Når det kommer til læring, er der generelt to tilgange, man kan tage: du kan enten gå bredt, og prøv at dække så meget af spektret af et felt som muligt, ellers kan du gå dybt og prøve at blive virkelig, virkelig specifik med det emne, du lærer. De fleste gode elever ved, at alt hvad du lærer i livet til en vis grad – fra algoritmer til grundlæggende livsfærdigheder – involverer en kombination af disse to tilgange.
Det samme gælder datalogi, problemløsning, og datastrukturer. Sidste uge dykkede vi dybt ned i første dybdesøgning og lærte, hvad det betyder at faktisk krydse gennem et binært søgetræ. Nu hvor vi er gået dybt, er det fornuftigt for os at gå bredt og forstå den anden almindelige træovergangsstrategi.
Med andre ord er det det øjeblik, du alle har ventet på: det er tid at nedbryde det grundlæggende i bredden-første søgning!
En af de bedste måder at forstå, hvad bredde-første søgning (BFS) er, er ved at forstå, hvad det ikke er. Det vil sige, hvis vi sammenligner BFS med DFS, vil det være meget lettere for os at holde dem lige i vores hoveder. Så lad os opdatere vores hukommelse om dybde-første søgning, før vi går videre.
Vi ved, at dybde-første søgning er processen med at krydse ned gennem en gren af et træ, indtil vi kommer til et blad, og derefter arbejde os tilbage til “trunk” på træet. Med andre ord betyder implementering af en DFS at krydse ned gennem undertrærne til et binært søgetræ.
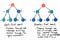
Okay, så hvordan går bredde-først søge sammenlignet med det? Nå, hvis vi tænker over det, er det eneste virkelige alternativ til at rejse ned ad en gren af et træ og derefter en anden at rejse ned ad træet sektion for sektion – eller niveau for niveau. Og det er præcis, hvad BFS er !
Bredde-første søgning involverer søgning gennem et træ et niveau ad gangen.
Vi krydser først et helt niveau af børneknuder, før du går videre til krydsning gennem børnebarneknuderne. Og vi krydser gennem et helt niveau af børnebørns knudepunkter, inden vi fortsætter med at krydse gennem oldebarns noder.
Okay, det virker ret klart. Hvad skelner der ellers mellem de to forskellige typer trætransversalgoritmer? Nå, vi har allerede dækket forskellene i procedurerne for disse to algoritmer. Lad os tænke på det andet vigtige aspekt, som vi endnu ikke har talt om: implementering.
Lad os først starte med det, vi kender. Hvordan gik vi i gang med at implementere dybde-første søgning i sidste uge? Du husker måske, at vi lærte tre forskellige metoder – ordre, postordre og forudbestilling – til at søge gennem et træ ved hjælp af DFS. Alligevel var der noget super sejt over, hvor ens disse tre implementeringer var; de kunne hver især blive ansat ved hjælp af rekursion. Vi ved også, at da DFS kan skrives som en rekursiv funktion, kan de få opkaldsstakken til at vokse så stor som den længste sti i træet.
Der var dog en ting, jeg forlod ud i sidste uge, der synes godt at bringe op nu (og måske er det endda en smule indlysende!): opkaldstakken implementerer faktisk en stakdatastruktur. Kan du huske dem? Vi lærte om stakke for et stykke tid siden, men her er de igen og dukker op overalt!
Den virkelig interessante ting ved at implementere dybde-første søgning ved hjælp af en stak er, at når vi krydser gennem undertrærne til en binært søgetræ, hver af de noder, som vi “kontrollerer” eller “besøger”, føjes til stakken. Når vi når en bladknude – en knude, der ikke har børn – begynder vi at sprænge knudepunkterne fra toppen af stakken. Vi ender ved rodknudepunktet igen og kan derefter fortsætte med at krydse det næste undertræ.

I eksempel på DFS-træet ovenfor bemærker du, at knudepunkterne 2, 3 og 4 alle føjes til toppen af stakken. Når vi kommer til “slutningen” af det subtræ – det vil sige når vi når bladknudepunkterne på 3 og 4 – begynder vi at sprænge disse knudepunkter fra vores stak af “knudepunkter at besøge”.Du kan se, hvad der i sidste ende vil ske med det rigtige undertræ: knudepunkterne, der skal besøges, skubbes på opkaldstakken, vi besøger dem og springer dem systematisk ud af stakken.
Til sidst, når vi Vi har besøgt både venstre og højre undertræ, vi er tilbage ved rodknudepunktet med intet tilbage at kontrollere, og vores opkaldsstak vil være tom.
Så vi skulle være i stand til at bruge en stak struktur og gør noget lignende med vores BFS-implementering … ikke? Jeg ved ikke, om det fungerer, men jeg tror, det vil være nyttigt i det mindste at starte med at tegne den algoritme, vi vil implementere, og se, hvor langt vi kan komme med den.
