人工知能は、人間と機械の能力の間のギャップを埋めるという途方もない成長を目の当たりにしてきました。研究者と愛好家は同様に、驚くべきことを実現するためにこの分野のさまざまな側面に取り組んでいます。そのような多くの分野の1つは、コンピュータビジョンの領域です。
この分野の課題は、機械が人間と同じように世界を見て、同様の方法で世界を認識し、知識を多数の人に使用できるようにすることです。画像&ビデオ認識、画像分析&分類、メディアレクリエーション、レコメンデーションシステム、自然言語処理などのタスクのin Computer Vision with Deep Learningは、主に1つの特定のアルゴリズムである畳み込みニューラルネットワークを介して構築され、時間とともに完成されてきました。
はじめに

Convolutional Neural Network(ConvNet / CNN)は深い学習です入力画像を取り込んで重要度を割り当てることができるアルゴリズム(learnabl e重みとバイアス)を画像内のさまざまな側面/オブジェクトに適用し、一方を他方から区別できるようにします。 ConvNetで必要な前処理は、他の分類アルゴリズムと比較してはるかに低くなっています。原始的な方法では、フィルターは手作業で設計されていますが、十分なトレーニングがあれば、ConvNetはこれらのフィルター/特性を学習できます。
ConvNetのアーキテクチャは、人間のニューロンの接続パターンのアーキテクチャに類似しています。脳と視覚野の組織に触発されました。個々のニューロンは、受容野として知られている視野の制限された領域でのみ刺激に反応します。このようなフィールドのコレクションは、視覚野全体をカバーするために重なり合っています。
フィードフォワードニューラルネットを介したConvNetの理由

画像はピクセル値のマトリックスにすぎませんよね?では、画像を平坦化して(たとえば、3×3画像マトリックスを9×1ベクトルに)、分類のために多層パーセプトロンにフィードしてみませんか?ええと、そうではありません。
非常に基本的なバイナリ画像の場合、メソッドはクラスの予測を実行しているときに平均精度スコアを表示する可能性がありますが、ピクセル依存性を持つ複雑な画像に関してはほとんどまたはまったく精度がありません。
ConvNetは、関連するフィルターを適用することで、画像内の空間的および時間的依存関係を正常にキャプチャできます。このアーキテクチャは、関連するパラメータの数が減り、重みが再利用できるため、画像データセットにより適したものになります。つまり、画像の洗練度をよりよく理解するようにネットワークをトレーニングできます。
入力画像

この図には、赤、緑、3つの色平面で区切られたRGB画像があります。とブルー。画像が存在するそのような色空間は多数あります—グレースケール、RGB、HSV、CMYKなど。
