Kunstmatige intelligentie is getuige geweest van een enorme groei in het overbruggen van de kloof tussen de mogelijkheden van mensen en machines. Onderzoekers en enthousiastelingen werken aan tal van aspecten van het veld om verbazingwekkende dingen te laten gebeuren. Een van de vele van dergelijke gebieden is het domein van Computer Vision.
De agenda voor dit veld is om machines in staat te stellen de wereld te zien zoals mensen doen, deze op een vergelijkbare manier waar te nemen en zelfs de kennis te gebruiken voor een groot aantal van taken zoals afbeelding & Videoherkenning, beeldanalyse & Classificatie, media-recreatie, aanbevelingssystemen, natuurlijke taalverwerking, enz. De vorderingen in Computer Vision met Deep Learning is in de loop van de tijd geconstrueerd en geperfectioneerd, voornamelijk op basis van één bepaald algoritme – een convolutioneel neuraal netwerk.
Inleiding

Een convolutioneel neuraal netwerk (ConvNet / CNN) is een Deep Learning algoritme dat een invoerbeeld kan aannemen, belang toekennen (learnabl e gewichten en vooroordelen) op verschillende aspecten / objecten in het beeld en in staat zijn om van elkaar te onderscheiden. De voorbewerking die nodig is in een ConvNet is veel lager in vergelijking met andere classificatie-algoritmen. Terwijl in primitieve methoden filters met de hand worden gemaakt, met voldoende training, hebben ConvNets de mogelijkheid om deze filters / kenmerken te leren.
De architectuur van een ConvNet is analoog aan die van het connectiviteitspatroon van Neuronen in de mens Brain en werd geïnspireerd door de organisatie van de Visual Cortex. Individuele neuronen reageren alleen op stimuli in een beperkt gebied van het gezichtsveld dat bekend staat als het receptieve veld. Een verzameling van dergelijke velden overlappen elkaar om het hele visuele gebied te bestrijken.
Waarom ConvNets over Feed-Forward neurale netwerken?

Een afbeelding is niets anders dan een matrix van pixelwaarden, toch? Dus waarom zou u de afbeelding niet gewoon plat maken (bijv. 3×3 afbeeldingsmatrix in een 9×1 vector) en deze naar een Multi-Level Perceptron sturen voor classificatiedoeleinden? Uh .. niet echt.
In het geval van extreem eenvoudige binaire afbeeldingen, kan de methode een gemiddelde precisie-score laten zien tijdens het voorspellen van klassen, maar zou het weinig tot geen nauwkeurigheid hebben als het gaat om complexe afbeeldingen met pixelafhankelijkheden overal.
Een ConvNet is in staat om met succes de ruimtelijke en temporele afhankelijkheden in een afbeelding vast te leggen door de toepassing van relevante filters. De architectuur past beter bij de beelddataset vanwege de vermindering van het aantal betrokken parameters en de herbruikbaarheid van gewichten. Met andere woorden, het netwerk kan worden getraind om de verfijning van de afbeelding beter te begrijpen.
Invoerafbeelding

In de afbeelding hebben we een RGB-afbeelding die is gescheiden door de drie kleurvlakken – rood, groen, en blauw. Er zijn een aantal van dergelijke kleurruimten waarin afbeeldingen bestaan – Grijstinten, RGB, HSV, CMYK, enz.
Je kunt je voorstellen hoe rekenkundig intensief dingen zouden worden als de afbeeldingen afmetingen bereiken, zeg 8K (7680 × 4320). De rol van het ConvNet is om de afbeeldingen te verkleinen tot een vorm die gemakkelijker te verwerken is, zonder functies te verliezen die essentieel zijn voor het verkrijgen van een goede voorspelling. Dit is belangrijk wanneer we een architectuur willen ontwerpen die niet alleen goed is in leerfuncties, maar ook schaalbaar is tot enorme datasets.
