La inteligencia artificial ha sido testigo de un crecimiento monumental en la reducción de la brecha entre las capacidades de los humanos y las máquinas. Tanto los investigadores como los entusiastas trabajan en numerosos aspectos del campo para hacer que sucedan cosas increíbles. Una de estas áreas es el dominio de la visión por computadora.
La agenda para este campo es permitir que las máquinas vean el mundo como lo hacen los humanos, lo perciban de manera similar e incluso usen el conocimiento para una multitud de tareas como Imágenes & Reconocimiento de video, Análisis de imágenes & Clasificación, Recreación de medios, Sistemas de recomendación, Procesamiento del lenguaje natural, etc. Los avances en Visión por Computadora con Deep Learning se ha construido y perfeccionado con el tiempo, principalmente sobre un algoritmo en particular: una Red Neural Convolucional.
Introducción

Una red neuronal convolucional (ConvNet / CNN) es un aprendizaje profundo algoritmo que puede tomar una imagen de entrada, asignar importancia (aprendizaje e pesos y sesgos) a varios aspectos / objetos de la imagen y poder diferenciar unos de otros. El preprocesamiento requerido en una ConvNet es mucho menor en comparación con otros algoritmos de clasificación. Mientras que en los métodos primitivos los filtros se diseñan a mano, con suficiente entrenamiento, las ConvNets tienen la capacidad de aprender estos filtros / características.
La arquitectura de una ConvNet es análoga a la del patrón de conectividad de las neuronas en el humano. Brain y se inspiró en la organización de Visual Cortex. Las neuronas individuales responden a los estímulos solo en una región restringida del campo visual conocida como campo receptivo. Una colección de estos campos se superponen para cubrir toda el área visual.
¿Por qué ConvNets sobre redes neuronales de avance?

Una imagen no es más que una matriz de valores de píxeles, ¿verdad? Entonces, ¿por qué no aplanar la imagen (por ejemplo, una matriz de imagen de 3×3 en un vector de 9×1) y alimentarla a un perceptrón multinivel para fines de clasificación? Uh … no realmente.
En casos de imágenes binarias extremadamente básicas, el método puede mostrar una puntuación de precisión promedio mientras realiza la predicción de clases, pero tendría poca o ninguna precisión cuando se trata de imágenes complejas que tienen dependencias de píxeles
Una ConvNet es capaz de capturar con éxito las dependencias espaciales y temporales en una imagen mediante la aplicación de filtros relevantes. La arquitectura se adapta mejor al conjunto de datos de imágenes debido a la reducción en el número de parámetros involucrados y la reutilización de pesos. En otras palabras, la red se puede entrenar para comprender mejor la sofisticación de la imagen.
Imagen de entrada

En la figura, tenemos una imagen RGB que ha sido separada por sus tres planos de color: rojo, verde, y azul. Hay varios espacios de color de este tipo en los que existen imágenes: escala de grises, RGB, HSV, CMYK, etc.
Puede imaginar lo intensivos que serían las cosas computacionalmente una vez que las imágenes alcanzan dimensiones, digamos 8K (7680 × 4320). El papel de ConvNet es reducir las imágenes a una forma que sea más fácil de procesar, sin perder características que son críticas para obtener una buena predicción. Esto es importante cuando vamos a diseñar una arquitectura que no solo sea buena para aprender características, sino que también sea escalable a conjuntos de datos masivos.
