Ami a tanulást illeti, általában kétféle megközelítést lehet alkalmazni: széles, és próbáljon meg egy adott terület spektrumát a lehető legnagyobb mértékben lefedni, különben elmélyülhet, és megpróbálhat igazán, nagyon konkrét lenni a tanult témával. A legtöbb jó tanuló tudja, hogy bizonyos mértékig mindaz, amit az életben megtanulsz – az algoritmusoktól az alapvető életkészségekig – e két megközelítés kombinációját foglalja magában.
Ugyanez vonatkozik az informatikára, a problémamegoldásra, és adatszerkezetek. A múlt héten mélyen belemerültünk a mélységi keresésbe, és megtudtuk, mit jelent valójában egy bináris keresőfán keresztül haladni. Most, hogy elmélyültünk, van értelme a szélesre menni és megérteni a másik általános fa bejárási stratégiát.
Más szavakkal, ez az a pillanat, amire mindannyian vártatok: itt az idő lebontani a szélesség-első keresés alapjait!
Az egyik legjobb módja annak, hogy megértsük, mi is a szélesség-első keresés (BFS), ha megértjük, mi nem. Vagyis, ha összehasonlítjuk a BFS-t a DFS-kel, sokkal könnyebb lesz számunkra egyenesen tartani őket a fejünkben. Tehát frissítsük emlékünket a mélység-első keresésről, mielőtt tovább mennénk.
Tudjuk, hogy a mélység-első keresés az a folyamat, amikor egy fa egyik ágán keresztül haladunk lefelé, amíg el nem érünk egy levélig, majd visszafordulunk a fa “törzséhez”. Más szóval, a DFS megvalósítása azt jelenti, hogy a bináris keresőfa részfáin keresztül haladunk lefelé.
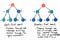
Rendben, akkor hogy van a szélesség első keresés ehhez képest? Nos, ha belegondolunk, az egyetlen valódi alternatíva a fa egyik ágának lefelé haladásához, majd a másik egy leágazás a fán szakaszonként vagy szintenként. És pontosan ez a BFS !
A szélesség első keresése magában foglalja a fán történő keresést, egy szintenként.
Mi először egy egész gyermekcsomóponton haladjon át, majd az unokák csomópontjain haladjon át. És az unokák csomópontjainak teljes szintjén haladunk át, mielőtt dédunokák csomópontjain mennénk keresztül.
Rendben, ez elég világosnak tűnik. Mi különbözteti meg még a két különböző típusú fa bejárási algoritmust? Nos, a két algoritmus eljárásainak különbségeit már lefedtük. Gondoljuk át a másik fontos szempontot, amelyről még nem beszéltünk: a megvalósításról.
Először is kezdjük azzal, amit tudunk. Hogyan haladtunk a mélység-első keresés végrehajtásával a múlt héten? Emlékezhet arra, hogy három különböző módszert tanultunk meg – inorder, postorder és preorder – a fán való kereséshez DFS segítségével. Mégis volt valami nagyon jó abban, hogy ez a három megvalósítás mennyire hasonlít egymásra; rekurzió alkalmazásával mindegyik alkalmazható. Azt is tudjuk, hogy mivel a DFS rekurzív függvényként írható, akkor a hívásverem akkora növekedéshez vezethet, mint a fa leghosszabb útja.
Azonban egy dolgot hagytam a múlt héten jónak tűnik felhozni (és talán ez egy kicsit nyilvánvaló is!): A hívásverem tulajdonképpen megvalósítja a verem adatstruktúráját. Emlékszel ezekre? Egy ideje már tanultunk a halmokról, de itt vannak ismét, és mindenhol megjelennek!
A mélységes keresés verem segítségével történő megvalósításának igazán érdekes dolga az, hogy amikor haladunk egy bináris keresőfa, az általunk “ellenőrzött” vagy “meglátogatott” csomópontok mindegyike hozzáadódik a veremhez. Amint elértünk egy levélcsomópontot – egy olyan csomópontot, amelynek nincs gyermeke -, elkezdjük kipattanni a csomópontokat a verem tetejéről. Újra a gyökércsomópontnál vagyunk, majd folytathatjuk a következő részfán való lefelé haladást.