画像が8K(7680×)の寸法に達すると、計算量の多いものがどのように得られるか想像できます。 4320)。 ConvNetの役割は、適切な予測を行うために重要な機能を失うことなく、画像を処理しやすい形式に縮小することです。これは、機能の学習に優れているだけでなく、大規模なデータセットに拡張可能なアーキテクチャを設計する場合に重要です。
畳み込みレイヤー—カーネル
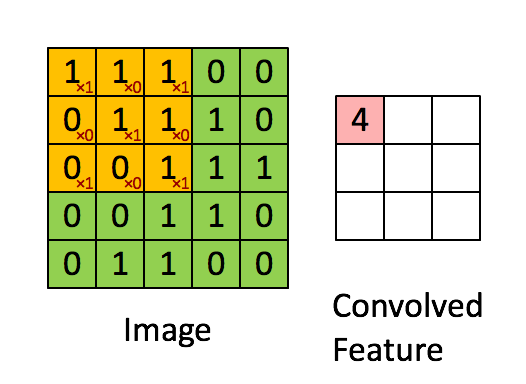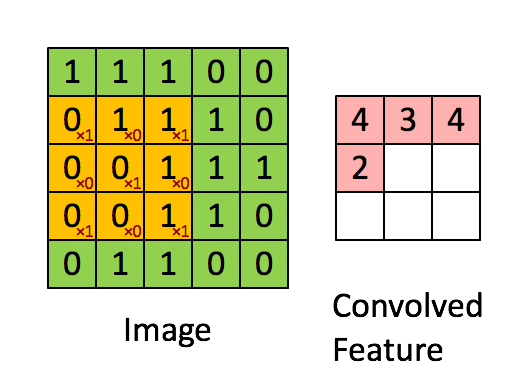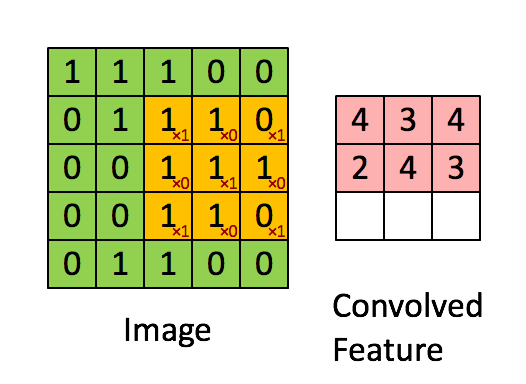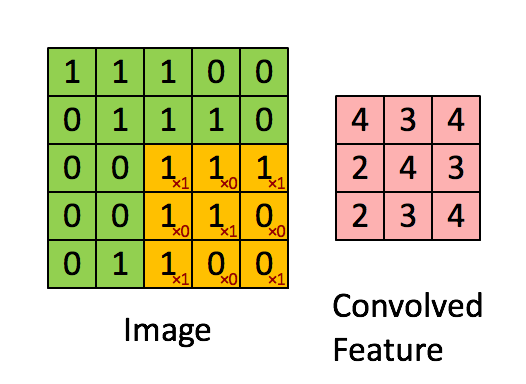
イメージ寸法= 5(高さ)x 5(幅)x 1(チャネル数、例:RGB)
上記のデモンストレーションでは、緑色のセクションは5x5x1の入力画像Iに似ています。キャリーに関係する要素畳み込み層の最初の部分での畳み込み操作は、カーネル/フィルターKと呼ばれ、黄色で表されます。 3x3x1行列としてKを選択しました。
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
ストライド長= 1(非ストライド)のため、マトリックスを実行するたびにカーネルが9回シフトします。 Kとカーネルがホバリングしている画像の部分Pとの間の乗算演算。

