Inteligența artificială a asistat la o creștere monumentală în reducerea decalajului dintre capacitățile oamenilor și mașini. Cercetătorii și entuziaștii, deopotrivă, lucrează la numeroase aspecte ale domeniului pentru a face să se întâmple lucruri uimitoare. Una dintre numeroasele astfel de domenii este domeniul Viziunii computerizate.
Agenda acestui domeniu este de a permite mașinilor să vadă lumea așa cum o fac oamenii, să o perceapă într-un mod similar și chiar să folosească cunoștințele pentru o multitudine. de sarcini precum Image & Recunoaștere video, Analiză imagine & Clasificare, Recreere media, Sisteme de recomandare, Prelucrarea limbajului natural, etc. în Computer Vision with Deep Learning a fost construit și perfecționat cu timpul, în primul rând pe un anumit algoritm – o rețea neuronală convolutională.
Introducere

O rețea neuronală convolutională (ConvNet / CNN) este o învățare profundă algoritm care poate lua o imagine de intrare, poate atribui importanță (learnabl greutăți și părtiniri) la diferite aspecte / obiecte din imagine și să fie capabili să se diferențieze unul de celălalt. Pre-procesarea necesară într-un ConvNet este mult mai mică în comparație cu alți algoritmi de clasificare. În timp ce în metodele primitive filtrele sunt realizate manual, cu suficientă pregătire, ConvNets au capacitatea de a învăța aceste filtre / caracteristici.
Arhitectura unui ConvNet este analogă cu cea a modelului de conectivitate al neuronilor în om Brain și a fost inspirat de organizarea Cortexului vizual. Neuronii individuali răspund la stimuli numai într-o regiune restrânsă a câmpului vizual cunoscut sub numele de Câmpul receptiv. O colecție de astfel de câmpuri se suprapune pentru a acoperi întreaga zonă vizuală.
De ce ConvNets peste Feed-Forward Neural Nets?

O imagine nu este altceva decât o matrice de valori ale pixelilor, nu? Deci, de ce să nu aplatizăm imaginea (de exemplu, matricea de imagine 3×3 într-un vector 9×1) și să o alimentăm către un Perceptron multi-nivel în scopuri de clasificare? Uh .. nu chiar.
În cazul imaginilor binare extrem de elementare, metoda ar putea arăta un scor mediu de precizie în timpul efectuării predicțiilor claselor, dar ar avea o precizie mică sau delocă atunci când vine vorba de imagini complexe care au dependențe de pixeli. peste tot.
Un ConvNet poate capta cu succes dependențele spațiale și temporale într-o imagine prin aplicarea filtrelor relevante. Arhitectura se potrivește mai bine cu setul de date al imaginii datorită reducerii numărului de parametri implicați și reutilizării greutăților. Cu alte cuvinte, rețeaua poate fi instruită pentru a înțelege mai bine sofisticarea imaginii.
Intrare imagine

În figură, avem o imagine RGB separată de cele trei planuri de culoare – roșu, verde, și Albastru. Există o serie de astfel de spații de culoare în care există imagini – Scară de gri, RGB, HSV, CMYK etc.
Vă puteți imagina cât de intens ar fi lucrurile din punct de vedere al calculului odată ce imaginile vor ajunge la dimensiuni, să zicem 8K (7680 × 4320). Rolul ConvNet este de a reduce imaginile într-o formă mai ușor de procesat, fără a pierde caracteristici care sunt esențiale pentru a obține o predicție bună. Acest lucru este important atunci când urmează să proiectăm o arhitectură care nu numai că este bună la învățarea caracteristicilor, dar este, de asemenea, scalabilă la seturi de date masive.