A fenti DFS-fában észreveheti, hogy a 2., 3. és 4. csomópont mind hozzáadódik a verem teteje. Amikor eljutunk az alfa “végéhez” – vagyis amikor elérjük a 3-as és a 4-es levélcsomópontokat – elkezdjük kipattanni ezeket a csomópontokat a “meglátogatni kívánt csomópontok” halmazunkból.Láthatja, hogy mi fog történni a megfelelő alfával: a meglátogatandó csomópontok a hívásverembe kerülnek, meglátogatjuk őket, és szisztematikusan kipattanjuk őket a veremből.
Végül, ha egyszer meglátogattuk a bal és a jobb alfát is, visszatérünk a gyökércsomópontra, és már nincs mit ellenőrizni, és a hívásveremünk üres lesz.
Tehát képesnek kell lennünk a verem struktúrát, és tegyen valami hasonlót a BFS megvalósítással … igaz? Nos, nem tudom, hogy működni fog-e, de úgy gondolom, hogy hasznos lesz legalább elindulni azzal, hogy kihúzza az implementálni kívánt algoritmust, és meglátja, meddig juthatunk el vele.
Próbáljuk meg:

Rendben, ezért balra van egy grafikonunk, amelyen a múlt héten implementáltuk a DFS-t. Hogyan használhatunk rajta helyette egy BFS algoritmust?
Nos, kezdésként tudjuk, hogy először a gyökércsomópontot akarjuk ellenőrizni. Ez az egyetlen csomópont, amelyhez kezdetben hozzáférünk, ezért “mutatunk” az f csomópontra.
Rendben, most ellenőriznünk kell ennek a gyökércsomópontnak a gyermekeit.
Egyik gyermeket szeretnénk ellenőrizni a másik után, ezért menjünk először a bal gyermekhez – a d csomópont az a csomópont, amelyre most “mutatunk” (és az egyetlen csomópont, amelyhez hozzáférünk).
Ezután a megfelelő gyermek csomópontra akarunk menni.
Ó, ó. Várjon, a gyökércsomópont már nem is áll rendelkezésünkre! És nem tudunk hátramenetben haladni, mert a bináris fáknak nincs fordított kapcsolata! Hogyan jutunk el a megfelelő gyermekcsomóponthoz? És… ó, nem, a bal bal és a jobb gyermek csomópont egyáltalán nincsenek összekapcsolva. Tehát ez azt jelenti, hogy lehetetlen egyik gyermekről a másikra ugrani, mert a d csomópont gyermekein kívül semmihez sem férünk hozzá.
Ó, kedves. Ugye nem jutottunk túl messzire? Ki kell találnunk egy másik módszert a probléma megoldására. Ki kell találnunk a fák bejárásának valamilyen módját, amely lehetővé teszi, hogy a fát sík sorrendben járjuk. A legfontosabb dolog, amit szem előtt kell tartanunk:
Minden meglátogatott csomópont összes gyermekcsomópontjára hivatkozást kell tartanunk. Ellenkező esetben soha többé nem fogunk tudni visszatérni hozzájuk, és meglátogatni őket.
Minél jobban gondolkodom rajta, annál nagyobb kedvem van hozzá mintha szeretnénk listát tartani az összes csomópontról, amelyet még ellenőriznünk kell, nem? Abban a pillanatban, hogy valamiről listát akarok vezetni, az elmém azonnal egy adatstruktúrára ugrik: természetesen egy sorra!
Nézzük meg, hogy a sorok segíthetnek-e bennünket a BFS megvalósításunkban.
Sorok a mentéshez!
Mint kiderült, a mélység-első keresés és a szélesség-első keresés között jelentős különbség van a két nagyon különböző algoritmus megvalósításához használt adatstruktúrában.
Míg a DFS verem adatstruktúrát használ, addig a BFS a sor adatstruktúrájára támaszkodik. A várakozási sorok használatának az a szép, hogy megoldja azt a problémát, amelyet korábban felfedeztünk: lehetővé teszi számunkra, hogy megőrizzük a csomópontok hivatkozását, amelyekhez vissza akarunk térni, annak ellenére, hogy még nem néztük meg őket.
Az általunk felfedezett – de még nem felkeresett – csomópontokat felvesszük a sorunkba, és később visszatérünk hozzájuk.