フィルターが右に移動します幅全体を解析するまで、特定のストライド値を使用します。次に進むと、同じストライド値を持つ画像の先頭(左)にホップダウンし、画像全体がトラバースされるまでこのプロセスを繰り返します。
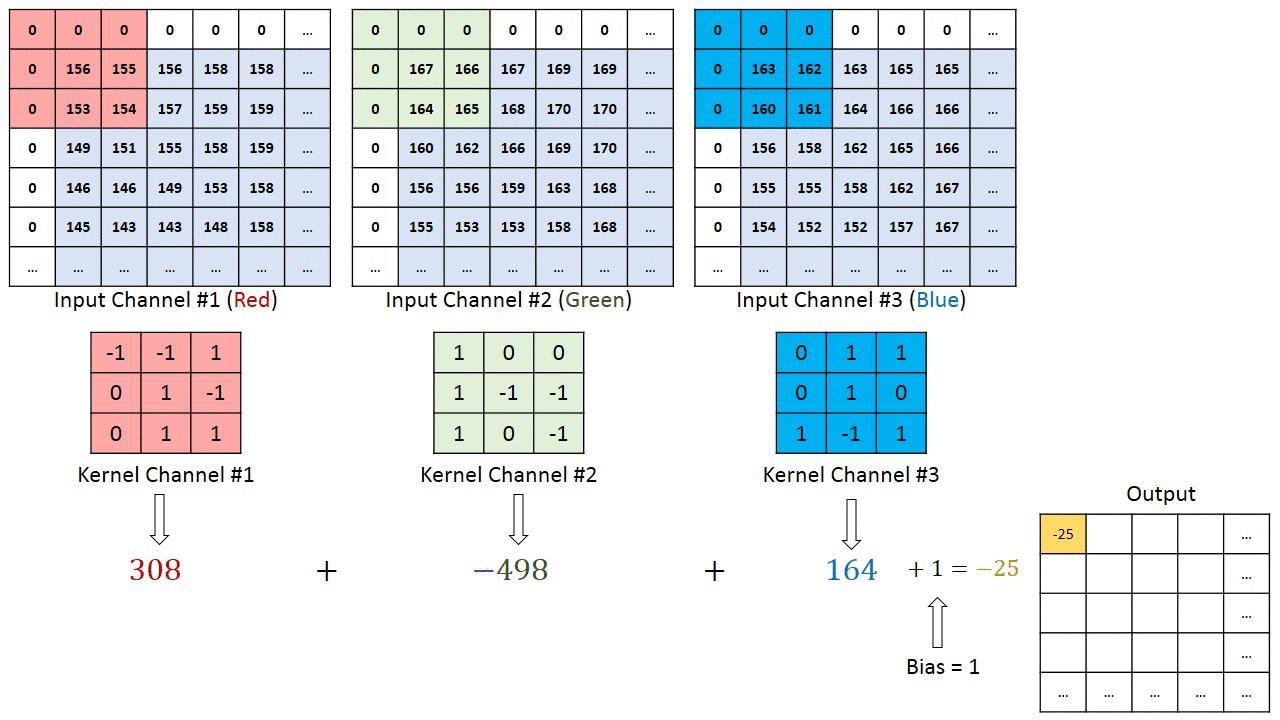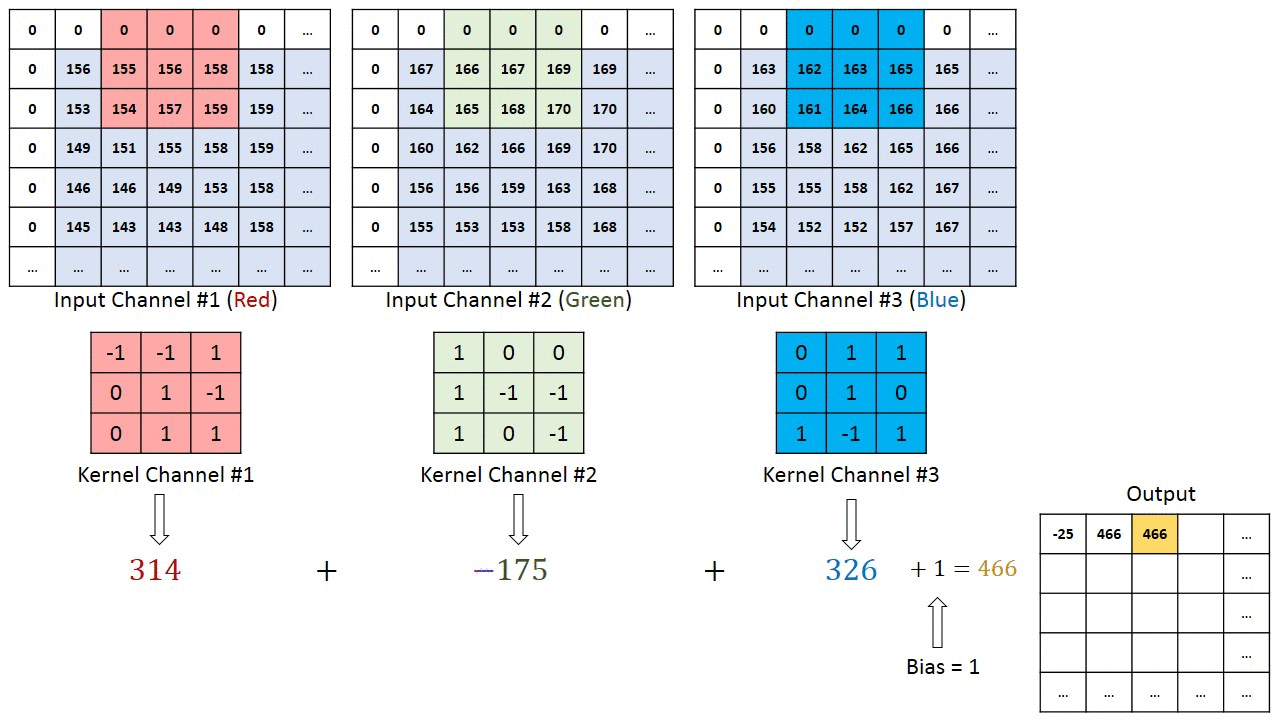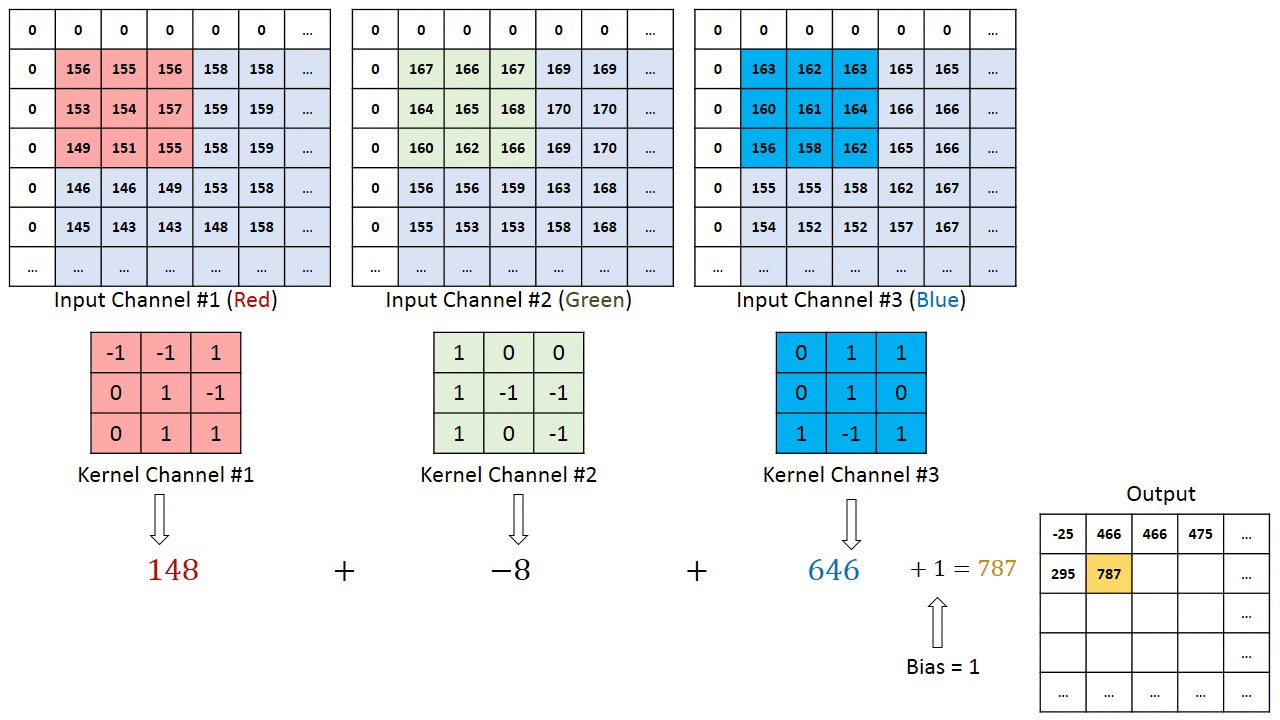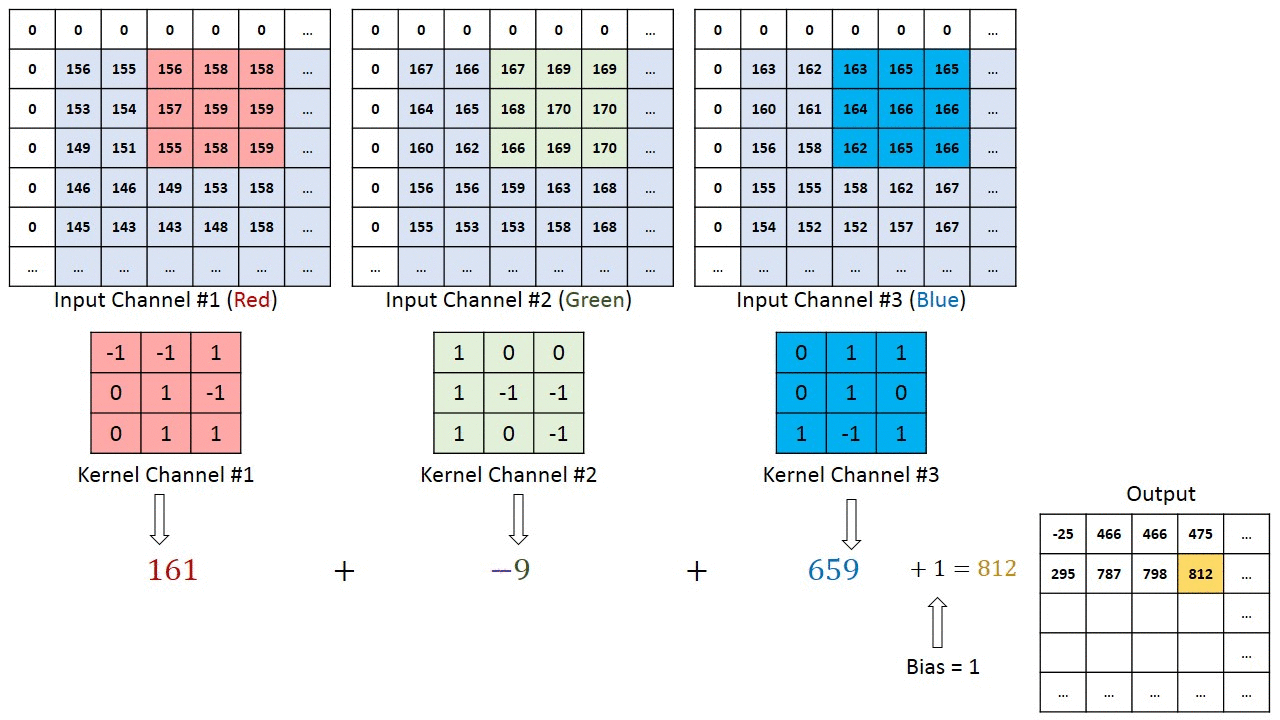
複数のチャネルを持つ画像の場合(例:RGB )、カーネルの深さは入力画像の深さと同じです。行列の乗算はKnスタックとInスタック(;;)の間で実行され、すべての結果がバイアスと合計されて、押しつぶされた1深度チャネルの畳み込み特徴出力が得られます。
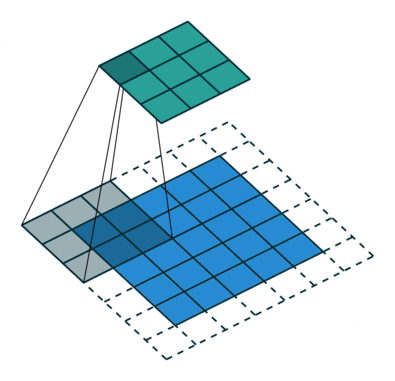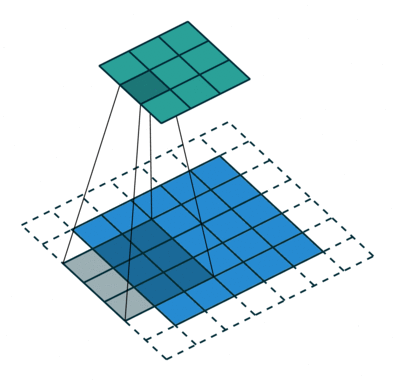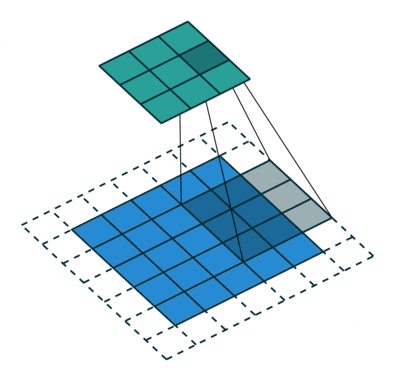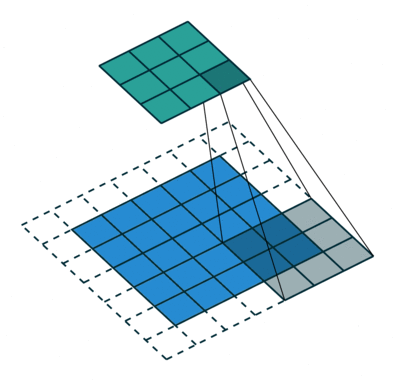
