Pokud jde o učení, lze obecně zvolit dva přístupy: jeden může jít široký a zkuste pokrýt co nejvíce spektra pole, nebo můžete jít do hloubky a pokusit se získat opravdu, opravdu konkrétní téma, které se učíte. Většina dobrých studentů ví, že do určité míry vše, co se v životě naučíte – od algoritmů po základní životní dovednosti – zahrnuje určitou kombinaci těchto dvou přístupů.
Totéž platí pro počítačovou vědu, řešení problémů, a datové struktury. Minulý týden jsme se ponořili hluboko do hloubkového hledání a zjistili jsme, co to znamená procházet binárním vyhledávacím stromem. Nyní, když jsme se dostali do hloubky, má smysl, abychom šli doširoka a porozuměli další běžné strategii procházení stromů.
Jinými slovy, je to okamžik, na který jste všichni čekali: je čas prolomit základy vyhledávání na šířku!
Jedním z nejlepších způsobů, jak pochopit, co je vyhledávání na šířku (BFS), je pochopit, čím není. To znamená, že když porovnáme BFS s DFS, bude pro nás mnohem snazší držet je rovně v hlavách. Než tedy půjdeme dále, obnovme si naši paměť hledání hloubky první.
Víme, že hledání hloubky je proces procházení dolů jednou větví stromu, dokud se nedostaneme k listu, a pak se vracet zpět do „kmene“ stromu. Jinými slovy, implementace DFS znamená procházení dolů podstromem binárního vyhledávacího stromu.
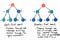
Dobře, tak jak to funguje hledat v porovnání s tím? No, když o tom přemýšlíme, jedinou skutečnou alternativou k cestování dolů po jedné větvi stromu a pak po druhé je cestovat dolů po stromové sekci po sekci – nebo po jednotlivých úrovních. A to je přesně to, co BFS je !
Hledání na šířku zahrnuje prohledávání stromu po jedné úrovni.
My nejprve projděte celou jednu úroveň podřízených uzlů a poté přejděte k uzlům vnoučat. A než projdeme uzly pravnuků, projdeme celou úroveň uzlů vnoučat.
Dobře, zdá se to docela jasné. Co ještě odlišuje dva různé typy algoritmů pro procházení stromem? Rozdíly v postupech těchto dvou algoritmů jsme již pokryli. Pojďme se zamyslet nad dalším důležitým aspektem, o kterém jsme ještě nemluvili: implementací.
Nejprve začněme s tím, co víme. Jak jsme minulý týden postupovali při implementaci vyhledávání do hloubky? Možná si vzpomenete, že jsme se naučili tři různé metody – procházení, postorder a předobjednávka – prohledávání stromu pomocí DFS. Přesto bylo něco super v tom, jak podobné jsou tyto tři implementace; každý mohl být zaměstnán pomocí rekurze. Víme také, že protože DFS lze zapsat jako rekurzivní funkci, mohou způsobit, že zásobník volání naroste na tak velkou délku jako nejdelší cesta ve stromu.
Zůstala však jedna věc z minulého týdne, který se nyní zdá být dobrý (a možná je to i trochu zřejmé!): zásobník volání ve skutečnosti implementuje datovou strukturu zásobníku. Pamatuješ si ty? O zásobnících jsme se dozvěděli před dávnou dobou, ale tady jsou opět a objevují se všude!
Skutečně zajímavá věc při implementaci vyhledávání do hloubky pomocí zásobníku je to, že když procházíme podstromy binární vyhledávací strom, každý z uzlů, které „kontrolujeme“ nebo „navštěvujeme“, se přidá do zásobníku. Jakmile se dostaneme k uzlu listu – uzlu, který nemá žádné děti – začneme vyskočit z uzlů z horní části zásobníku. Skončíme znovu v kořenovém uzlu a pak můžeme pokračovat v procházení dolů dalším podstromem.

V příkladu výše uvedeného stromu DFS si všimnete, že všechny uzly 2, 3 a 4 budou přidány do horní část stohu. Když se dostaneme na „konec“ tohoto podstromu – to znamená, když dosáhneme listových uzlů 3 a 4 – začneme tyto uzly vysouvat ze svého „uzlu k návštěvě“.Můžete vidět, co se nakonec stane se správným podstromem: uzly, které se mají navštívit, se posunou do zásobníku volání, my je navštívíme a systematicky je vysuneme ze zásobníku.
Nakonec, jakmile Navštívili jsme levý i pravý podstrom, vrátíme se do kořenového uzlu a nebudeme muset nic kontrolovat a náš zásobník volání bude prázdný.
Takže bychom měli být schopni použít strukturu zásobníku a udělat něco podobného s naší implementací BFS … že? No, nevím, jestli to bude fungovat, ale myslím si, že bude užitečné alespoň začít tím, že nakreslíme algoritmus, který chceme implementovat, a uvidíme, jak daleko se s ním dostaneme.
Zkusme to:

Dobře, takže vlevo máme graf, který jsme minulý týden implementovali DFS. Jak bychom místo toho mohli použít algoritmus BFS?
