A mesterséges intelligencia monumentális növekedésnek volt tanúja az emberek és a gépek képességei közötti szakadék áthidalásának. Kutatók és rajongók egyaránt a terület számos aspektusán dolgoznak, hogy elképesztő dolgok történjenek. A sok ilyen terület egyike a Computer Vision területe.
Ennek a területnek az a célja, hogy lehetővé tegye a gépek számára, hogy az embereket úgy nézzék meg, ahogyan az emberek, hasonló módon érzékeljék a világot, és akár sok ember számára is felhasználják az ismereteket. olyan feladatok közül, mint az Image & Videófelismerés, Képelemzés & Osztályozás, Média rekreáció, Ajánlási rendszerek, Természetes nyelv feldolgozása stb. A számítógépes látás mély tanulással című dokumentumot az idő előrehaladtával fejlesztették és tökéletesítették, elsősorban egy adott algoritmuson – egy konvolúciós neurális hálózaton keresztül.
Bevezetés

A konvolúciós neurális hálózat (ConvNet / CNN) egy mély tanulás algoritmus, amely bemeneti képet készíthet, fontosságot tulajdoníthat (tanulható e súlyok és torzítások) a kép különböző aspektusaihoz / tárgyaihoz, és képesek legyenek megkülönböztetni egymástól. A ConvNet-ben előírt feldolgozás sokkal alacsonyabb, mint más osztályozási algoritmusoké. Míg a primitív módszerekben a szűrőket kézzel készítik, kellő képzettséggel, a ConvNets képes megismerni ezeket a szűrőket / jellemzőket.
A ConvNet architektúrája analóg az emberi neuronok kapcsolódási mintázatával. Agy és a Visual Cortex szervezete ihlette. Az egyes idegsejtek csak a látómező korlátozott régiójában reagálnak az úgynevezett Receptív mezőre. Az ilyen mezők gyűjteménye átfedésben van, hogy lefedje a teljes vizuális területet.
Miért érdemes a ConvNeteket átadni az előre továbbított neurális hálózatokra?

A kép nem más, mint pixelértékek mátrixa, igaz? Tehát miért nem simítja csak el a képet (pl. 3×3 képmátrix egy 9×1 vektorba), és osztályozás céljából táplálja azt egy Többszintű Perceptronba? Uh .. nem igazán.
Rendkívül egyszerű bináris képek esetén a módszer átlagos pontosságot mutathat az osztályok előrejelzése közben, de alig vagy egyáltalán nem pontos, ha komplex képpontfüggőségű képekről van szó.
A ConvNet a releváns szűrők alkalmazásával képes a térbeli és időbeli függőségek sikeres rögzítésére egy képben. Az architektúra jobban illeszkedik a képadatkészletbe az érintett paraméterek számának csökkenése és a súlyok újrafelhasználhatósága miatt. Más szavakkal, a hálózat kiképezhető, hogy jobban megértse a kép kifinomultságát.
Bemeneti kép

Az ábrán egy RGB kép található, amelyet három színsík választott el egymástól: piros, zöld, és Kék. Számos ilyen színtér létezik, amelyekben képek léteznek – Szürkeárnyalatos, RGB, HSV, CMYK stb.
El tudja képzelni, hogy a számításigényes dolgok mit hoznának, ha a képek elérnék a dimenziókat, mondjuk 8K (7680 × 4320). A ConvNet feladata, hogy a képeket könnyebben feldolgozható formává alakítsa anélkül, hogy elveszítené azokat a funkciókat, amelyek kritikusak a jó előrejelzéshez. Ez akkor fontos, ha olyan architektúrát tervezünk, amely nem csak a tanulási funkciók szempontjából jó, de masszív adathalmazokra is méretezhető.