Capa de convolución: el núcleo
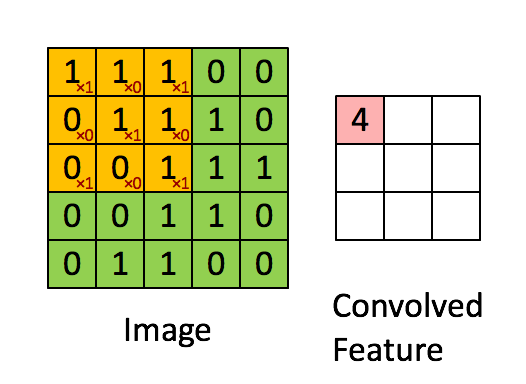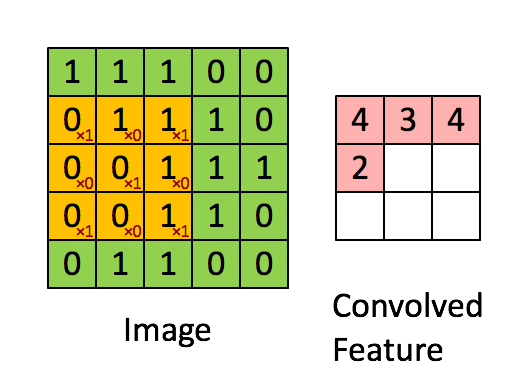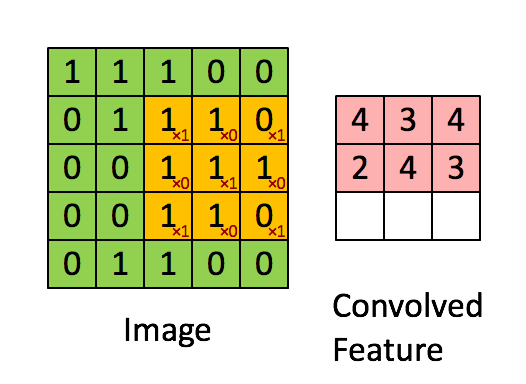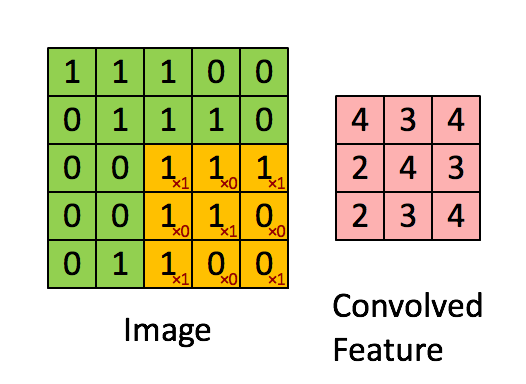
Imagen Dimensiones = 5 (Alto) x 5 (Ancho) x 1 (Número de canales, por ejemplo, RGB)
En la demostración anterior, la sección verde se asemeja a nuestra imagen de entrada de 5x5x1, I. El elemento involucrado en el transporte La operación de convolución en la primera parte de una capa convolucional se llama Kernel / Filter, K, representada en color amarillo. Hemos seleccionado K como una matriz de 3x3x1.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