Pro začátek víme, že nejprve chceme zkontrolovat kořenový uzel. To je jediný uzel, ke kterému budeme mít zpočátku přístup, a tak budeme „ukazovat“ na uzel f.
Dobře, nyní budeme muset zkontrolovat podřízené položky tohoto kořenového uzlu.
Chceme kontrolovat jedno dítě za druhým, pojďme tedy nejprve k levému dítěti – uzel d je uzel, na který nyní „ukazujeme“ (a jediný uzel, ke kterému máme přístup).
Dále budeme chtít přejít do správného podřízeného uzlu.
Uh oh. Počkejte, kořenový uzel už pro nás ani není k dispozici! A nemůžeme se pohybovat opačně, protože binární stromy nemají zpětné odkazy! Jak se dostaneme do správného podřízeného uzlu? A … ach ne, levý podřízený uzel da pravý podřízený uzel k nejsou vůbec propojeny. To znamená, že pro nás není možné skákat z jednoho dítěte na druhé, protože kromě dětí uzlu d nemáme přístup k ničemu.
Ach, drahoušku. Nedostali jsme se moc daleko, že? Budeme muset přijít na jinou metodu řešení tohoto problému. Musíme vymyslet nějaký způsob implementace procházení stromu, který nám umožní procházet se stromem v pořadí na úrovni. Nejdůležitější věcí, kterou musíme mít na paměti, je toto:
Musíme si ponechat odkaz na všechny podřízené uzly každého uzlu, který navštěvujeme. Jinak se k nim nebudeme moci později vrátit a navštívit je!
Čím víc o tom přemýšlím, tím víc mám chuť je to, jako bychom chtěli vést seznam všech uzlů, které ještě musíme zkontrolovat, že? A v okamžiku, kdy si chci něco uložit, moje mysl okamžitě skočí zejména na jednu datovou strukturu: frontu, samozřejmě!
Uvidíme, jestli nám fronty mohou pomoci s naší implementací BFS.
Fronty na záchranu!
Jak se ukázalo, zásadním rozdílem v hloubkovém a širokém vyhledávání je datová struktura používaná k implementaci obou těchto velmi odlišných algoritmů.
Zatímco DFS používá datovou strukturu zásobníku, BFS se opírá o datovou strukturu fronty. Pěkné na používání front je, že řeší samotný problém, který jsme objevili dříve: umožňuje nám uchovat odkaz na uzly, ke kterým se chceme vrátit, i když jsme je ještě nekontrolovali / nenavštívili.
Do fronty přidáváme uzly, které jsme objevili – ale ještě jsme nenavštívili – a vrátíme se k nim později.
Běžným termínem pro uzly, které přidáme do naší fronty, jsou objevené uzly; objevený uzel je ten, který přidáme do naší fronty, jejíž polohu víme, ale musíme ji ještě skutečně navštívit. Ve skutečnosti to je přesně to, co dělá z fronty perfektní strukturu pro řešení problému BFS.

V grafu vlevo začneme přidáním kořenového uzlu do naší fronty, protože je to jediný uzel, jaký jsme kdy použili mít přístup (alespoň zpočátku) do stromu. To znamená, že kořenový uzel je jediným objeveným uzlem, který má být spuštěn.
Jakmile máme alespoň jeden uzel zařazen do fronty, můžeme zahájit proces návštěvy uzlů a přidání odkazů na jejich podřízené uzly do naší fronty.
Dobře, takže to všechno může znít trochu matoucí. A to je v pořádku! Myslím, že bude mnohem snazší to pochopit, pokud to rozdělíme na jednodušší kroky.
Pro každý uzel v naší frontě – vždy počínaje kořenovým uzlem – budeme chtít udělat tři věci:
- Navštivte uzel, což obvykle znamená jen vytisknout jeho hodnotu.
- Přidejte do podřízené fronty levé dítě uzlu.
- Přidejte pravé uzel dítě do naší fronty.
Jakmile provedeme tyto tři věci, můžeme uzel z naší fronty odebrat, protože ho už nepotřebujeme!V podstatě to musíme dělat opakovaně, dokud se nedostaneme do bodu, kdy je naše fronta prázdná.
Dobře, podívejme se na to v akci!
V níže uvedeném grafu začneme s kořenovým uzlem, uzlem f, jako jediným objeveným uzlem. Pamatujete si naše tři kroky? Pojďme je udělat hned:
- Navštívíme uzel f a vytiskneme jeho hodnotu.
- Zařadíme odkaz na jeho levé dítě, uzel d.
- Zařadíme odkaz na jeho pravé dítě, uzel k.
A poté odstraníme uzel f z naší fronty!

Dalším uzlem v přední části fronty je uzel d. Opět platí tři stejné kroky: vytisknout jeho hodnotu, přidat jeho levé dítě, přidat jeho pravé dítě a poté jej odebrat z fronty.
Naše fronta má nyní odkazy na uzly k, b a e . Pokud budeme tento proces soustavně opakovat, všimneme si, že ve skutečnosti procházíme grafem a tiskneme uzly v pořadí podle úrovně. Hurá! To je přesně to, co jsme chtěli udělat na prvním místě.