Convolution Layer – A kern
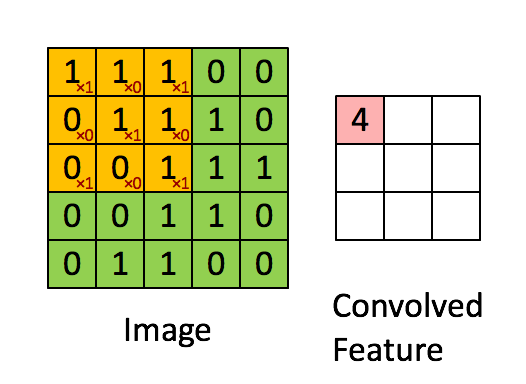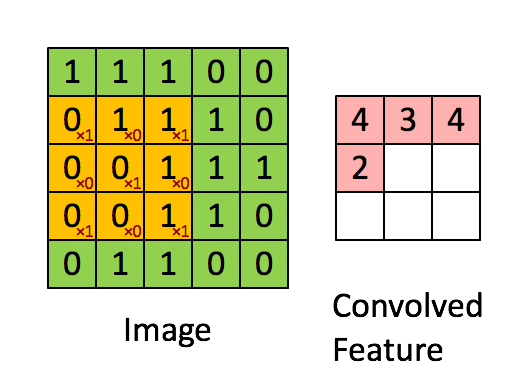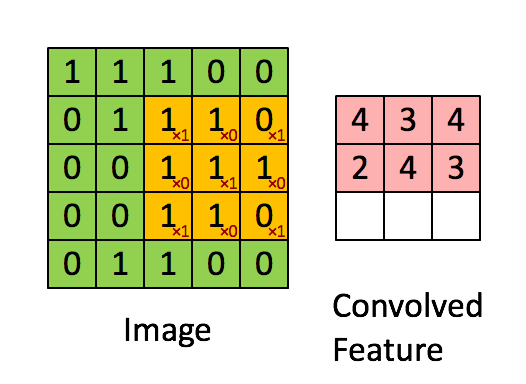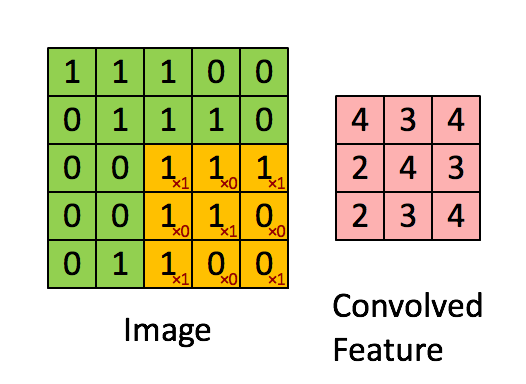
Kép Méretek = 5 (magasság) x 5 (szélesség) x 1 (csatornák száma, pl. RGB)
A fenti bemutatásban a zöld szakasz hasonlít az 5x5x1 bemeneti képünkre, I. A konvolúciós réteg első részében található konvolúciós műveletet a sárga színnel jelölt K-magnak / szűrőnek nevezzük. K-t választottunk 3x3x1 mátrixnak.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
A kernel 9-szer elmozdul, mert a lépéshossz = 1 (nem lépcsőzetes), minden alkalommal, amikor mátrixot hajt végre szorzási művelet K és a kép P része között, amely felett a kernel lebeg.

A szűrő jobbra mozog egy bizonyos lépésértékkel, amíg a teljes szélességet értelmezi. Továbbhaladva a kép elejére (balra) ugrik ugyanazzal a lépésértékkel, és addig ismételgeti a folyamatot, amíg a teljes kép be nem megy.
