Oppimisen suhteen on yleensä kaksi lähestymistapaa: voit joko mennä ja yritä peittää mahdollisimman suuri osa alan spektristä, tai voit mennä syvälle ja yrittää saada todella, todella täsmällinen oppimasi aiheen kanssa. Suurin osa hyvistä oppijoista tietää, että jossain määrin kaikkeen, mitä opit elämässäsi – algoritmeista elämän perustaitoihin – sisältyy näiden kahden lähestymistavan yhdistelmä.
Sama koskee tietojenkäsittelytieteitä, ongelmanratkaisuja, ja tietorakenteet. Viime viikolla kynsimme syvälle syvimpään etsintään ja opimme, mitä tarkoittaa todellinen kulkeminen binäärisen hakupuun läpi. Nyt kun olemme menneet syvälle, on järkevää mennä leveäksi ja ymmärtää muu yleinen puun kulkustrategia.
Toisin sanoen, se on hetki, jota olette kaikki odottaneet: on aika hajottaa leveys-ensimmäisen haun perusteet!
Yksi parhaista tavoista ymmärtää, mikä on leveys-ensimmäinen haku (BFS), on ymmärtää, mitä se ei ole. Toisin sanoen, jos verrataan BFS: ää DFS: ään, meidän on paljon helpompaa pitää ne suoraan päämme. Joten päivitämme muistimme syvyyden etsinnästä ennen kuin siirrymme eteenpäin.
Tiedämme, että syvyyshaku on prosessi, joka kulkee alas puun yhden oksan läpi, kunnes pääsemme lehteen, ja sitten palataan takaisin puun ”runkoon”. Toisin sanoen DFS: n toteuttaminen tarkoittaa kulkemista alaspäin binäärisen hakupuun alipuiden läpi.
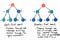
Okei, niin miten leveys ensin haku vertaa siihen? No, jos ajattelemme sitä, ainoa todellinen vaihtoehto matkalle puun yhdestä oksasta alaspäin on toinen kulkeminen puusta alas osittain – tai tasolta tasolle. Ja juuri tämä on BFS !
Leveyshaku sisältää puun haun tasolta kerrallaan.
Me kulkea ensin yhden kokonaisen lapsisolmutason läpi, ennen kuin siirtyä kulkemaan lastenlasten solmujen läpi. Ja käymme läpi koko lapsenlapsen solmujen, ennen kuin jatkamme lastenlastenlapsen solmujen läpi.
Selvä, se näyttää melko selvältä. Mikä vielä erottaa kaksi erilaista puun läpikulkualgoritmia? No, olemme jo käsitelleet näiden kahden algoritmin menettelytapojen erot. Mietitään muuta tärkeää näkökohtaa, josta emme ole vielä puhuneet: toteutusta.
Aloitetaan ensin tiedämme. Kuinka edistyimme viime viikolla syvyyshaun toteuttamisessa? Saatat muistaa, että opimme kolme erilaista tapaa etsiä puusta DFS: n avulla – tilaus, postitilaus ja ennakkotilaus. Silti siinä oli jotain erittäin hienoa siitä, kuinka samanlaisia nämä kolme toteutusta olivat; heitä kaikkia voitaisiin käyttää rekursiota käyttämällä. Tiedämme myös, että koska DFS voidaan kirjoittaa rekursiivisena funktiona, ne voivat aiheuttaa puhelupinon kasvavan yhtä suureksi kuin puun pisin polku.
Jätin kuitenkin yhden asian viime viikolla, joka näyttää hyvältä tuoda esiin nyt (ja ehkä se on jopa hieman ilmeinen!): puhelupino todella toteuttaa pinon tietorakenteen. Muistatko ne? Opimme pinoista jonkin aikaa sitten, mutta tässä ne ovat taas, ja ne näkyvät kaikkialla!
Todella mielenkiintoinen asia syvyyslähtöisen haun toteuttamisessa pinon avulla on se, että kulkiessamme läpi alipuut binaarihakupuu, kukin soluista, joita ”tarkistamme” tai ”vierailemme”, lisätään pinoon. Kun olemme saavuttaneet lehtisolmun – solmun, jolla ei ole lapsia -, alamme pudota solmut pinon yläosasta. Päätymme uudelleen juurisolmuun ja voimme jatkaa seuraavaa alipuuta pitkin.