Convolution Layer – Kernel
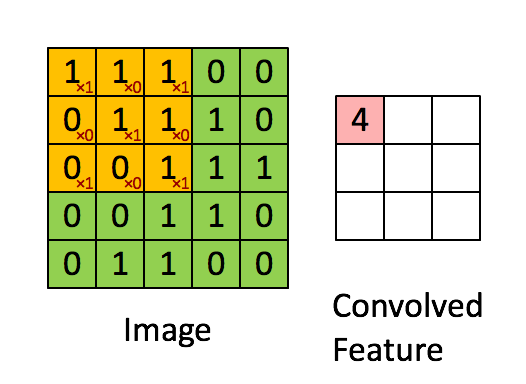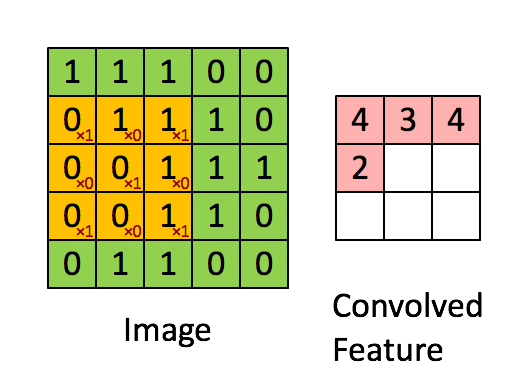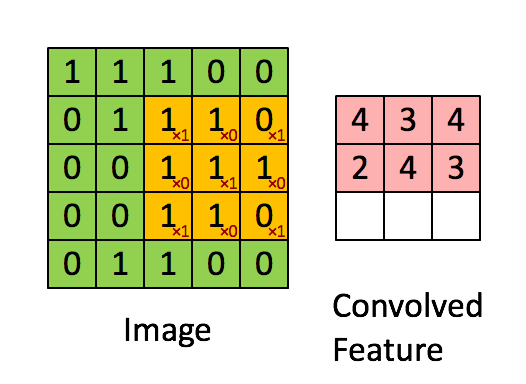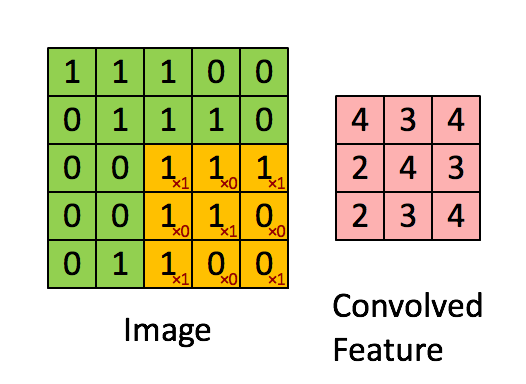
Imagine Dimensiuni = 5 (Înălțime) x 5 (Lățime) x 1 (Număr de canale, de ex. RGB)
În demonstrația de mai sus, secțiunea verde seamănă cu imaginea noastră de intrare 5x5x1, I. Elementul implicat în transportarea operația de convoluție din prima parte a unui strat de convoluție se numește Kernel / Filter, K, reprezentat în culoarea galbenă. Am selectat K ca o matrice de 3x3x1.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