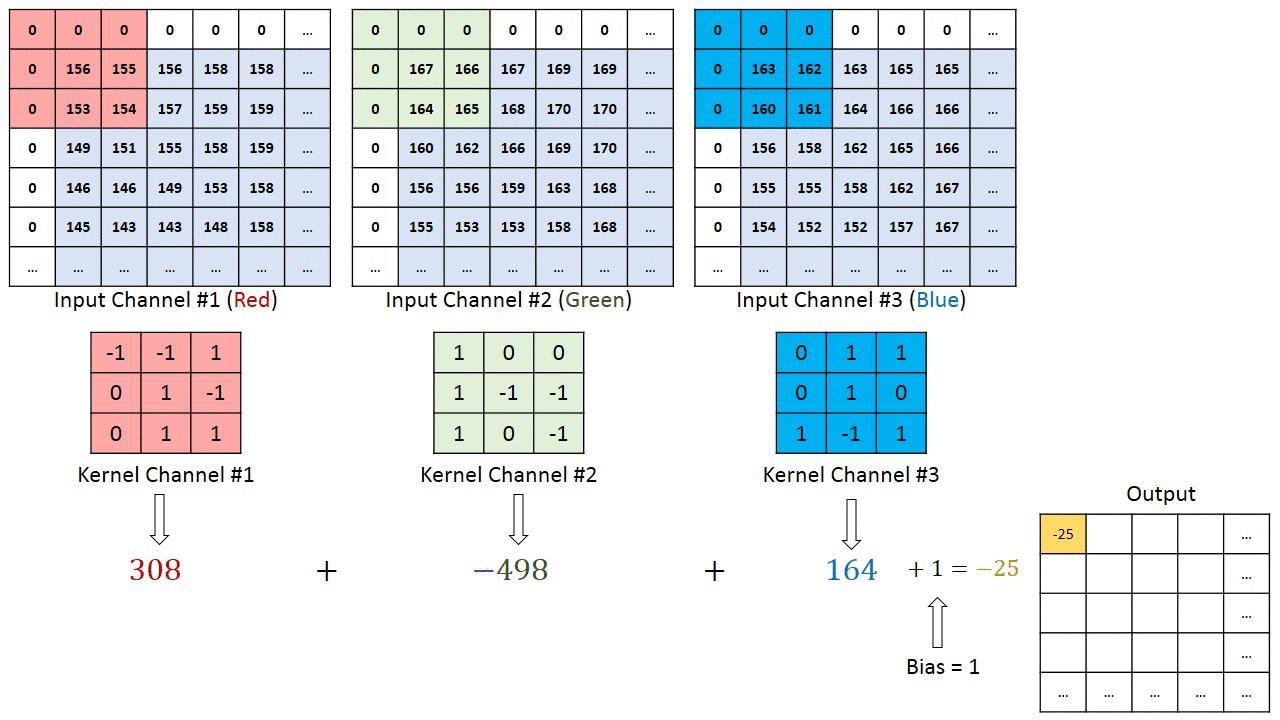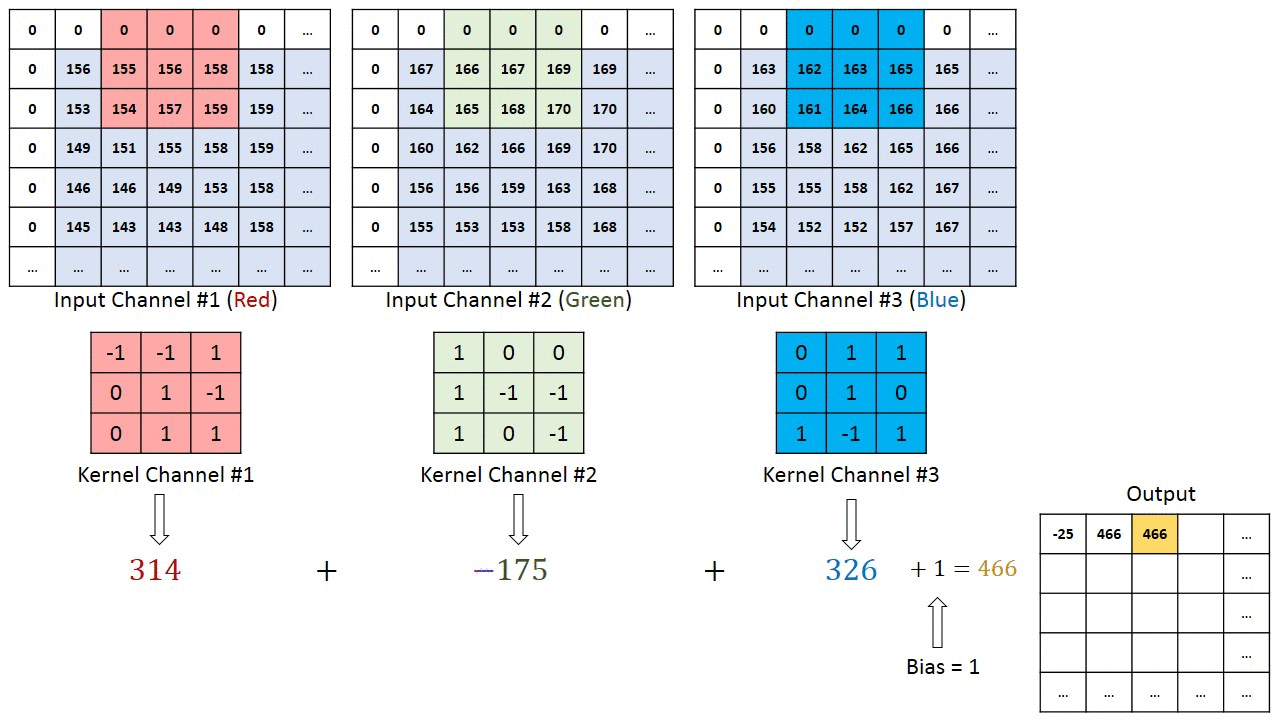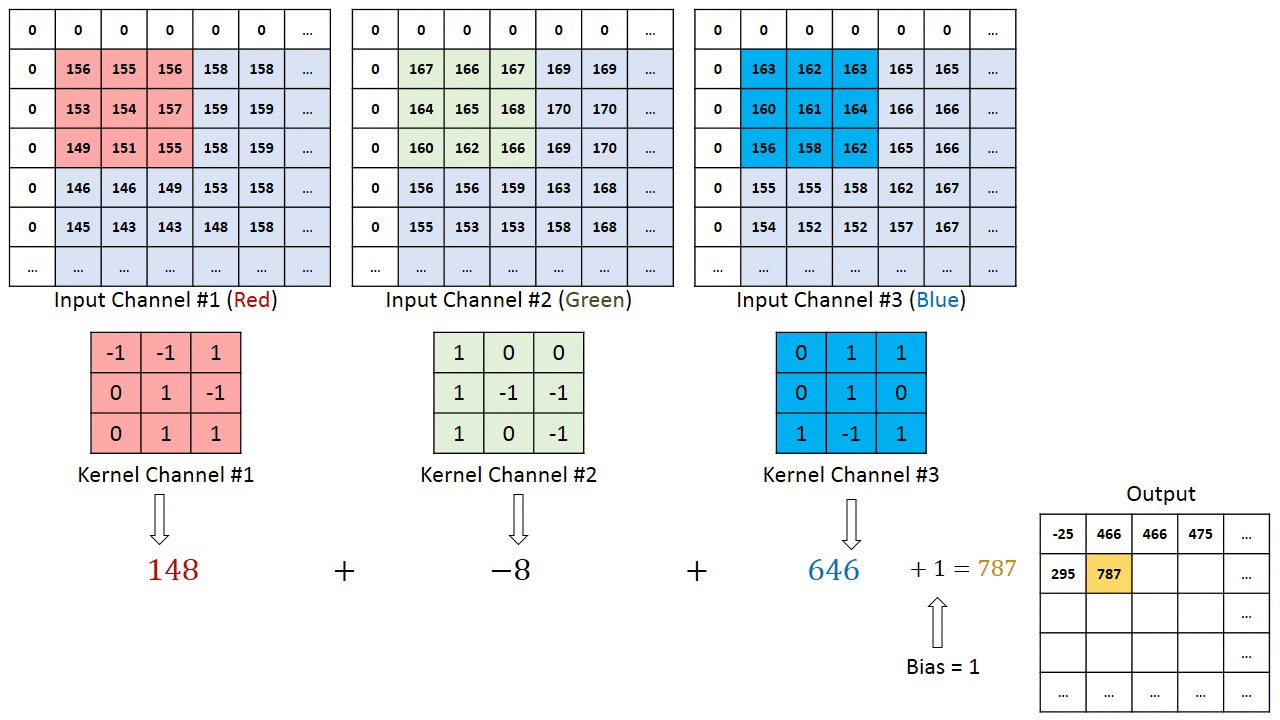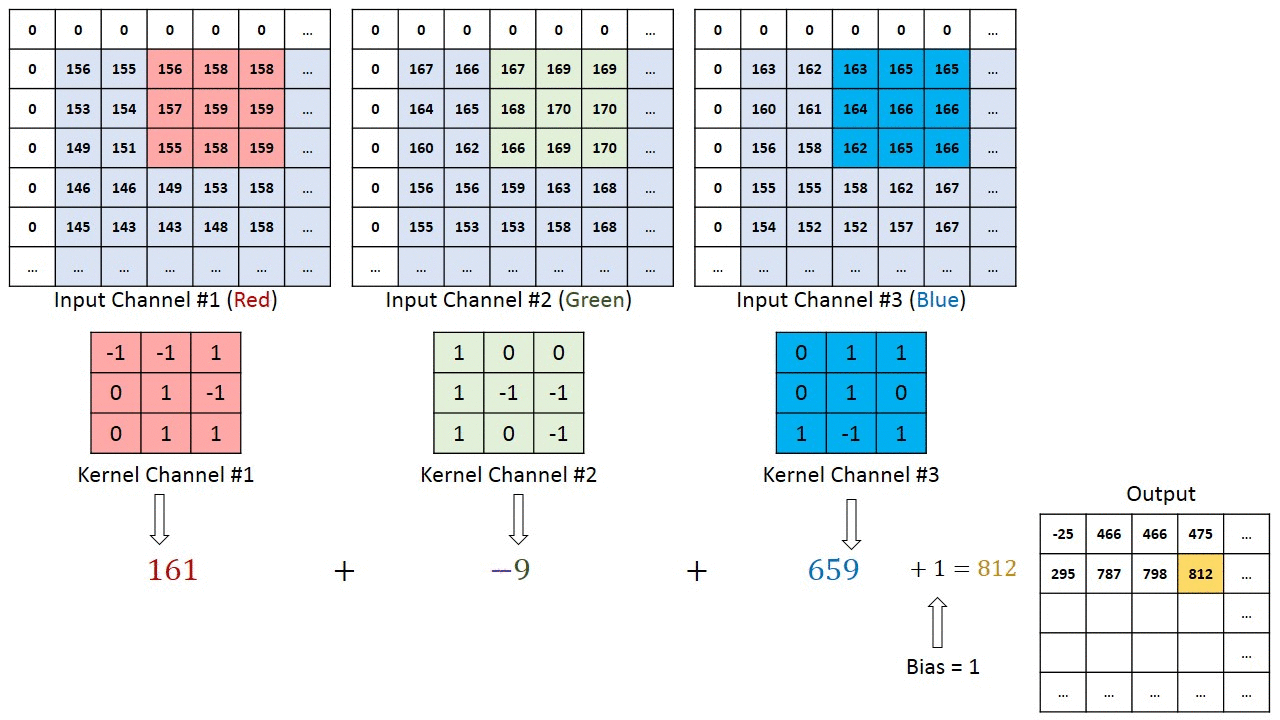
Többcsatornás képek (pl. RGB) esetén ), a kernel mélysége megegyezik a bemeneti kép mélységével. A mátrix szorzást a Kn és az In stack (;;) között hajtjuk végre, és az összes eredményt az előfeszítéssel összegezzük, hogy