Kunstig intelligens har vært vitne til en monumental vekst i å bygge bro over gapet mellom menneskers og maskiners evner. Forskere og entusiaster jobber med mange aspekter av feltet for å få fantastiske ting til å skje. Ett av mange slike områder er domenet til Computer Vision.
Agendaen for dette feltet er å gjøre det mulig for maskiner å se på verden som mennesker gjør, oppfatte den på en lignende måte og til og med bruke kunnskapen til et mangfold. av oppgaver som Image & Videogjenkjenning, Image Analysis & Klassifisering, Media Recreation, Anbefalingssystemer, Natural Language Processing osv. Fremskrittene i Computer Vision with Deep Learning har blitt konstruert og perfeksjonert med tiden, hovedsakelig over en bestemt algoritme – et Convolutional Neural Network.
Innledning

A Convolutional Neural Network (ConvNet / CNN) er en dyp læring algoritme som kan ta inn et inngangsbilde, tildele betydning (lærbar vekter og skjevheter) til ulike aspekter / objekter i bildet og være i stand til å skille det ene fra det andre. Forbehandlingen som kreves i et ConvNet er mye lavere sammenlignet med andre klassifiseringsalgoritmer. Mens i primitive metoder er filtre håndkonstruert, med nok opplæring, har ConvNets muligheten til å lære disse filtrene / egenskapene.
Arkitekturen til et ConvNet er analog med den for tilkoblingsmønsteret til Neurons in the Human Hjernen og ble inspirert av organisasjonen av Visual Cortex. Individuelle nevroner reagerer bare på stimuli i et begrenset område av synsfeltet, kjent som det mottakelige feltet. En samling av slike felt overlapper for å dekke hele det visuelle området.
Hvorfor ConvNets over feed-forward Neural Nets?

Et bilde er vel ikke noe annet enn en matrise av pikselverdier, ikke sant? Så hvorfor ikke bare flate bildet (f.eks. 3×3 bildematrise i en 9×1-vektor) og mate det til en Multi-Level Perceptron for klassifiseringsformål? Uh .. egentlig ikke.
I tilfeller av ekstremt grunnleggende binære bilder, kan metoden vise en gjennomsnittlig presisjonspoeng mens du utfører prediksjon av klasser, men vil ha liten eller ingen nøyaktighet når det gjelder komplekse bilder som har pixelavhengighet gjennom.
Et ConvNet er i stand til å lykkes med å fange avhengighet mellom rom og tid i et bilde ved å bruke relevante filtre. Arkitekturen utfører en bedre tilpasning til bildedatasettet på grunn av reduksjon i antall involverte parametere og gjenbrukbar vekt. Med andre ord kan nettverket opplæres for å forstå raffinementet i bildet bedre.
Inngangsbilde

I figuren har vi et RGB-bilde som er atskilt med de tre fargeflakene – rød, grønn, og blått. Det finnes en rekke slike fargerom der bilder eksisterer – Gråtoner, RGB, HSV, CMYK osv.
Du kan forestille deg hvor beregningskrevende ting ville bli når bildene når dimensjoner, si 8K (7680 × 4320). Rollen til ConvNet er å redusere bildene til en form som er lettere å behandle, uten å miste funksjoner som er kritiske for å få en god spådom. Dette er viktig når vi skal designe en arkitektur som ikke bare er god til å lære funksjoner, men som også er skalerbar til store datasett.