Convolution Layer – The Kernel
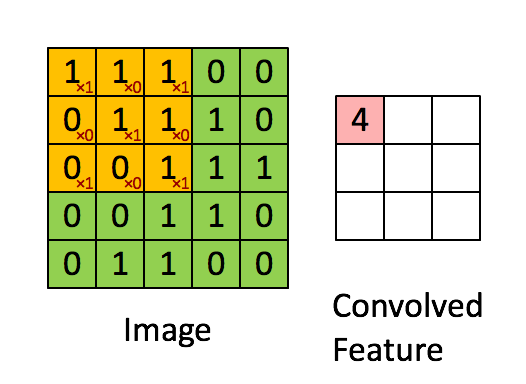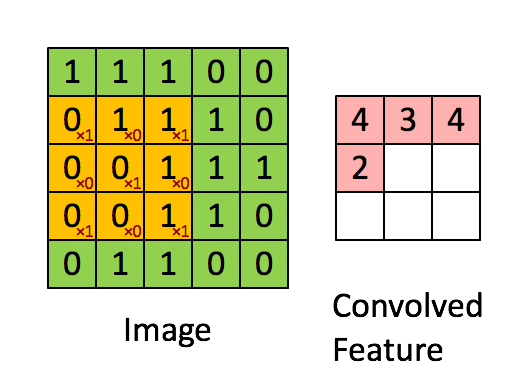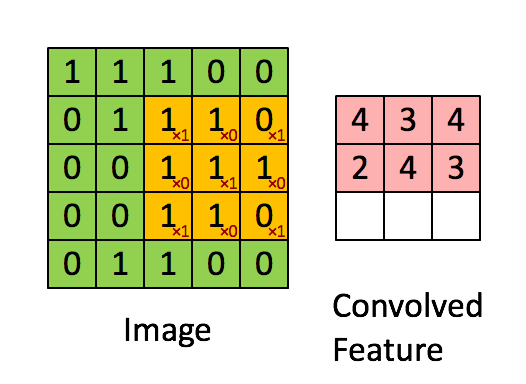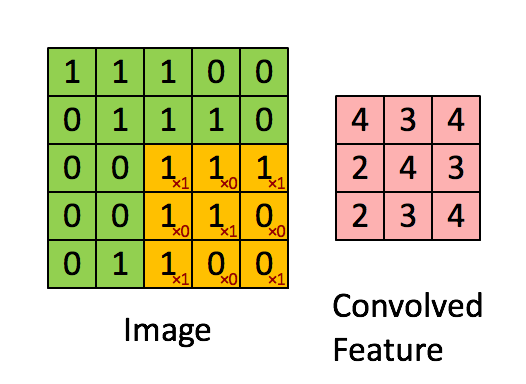
Afbeelding Afmetingen = 5 (hoogte) x 5 (breedte) x 1 (aantal kanalen, bijv. RGB)
In de bovenstaande demonstratie lijkt het groene gedeelte op ons 5x5x1 invoerbeeld, I. Het element dat betrokken is bij het dragen De convolutiebewerking in het eerste deel van een convolutionele laag wordt de kernel / filter, K, weergegeven in de kleur geel. We hebben K geselecteerd als een 3x3x1-matrix.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
De kernel verschuift 9 keer vanwege de paslengte = 1 (niet-gestegen), elke keer dat een matrix wordt uitgevoerd vermenigvuldiging tussen K en het deel P van de afbeelding waarover de kernel zweeft.

Het filter beweegt naar rechts met een bepaalde stapwaarde totdat de volledige breedte wordt geparseerd. Verderop springt het naar het begin (links) van de afbeelding met dezelfde stapwaarde en herhaalt het proces totdat de hele afbeelding is doorlopen.
