När det gäller lärande finns det i allmänhet två tillvägagångssätt man kan ta: man kan antingen gå bred, och försök att täcka så mycket av spektrumet av ett fält som möjligt, eller så kan du gå djupt och försöka bli riktigt, riktigt specifik med ämnet du lär dig. De flesta bra elever vet att till viss del allt du lär dig i livet – från algoritmer till grundläggande livsförmåga – involverar någon kombination av dessa två tillvägagångssätt.
Detsamma gäller datavetenskap, problemlösning, och datastrukturer. Förra veckan dök vi djupt in i djup-första sökningen och lärde oss vad det innebär att faktiskt korsa genom ett binärt sökträd. Nu när vi har gått djupt är det vettigt för oss att gå bredt och förstå den andra vanliga trädgenomgångsstrategin.
Med andra ord är det det ögonblick som ni alla har väntat på: det är dags att bryta ner grunderna i bredd-först-sökning!
Ett av de bästa sätten att förstå vad bredd-första-sökning (BFS) är, är att förstå vad det inte är. Det vill säga om vi jämför BFS med DFS blir det mycket lättare för oss att hålla dem raka i huvudet. Så låt oss uppdatera vårt minne av djup-först-sökning innan vi går vidare.
Vi vet att djup-första-sökning är processen att korsa ner genom en trädgren tills vi kommer till ett blad, och sedan arbeta oss tillbaka till ”stam” av trädet. Med andra ord innebär implementering av en DFS att korsa genom underträdet i ett binärt sökträd.
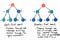
Okej, så hur gör bredd-först Sök, jämför med det? Tja, om vi tänker på det, är det enda verkliga alternativet att resa ner en gren av ett träd och sedan en annan att resa ner i trädet sektion för sektion – eller, nivå för nivå. Och det är precis vad BFS är !
Bredd-första sökning innebär sökning genom ett träd en nivå i taget.
Vi korsa genom en hel nivå av barnnoder först innan du går vidare för att korsa genom barnbarnsnoderna. Och vi går igenom en hel nivå av barnbarnsnoder innan vi går igenom barnbarnsnoder.
Okej, det verkar ganska tydligt. Vad skiljer mer mellan de två olika typerna av trädgenomgångsalgoritmer? Vi har redan täckt skillnaderna i procedurerna för dessa två algoritmer. Låt oss tänka på den andra viktiga aspekten som vi inte har pratat om ännu: implementering.
Låt oss först börja med det vi vet. Hur började vi genomföra djup-första sökningen förra veckan? Du kanske kommer ihåg att vi lärde oss tre olika metoder – beställning, postorder och förbeställning – för att söka genom ett träd med DFS. Ändå var det något super coolt med hur lika dessa tre implementeringar; de kunde var och en användas med rekursion. Vi vet också att eftersom DFS kan skrivas som en rekursiv funktion kan de få samtalsstapeln att växa så stor som den längsta vägen i trädet.
Det var dock en sak jag lämnade ut förra veckan som verkar bra att ta upp nu (och kanske är det till och med lite uppenbart!): samtalsstacken implementerar faktiskt en stackdatastruktur. Kommer du ihåg dem? Vi lärde oss om stackar för ett tag sedan, men här är de igen och dyker upp överallt!
Det riktigt intressanta med att implementera djup-första sökning med hjälp av en stack är att när vi går igenom underträd av en binärt sökträd, varje nod som vi ”kontrollerar” eller ”besöker” läggs till i stacken. När vi väl har nått en bladnod – en nod som inte har några barn – börjar vi poppa av noder från toppen av stacken. Vi hamnar vid rotnoden igen och kan sedan fortsätta att gå igenom nästa underträd.

I exempel på DFS-träd ovan ser du att noderna 2, 3 och 4 alla läggs till toppen av stapeln. När vi kommer till ”slutet” på det subtreetet – det vill säga när vi når bladnoderna 3 och 4 – börjar vi ta bort dessa noder från vår stack med ”noder att besöka”.Du kan se vad som så småningom kommer att hända med rätt underträd: noderna att besöka kommer att tryckas på samtalsstacken, vi kommer att besöka dem och systematiskt poppa dem från stacken.
Så småningom, när vi Vi har besökt både vänster och höger underträd, vi kommer tillbaka till rotnoden utan att det finns något kvar att kontrollera, och vår samtalsstack kommer att vara tom.
Så vi borde kunna använda en stapla strukturen och gör något liknande med vårt BFS-implementering … eller hur? Tja, jag vet inte om det kommer att fungera, men jag tror att det kommer att vara till hjälp att åtminstone börja med att rita ut algoritmen vi vill implementera och se hur långt vi kan komma med den.