畳み込み演算の目的は、エッジなどの高レベルの特徴を抽出することです。入力画像から。 ConvNetは、1つの畳み込み層のみに限定される必要はありません。従来、最初のConvLayerは、エッジ、色、グラデーションの向きなどの低レベルの機能をキャプチャする役割を果たします。レイヤーを追加すると、アーキテクチャは高レベルの機能にも適応し、健全な理解を持つネットワークを提供します。データセット内の画像の数は、私たちと同じです。
操作の結果には2つのタイプがあります。1つは入力と比較して畳み込み特徴の次元が減少し、もう1つは入力と比較して次元が減少します。次元は増加するか、同じままです。これは、前者の場合は有効なパディングを適用し、後者の場合は同じパディングを適用することによって行われます。
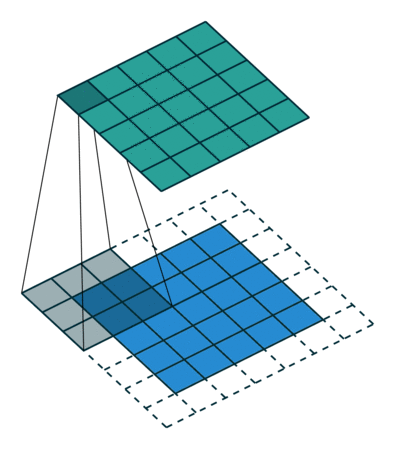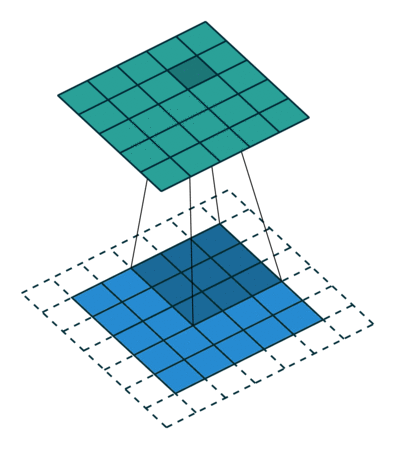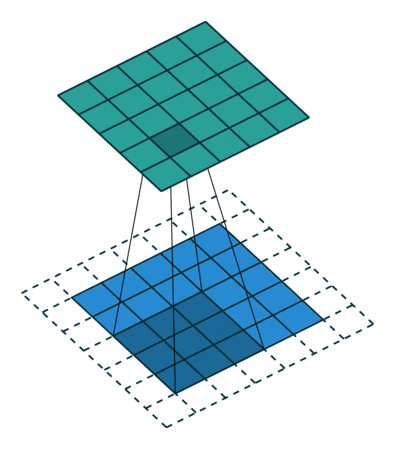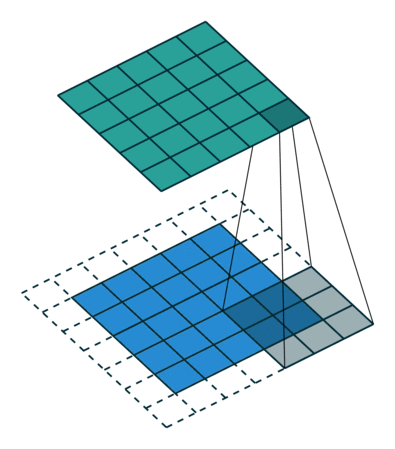
5x5x1イメージを6x6x1イメージに拡張し、その上に3x3x1カーネルを適用すると、畳み込み行列の次元は5x5x1であることがわかります。したがって、名前—同じパディング。
一方、パディングなしで同じ操作を実行すると、カーネル(3x3x1)自体の次元を持つマトリックス—有効なパディングが表示されます。
次のリポジトリには、パディングとストライド長がどのように連携してニーズに関連する結果を達成するかをよりよく理解するのに役立つ多くのGIFが格納されています。