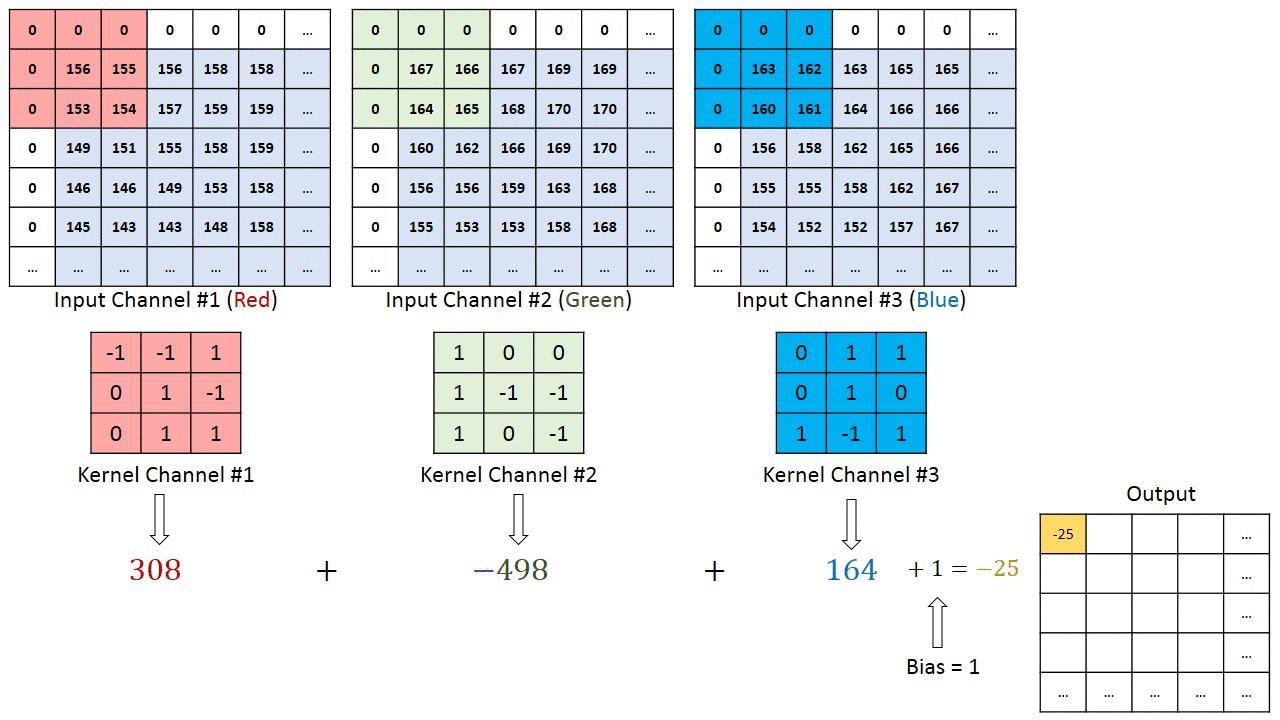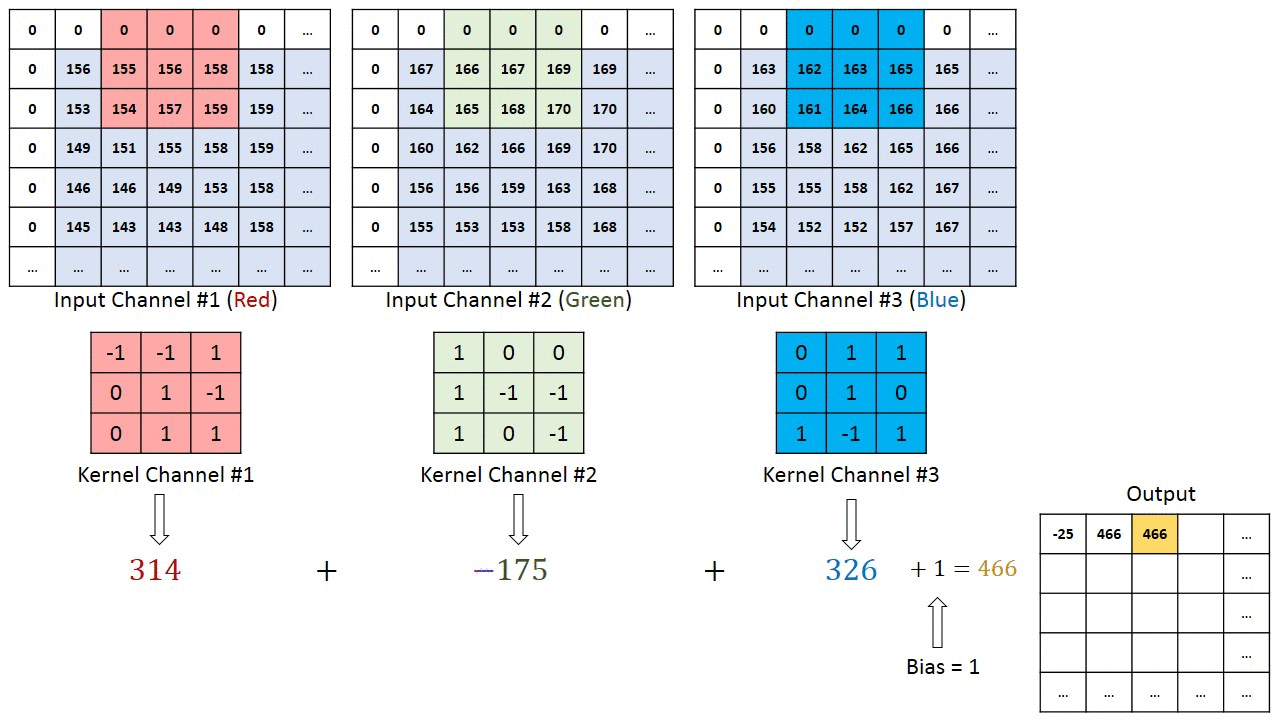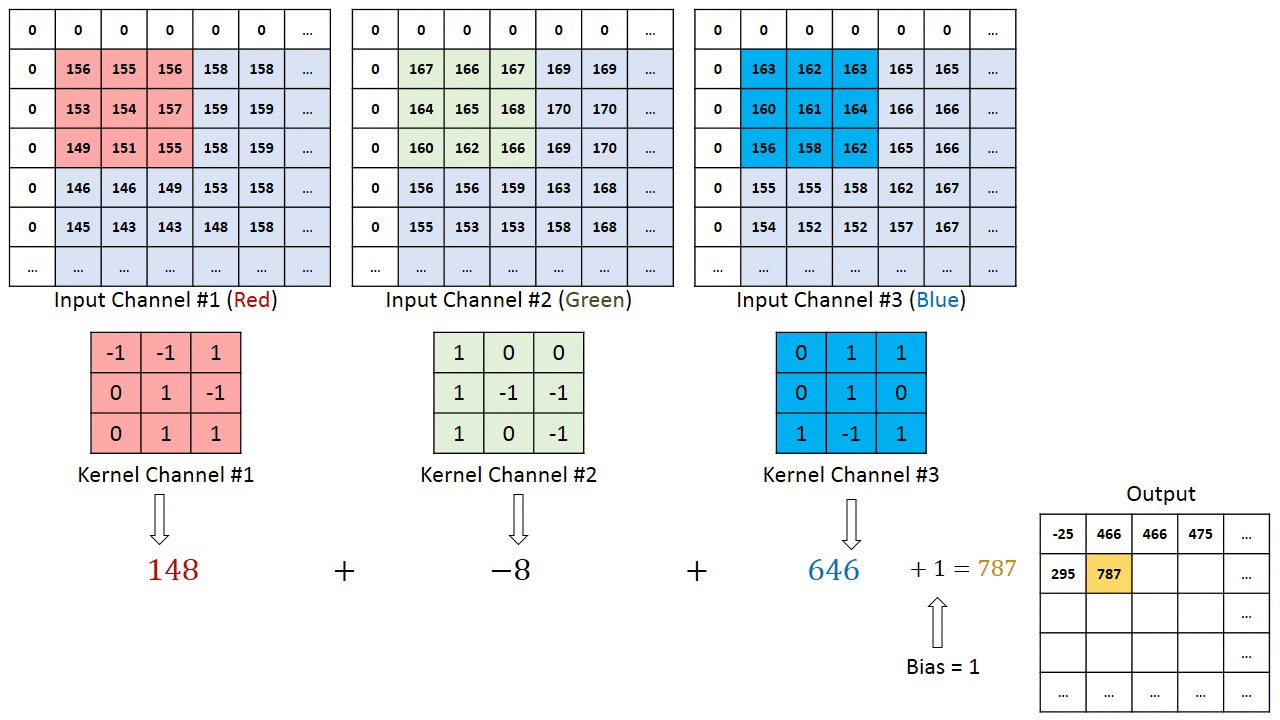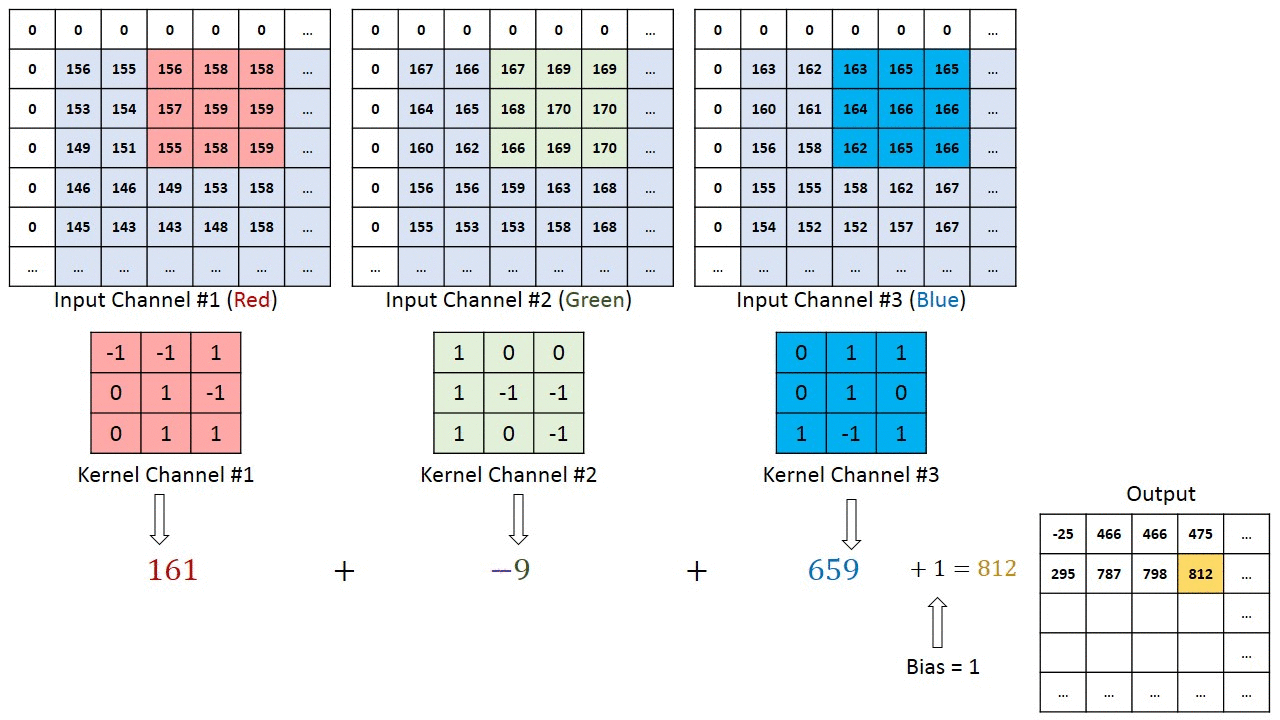
In het geval van afbeeldingen met meerdere kanalen (bijv. RGB ), heeft de Kernel dezelfde diepte als die van het invoerbeeld. Matrixvermenigvuldiging wordt uitgevoerd tussen Kn en In stack (;;) en alle resultaten worden opgeteld met de