egy összemosott egy mélységű csatorna konvolúció kimenetet kapjunk.
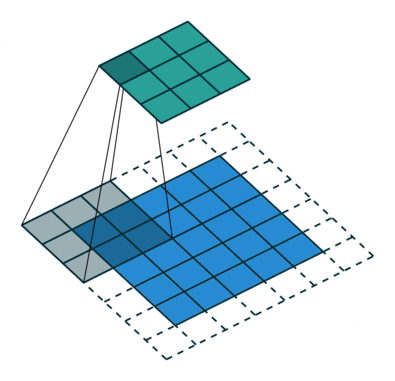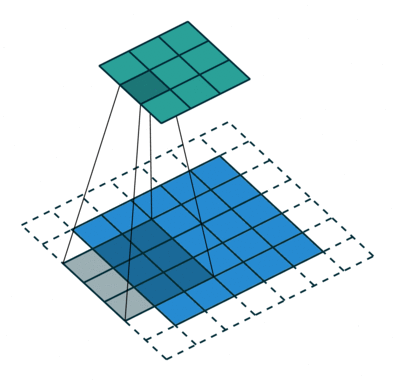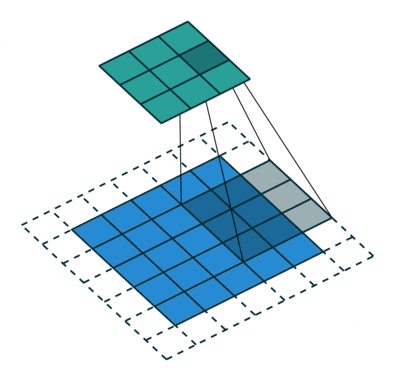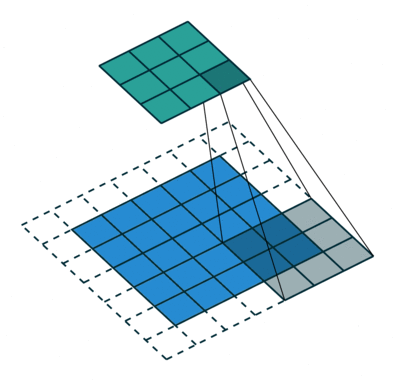
A Convolution művelet célja a magas szintű szolgáltatások, például az élek kibontása, a bemeneti képből. A ConvNetsnek nem kell csak egy konvolúciós rétegre korlátozódnia. Hagyományosan az első ConvLayer felelős az Alacsony szintű jellemzők, például élek, szín, színátmenet orientáció stb. Rögzítéséért. A hozzáadott rétegekkel az architektúra alkalmazkodik a Magas szintű jellemzőkhöz is, ezáltal olyan hálózatot kapunk, amely teljes körű megértéssel rendelkezik képek az adatkészletben, hasonlóan ahhoz, ahogyan tennénk.