プーリングレイヤー
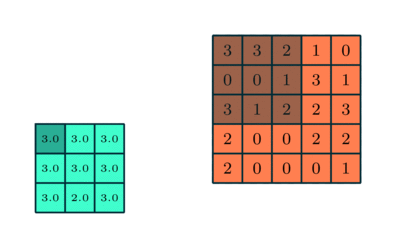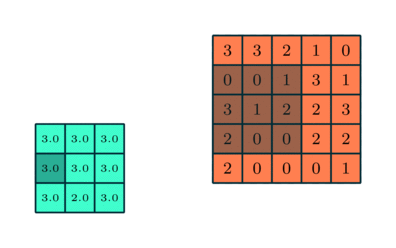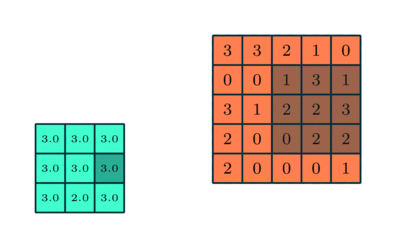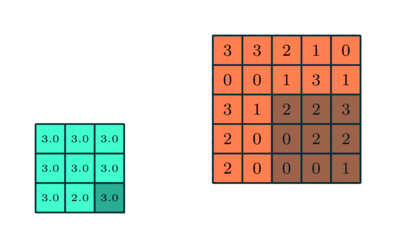
畳み込み層と同様に、プーリング層畳み込み特徴の空間サイズを縮小する責任があります。これは、次元削減を通じてデータを処理するために必要な計算能力を削減するためです。さらに、回転および位置に不変である主要な特徴を抽出するのに役立ち、モデルの効果的なトレーニングのプロセスを維持します。
プーリングには、最大プーリングと平均プーリングの2つのタイプがあります。最大プーリングは、カーネルによってカバーされるイメージの部分から最大値を返します。一方、平均プーリングは、カーネルによってカバーされる画像の部分からのすべての値の平均を返します。
最大プーリングは、ノイズ抑制剤としても機能します。ノイズの多いアクティベーションを完全に破棄し、次元削減とともにノイズ除去も実行します。一方、平均プーリングは、ノイズ抑制メカニズムとして単純に次元削減を実行します。したがって、最大プーリングは平均プーリングよりもはるかに優れていると言えます。