Convolution Layer – The Kernel
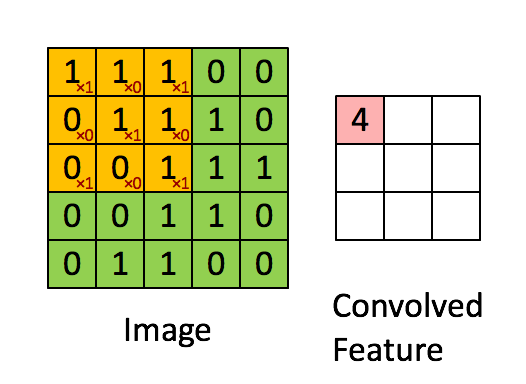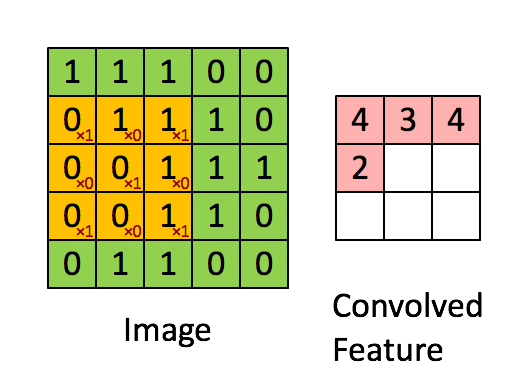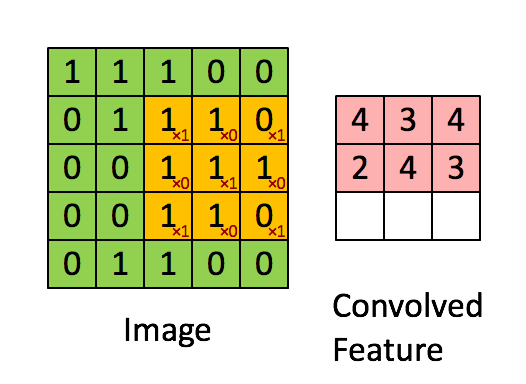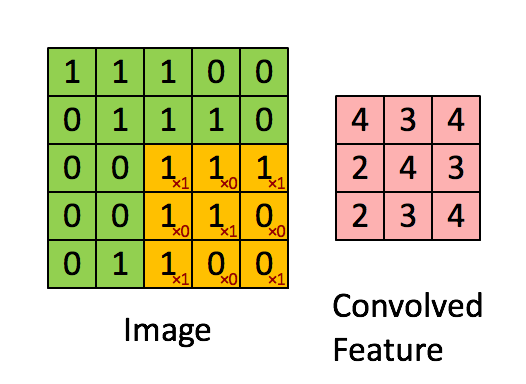
Bilde Dimensjoner = 5 (høyde) x 5 (bredde) x 1 (antall kanaler, f.eks. RGB)
I demonstrasjonen ovenfor ligner den grønne delen vårt 5x5x1 inngangsbilde, I. Elementet som er involvert i å bære ut konvolusjonsoperasjonen i første del av et konvolusjonslag kalles Kernel / Filter, K, representert i fargen gul. Vi har valgt K som en 3x3x1 matrise.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