El kernel cambia 9 veces debido a Stride Length = 1 (Non-Strided), cada vez que se realiza una matriz operación de multiplicación entre K y la parte P de la imagen sobre la que se cierne el núcleo.

El filtro se mueve hacia la derecha con un determinado valor de zancada hasta que analiza el ancho completo. Continuando, salta al principio (izquierda) de la imagen con el mismo valor de Stride y repite el proceso hasta que se recorre toda la imagen.
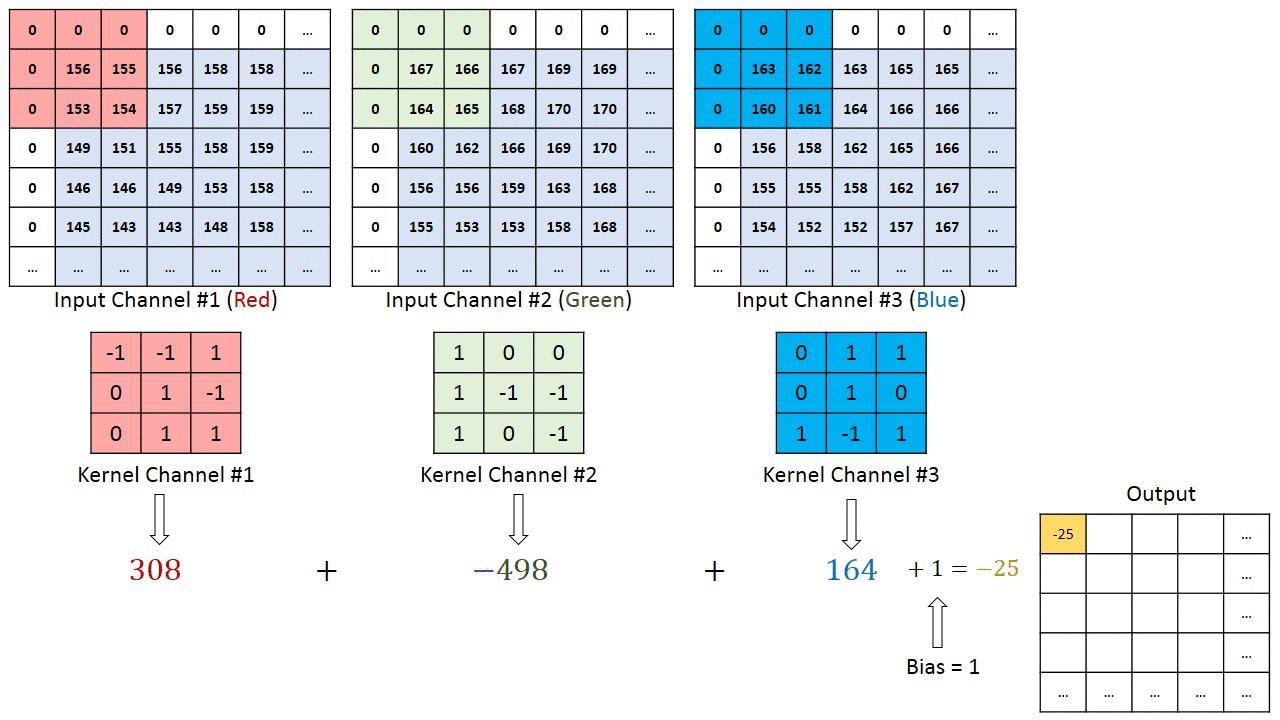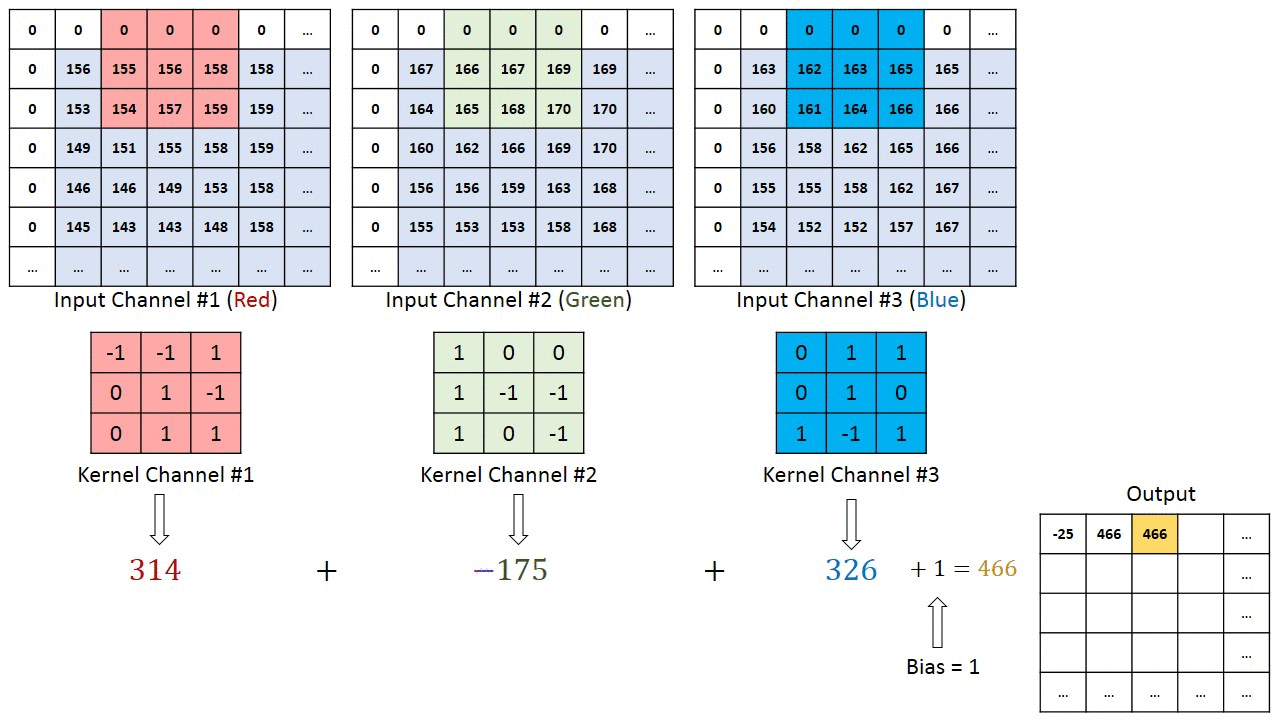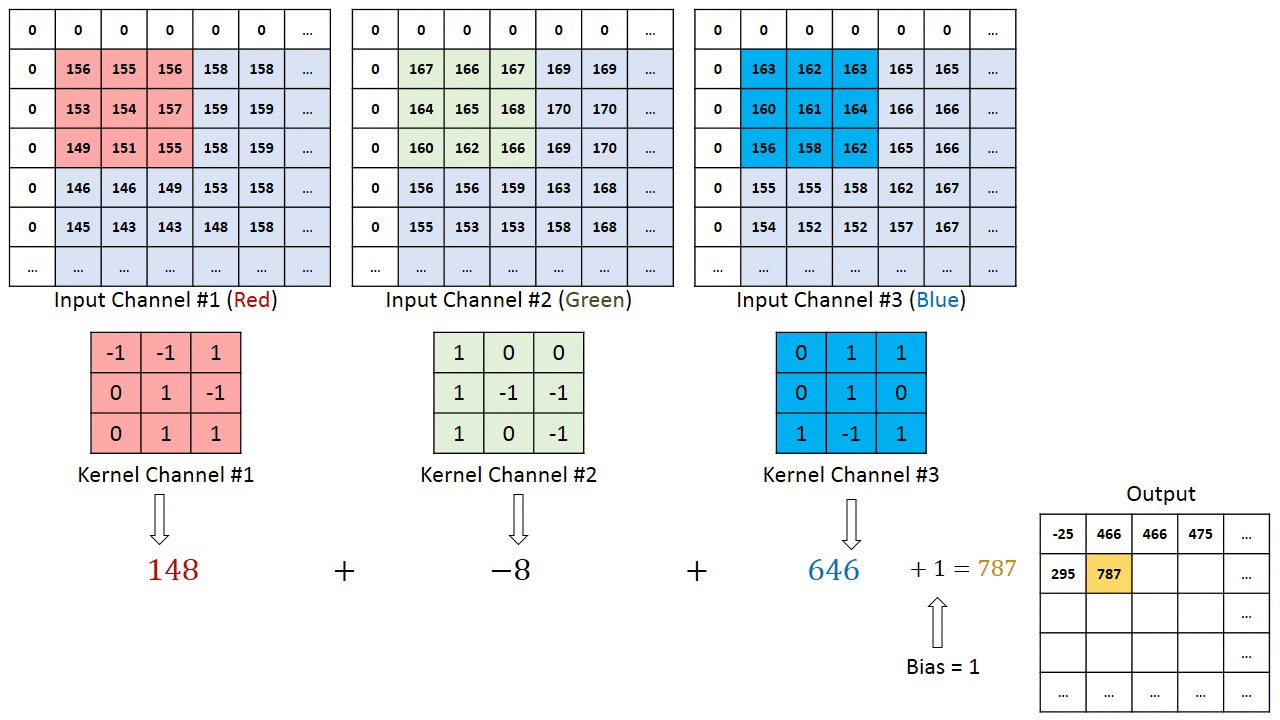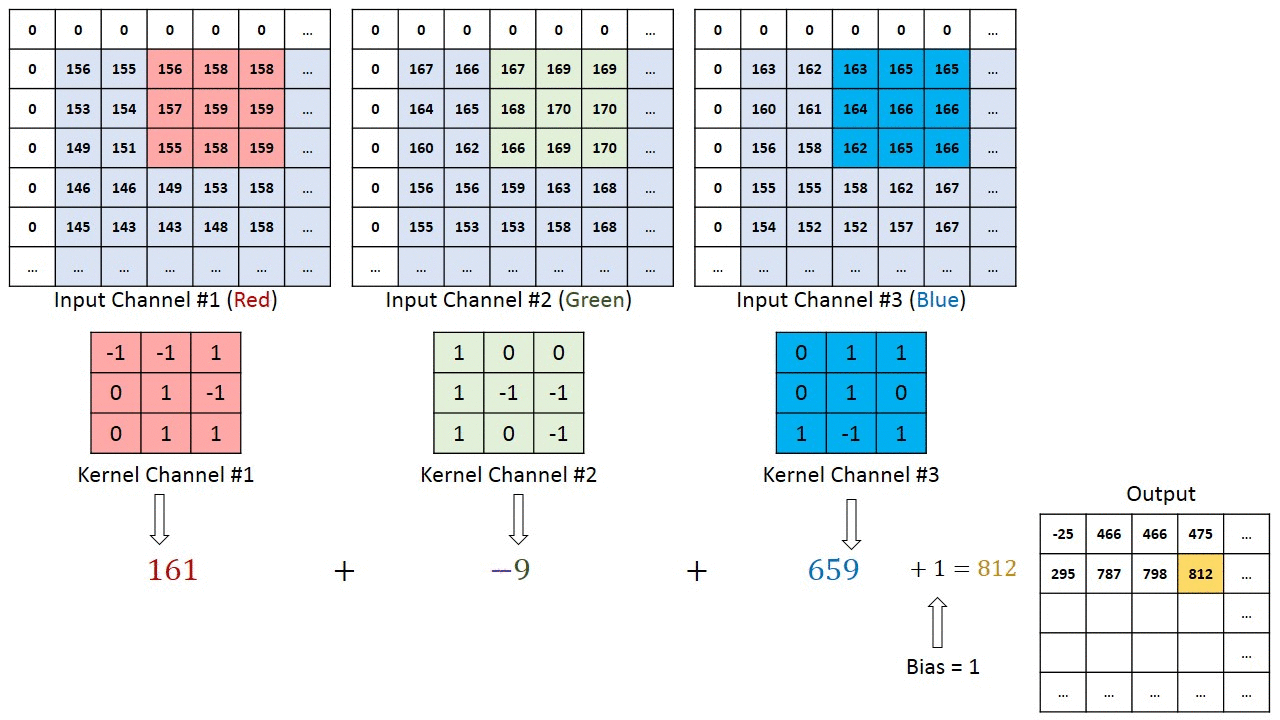
En el caso de imágenes con múltiples canales (por ejemplo, RGB ), el Kernel tiene la misma profundidad que la imagen de entrada. La multiplicación de matrices se realiza entre Kn e In stack (;;) y todos los resultados se suman con el sesgo para darnos una salida de función convolucionada de canal de una profundidad aplastada.
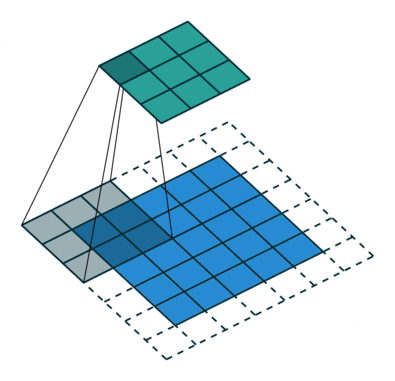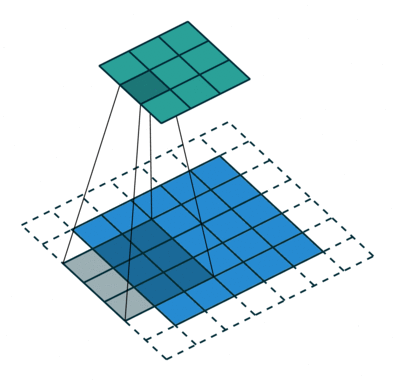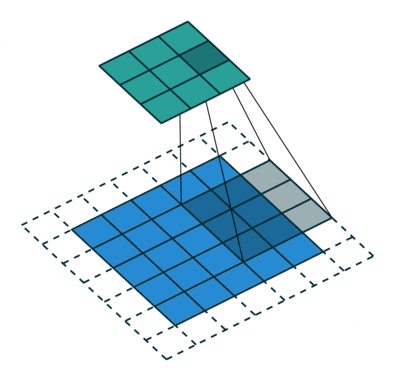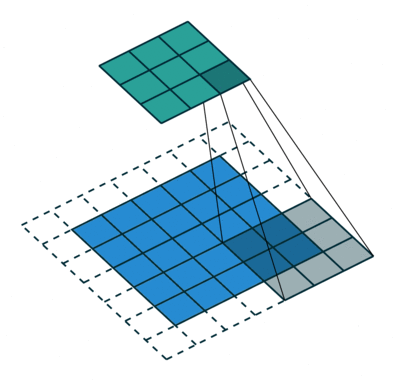
El objetivo de la operación de convolución es extraer las características de alto nivel, como los bordes, de la imagen de entrada. No es necesario que las ConvNets se limiten a una sola capa convolucional. Convencionalmente, el primer ConvLayer es responsable de capturar las características de bajo nivel, como los bordes, el color, la orientación del degradado, etc. Con capas agregadas, la arquitectura se adapta también a las características de alto nivel, brindándonos una red que tiene una comprensión completa. de imágenes en el conjunto de datos, similar a como lo haríamos nosotros.