Låt oss försöka:

Okej, så vi har en graf till vänster som vi implementerade DFS förra veckan. Hur kan vi använda en BFS-algoritm på den istället?
Tja, för att börja vet vi att vi först vill kontrollera rotnoden. Det är den enda noden vi har tillgång till från början, och så ”pekar” vi på noden f.
Okej, nu måste vi kontrollera barnen till denna rotnod.
Vi vill kontrollera det ena barnet efter det andra, så låt oss gå till det vänstra barnet först – nod d är den nod vi ”pekar” mot nu (och den enda noden vi har tillgång till).
Därefter vill vi gå till rätt barnnod.
Uh oh. Vänta, rotnoden är inte ens tillgänglig för oss längre! Och vi kan inte röra oss bakåt, för binära träd har inte omvända länkar! Hur ska vi komma till rätt barnnod? Och … åh nej, vänster barnnod d och högernod k är inte länkade alls. Så det betyder att det är omöjligt för oss att hoppa från ett barn till ett annat eftersom vi inte har tillgång till någonting utom för nods barn.
Åh kära. Vi kom inte så långt, eller hur? Vi måste ta reda på en annan metod för att lösa detta problem. Vi måste räkna ut något sätt att genomföra en trädkorsning som låter oss gå i trädet i jämn ordning. Det viktigaste vi måste komma ihåg är detta:
Vi måste ha en referens till alla barnnoder i varje nod som vi besöker. Annars kommer vi aldrig att kunna gå tillbaka till dem senare och besöka dem!
Ju mer jag tänker på det, desto mer känner jag mig för det är som om vi vill ha en lista över alla noder vi fortfarande behöver kontrollera, eller hur? Och i det ögonblick jag vill hålla en lista över något hoppar mitt sinne omedelbart till en datastruktur i synnerhet: en kö, förstås!
Låt oss se om köer kan hjälpa oss med vår BFS-implementering.
Köer till undsättning!
Som det visar sig är en stor skillnad i djup-första sökning och bredd-första sökning datastrukturen som används för att implementera båda dessa mycket olika algoritmer.
Medan DFS använder en stapeldatastruktur lutar BFS sig på ködatastrukturen. Det fina med att använda köer är att det löser själva problemet vi upptäckte tidigare: det låter oss behålla en referens till noder som vi vill komma tillbaka till, även om vi inte har kontrollerat / besökt dem ännu.
Vi lägger till noder som vi har upptäckt – men ännu inte besökt – i vår kö och kommer tillbaka till dem senare.
En vanlig term för noder som vi lägger till i vår kö är upptäckta noder; en upptäckt nod är en som vi lägger till i vår kö, vars plats vi känner till, men vi har ännu inte faktiskt besökt. I själva verket är det precis detta som gör en kö till den perfekta strukturen för att lösa BFS-problemet.

I diagrammet till vänster börjar vi med att lägga till rotnoden i vår kö, eftersom det är den enda noden vi någonsin ha åtkomst till (åtminstone initialt) i ett träd. Det betyder att rotnoden är den enda upptäckta noden som startar.
När vi har åtminstone en nod anslagen kan vi starta processen med att besöka noder och lägga till referenser till deras barnnoder i vår kö.
Okej, så allt detta låter kanske lite förvirrande. Och det är okej! Jag tror att det blir mycket lättare att förstå om vi bryter ner det i enklare steg.
För varje nod i vår kö – alltid med rotnoden – vi vill göra tre saker:
- Besök noden, vilket vanligtvis bara betyder att skriva ut dess värde.
- Lägg till nodens vänstra barn i vår kö.
- Lägg till nodens högra barn till vår kö.
När vi väl gjort dessa tre saker kan vi ta bort noden från vår kö, för vi behöver inte längre!Vi måste i grunden fortsätta göra detta upprepade gånger tills vi kommer till den punkt där vår kö är tom.
Okej, låt oss titta på detta i aktion!
I diagrammet nedan börjar vi av med rotnoden, nod f, som den enda upptäckta noden. Kommer du ihåg våra tre steg? Låt oss göra dem nu:
- Vi besöker nod f och skriver ut dess värde.
- Vi kommer att ange en referens till dess vänstra barn, nod d.
- Vi kommer att ange en referens till dess rätta barn, nod k.
Och sedan tar vi bort nod f från vår kö!

Nästa nod längst fram i kön är nod d. Återigen, samma tre steg här: skriv ut dess värde, lägg till sitt vänstra barn, lägg till sitt högra barn och ta sedan bort det från kön.
Vår kö har nu referenser till noder k, b och e . Om vi fortsätter att upprepa denna process systematiskt kommer vi att märka att vi faktiskt går igenom grafen och skriver ut noderna i nivåordning. Hurra! Det är precis vad vi ville göra i första hand.