Kjernen skifter 9 ganger på grunn av skrittlengde = 1 (ikke-stridet), hver gang du utfører en matrise multiplikasjonsoperasjon mellom K og den delen P av bildet som kjernen svever over.

Filteret beveger seg til høyre med en viss trinnverdi til den analyserer hele bredden. Når du går videre, hopper den ned til begynnelsen (til venstre) av bildet med samme trinnverdi og gjentar prosessen til hele bildet er krysset.
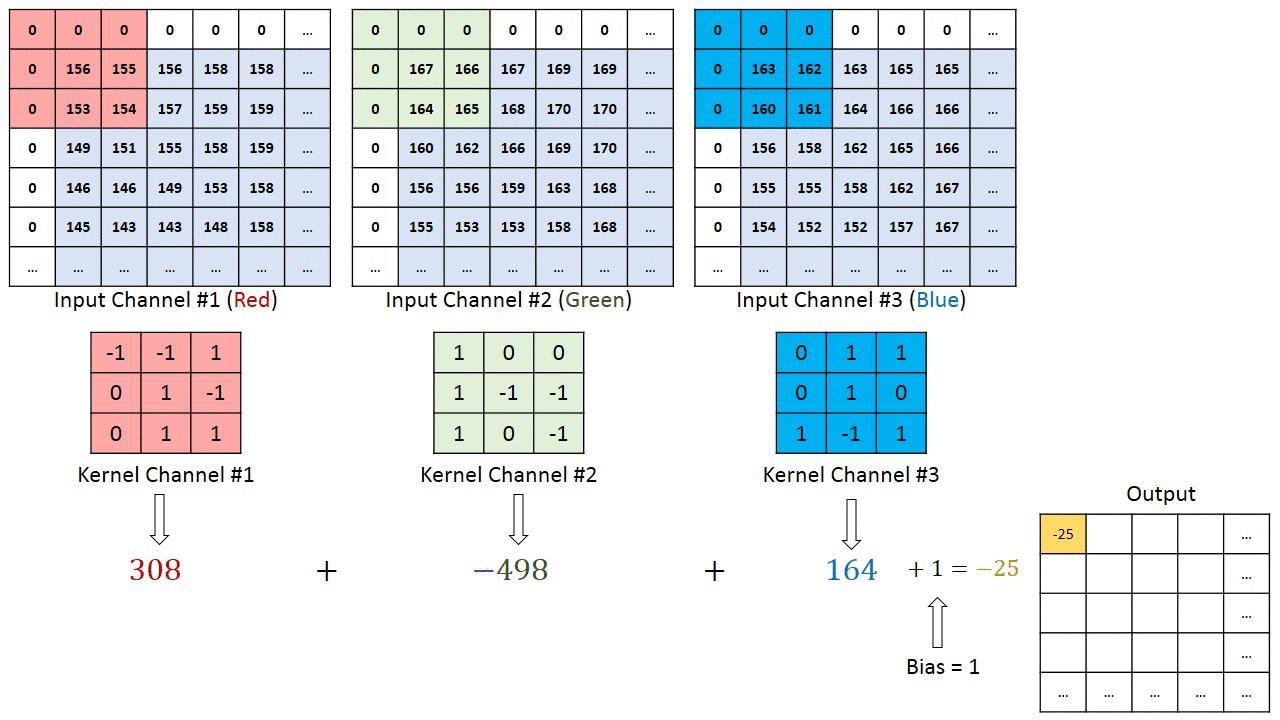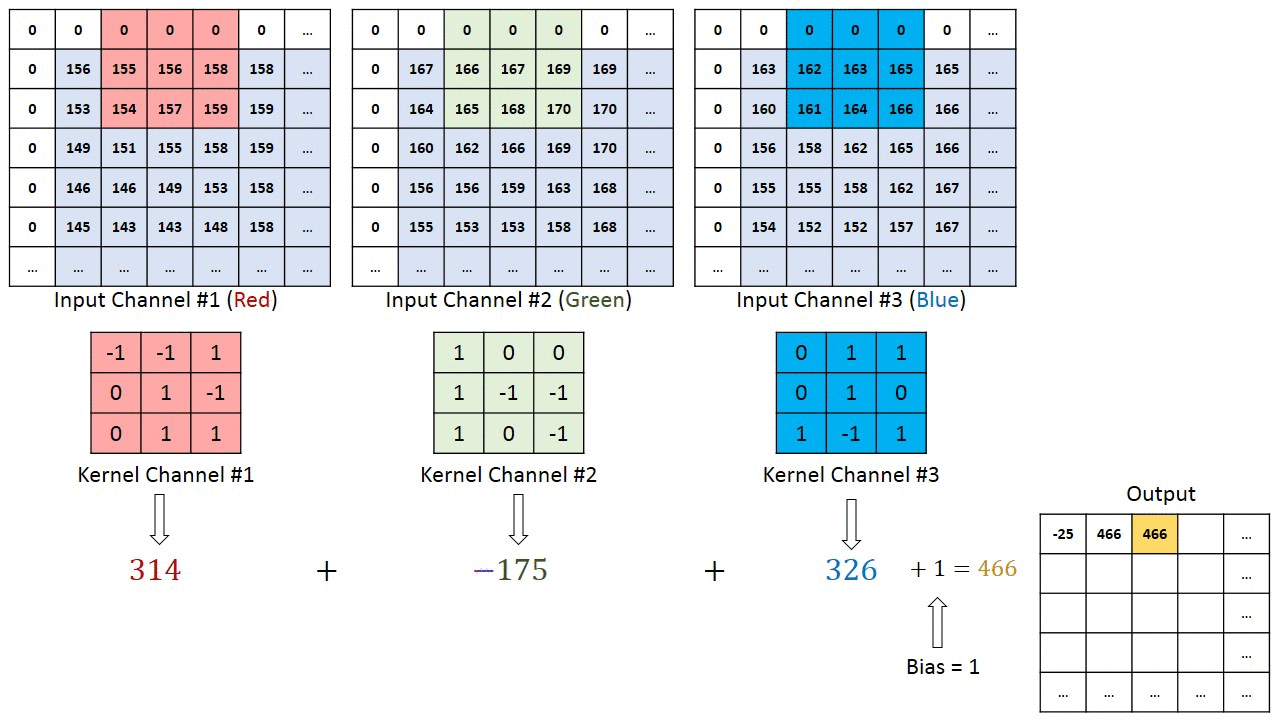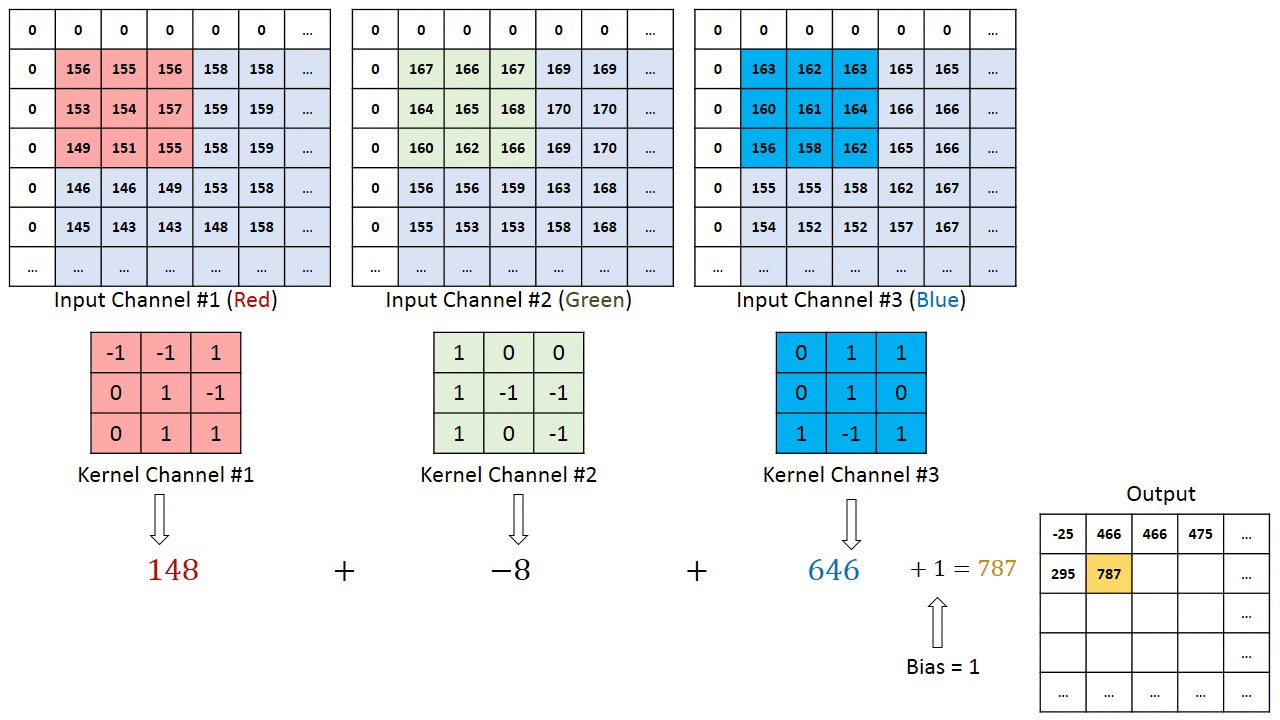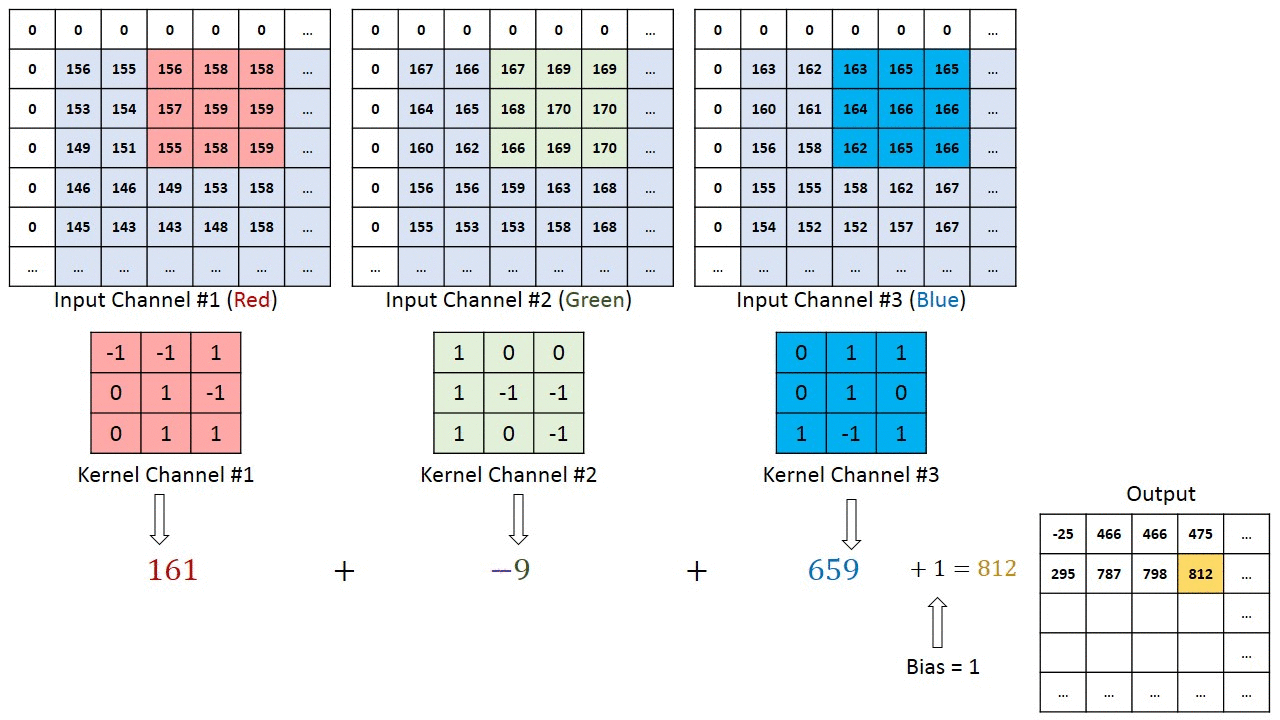
Når det gjelder bilder med flere kanaler (f.eks. RGB ), har kjernen samme dybde som inngangsbildet. Matrisemultiplikasjon utføres mellom Kn og In stack (;;), og alle resultatene oppsummeres med skjevhet for å gi oss en squashed en dybdekanal Convoluted Feature Output.
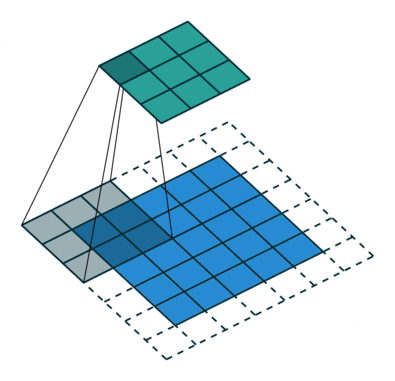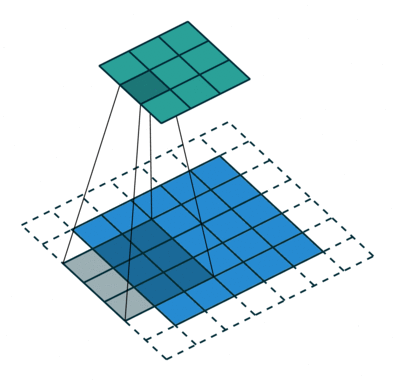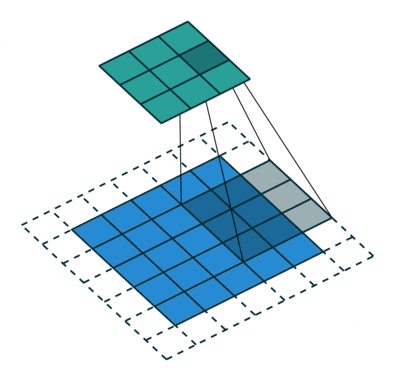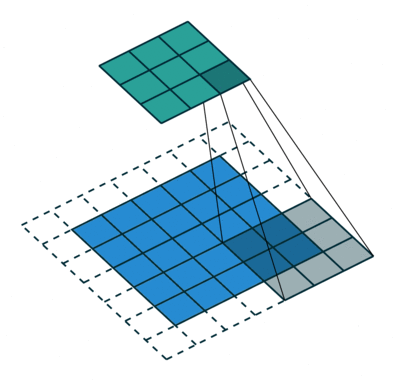
Målet med Convolution Operation er å trekke ut funksjoner på høyt nivå som kanter, fra inngangsbildet. ConvNets trenger ikke være begrenset til bare ett konvolusjonslag. Konvensjonelt er det første ConvLayer som er ansvarlig for å fange lavnivåfunksjonene som kanter, farger, gradientorientering osv. Med ekstra lag tilpasser arkitekturen seg også til høynivåfunksjonene, noe som gir oss et nettverk som har den sunne forståelsen av bilder i datasettet, ligner på hvordan vi ville gjort.