bias om ons een geplet kanaal van één diepte ingewikkelde functie-uitvoer te geven.
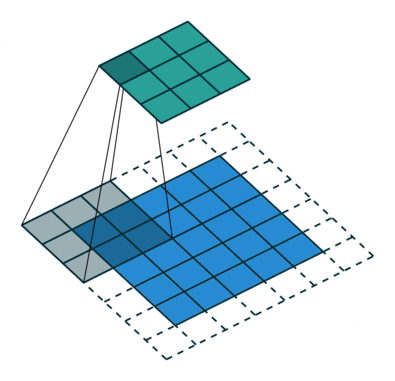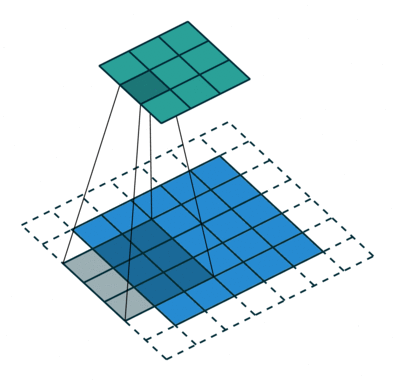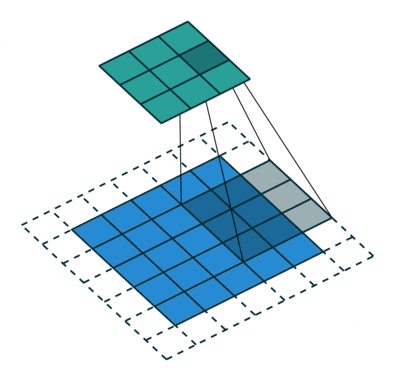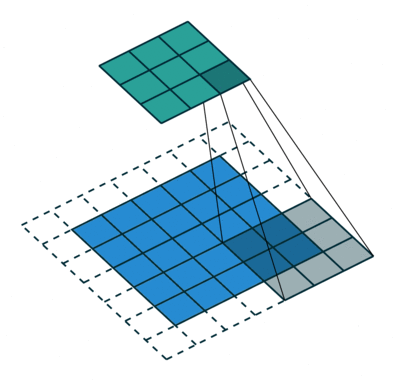
Het doel van de Convolution-operatie is om de functies op hoog niveau te extraheren, zoals randen, van het invoerbeeld. ConvNets hoeven niet beperkt te zijn tot slechts één convolutionele laag. Conventioneel is de eerste ConvLayer verantwoordelijk voor het vastleggen van de Low-Level-functies zoals randen, kleur, verlooporiëntatie, enz. Met toegevoegde lagen past de architectuur zich ook aan de High-Level-functies aan, wat ons een netwerk geeft met het gezonde begrip van afbeeldingen in de dataset, vergelijkbaar met hoe we dat zouden doen.