Hay dos tipos de resultados para la operación: uno en el que la función convolucionada se reduce en dimensionalidad en comparación con la entrada, y el otro en el que la dimensionalidad aumenta o permanece igual. Esto se hace aplicando Relleno válido en el caso del primero, o Mismo relleno en el caso del segundo.
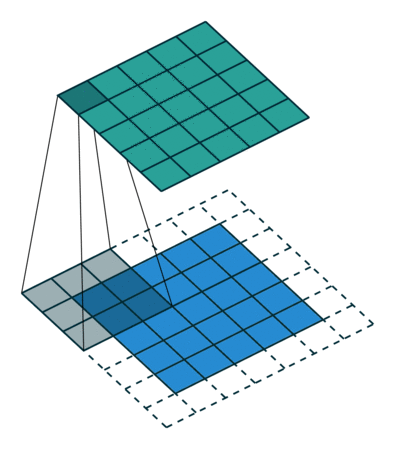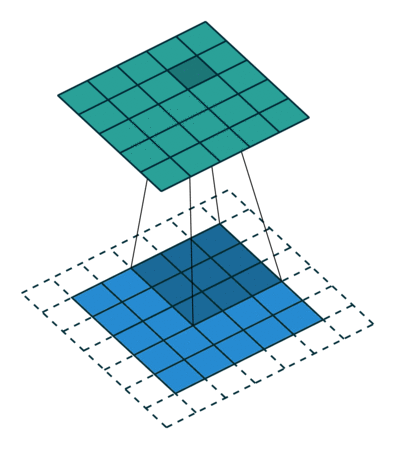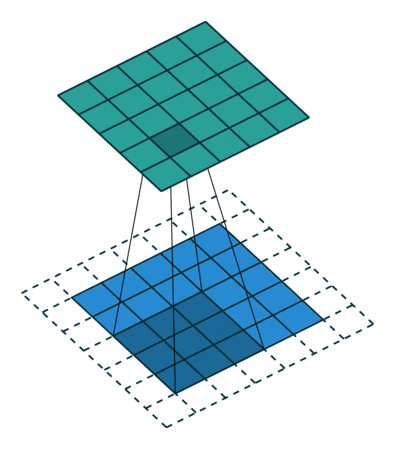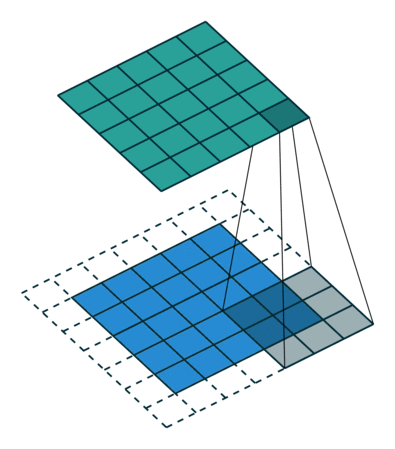
Cuando aumentamos la imagen de 5x5x1 en una imagen de 6x6x1 y luego aplicamos el kernel de 3x3x1 sobre ella, encontramos que el La matriz convolucionada resulta ser de dimensiones 5x5x1. De ahí el nombre – Mismo relleno.
Por otro lado, si realizamos la misma operación sin relleno, se nos presenta una matriz que tiene las dimensiones del propio Kernel (3x3x1) – Relleno válido.