Lad os prøve:

Okay, så vi har en graf til venstre, som vi implementerede DFS i sidste uge. Hvordan kan vi bruge en BFS-algoritme på den i stedet?
Nå, for at starte, ved vi, at vi først vil kontrollere rodnoden. Det er den eneste node, vi oprindeligt har adgang til, og så “peger” vi på node f.
Okay, nu bliver vi nødt til at kontrollere børnene til denne rodknude.
Vi vil kontrollere det ene barn efter det andet, så lad os først gå til det venstre barn – node d er den node, vi “peger” på nu (og den eneste node, vi har adgang til).
Derefter vil vi gå til den rigtige underordnede node.
Uh åh. Vent, rodnoden er ikke engang tilgængelig for os mere! Og vi kan ikke bevæge os baglæns, fordi binære træer ikke har omvendte links! Hvordan skal vi komme til den rigtige barneknude? Og … åh nej, venstre barneknude d og højre barneknudepunkt k er slet ikke forbundet. Så det betyder, at det er umuligt for os at hoppe fra et barn til et andet, fordi vi ikke har adgang til noget undtagen node d’s børn.
Åh kære. Vi kom ikke meget langt, gjorde vi? Vi bliver nødt til at finde ud af en anden metode til løsning af dette problem. Vi er nødt til at finde ud af en eller anden måde at implementere en træpasning, der lader os gå i træet i niveau rækkefølge. Det vigtigste, vi skal huske på, er dette:
Vi er nødt til at holde en henvisning til alle børneknudepunkter i hver node, vi besøger. Ellers kan vi aldrig gå tilbage til dem senere og besøge dem!
Jo mere jeg tænker på det, jo mere har jeg lyst til det er som om vi vil holde en liste over alle de noder, vi stadig har brug for at kontrollere, er det ikke? Og i det øjeblik, jeg vil holde en liste over noget, springer mit sind straks til en datastruktur især: en kø, selvfølgelig!
Lad os se, om køer kan hjælpe os med vores BFS-implementering.
Køer til undsætning!
Som det viser sig, er en stor forskel i dybde-første søgning og bredde-første søgning datastrukturen, der bruges til at implementere begge disse meget forskellige algoritmer.
Mens DFS bruger en stakdatastruktur, læner BFS sig til kødatastrukturen. Det pæne ved at bruge køer er, at det løser netop det problem, vi opdagede tidligere: det giver os mulighed for at holde en henvisning til noder, som vi vil vende tilbage til, selvom vi ikke har kontrolleret / besøgt dem endnu.
Vi tilføjer noder, som vi har opdaget – men endnu ikke har besøgt – til vores kø og vender tilbage til dem senere.
Et almindeligt udtryk for noder, som vi tilføjer til vores kø, er opdagede noder; en opdaget knude er en, som vi føjer til vores kø, hvis placering vi kender, men vi har endnu ikke besøgt. Faktisk er det netop det, der gør en kø til den perfekte struktur til løsning af BFS-problemet.

I grafen til venstre starter vi med at tilføje rodnoden til vores kø, da det er den eneste node, vi nogensinde har har adgang til (i det mindste oprindeligt) i et træ. Dette betyder, at rodknudepunktet er den eneste opdagede knude, der starter.
Når vi har mindst en knudepunkt, kan vi starte processen med at besøge noder og tilføje referencer til deres børneknuder i vores kø.
Okay, så alt dette lyder måske lidt forvirrende. Og det er okay! Jeg tror, det vil være meget lettere at forstå, hvis vi deler det op i enklere trin.
For hver node i vores kø – altid startende med rodnoden – vil vi gerne gøre tre ting:
- Besøg noden, hvilket normalt kun betyder at udskrive dens værdi.
- Føj nodens venstre barn til vores kø.
- Tilføj nodens højre barn til vores kø.
Når vi først har gjort disse tre ting, kan vi fjerne noden fra vores kø, fordi vi ikke har brug for det mere!Vi er grundlæggende nødt til at fortsætte med at gøre dette gentagne gange, indtil vi kommer til det punkt, hvor vores kø er tom.
Okay, lad os se på dette i aktion!
I nedenstående graf starter vi slukket med rodnoden, node f, som den eneste opdagede node. Kan du huske vores tre trin? Lad os gøre dem nu:
- Vi besøger node f og udskriver dens værdi.
- Vi sætter en henvisning til dens venstre barn, node d.
- Vi sætter en henvisning til dets højre barn, node k.
Og så fjerner vi node f fra vores kø!

Den næste node foran køen er node d. Igen, de samme tre trin her: Udskriv værdien, tilføj sit venstre barn, tilføj sit højre barn, og fjern det derefter fra køen.
Vores kø har nu henvisninger til knudepunkterne k, b og e . Hvis vi fortsætter med at gentage denne proces systematisk, bemærker vi, at vi faktisk krydser grafen og udskriver noderne i niveau rækkefølge. Hurra! Det er præcis, hvad vi i første omgang ønskede at gøre.