Er zijn twee soorten resultaten voor de bewerking: een waarin het geconvolueerde kenmerk minder dimensionaliteit heeft in vergelijking met de invoer, en de andere waarin de dimensionaliteit wordt óf vergroot óf blijft hetzelfde. Dit wordt gedaan door Valid Padding toe te passen in het eerste geval, of Same Padding in het geval van het laatste.
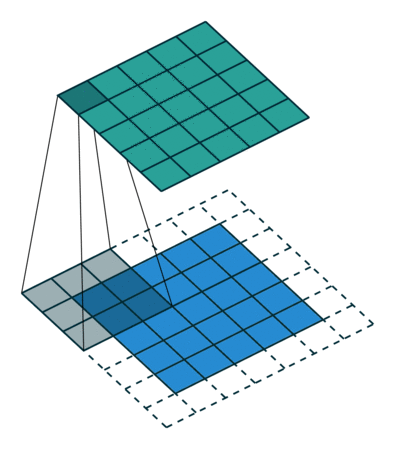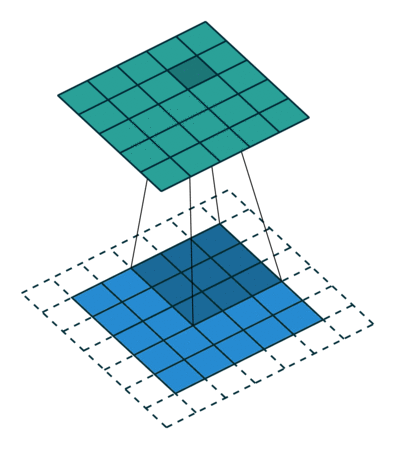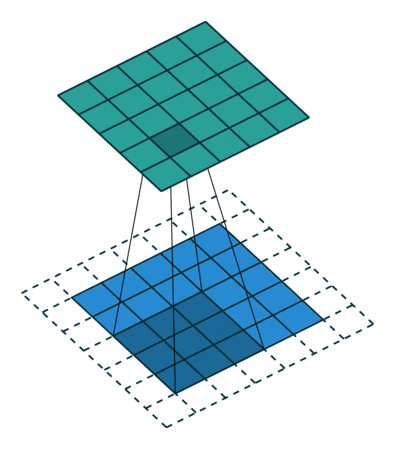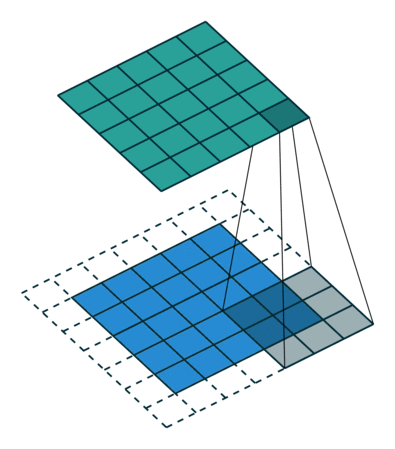
Wanneer we de afbeelding van 5x5x1 vergroten tot een afbeelding van 6x6x1 en vervolgens de kernel van 3x3x1 erop toepassen, zien we dat de geconvolueerde matrix blijkt afmetingen 5x5x1 te hebben. Vandaar de naam – Same Padding.
Aan de andere kant, als we dezelfde bewerking uitvoeren zonder padding, krijgen we een matrix te zien die afmetingen heeft van de kernel (3x3x1) zelf – Valid Padding.
De volgende repository bevat veel van dergelijke GIF’s die je zouden helpen een beter begrip te krijgen van hoe opvulling en paslengte samenwerken om resultaten te bereiken die relevant zijn voor onze behoeften.