A műveletnek kétféle eredménye van – az egyikben az összevont tulajdonság mérete csökken a bemenethez képest, a másik pedig a dimenzionalitás vagy megnövekszik, vagy ugyanaz marad. Ezt úgy végezzük, hogy az előbbi esetén az Érvényes kitöltést, az utóbbi esetében az Ugyanazon kitöltést alkalmazzuk.
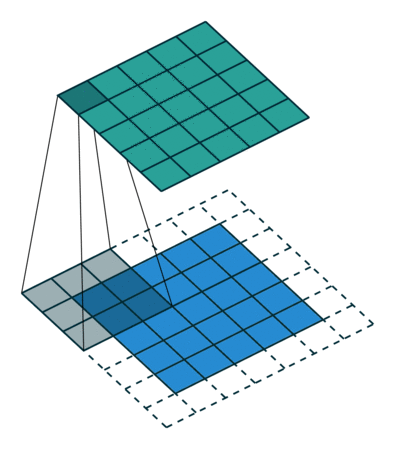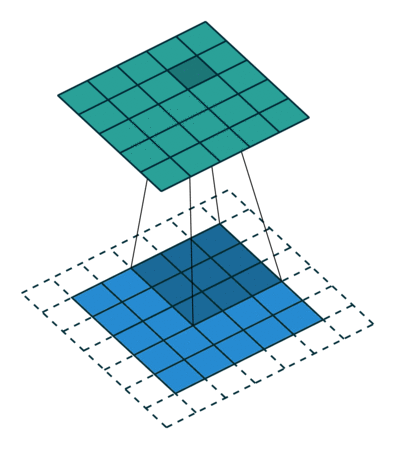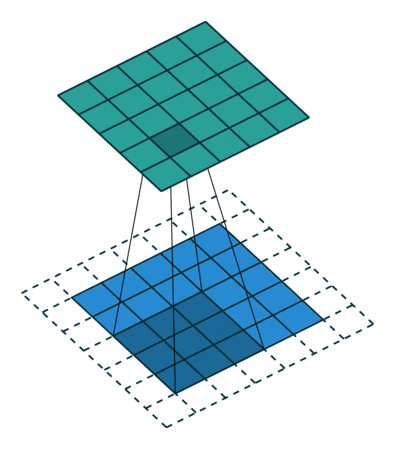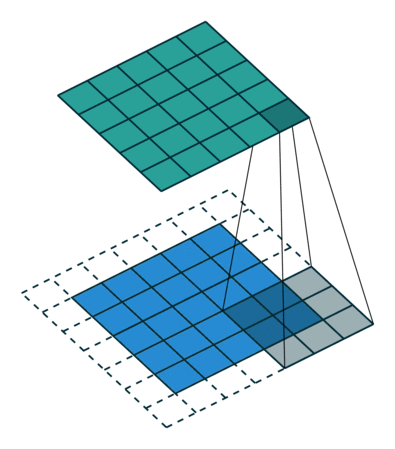
Amikor az 5x5x1 képet 6x6x1 képpé bővítjük, majd a 3x3x1 kernelt alkalmazzuk rajta, akkor az összevont mátrix 5x5x1 méretűnek bizonyul. Innen ered a neve – Ugyanaz a kitöltés.
Ha viszont ugyanazt a műveletet hajtjuk végre párnázás nélkül, akkor egy olyan mátrixot kapunk, amely magának a magnak (3x3x1) – Valid Padding. p>
A következő adattárban sok ilyen GIF található, amelyek segítenek jobban megérteni, hogyan működnek együtt a Padding és a Stride Length az igényeinknek megfelelő eredmények elérése érdekében.