Klíčem k tak dobrému fungování je samotná povaha struktury fronty. Fronty se řídí zásadou FIFO (first-in, first-out), což znamená, že cokoli, co bylo zařazeno do fronty jako první, je první položka, která bude načtena a odstraněna z fronty.
A konečně, když se věnujeme frontám, stojí za zmínku, že časoprostorová složitost algoritmu BFS souvisí také s frontou, kterou používáme k jeho implementaci – kdo věděl, že se fronty vrátí být tak užitečný, že?
Časová složitost algoritmu BFS závisí přímo na tom, kolik času trvá návštěva uzlu. Vzhledem k tomu, že čas potřebný k načtení hodnoty uzlu a zařazení jeho podřízených položek se na základě uzlu nemění, můžeme říci, že návštěva uzlu trvá konstantní čas neboli O (1). Jelikož každý uzel v průchodu stromu BFS navštěvujeme pouze jednou, čas, který nám bude trvat, než přečteme každý uzel, opravdu záleží jen na tom, kolik uzlů ve stromu je! Pokud má náš strom 15 uzlů, bude nám trvat O (15); ale pokud má náš strom 1500 uzlů, bude nám trvat O (1500). Časová složitost vyhledávacího algoritmu na první šířku tedy trvá lineární čas, nebo O (n), kde n je počet uzlů ve stromu.
Složitost prostoru je podobná tomuto, má více dělat s tím, jak moc naše fronta roste a zmenšuje se, když do ní přidáváme uzly, které musíme zkontrolovat. V nejhorším případě bychom potenciálně mohli zařadit do fronty všechny uzly ve stromu, pokud jsou všechny navzájem podřízené, což znamená, že bychom možná mohli využívat tolik paměti, kolik uzlů ve stromu je. Pokud může velikost fronty narůst na počet uzlů ve stromu, je složitost prostoru pro algoritmus BFS také lineární čas, nebo O (n), kde n je počet uzlů ve stromu.
To je všechno dobré a dobré, ale víte, co bych teď opravdu chtěl udělat? Rád bych napsal jeden z těchto algoritmů! Pojďme konečně uplatnit celou tuto teorii v praxi.
Kódování našeho prvního široce používaného vyhledávacího algoritmu
Zvládli jsme to! Konečně se chystáme kódovat náš úplně první algoritmus BFS. Trochu jsme toho udělali minulý týden s algoritmy DFS, takže se pokusme napsat také implementaci vyhledávání na šířku.
Možná si pamatujete, že jsme to minulý týden napsali ve vanilkovém JavaScriptu, takže toho se budeme držet znovu kvůli konzistenci. V případě, že potřebujete rychlou aktualizaci, rozhodli jsme se, že to zjednodušíme a zapíšeme naše uzlové objekty jako Plain Old JavaScript Objects (POJO), například takto:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
Dobře, v pohodě. Jeden krok hotový.
Ale teď, když víme o frontách a jsme si jistí, že k implementaci tohoto algoritmu budeme muset použít jeden … měli bychom pravděpodobně přijít na to, jak to udělat v JavaScriptu, že? Jak se ukázalo, je opravdu snadné vytvořit objekt podobný frontě v JS!
Můžeme použít pole, které dělá tento trik docela pěkně:
Pokud bychom z toho chtěli udělat trochu lepšího, mohli bychom také pravděpodobně vytvořit objekt Queue, který může mít užitečnou funkci jako top nebo isEmpty; ale zatím se budeme spoléhat na velmi jednoduchou funkčnost.
Dobře, pojďme napsat toto štěně! Vytvoříme funkci levelOrderSearch, která převezme objekt rootNode.
Skvělé! To je ve skutečnosti … celkem jednoduché. Nebo alespoň mnohem jednodušší, než jsem čekal. Vše, co zde děláme, je použití smyčky while k pokračování těchto tří kroků kontroly uzlu, přidání jeho levého potomka a přidání jeho pravého potomka.Pokračujeme v iteraci prostřednictvím queue pole, dokud z něj nebude odstraněno vše a jeho délka je 0.
Úžasný. Naše odborné znalosti v oblasti algoritmů vzrostly za pouhý den! Nejen, že víme, jak psát algoritmy pro procházení rekurzivním stromem, ale nyní také víme, jak psát iterativní. Kdo věděl, že algoritmické vyhledávání může být tak posilující!
Zdroje
O vyhledávání na šířku je stále ještě co učit a kdy může být užitečné. Naštěstí existuje spousta zdrojů, které pokrývají informace, které jsem do tohoto příspěvku nemohl vejít. Níže se podívejte na několik opravdu dobrých.
- Algoritmy DFS a BFS pomocí Stacks and Queues, profesor Lawrence L. Larmore
- Algoritmus vyhledávání prvního šíře, Khan Akademie
- Struktura dat – první šíře, TutorialsPoint
- Binární strom: Traversal Order Order, mycodeschool
- první šíře stromu, oddělení informatiky Bostonská univerzita