Det er to typer resultater til operasjonen – den ene der den konvolverte funksjonen er redusert i dimensjonalitet sammenlignet med inngangen, og den andre der dimensjonaliteten er enten økt eller forblir den samme. Dette gjøres ved å bruke Valid Padding i tilfelle førstnevnte, eller Same Padding i tilfelle sistnevnte.
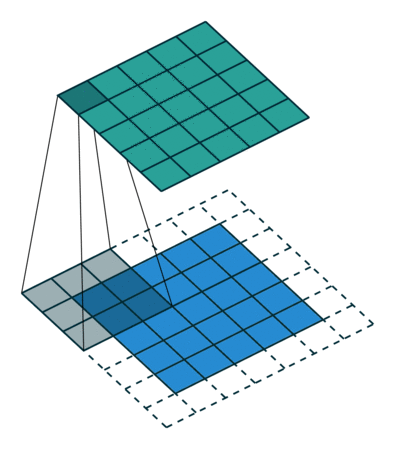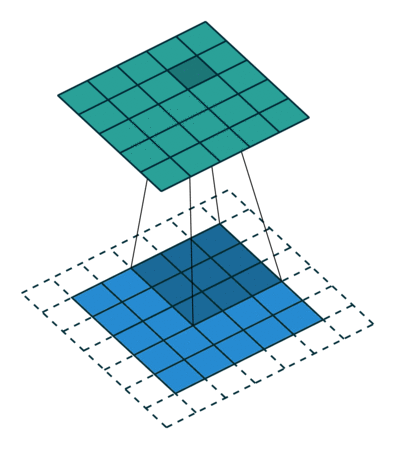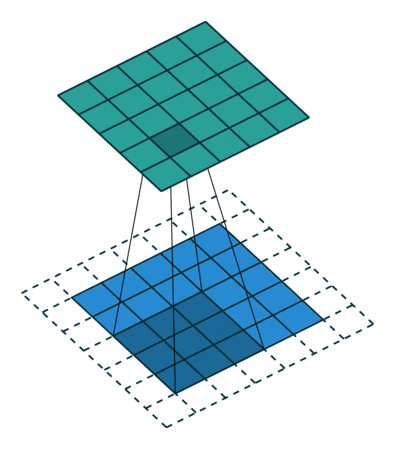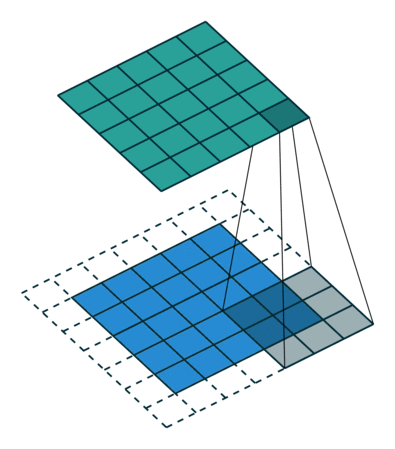
Når vi utvider 5x5x1-bildet til et 6x6x1-bilde og deretter bruker 3x3x1-kjernen over det, finner vi ut at convolved matrix viser seg å være av dimensjoner 5x5x1. Derav navnet – Samme polstring.
På den annen side, hvis vi utfører den samme operasjonen uten polstring, blir vi presentert en matrise som har dimensjoner av selve kjernen (3x3x1) – Gyldig polstring.