El siguiente repositorio alberga muchos GIF de este tipo que lo ayudarían a comprender mejor cómo el relleno y la longitud de zancada funcionan juntos para lograr resultados relevantes para nuestras necesidades.
Capa de agrupación
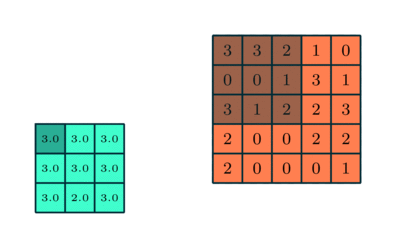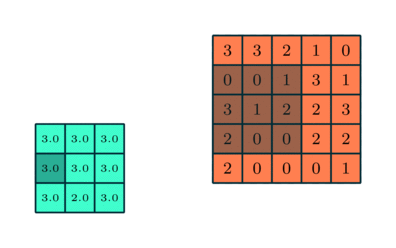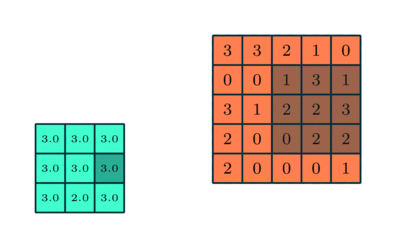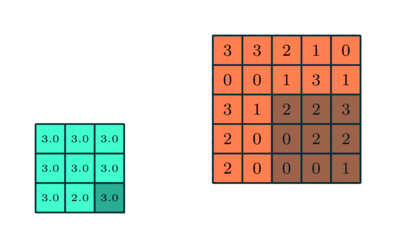
Similar a la capa convolucional, la capa agrupación es responsable de reducir el tamaño espacial de la Entidad Convolucionada. Esto es para disminuir la potencia computacional requerida para procesar los datos a través de la reducción de dimensionalidad. Además, es útil para extraer características dominantes que son invariantes en rotación y posición, manteniendo así el proceso de entrenamiento efectivo del modelo.
Hay dos tipos de Pooling: Max Pooling y Average Pooling. Max Pooling devuelve el valor máximo de la parte de la imagen cubierta por el Kernel. Por otro lado, la agrupación promedio devuelve el promedio de todos los valores de la parte de la imagen cubierta por el kernel.
La agrupación máxima también funciona como un supresor de ruido. Descarta las activaciones ruidosas por completo y también realiza la eliminación de ruido junto con la reducción de dimensionalidad. Por otro lado, la agrupación media simplemente realiza la reducción de dimensionalidad como un mecanismo de supresión de ruido. Por lo tanto, podemos decir que la agrupación máxima funciona mucho mejor que la agrupación promedio.
La capa convolucional y la capa de agrupación, juntas forman la i-ésima capa de una red neuronal convolucional. Dependiendo de las complejidades de las imágenes, el número de capas de este tipo puede incrementarse para capturar detalles de bajo nivel aún más, pero a costa de más poder computacional.
Después de pasar por el proceso anterior, tenemos Habilitado con éxito el modelo para comprender las características. Continuando, vamos a aplanar la salida final y alimentarla a una red neuronal normal para fines de clasificación.
Clasificación: capa totalmente conectada (capa FC)

Agregar una capa completamente conectada es una forma (generalmente) económica de aprender combinaciones no lineales de las características de alto nivel representadas por la salida de la capa convolucional. La capa Fully-Connected está aprendiendo una función posiblemente no lineal en ese espacio.
Ahora que hemos convertido nuestra imagen de entrada en una forma adecuada para nuestro perceptrón multinivel, aplanaremos la imagen en un vector de columna. La salida aplanada se alimenta a una red neuronal de retroalimentación y la propagación inversa se aplica a cada iteración del entrenamiento. A lo largo de una serie de épocas, el modelo es capaz de distinguir entre las características dominantes y ciertas características de bajo nivel en las imágenes y clasificarlas utilizando la técnica de clasificación Softmax.
Hay varias arquitecturas de CNN disponibles que han sido clave en la construcción de algoritmos que impulsan y deben impulsar la IA en su conjunto en el futuro previsible. Algunos de ellos se enumeran a continuación:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
