred că va fi util să începem cel puțin prin extragerea algoritmului pe care dorim să îl implementăm și pentru a vedea cât de departe putem ajunge cu el.
Să încercăm:
Încercarea de a traversa un copac folosind BFS
Bine, deci avem un grafic în stânga pe care am implementat DFS săptămâna trecută. Cum ar putea folosi un algoritm BFS pe el?
Ei bine, pentru început, știm că vrem să verificăm mai întâi nodul rădăcină. Acesta este singurul nod la care vom avea acces inițial, așa că vom „indica” nodul f.
Bine, acum va trebui să verificăm copiii acestui nod rădăcină.
Vrem să verificăm un copil după altul, deci să mergem mai întâi la copilul din stânga – nodul d este nodul către care „îndreptăm” acum (și singurul nod la care avem acces).
Apoi, vom dori să mergem la nodul copil potrivit.
Uh oh. Așteptați, nodul rădăcină nici nu mai este disponibil pentru noi! Și nu ne putem mișca în sens invers, deoarece copacii binari nu au legături inverse! Cum vom ajunge la nodul copil potrivit? Și … oh, nu, nodul copil stânga d și nodul copil dreapta k nu sunt deloc legate. Deci, asta înseamnă că este imposibil pentru noi să sărim de la un copil la altul, deoarece nu avem acces la nimic, cu excepția copiilor nodului d.
O, dragă. Nu am ajuns prea departe, nu-i așa? Va trebui să ne dăm seama de o altă metodă de rezolvare a acestei probleme. Trebuie să ne dăm seama de o modalitate de a implementa o traversare a copacului care ne va permite să mergem în copac în ordine plană. Cel mai important lucru pe care trebuie să-l avem în vedere este:
Trebuie să păstrăm o referință la toate nodurile copii ale fiecărui nod pe care îl vizităm. În caz contrar, nu vom mai putea reveni la ei mai târziu și le vom vizita!
Cu cât mă gândesc mai mult la asta, cu atât îmi vine mai mult parcă vrem să păstrăm o listă cu toate nodurile pe care trebuie să le verificăm, nu-i așa? Și în momentul în care vreau să păstrez o listă de ceva, mintea mea sare imediat la o structură de date în special: o coadă, desigur!
Să vedem dacă cozile ne pot ajuta cu implementarea BFS.
Cozi de salvare!
După cum se dovedește, o diferență majoră în căutarea în profunzime și în căutarea în primul rând este structura de date utilizată pentru implementarea acestor algoritmi foarte diferiți.
În timp ce DFS utilizează o structură de date stivă, BFS se sprijină pe structura de date a cozii. Interesantul utilizării cozilor este că rezolvă chiar problema pe care am descoperit-o mai devreme: ne permite să păstrăm o referință la nodurile la care dorim să revenim, chiar dacă nu le-am verificat / vizitat încă.
Adăugăm noduri pe care le-am descoperit – dar care nu le-am vizitat încă – la coada noastră și revenim la ele mai târziu. >
Un termen comun pentru noduri pe care le adăugăm la coada noastră sunt nodurile descoperite; un nod descoperit este unul pe care îl adăugăm la coada noastră, a cărui locație o cunoaștem, dar încă nu am vizitat-o. De fapt, tocmai acest lucru face din coadă structura perfectă pentru rezolvarea problemei BFS.
Utilizarea cozilor pentru implementați prima căutare largă
În graficul din stânga, începem adăugând nodul rădăcină în coada noastră, deoarece acesta este singurul nod pe care l-am avut vreodată au acces (cel puțin, inițial) într-un copac. Aceasta înseamnă că nodul rădăcină este singurul nod descoperit care începe.
Odată ce avem cel puțin un nod pus în coadă, putem începe procesul de vizitare a nodurilor și adăugarea de referințe la nodurile lor de copii în coada noastră.
Bine, deci toate acestea ar putea părea puțin confuze. Și este în regulă! Cred că va fi mult mai ușor de înțeles dacă îl împărțim în pași mai simpli.
Pentru fiecare nod din coada noastră – începând întotdeauna cu nodul rădăcină – vom dori să facem trei lucruri:
Accesați nodul, ceea ce înseamnă, de obicei, doar tipărirea valorii acestuia.
Adăugați copilul stâng al nodului în coada noastră.
Adăugați dreapta nodului copil la coada noastră.
Odată ce facem aceste trei lucruri, putem elimina nodul din coada noastră, pentru că nu mai avem nevoie de el!În principiu, trebuie să continuăm să facem acest lucru în mod repetat până când ajungem la punctul în care coada noastră este goală.
Bine, să analizăm acest lucru în acțiune!
În graficul de mai jos, începem oprit cu nodul rădăcină, nodul f, ca singurul nod descoperit. Vă amintiți cei trei pași ai noștri? Să le facem acum:
Vom vizita nodul f și vom imprima valoarea acestuia.
Vom stoca o referință la copilul din stânga, nodul d.
Vom face o referință la copilul său potrivit, nodul k.
Și apoi, vom elimina nodul f din coada noastră!
Creșterea structurii cozii într-o implementare de căutare pe lățime
Următorul nod din partea din față a cozii este nodul d. Din nou, aceiași trei pași aici: tipăriți valoarea acestuia, adăugați copilul stâng, adăugați copilul drept și apoi scoateți-l din coadă.