畳み込み層とプーリング層が一緒になって、畳み込みニューラルネットワークのi番目の層を形成します。画像の複雑さによっては、低レベルの詳細をさらにキャプチャするためにそのようなレイヤーの数を増やすことができますが、計算能力が高くなります。
上記のプロセスを経た後、モデルが機能を理解できるようになりました。次に、最終出力をフラット化し、分類のために通常のニューラルネットワークにフィードします。
分類—完全に接続されたレイヤー(FCレイヤー)

完全に接続されたレイヤーの追加は、畳み込みレイヤーの出力で表される高レベルの特徴の非線形結合を学習する(通常)安価な方法です。完全に接続されたレイヤーは、その空間で非線形関数の可能性を学習しています。
入力画像を多層パーセプトロンに適した形式に変換したので、画像を平坦化して列ベクトル。平坦化された出力はフィードフォワードニューラルネットワークに送られ、トレーニングのすべての反復にバックプロパゲーションが適用されます。一連のエポックにわたって、モデルは画像内の支配的な特徴と特定の低レベルの特徴を区別し、Softmax分類手法を使用してそれらを分類することができます。
利用可能なCNNのさまざまなアーキテクチャがあります。予見可能な将来にAI全体に電力を供給し、電力を供給するアルゴリズムを構築します。それらのいくつかを以下に示します。
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