Esimerkiksi yllä olevassa DFS-puussa huomaat, että kaikki solmut 2, 3 ja 4 lisätään pinon yläosassa. Kun olemme saavuttaneet tuon alipuun ”lopun” – toisin sanoen saavuttaessamme 3 ja 4 lehtisolmut – alamme pudota noita solmuja ”vierailukohtien solmustamme”.Näet, mitä oikean alipuun kohdalla lopulta tapahtuu: solmukohdat, jotka vierailet, työnnetään puhelupinoon, vierailemme niissä ja pudotamme järjestelmällisesti ne pinosta.
Lopulta, kun olemme Olemme käyneet sekä vasemmassa että oikeassa alipuussa, palaamme juurisolmuun, eikä mitään tarkistettavaa ole jäljellä, ja puhelupino on tyhjä.
Joten meidän pitäisi pystyä käyttämään pinota rakenne ja tee jotain vastaavaa BFS-toteutuksellamme … eikö? No, en tiedä, toimiiko se, mutta mielestäni on hyödyllistä ainakin aloittaa piirtämällä algoritmi, jonka haluamme toteuttaa, ja nähdä, kuinka pitkälle voimme saavuttaa sen.
Yritetään:

Okei, joten vasemmalla puolella on kaavio, jonka mukaan DFS otettiin käyttöön viime viikolla. Kuinka voimme käyttää sen sijaan BFS-algoritmia?
Aluksi tiedämme, että haluamme tarkistaa ensin juurisolmun. Se on ainoa solmu, johon pääsemme alun perin, joten ”osoitamme” solmuun f.
Selvä, nyt meidän on tarkistettava tämän juurisolmun lapset.
Haluamme tarkistaa yhden lapsen toisensa jälkeen, joten mennään ensin vasemmalle lapselle – solmu d on solmu, johon ”osoitamme” nyt (ja ainoa solmu, johon meillä on pääsy).
Seuraavaksi haluamme siirtyä oikeaan lapsisolmuun.
Voi oh. Odota, juurisolmu ei ole enää edes käytettävissä! Emme voi liikkua taaksepäin, koska binaaripuilla ei ole käänteisiä linkkejä! Kuinka aiomme päästä oikeaan lapsisolmuun? Ja… no ei, vasen lapsisolmu d ja oikea lapsisolmu k eivät ole lainkaan yhteydessä toisiinsa. Joten, se tarkoittaa, että meidän on mahdotonta hypätä lapselta toiselle, koska meillä ei ole mitään muuta kuin solmun d lapsia.
Voi kulta. Emme päässeet kovin pitkälle, vai mitä? Meidän on löydettävä erilainen tapa ratkaista tämä ongelma. Meidän on keksittävä jokin tapa toteuttaa puun läpikulku, jonka avulla voimme kävellä puuta tasaisessa järjestyksessä. Tärkein asia, joka meidän on pidettävä mielessä, on tämä:
Meidän on pidettävä viittaus jokaisen käymämme solmun kaikkiin lapsisolmuihin. Muuten emme voi koskaan palata heidän luokseen myöhemmin ja käydä heidän luonaan!
Mitä enemmän ajattelen sitä, sitä enemmän minusta tuntuu se on kuin haluaisimme pitää luettelon kaikista solmuista, jotka meidän on vielä tarkistettava, eikö olekin? Ja kun haluan pitää luettelon jostakin, mieleni hyppää heti yhteen tietorakenteeseen: tietysti jonoon!
Katsotaanpa, voivatko jonot auttaa meitä BFS-toteutuksessamme.
Jonot pelastukseen!
Kuten käy ilmi, merkittävä ero syvyys-etsinnässä ja leveysetsinnässä on tietorakenne, jota käytetään näiden molempien hyvin erilaisten algoritmien toteuttamiseen.
Vaikka DFS käyttää pinotietorakennetta, BFS nojaa jonotietorakenteeseen. Jonojen käytössä on hienoa, että se ratkaisee juuri aiemmin havaitsemamme ongelman: sen avulla voimme säilyttää viittauksen solmuihin, joihin haluamme palata, vaikka emme ole vielä tarkistaneet / käyneet niissä.