Nyckeln till att detta fungerar så bra är köstrukturen. Köer följer principen först-in-först-ut (FIFO), vilket innebär att allt som inhämtades först är det första objektet som kommer att läsas och tas bort från kön.
Slutligen, medan vi är på ämnet köer, är det värt att nämna att en BFS-algoritms rymdtidskomplexitet också är relaterad till kön som vi använder för att implementera den – vem visste att köer skulle komma tillbaka för att vara så användbar, eller hur?
Tidskomplexiteten för en BFS-algoritm beror direkt på hur mycket tid det tar att besöka en nod. Eftersom den tid det tar att läsa en nods värde och enqueue dess barn inte ändras baserat på noden, kan vi säga att besöka en nod tar konstant tid, eller, O (1) tid. Eftersom vi bara besöker varje nod i en BFS-trädgenomgång exakt en gång beror den tid det tar att läsa varje nod egentligen bara på hur många noder det finns i trädet! Om vårt träd har 15 noder tar det oss O (15); men om vårt träd har 1500 noder tar det oss O (1500). Således tar tidskomplexiteten för en bredd-första sökalgoritm linjär tid, eller O (n), där n är antalet noder i trädet.
Rymdkomplexitet liknar detta, har mer att gör med hur mycket vår kö växer och krymper när vi lägger till de noder som vi behöver kontrollera för den. I värsta fall skulle vi eventuellt kunna täcka alla noder i ett träd om de alla är varandras barn, vilket innebär att vi möjligen kan använda så mycket minne som det finns noder i trädet. Om storleken på kön kan växa till antalet noder i trädet är utrymmets komplexitet för en BFS-algoritm också linjär tid, eller O (n), där n är antalet noder i trädet.
Det här är allt bra och bra, men vet du vad jag verkligen skulle vilja göra just nu? Jag vill faktiskt skriva en av dessa algoritmer! Låt oss äntligen omsätta all denna teori i praktiken.
Kodning av vår första bredd-första sökalgoritm
Vi har gjort det! Vi kommer äntligen att koda vår allra första BFS-algoritm. Vi gjorde lite av detta förra veckan med DFS-algoritmer, så låt oss försöka skriva en bredd-första sökimplementering av detta också.
Du kanske kommer ihåg att vi skrev detta i vanilj JavaScript förra veckan, så vi kommer att hålla fast vid det igen för konsekvensens skull. Om du behöver en snabb uppdatering bestämde vi oss för att hålla det enkelt och skriva våra nodobjekt som vanliga gamla JavaScript-objekt (POJO), så här:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
Okej, coolt. Ett steg gjort.
Men nu när vi känner till köer och är säkra på att vi måste använda en för att implementera denna algoritm … borde vi nog ta reda på hur man gör det i JavaScript, eller hur? Som det visar sig är det väldigt enkelt att skapa ett köliknande objekt i JS!
Vi kan använda en matris, vilket gör tricket ganska snyggt:
Om vi ville göra detta lite snyggare, skulle vi förmodligen också kunna skapa ett Queue -objekt, som kan ha praktisk funktion som top eller isEmpty; men för närvarande litar vi på mycket enkel funktionalitet.
Okej, låt oss skriva den här valpen! Vi skapar en levelOrderSearch -funktion som tar in ett rootNode -objekt.
Fantastiskt! Detta är faktiskt … ganska enkelt. Eller åtminstone mycket enklare än jag förväntade mig att det skulle bli. Allt vi gör här är att använda en while -slinga för att fortsätta göra de tre stegen för att kontrollera en nod, lägga till sitt vänstra barn och lägga till sitt högra barn.Vi fortsätter att itera genom queue -matrisen tills allt har tagits bort från den och dess längd är 0.
Fantastisk. Vår algoritmkompetens har skjutit i höjden på bara en dag! Inte bara vet vi hur man skriver rekursiva trädgenomgångsalgoritmer, utan nu vet vi också hur man skriver iterativa. Vem visste att algoritmiska sökningar kan vara så bemyndigande!
Resurser
Det finns fortfarande mycket att lära sig om bredd-först-sökning och när det kan vara användbart. Lyckligtvis finns det massor av resurser som täcker information som jag inte kunde passa in i det här inlägget. Kolla in några av de riktigt bra nedan.
- DFS- och BFS-algoritmer med staplar och köer, professor Lawrence L. Larmore
- Algoritmen Breadth-First Search, Khan Akademi
- Datastruktur – Breadth First Traversal, TutorialsPoint
- Binary tree: Level Order Traversal, mycodeschool
- Breadth-First Traversal of a Tree, Data Science Department of Boston University