A csomópontok általános kifejezései, amelyeket hozzáadunk a várólistánkhoz, felfedezett csomópontok; egy felfedezett csomópont az, amelyet felveszünk a várólistánkba, amelynek helyét ismerjük, de valójában még nem látogattuk meg. Valójában pontosan ez teszi a várólistát a BFS probléma megoldásának tökéletes szerkezetévé.

A bal oldali grafikonon azzal kezdjük, hogy hozzáadjuk a gyökércsomópontot a sorunkhoz, mivel ez az egyetlen csomópont, amit valaha hozzáférjen (legalábbis kezdetben) egy fához. Ez azt jelenti, hogy a gyökércsomópont az egyetlen felfedezett csomópont, amely elindul.
Ha legalább egy csomópont be van építve, megkezdhetjük a csomópontok felkeresésének folyamatát, és hozzáadhatjuk a gyermekeik csomópontjaira vonatkozó hivatkozásokat a sorunkba.
Oké, szóval ez mind kissé zavarónak tűnhet. És ez rendben van! Azt hiszem, sokkal könnyebb megfogni, ha egyszerűbb lépésekre bontjuk.
A sorban lévő minden csomópontnál – mindig a gyökércsomóponttól kezdve – három dolgot akarunk megtenni:
- Látogassa meg a csomópontot, ami általában csak azt jelenti, hogy kinyomtatja az értékét.
- Adja hozzá a csomópont bal gyermekét a sorunkhoz.
- Adja hozzá a csomópont jobbját gyermek a várólistánkba.
Ha ezt a három dolgot elvégezzük, eltávolíthatjuk a csomópontot a sorunkból, mert már nincs rá szükségünk!Alapvetően ezt folyamatosan kell folytatnunk, amíg el nem jutunk arra a pontra, amikor a sorunk üres.
Rendben, nézzük meg ezt működés közben!
Az alábbi grafikonon kezdjük ki az f csomópont, mint az egyetlen felfedezett csomópont. Emlékszel a három lépésünkre? Most végezzük el őket:
- Meglátogatjuk az f csomópontot, és kinyomtatjuk az értékét.
- Hivatkozást mutatunk a bal gyermekére, a d csomópontra.
- Hivatkozást mutatunk a jobb gyermekére, a k csomópontra.
Ezután eltávolítjuk az f csomópontot a sorunkból!

A következő csomópont a sor elején a d csomópont. Ismét ugyanaz a három lépés itt: kinyomtatja az értékét, hozzáadja a bal gyermekét, hozzáadja a jobb gyermekét, majd eltávolítja a sorból.
A várólistánkban most hivatkozunk a k, b és e csomópontokra. . Ha folyamatosan szisztematikusan ismételjük ezt a folyamatot, akkor észrevesszük, hogy valójában haladunk a grafikonon, és a sorrendben kinyomtatjuk a csomópontokat. Hurrá! Először pontosan ezt szerettük volna megtenni.
Ennek a remek működésnek a kulcsa a sorstruktúra természete. A várólisták a first-in, first-out (FIFO) elvet követik, ami azt jelenti, hogy bármi, amit elsőként állítottak be, az az első elem, amelyet elolvasnak és eltávolítanak a sorból.
Végül, miközben a sorok témáján vagyunk, érdemes megemlíteni, hogy egy BFS algoritmus tér-idő bonyolultsága összefügg azzal a várakozási sorral is, amelyet a megvalósításához használunk – aki tudta, hogy a sorok visszatérnek hogy ilyen hasznos legyen, igaz?
A BFS algoritmus időbeli összetettsége közvetlenül attól függ, hogy mennyi időbe telik egy csomópont meglátogatása. Mivel az az idő, amely egy csomópont értékének kiolvasásához és gyermekeinek megszerzéséhez szükséges, a csomópont alapján nem változik, azt mondhatjuk, hogy egy csomópont meglátogatása állandó időt, vagy O (1) időt vesz igénybe. Mivel egy BFS fa áthaladásának minden egyes csomópontját csak egyszer látogatjuk meg pontosan, az az idő, amely alatt minden csomópontot elolvasunk, csak attól függ, hogy hány csomópont van a fában! Ha a fánknak 15 csomópontja van, akkor O (15) elvisz minket; de ha a fánknak 1500 csomópontja van, akkor O (1500) elvisz minket. Így a szélességig terjedő első keresési algoritmus időbeli bonyolultsága lineáris időt vesz igénybe, vagy O (n), ahol n a fa csomópontjainak száma.