Lisäämme jonoon solmut, jotka olemme löytäneet – mutta joita emme ole vielä käyneet – ja palaamme niihin myöhemmin.
Yleinen termi solmuille, jotka lisätään jonoon, ovat löydetyt solmut; löydetty solmu on sellainen, jonka lisäämme jonoon, jonka sijainnin tiedämme, mutta emme ole vielä käyneet siellä. Itse asiassa tämä tekee jonosta täydellisen rakenteen BFS-ongelman ratkaisemiseksi.

Vasemmalla olevassa kaaviossa aloitetaan lisäämällä juurisolmu jonoon, koska se on ainoa solmu, jonka olemme koskaan on pääsy puuhun (ainakin aluksi). Tämä tarkoittaa, että juurisolmu on ainoa löydetty solmu, joka alkaa.
Kun ainakin yksi solmu on kiinnitetty, voimme aloittaa solmujen vierailun ja lisätä viitteitä lasten solmuihin jonoon.
Okei, joten kaikki tämä saattaa kuulostaa hieman hämmentävältä. Ja se on okei! Mielestäni on paljon helpompi ymmärtää, jos jaamme sen yksinkertaisempiin vaiheisiin.
Haluamme tehdä jokaisessa jonossa olevassa solmussa – aina juurisolmusta alkaen – kolme asiaa:
- Käy solmussa, mikä yleensä tarkoittaa vain sen arvon tulostamista.
- Lisää solmun vasen lapsi jonoon.
- Lisää solmun oikea lapsi jonoon.
Kun teemme nämä kolme asiaa, voimme poistaa solmun jonostamme, koska emme enää tarvitse sitä!Meidän on periaatteessa jatkettava tätä toistuvasti, kunnes pääsemme pisteeseen, jossa jonomme on tyhjä.
Okei, katsotaanpa tätä toiminnassa!
Aloitamme alla olevassa kaaviossa pois päätasolta, solmu f, ainoana löydettynä solmuna. Muistatko kolme vaihettamme? Tehdään ne nyt:
- Käymme solmussa f ja tulostamme sen arvon.
- Luomme viitteen sen vasemmalle alatasolle, solmu d.
- Luomme viittauksen sen oikeaan lapseen, solmuun k.
Ja sitten poistamme solmun f jonostamme!

Seuraava jonon edessä oleva solmu on solmu d. Jälleen samat kolme vaihetta tässä: tulosta sen arvo, lisää vasen lapsi, lisää oikea lapsi ja poista se sitten jonosta.
Jonossa on nyt viitteitä solmuihin k, b ja e. . Jos toistamme tätä prosessia järjestelmällisesti, huomaat, että käymme läpi kaavion ja tulostamme solmut tasojärjestyksessä. Hurraa! Juuri sen halusimme tehdä ensinnäkin.
Avain tähän hyvin toimivaan toimintoon on jonorakenteen luonne. Jonot noudattavat first-in, first-out (FIFO) -periaatetta, mikä tarkoittaa, että mikä ensin kirjoitettiin, se on ensimmäinen kohde, joka luetaan ja poistetaan jonosta.
Lopuksi, vaikka olemme jonojen aiheessa, on syytä mainita, että BFS-algoritmin aika-ajan monimutkaisuus liittyy myös jonoon, jota käytämme sen toteuttamiseen – kuka tiesi, että jonot palaisivat takaisin olla niin hyödyllinen, eikö?
BFS-algoritmin ajan monimutkaisuus riippuu suoraan siitä, kuinka kauan solmun vierailu vie. Koska solmun arvon lukemiseen ja sen lasten houkuttamiseen kuluva aika ei muutu solmun perusteella, voimme sanoa, että solmun vierailu vie jatkuvasti tai O (1) aikaa. Koska vierailemme vain jokaisessa BFS-puun läpikulun solmussa täsmälleen kerran, jokaisen solmun lukemiseen kuluva aika riippuu oikeastaan vain siitä, kuinka monta solmua puussa on! Jos puullamme on 15 solmua, se vie meidät O (15); mutta jos puullamme on 1500 solmua, se vie meidät O (1500). Siten leveysennakkoisen hakualgoritmin aikakompleksisuus vie lineaarista aikaa tai O (n), jossa n on puun solmujen määrä.