Nøglen til, at dette fungerer så godt, er selve køstrukturen. Køer følger FIFO-princippet first-in, first-out (FIFO), hvilket betyder, at det, der først blev opsamlet, er det første element, der læses og fjernes fra køen.
Endelig, mens vi er om emnet køer, er det værd at nævne, at rumtidskompleksiteten af en BFS-algoritme også er relateret til den kø, vi bruger til at implementere den – hvem vidste, at køer ville komme tilbage for at være så nyttig, ikke?
Tidskompleksiteten af en BFS-algoritme afhænger direkte af, hvor lang tid det tager at besøge en node. Da den tid, det tager at læse en nodes værdi og opsamle dens børn, ikke ændrer sig baseret på noden, kan vi sige, at besøg på en node tager konstant tid eller, O (1) tid. Da vi kun besøger hver node i et BFS-træ gennemgange nøjagtigt en gang, afhænger den tid, det tager os at læse hver node, bare bare af, hvor mange noder der er i træet! Hvis vores træ har 15 knudepunkter, vil det tage os O (15); men hvis vores træ har 1500 noder, vil det tage os O (1500). Således tager tidskompleksiteten af en bred-første søgealgoritme lineær tid, eller O (n), hvor n er antallet af noder i træet.
Rumkompleksitet svarer til dette, har mere at gør med, hvor meget vores kø vokser og krymper, når vi tilføjer de noder, som vi skal kontrollere, til den. I værste fald kan vi potentielt omslutte alle noder i et træ, hvis de alle er børn af hinanden, hvilket betyder, at vi muligvis kan bruge så meget hukommelse, som der er noder i træet. Hvis køens størrelse kan vokse til at blive antallet af noder i træet, er pladskompleksiteten for en BFS-algoritme også lineær tid eller O (n), hvor n er antallet af noder i træet.
Dette er godt og godt, men ved du hvad jeg virkelig gerne vil gøre lige nu? Jeg vil faktisk skrive en af disse algoritmer! Lad os endelig omsætte al denne teori i praksis.
Kodning af vores første bredeste-første søgealgoritme
Vi har nået det! Vi skal endelig kode vores allerførste BFS-algoritme. Vi gjorde en lille smule af dette i sidste uge med DFS-algoritmer, så lad os også prøve at skrive en bredeste først-implementering af dette.
Du kan huske, at vi skrev dette i vanille JavaScript i sidste uge, så vi holder fast ved det igen for konsistens skyld. Hvis du har brug for en hurtig genopfriskning, besluttede vi at holde det enkelt og skrive vores node-objekter som almindelige gamle JavaScript-objekter (POJO’er) som denne:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
Okay, sejt. Et trin udført.
Men nu hvor vi kender til køer og er sikre på, at vi bliver nødt til at bruge en til at implementere denne algoritme … skal vi nok finde ud af, hvordan man gør det i JavaScript, ikke? Nå, som det viser sig, er det virkelig nemt at oprette et kølignende objekt i JS!
Vi kan bruge et array, som gør tricket ganske pænt:
Hvis vi ville gøre dette lidt mere avanceret, kunne vi sandsynligvis også oprette et Queue objekt, som muligvis har en praktisk funktion som top eller isEmpty; men indtil videre stoler vi på meget enkel funktionalitet.
Okay, lad os skrive denne hvalp! Vi opretter en levelOrderSearch -funktion, der optager et rootNode -objekt.
Awesome! Dette er faktisk … ret simpelt. Eller i det mindste meget enklere end jeg havde forventet at være. Alt, hvad vi laver her, er at bruge en while -sløjfe til at fortsætte med at udføre disse tre trin for at kontrollere en node, tilføje sit venstre barn og tilføje sit højre barn.Vi fortsætter med at gentage gennem queue array indtil alt er fjernet fra det, og dets længde er 0.
Fantastiske. Vores algoritmeekspertise er steget i luften på bare en dag! Ikke kun ved vi, hvordan vi skriver rekursive algoritmer for traversering af træer, men nu ved vi også, hvordan man skriver iterative. Hvem vidste, at algoritmiske søgninger kunne være så bemyndigende!
Ressourcer
Der er stadig meget at lære om bredeste-første søgning, og hvornår det kan være nyttigt. Heldigvis er der masser af ressourcer, der dækker oplysninger, som jeg ikke kunne passe ind i dette indlæg. Tjek et par af de rigtig gode nedenfor.
- DFS og BFS algoritmer ved hjælp af stakke og køer, professor Lawrence L. Larmore
- Algoritmen Breadth-First Search, Khan Akademi
- Datastruktur – Første gennemgang af bredde, TutorialsPoint
- Binært træ: Gennemgang af niveauordre, mycodeschool
- Bredde-første gennemgang af et træ, Computer Science Department of Boston University