Coada noastră are acum referințe la nodurile k, b și e . Dacă repetăm în mod sistematic acest proces, vom observa că parcurgem graficul și tipărim nodurile în ordine de nivel. Ura! Exact asta am vrut să facem în primul rând.
Cheia acestei funcționări atât de bine este însăși natura structurii cozii. Cozile respectă principiul first-in, first-out (FIFO), ceea ce înseamnă că tot ceea ce a fost pus în stânga este primul element care va fi citit și eliminat din coadă.
În cele din urmă, în timp ce suntem pe tema cozilor, merită menționat faptul că complexitatea spațiu-timp a unui algoritm BFS este legată și de coada pe care o folosim pentru a-l implementa – cine știa că cozile vor reveni să fie atât de util, nu?
Complexitatea de timp a unui algoritm BFS depinde direct de cât timp este necesar pentru a vizita un nod. Întrucât timpul necesar citirii valorii unui nod și punerea în stăpânire a copiilor acestuia nu se schimbă în funcție de nod, putem spune că vizitarea unui nod necesită timp constant sau, timp O (1). Întrucât vizităm fiecare nod dintr-o traversare a arborelui BFS exact o singură dată, timpul necesar pentru a citi fiecare nod depinde într-adevăr de câte noduri există în arbore! Dacă arborele nostru are 15 noduri, ne va lua O (15); dar dacă arborele nostru are 1500 de noduri, ne va lua O (1500). Astfel, complexitatea în timp a unui algoritm de căutare pe lățime durează liniar, sau O (n), unde n este numărul de noduri din arbore.
Complexitatea spațiului este similară cu aceasta, are mai mult de faceți cu cât coada noastră crește și se micșorează pe măsură ce adăugăm nodurile pe care trebuie să le verificăm. În situația cea mai gravă, am putea potențial stoarce toate nodurile dintr-un copac dacă sunt toți copiii unul al celuilalt, ceea ce înseamnă că am putea folosi cu atâtea memorie cât sunt noduri în arbore. Dacă dimensiunea cozii poate crește până la numărul de noduri din arbore, complexitatea spațiului pentru un algoritm BFS este, de asemenea, timp liniar sau O (n), unde n este numărul de noduri din arbore.
Totul este bine, dar știi ce aș vrea să fac chiar acum? Aș vrea să scriu unul dintre acești algoritmi! Să punem în sfârșit toată această teorie în practică.
Codificarea primului nostru algoritm de căutare pe lățime
Am reușit! În sfârșit, vom codifica primul nostru algoritm BFS. Am făcut puțin din acest lucru săptămâna trecută cu algoritmi DFS, așa că haideti să încercăm să scriem și o implementare de căutare pe larg.
S-ar putea să vă amintiți că am scris asta în vanilie JavaScript săptămâna trecută, deci vom rămâne cu asta din nou de dragul coerenței. În cazul în care aveți nevoie de o reîmprospătare rapidă, am decis să o simplificăm și să scriem obiectele nodului nostru ca obiecte obișnuite JavaScript vechi (POJO), astfel:
Dar acum, când știm despre cozi și suntem siguri că va trebui să folosim unul pentru a implementa acest algoritm … probabil ar trebui să ne dăm seama cum să facem acest lucru în JavaScript, nu? Ei bine, după cum se dovedește, este foarte ușor să creezi un obiect asemănător cozii în JS!
Putem folosi o matrice, care face trucul destul de frumos:
Dacă am vrea să facem acest lucru puțin mai amuzant, am putea crea, de asemenea, probabil un obiect Queue, care ar putea avea o funcție utilă ca top sau isEmpty; dar, deocamdată, ne vom baza pe funcționalități foarte simple.
Bine, să scriem acest cățeluș! Vom crea o funcție levelOrderSearch, care include un obiect rootNode.
Minunat! Acesta este de fapt … destul de simplu. Sau cel puțin, mult mai simplu decât mă așteptam să fie. Tot ce facem aici este să folosim o buclă while pentru a continua acești trei pași de verificare a unui nod, adăugarea copilului stâng și adăugarea copilului drept.Continuăm să iterăm prin matricea queue până când totul a fost eliminat din el și lungimea acestuia este 0.
Uimitor. Expertiza noastră în algoritmi a crescut în doar o zi! Nu numai că știm să scriem algoritmi recursivi de traversare a copacilor, dar acum știm și să scriem algoritmi iterativi. Cine a știut că căutările algoritmice ar putea fi atât de împuternicitoare!
Resurse
Există încă multe de învățat despre prima căutare amplă și când poate fi utilă. Din fericire, există o mulțime de resurse care acoperă informații pe care nu le-aș putea încadra în această postare. Consultați câteva dintre cele foarte bune de mai jos.
Algoritmi DFS și BFS folosind stive și cozi, profesorul Lawrence L. Larmore
The Breadth-First Search Algorithm, Khan Academia
Structura datelor – Lățimea întâi traversare, Tutorial Punct
Arborele binar: traversarea ordinii de nivel, mycodeschool
Lărgimea-prima traversare a unui arbore, Departamentul de informatică al Universitatea din Boston