Avaruuden monimutkaisuus on samanlainen kuin tällä, on enemmän tehdä, kuinka paljon jonomme kasvaa ja kutistuu, kun lisätään siihen tarkistettavat solmut. Pahimmassa tapauksessa voisimme mahdollisesti houkutella kaikki puun solmut, jos ne kaikki ovat toistensa lapsia, mikä tarkoittaa, että voimme mahdollisesti käyttää niin paljon muistia kuin puussa on solmuja. Jos jonon koko voi kasvaa puun solmujen lukumääräksi, BFS-algoritmin tilan monimutkaisuus on myös lineaarinen aika tai O (n), jossa n on puun solmujen määrä.
Kaikki on hyvin ja hyvä, mutta tiedätkö mitä haluaisin todella tehdä juuri nyt? Haluaisin itse kirjoittaa yhden näistä algoritmeista! Otetaan vihdoin kaikki tämä teoria käytäntöön.
Ensimmäisen leveimmän ensimmäisen hakualgoritmimme koodaus
Olemme tehneet sen! Aiomme vihdoin koodata ensimmäisen BFS-algoritmin. Teimme vähän tästä viime viikolla DFS-algoritmeilla, joten yritetään kirjoittaa myös tämän ensimmäinen hakutoteutus.
Muistatte, että kirjoitimme tämän vaniljakoodauskoodilla viime viikolla, joten pidämme kiinni siitä uudelleen johdonmukaisuuden vuoksi. Jos tarvitset nopean päivityksen, päätimme pitää sen yksinkertaisena ja kirjoittaa solmuobjektimme Tavallisiksi vanhiksi JavaScript-objekteiksi (POJO), kuten tämä:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
Okei, siistiä. Yksi askel tehty.
Mutta nyt kun tiedämme jonot ja olemme varmoja, että joudumme käyttämään sitä tämän algoritmin toteuttamiseen … meidän pitäisi todennäköisesti selvittää, miten se tehdään JavaScriptissä, eikö? No, kuten käy ilmi, jonon kaltaisen objektin luominen JS: ään on todella helppoa!
Voimme käyttää taulukkoa, joka tekee temppun melko hienosti:
Jos haluaisimme tehdä tästä hieman miellyttävämmän, voimme todennäköisesti luoda Queue -objekti, jolla voi olla kätevä toiminto, kuten top tai isEmpty; mutta toistaiseksi luotamme hyvin yksinkertaisiin toimintoihin.
Okei, kirjoitetaan tämä pentu! Luomme funktion levelOrderSearch, joka vie objektin rootNode.
Mahtava! Tämä on oikeastaan … melko yksinkertaista. Tai ainakin paljon yksinkertaisempi kuin odotin sen olevan. Ainoa mitä täällä teemme, on while -silmukan jatkaminen näiden kolmen vaiheen suorittamiseksi: solmun tarkistaminen, vasemman lapsen lisääminen ja oikean lapsen lisääminen.Jatkamme iterointia queue -taulukon kautta, kunnes kaikki on poistettu siitä ja sen pituus on 0.
Hämmästyttävä. Algoritmiosaamisemme on noussut taivaalle päivässä! Paitsi että tiedämme kuinka kirjoittaa rekursiivisia puiden läpikulkualgoritmeja, nyt tiedämme myös, kuinka kirjoittaa iteratiivisia. Kuka tiesi, että algoritmiset haut voisivat olla niin vaikuttavia!
Resurssit
Leveys-ensimmäisestä hausta ja siitä, milloin se voi olla hyödyllistä, on vielä paljon opittavaa. Onneksi on olemassa runsaasti resursseja, jotka kattavat tietoja, joita en voinut sovittaa tähän viestiin. Katso muutamia alla olevista todella hyvistä.
- DFS- ja BFS-algoritmit pinojen ja jonojen avulla, professori Lawrence L. Larmore
- The Breadth-First Search Algorithm, Khan Akatemia
- Tietorakenne – Laajuuden ensimmäinen läpikulku, TutorialsPoint
- Binaarinen puu: Tasojärjestyksen läpikäynti, mykoodikoulu
- Puun leveys – ensimmäinen läpikulku, Tietojenkäsittelytieteen osasto Bostonin yliopisto