Følgende depot inneholder mange slike GIF-er som vil hjelpe deg med å få en bedre forståelse av hvordan polstring og stridlengde fungerer sammen for å oppnå resultater som er relevante for våre behov.
Pooling Layer
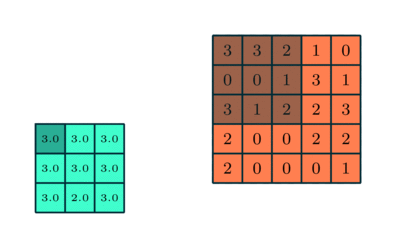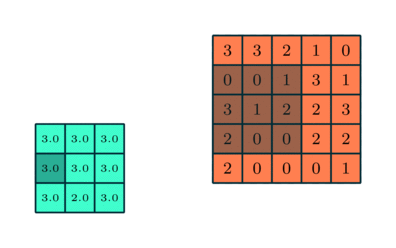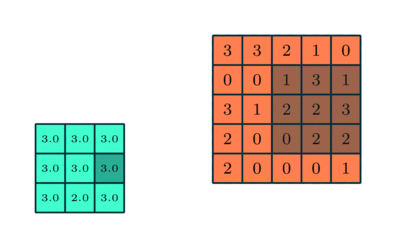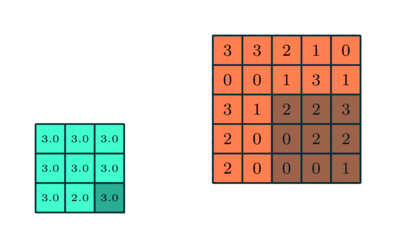
I likhet med Convolutional Layer, Pooling-laget er ansvarlig for å redusere den romlige størrelsen på Convolved Feature. Dette er for å redusere beregningskraften som kreves for å behandle dataene gjennom dimensjonsreduksjon. Videre er det nyttig for å trekke ut dominerende funksjoner som er rotasjons- og posisjonelle uforanderlige, og dermed opprettholde prosessen med effektiv opplæring av modellen.
Det er to typer pooling: Max Pooling og Average Pooling. Max Pooling returnerer maksimumsverdien fra den delen av bildet som dekkes av kjernen. På den annen side returnerer gjennomsnittlig pooling gjennomsnittet av alle verdiene fra den delen av bildet som dekkes av kjernen.
Max Pooling fungerer også som et støydempende middel. Det forkaster de støyende aktiveringene helt og utfører også avstøyning sammen med dimensjonsreduksjon. På den annen side utfører gjennomsnittlig pooling bare dimensjonsreduksjon som en støydempende mekanisme. Derfor kan vi si at Max Pooling presterer mye bedre enn gjennomsnittlig pooling.
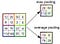
Convolutional Layer og Pooling Layer, sammen danner det i-th laget av et Convolutional Neural Network. Avhengig av kompleksiteten i bildene, kan antallet slike lag økes for å fange detaljer på lave nivåer ytterligere, men på bekostning av mer beregningskraft.
Etter å ha gått gjennom prosessen ovenfor, har vi gjorde det mulig for modellen å forstå funksjonene. Når vi går videre, skal vi flate den endelige produksjonen og mate den til et vanlig nevralt nettverk for klassifiseringsformål.
Klassifisering – Fullt koblet lag (FC-lag)

Å legge til et fullt tilkoblet lag er en (vanligvis) billig måte å lære ikke-lineære kombinasjoner av funksjonene på høyt nivå som representert av utfallet fra konvolusjonslaget. Fullt-koblet laget lærer en muligens ikke-lineær funksjon i det rommet.
Nå som vi har konvertert vårt inngangsbilde til en passende form for Multi-Level Perceptron, skal vi flate bildet til et kolonnevektor. Den flate produksjonen blir matet til et feed-forward neuralt nettverk og backpropagation brukt på hver iterasjon av trening. I løpet av en rekke epoker er modellen i stand til å skille mellom dominerende og visse funksjoner på lavt nivå i bilder og klassifisere dem ved hjelp av Softmax Classification-teknikken.
Det er forskjellige arkitekturer av CNN-er tilgjengelig som har vært nøkkelen til bygge algoritmer som driver og skal drive AI som helhet i overskuelig fremtid. Noen av dem er oppført nedenfor:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