A tér bonyolultsága hasonló ehhez csináld, hogy mennyivel növekszik és csökken a sorunk, miközben hozzáadjuk az ellenőrizni kívánt csomópontokat. A legrosszabb esetben potenciálisan a fa összes csomópontját lehívhatjuk, ha mindannyian egymás gyermekei, ami azt jelenti, hogy annyi memóriát használhatunk, amennyit csomópontok találhatók a fán. Ha a sor mérete megnőhet a fa csomópontjainak számához, akkor a BFS algoritmus térbonyolultsága szintén lineáris idő, vagy O (n), ahol n a fa csomópontjainak száma.
Ez nagyon jó, de tudod, mit szeretnék most igazán csinálni? Szeretném valóban megírni ezen algoritmusok egyikét! Végül alkalmazzuk mindezt az elméletet a gyakorlatban.
Első szélességi keresési algoritmusunk kódolása
Sikerült! Végül kódolni fogjuk a legelső BFS algoritmusunkat. A múlt héten tettünk egy keveset DFS algoritmusokkal, ezért próbáljuk meg megírni ennek is a legelső keresési megvalósítását.
Emlékezhet, hogy ezt a múlt héten vanília JavaScript-ben írtuk, tehát a következetesség kedvéért még egyszer kitartunk ezzel. Ha gyors frissítésre van szüksége, úgy döntöttünk, hogy egyszerűvé tesszük, és csomópontobjektumainkat Sima régi JavaScript objektumokként (POJO) írjuk, így:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
Oké, klassz. Egy lépés megtörtént.
De most, hogy tudunk a várólistákról, és biztosak vagyunk abban, hogy egyet kell használnunk ennek az algoritmusnak a megvalósításához … valószínűleg ki kellene találnunk, hogyan kell ezt megtenni a JavaScript-ben, igaz? Nos, mint kiderült, nagyon egyszerű létrehozni egy sorszerű objektumot a JS-ben!
Használhatunk egy tömböt, ami elég szépen elvégzi a trükköt:
Ha ezt kicsit kedvesebbé szeretnénk tenni, akkor valószínűleg létrehozhatnánk egy Queue objektum, amelynek hasznos funkciói lehetnek, például: top vagy isEmpty; de egyelőre nagyon egyszerű funkcionalitásra fogunk támaszkodni.
Oké, írjuk meg ezt a kiskutyát! Létrehozunk egy levelOrderSearch függvényt, amely egy rootNode objektumot vesz fel.
Félelmetes! Ez valójában … meglehetősen egyszerű. Vagy legalábbis sokkal egyszerűbb, mint amire számítottam. Itt csak annyit csinálunk, hogy egy while ciklust használunk a csomópont ellenőrzésének, a bal gyermek hozzáadásának és a jobb gyermek hozzáadásának három lépésének folytatásához.Addig folytatjuk az iterációt a queue tömbön, amíg mindent eltávolítunk belőle, és hossza 0.
Elképesztő. Algoritmus-tudásunk egy nap alatt az egekbe szöktek! Nemcsak rekurzív fa bejárási algoritmusok írását ismerjük, hanem iteratívak írását is. Ki tudta, hogy az algoritmikus keresések ennyire felhatalmazást jelenthetnek!
Erőforrások
Sokat kell még tanulni a szélesség első kereséséről, és arról, hogy mikor lehet hasznos. Szerencsére rengeteg erőforrás fed le olyan információkat, amelyeket nem tudtam beilleszteni ebbe a bejegyzésbe. Az alábbiakban megnézhet néhány igazán jót.
- DFS és BFS algoritmusok verem és várólista segítségével, Lawrence L. Larmore professzor
- A szélesség első keresési algoritmusa, Khan Akadémia
- Adatstruktúra – Szélesség első bejárása, oktatóanyagokPoint
- Bináris fa: Szintű sorrend bejárása, mycodeschool
- Egy fa szélességének első átjárása, Számítástechnika Tanszék Boston University