Nucleul se schimbă de 9 ori datorită lungimii pasului = 1 (non-strid), de fiecare dată realizând o matrice operație de multiplicare între K și porțiunea P a imaginii peste care planează nucleul.

Filtrul se deplasează spre dreapta cu o anumită valoare a pasului până când analizează lățimea completă. Mergând mai departe, saltează până la începutul (stânga) imaginii cu aceeași valoare a pasului și repetă procesul până când întreaga imagine este traversată.
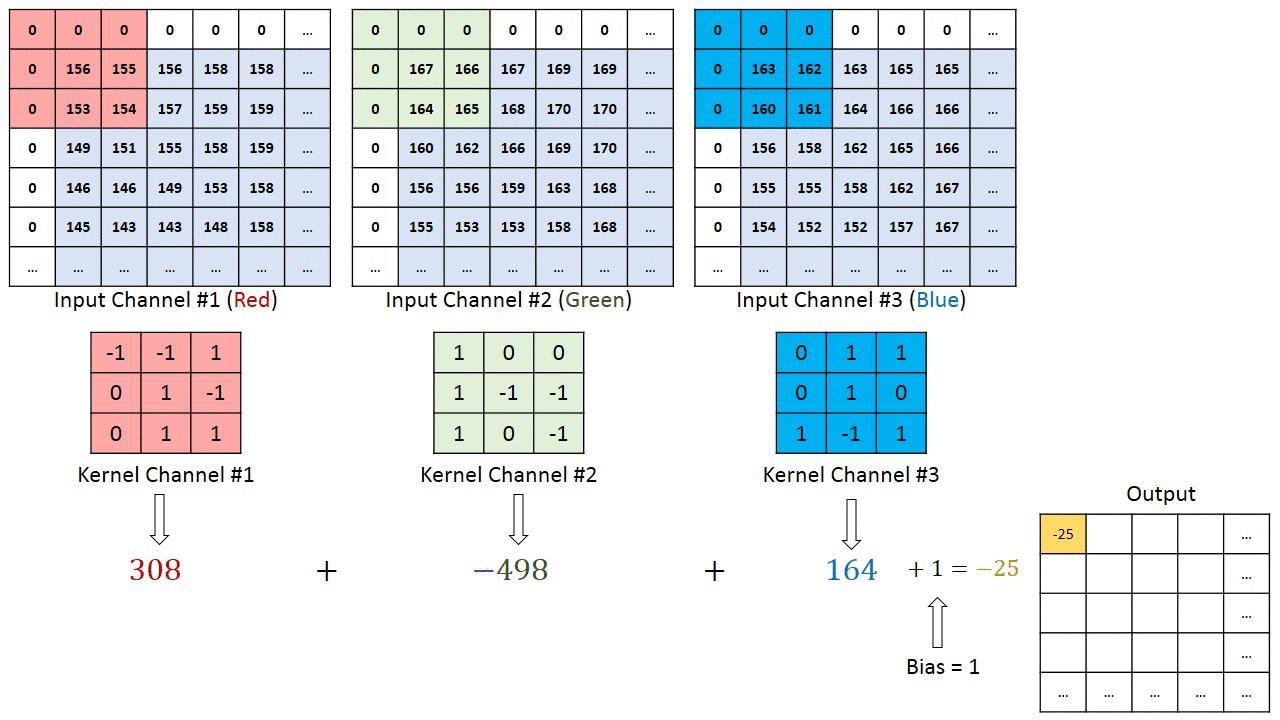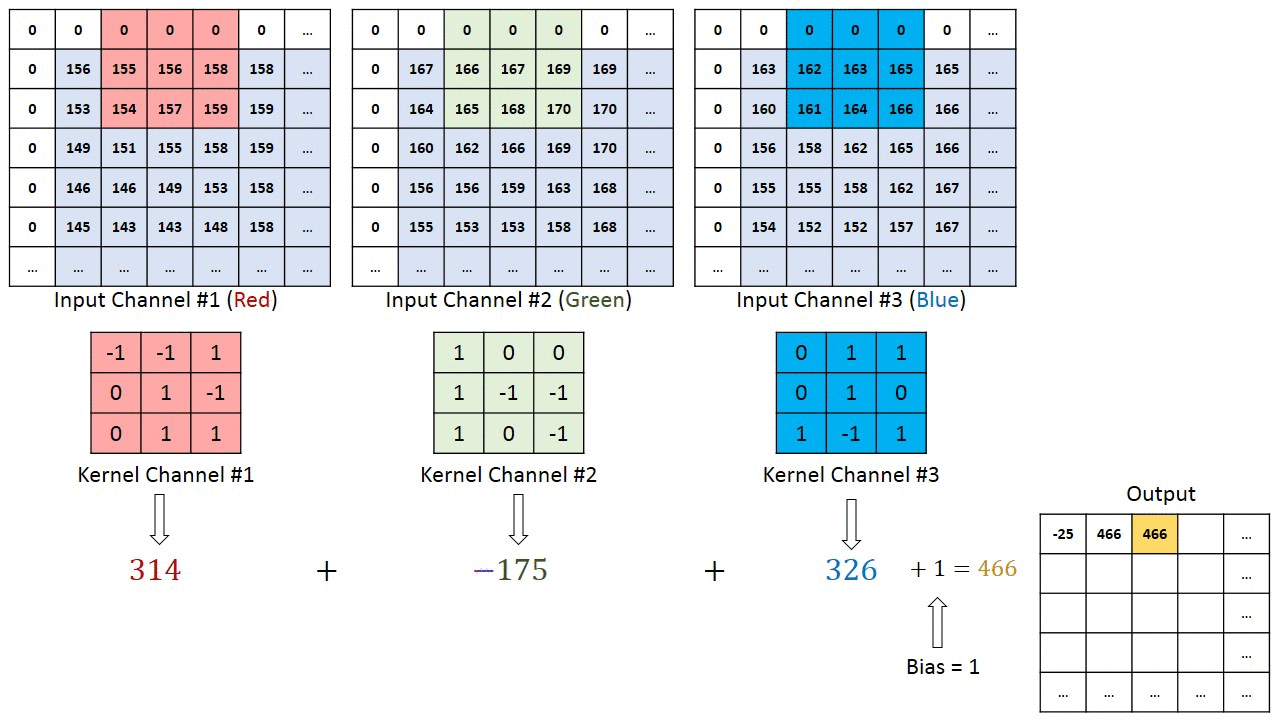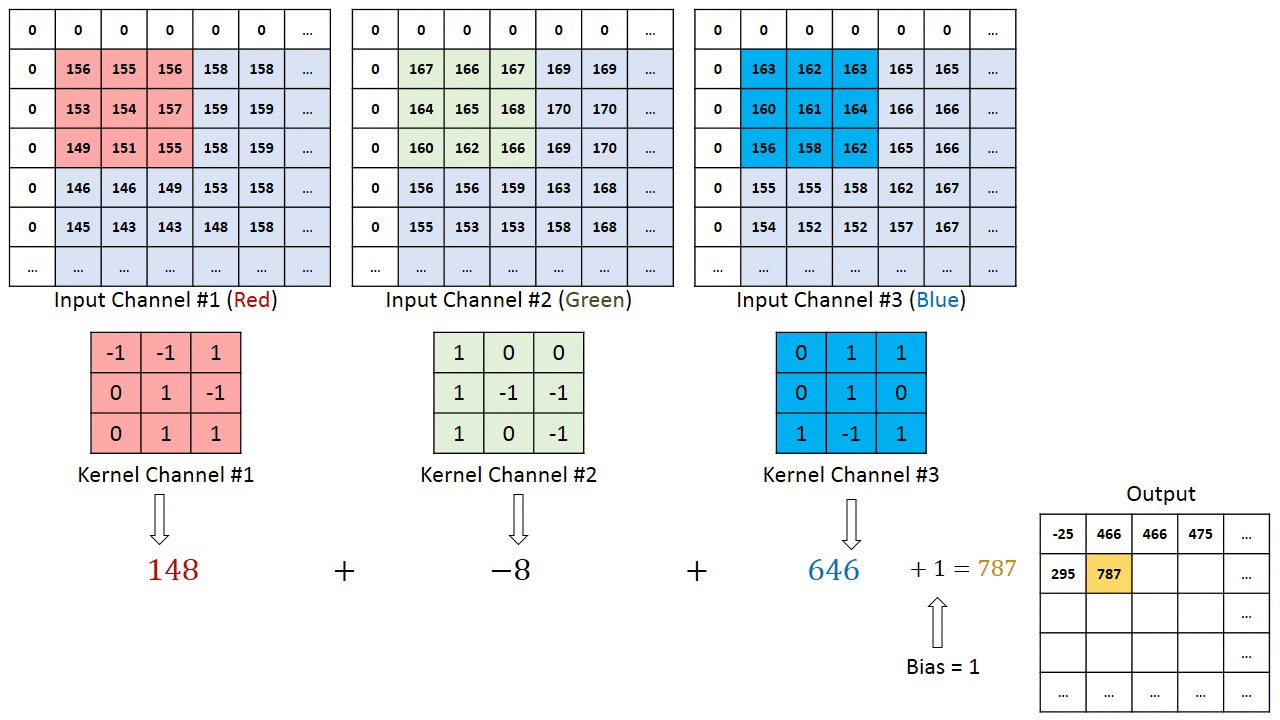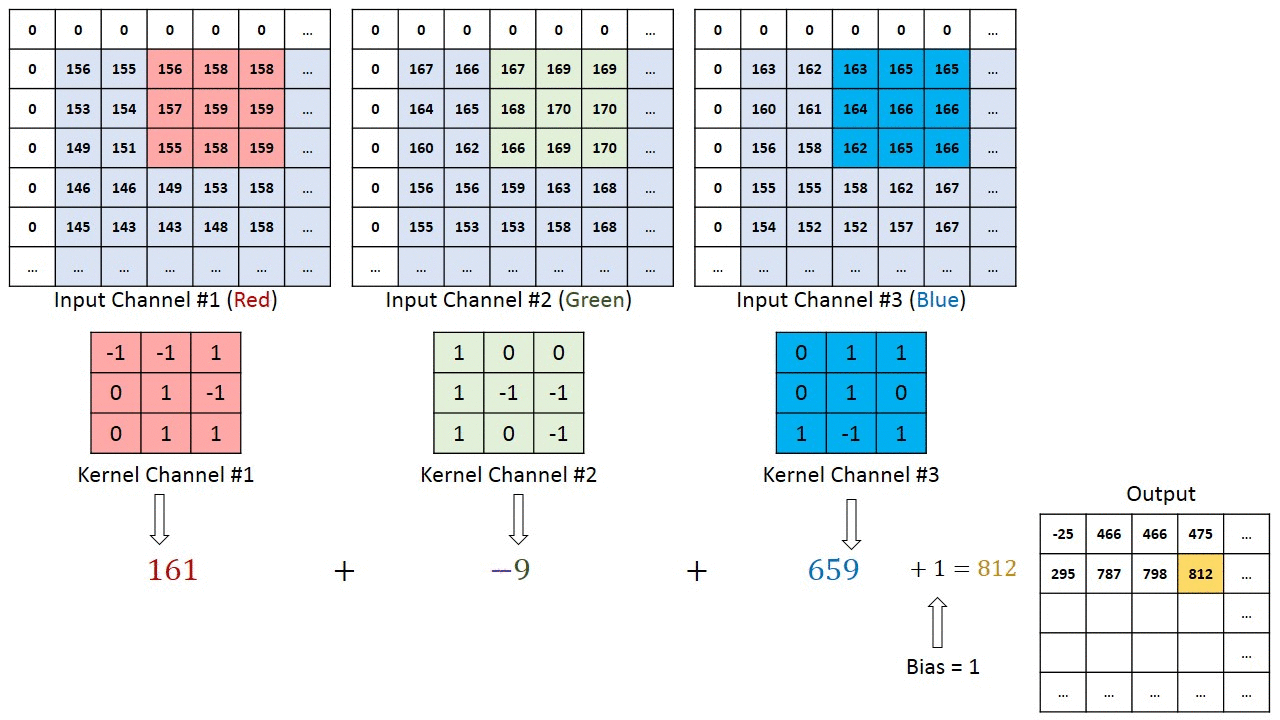
În cazul imaginilor cu mai multe canale (de ex. RGB ), nucleul are aceeași adâncime ca cea a imaginii de intrare. Înmulțirea matricei se realizează între Kn și In stack (;;) și toate rezultatele sunt însumate cu polarizarea pentru a ne oferi un canal de profunzime cu o profunzime de ieșire caracteristică complicată.
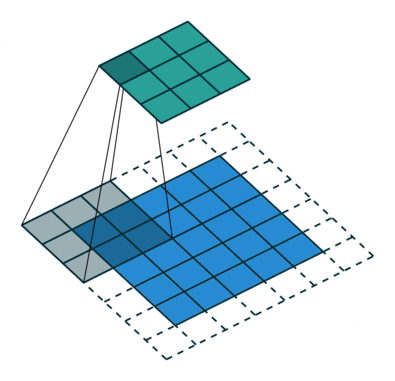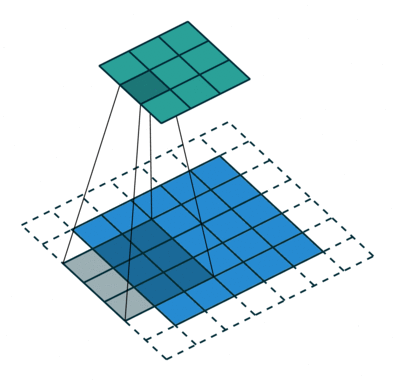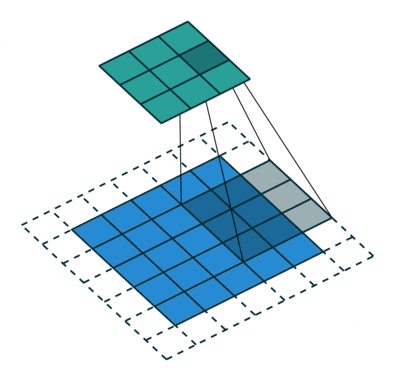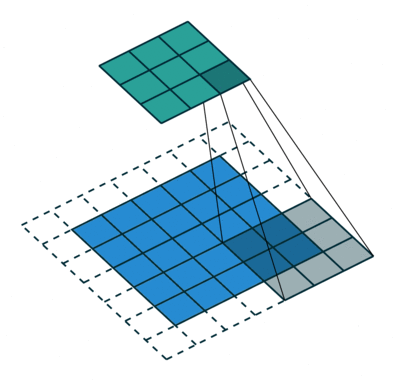
Obiectivul operației de convoluție este de a extrage caracteristicile de nivel înalt, cum ar fi marginile, din imaginea de intrare. ConvNets nu trebuie să fie limitate la un singur strat convoluțional. În mod convențional, primul ConvLayer este responsabil pentru captarea caracteristicilor de nivel scăzut, cum ar fi marginile, culoarea, orientarea gradientului etc. Cu straturi adăugate, arhitectura se adaptează și la caracteristicile de nivel înalt, oferindu-ne o rețea care are o înțelegere sănătoasă. de imagini în setul de date, similar cu modul în care am face-o.