Pooling Layer
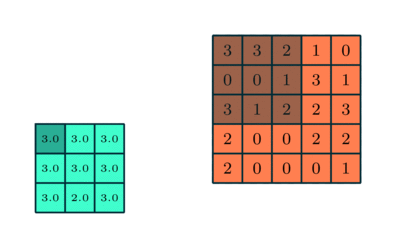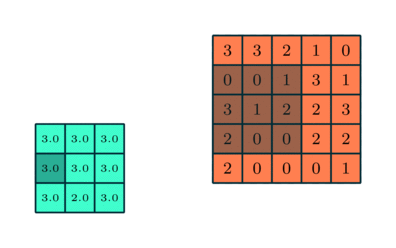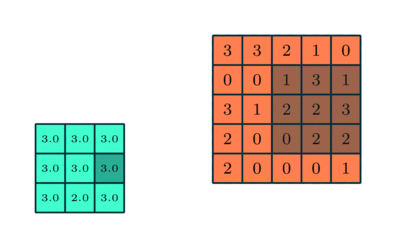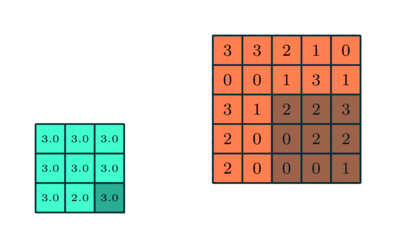
Vergelijkbaar met de convolutionele laag, de pooling-laag is verantwoordelijk voor het verkleinen van de ruimtelijke grootte van de Convolved Feature. Dit is om de rekenkracht die nodig is om de gegevens te verwerken te verminderen door het verminderen van de dimensionaliteit. Bovendien is het nuttig voor het extraheren van dominante kenmerken die rotatie- en positioneel-invariant zijn, waardoor het proces van effectieve training van het model behouden blijft.
Er zijn twee soorten pooling: max. Pooling en gemiddelde pooling. Max Pooling retourneert de maximale waarde van het gedeelte van de afbeelding dat door de kernel wordt bedekt. Aan de andere kant retourneert Average Pooling het gemiddelde van alle waarden van het gedeelte van de afbeelding dat door de kernel wordt bedekt.
Max Pooling werkt ook als een ruisonderdrukker. Het negeert de luidruchtige activeringen helemaal en voert ook de-ruis uit samen met dimensionaliteitsreductie. Aan de andere kant voert Average Pooling simpelweg dimensionaliteitsreductie uit als een ruisonderdrukkingsmechanisme. Daarom kunnen we zeggen dat Max Pooling veel beter presteert dan gemiddelde pooling.
De convolutionele laag en de pooling-laag vormen samen de i-de laag van een convolutioneel neuraal netwerk. Afhankelijk van de complexiteit van de afbeeldingen, kan het aantal van dergelijke lagen worden verhoogd om nog meer details op laag niveau vast te leggen, maar dit gaat ten koste van meer rekenkracht.
Nadat we het bovenstaande proces hebben doorlopen, hebben we heeft het model met succes in staat gesteld de functies te begrijpen. Verderop gaan we de uiteindelijke uitvoer afvlakken en voor classificatiedoeleinden naar een normaal neuraal netwerk sturen.
Classificatie – Volledig verbonden laag (FC-laag)

Het toevoegen van een volledig verbonden laag is een (meestal) goedkope manier om niet-lineaire combinaties te leren van de kenmerken op hoog niveau, zoals weergegeven door de uitvoer van de convolutionele laag. De Fully-Connected-laag leert een mogelijk niet-lineaire functie in die ruimte.
Nu we ons invoerbeeld hebben omgezet in een geschikte vorm voor onze Multi-Level Perceptron, zullen we het beeld afvlakken tot een kolom vector. De afgeplatte output wordt naar een feed-forward neuraal netwerk gevoerd en backpropagation wordt toegepast op elke iteratie van training. Over een reeks van tijdperken is het model in staat onderscheid te maken tussen dominerende en bepaalde low-level kenmerken in afbeeldingen en deze te classificeren met behulp van de Softmax Classification-techniek.
Er zijn verschillende architecturen van CNN’s beschikbaar die een sleutelrol speelden in het bouwen van algoritmen die AI als geheel aandrijven en zullen aandrijven in de nabije toekomst. Sommigen van hen zijn hieronder opgesomd:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