Pooling Layer
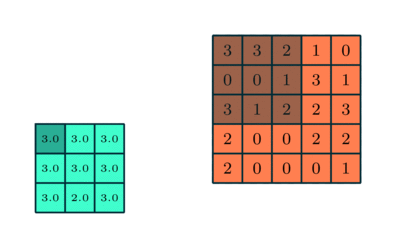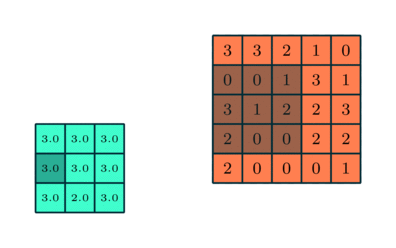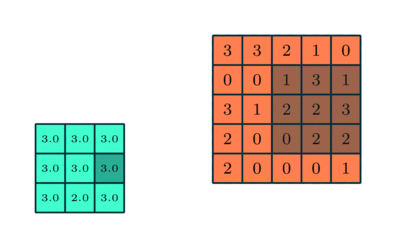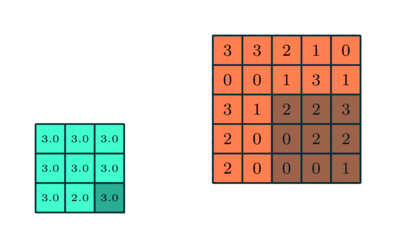
Hasonló a Konvolúciós réteghez, a Pooling réteg felelős a Konvolált funkció térméretének csökkentéséért. Ennek célja az adatok feldolgozásához szükséges számítási teljesítmény csökkentése a dimenziócsökkentés révén. Ezenkívül hasznos domináns jellemzők kinyerésére, amelyek rotációs és pozícióvariánsak, így fenntartva a modell hatékony képzésének folyamatát.
A poolingnak két típusa van: Max pooling és átlagos pooling. A Max Pooling a kernel által lefedett képrészből adja vissza a maximális értéket. Másrészt az Átlagos pooling visszaadja az összes érték átlagát a kép azon részéből, amelyet a kernel borít.
A Max Pooling zajcsökkentőként is működik. Teljesen elveti a zajos aktiválásokat, és a zajcsökkentést, valamint a dimenziócsökkentést is végrehajtja. Másrészt az átlagos pooling egyszerűen zajcsökkentő mechanizmusként hajtja végre a dimenziócsökkentést. Ezért azt mondhatjuk, hogy a Max Pooling sokkal jobban teljesít, mint az átlagos pooling.
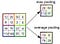
A konvolúciós réteg és a pooling réteg együttesen alkotják a konvolúciós ideghálózat i-edik rétegét. A képek bonyolultságától függően az ilyen rétegek száma növelhető, hogy még alacsonyabb szintű részleteket rögzítsen, de nagyobb számítási erővel.
A fenti folyamat végigvitelét követően sikeresen lehetővé tette a modell számára a funkciók megértését. Továbbhaladva a végső kimenetet egyengetjük és besorolás céljából egy szabályos ideghálózatba tápláljuk.
Besorolás – Teljesen összekapcsolt réteg (FC réteg)

Teljesen összekapcsolt réteg hozzáadása (általában) olcsó módszer a magas szintű jellemzők nemlineáris kombinációinak megtanulására, amelyet a konvolúciós réteg kimenete képvisel. A Teljesen összekapcsolt réteg egy lehetséges nemlineáris függvényt tanul meg ebben a térben.
Most, hogy a bemeneti képünket többszintű Perceptronunk számára megfelelő formává alakítottuk, a képet egy oszlop vektor. A lapított kimenetet egy előre irányított ideghálózatba táplálják, és a tréning minden iterációjára alkalmazzák a szaporítást. Korszakok során a modell képes megkülönböztetni az uralkodó és bizonyos alacsony szintű jellemzőket a képek között, és a Softmax osztályozási technikával osztályozni őket.
A CNN-ek különböző architektúrái állnak rendelkezésre, amelyek kulcsfontosságúak voltak olyan algoritmusok készítése, amelyek belátható időn belül az AI egészét táplálják és működtetik. Néhányat az alábbiakban sorolunk fel:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