Există două tipuri de rezultate ale operației – unul în care caracteristica convolvată este redusă în dimensionalitate în comparație cu intrarea și cealaltă în care dimensionalitatea este fie crescută, fie rămâne aceeași. Acest lucru se face aplicând Padding valid în cazul primului sau Același Padding în cazul celui din urmă.
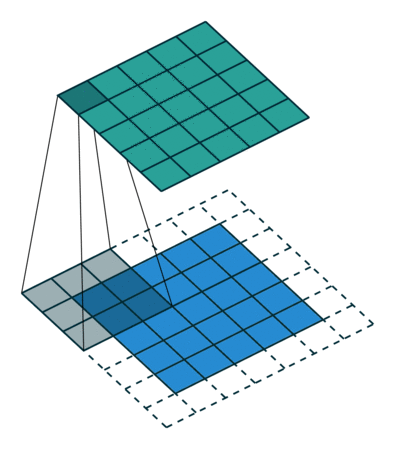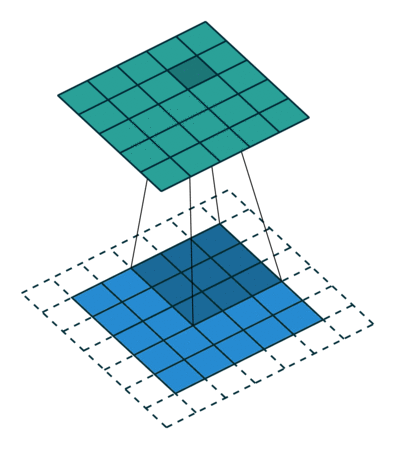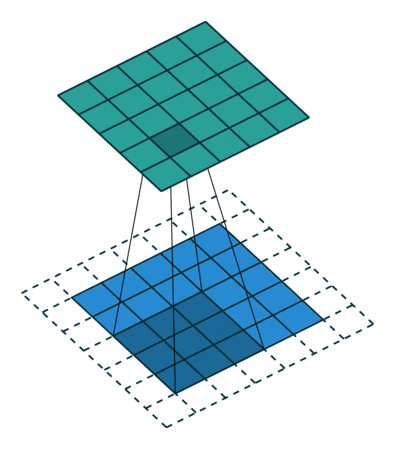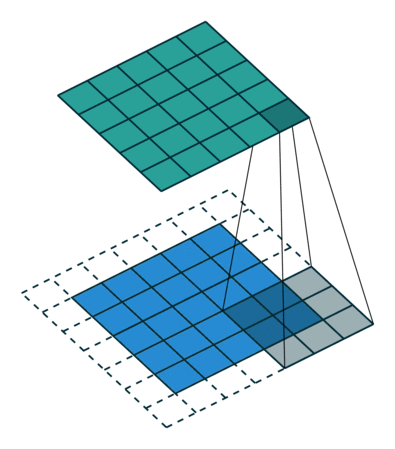
Când mărim imaginea de 5x5x1 într-o imagine de 6x6x1 și apoi aplicăm nucleul de 3x3x1 peste el, descoperim că matricea convolvată se dovedește a fi de dimensiuni 5x5x1. De aici și numele – Același Padding.
Pe de altă parte, dacă efectuăm aceeași operație fără umplutură, ni se prezintă o matrice care are dimensiunile nucleului (3x3x1) în sine – Padding valid.
Următorul depozit găzduiește multe astfel de GIF-uri care vă vor ajuta să înțelegeți mai bine modul în care Padding și Stride Length funcționează împreună pentru a obține rezultate relevante pentru nevoile noastre.
Pooling Layer
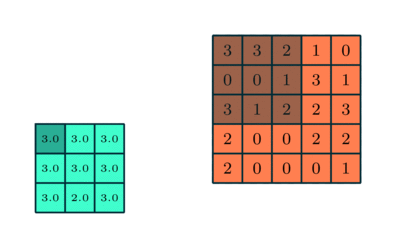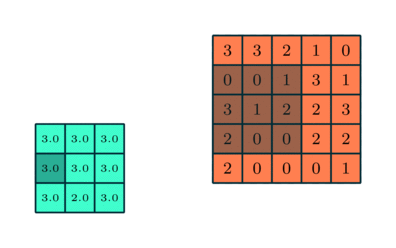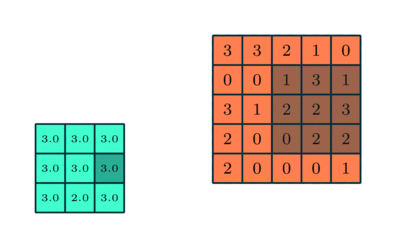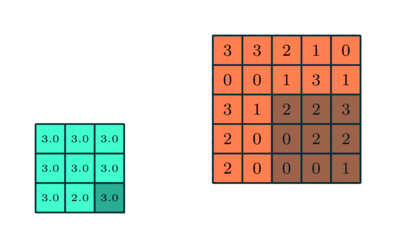
Similar stratului convolutiv, stratul Pooling este responsabil pentru reducerea dimensiunii spațiale a caracteristicii implicate. Aceasta înseamnă scăderea puterii de calcul necesare procesării datelor prin reducerea dimensionalității. Mai mult, este util pentru extragerea trăsăturilor dominante care sunt invariante de rotație și pozițională, menținând astfel procesul de instruire eficientă a modelului.
Există două tipuri de pooling: Max Pooling și Media Pooling. Max Pooling returnează valoarea maximă din porțiunea de imagine acoperită de Kernel. Pe de altă parte, Media Pooling returnează media tuturor valorilor din porțiunea de imagine acoperită de Kernel.
Max Pooling are, de asemenea, rolul de a reduce zgomotul. Elimină activările zgomotoase în totalitate și, de asemenea, efectuează de-zgomot împreună cu reducerea dimensionalității. Pe de altă parte, Pooling-ul mediu realizează pur și simplu reducerea dimensionalității ca un mecanism de suprimare a zgomotului. Prin urmare, putem spune că Max Pooling funcționează mult mai bine decât Media Pooling.
Stratul convoluțional și stratul de pooling, formează împreună stratul i al unei rețele neuronale convoluționale. În funcție de complexitatea imaginilor, numărul de astfel de straturi poate fi mărit pentru a capta detalii de niveluri scăzute și mai mult, dar cu prețul unei puteri de calcul mai mari.
După parcurgerea procesului de mai sus, avem activat cu succes modelul pentru a înțelege caracteristicile. Mergând mai departe, vom aplatiza rezultatul final și îl vom alimenta către o rețea neuronală obișnuită în scopuri de clasificare.
Clasificare – Strat complet conectat (Strat FC)

Adăugarea unui strat complet conectat este un mod (de obicei) ieftin de a învăța combinații neliniare ale caracteristicilor de nivel înalt, reprezentate de ieșirea stratului convoluțional. Stratul complet conectat învață o funcție posibil neliniară în acel spațiu.
Acum că ne-am convertit imaginea de intrare într-o formă adecvată pentru Perceptronul nostru pe mai multe niveluri, vom aplatiza imaginea într-un vector coloană. Ieșirea aplatizată este alimentată către o rețea neuronală de avansare și propagarea înapoi aplicată fiecărei iterații de antrenament. De-a lungul unei serii de epoci, modelul este capabil să facă distincția între caracteristicile dominante și anumite caracteristici de nivel scăzut din imagini și să le clasifice folosind tehnica de clasificare Softmax.
Există diferite arhitecturi ale CNN-urilor disponibile, care au fost esențiale în construind algoritmi care alimentează și vor alimenta AI în ansamblu în viitorul previzibil. Unele dintre ele au fost enumerate mai jos:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
