Jeśli chodzi o naukę, ogólnie można zastosować dwa podejścia: możesz szerokie i spróbuj objąć jak najwięcej spektrum dziedziny, lub możesz sięgnąć głęboko i spróbować uzyskać naprawdę, bardzo konkretny temat, którego się uczysz. Większość dobrych uczniów wie, że do pewnego stopnia wszystko, czego uczysz się w życiu – od algorytmów po podstawowe umiejętności życiowe – zawiera kombinację tych dwóch podejść.
To samo dotyczy informatyki, rozwiązywania problemów, i struktury danych. W zeszłym tygodniu zagłębiliśmy się w przeszukiwanie najpierw w głąb i dowiedzieliśmy się, co to właściwie znaczy przechodzić przez binarne drzewo wyszukiwania. Teraz, gdy zaszliśmy głęboko, sensowne jest, abyśmy poszli szeroko i zrozumieli inną popularną strategię przechodzenia po drzewie.
Innymi słowy, jest to moment, na który wszyscy czekali: nadszedł czas aby rozbić podstawy wyszukiwania wszerz!
Jednym z najlepszych sposobów zrozumienia, czym dokładnie jest przeszukiwanie wszerz (BFS), jest zrozumienie, czym ono nie jest. Oznacza to, że jeśli porównamy BFS z DFS, znacznie łatwiej będzie nam utrzymać je w pamięci. Więc odświeżmy naszą pamięć wyszukiwania w głąb, zanim przejdziemy dalej.
Wiemy, że przeszukiwanie w głąb to proces przechodzenia w dół przez jedną gałąź drzewa, aż dotrzemy do liścia, a następnie wracamy do „pnia” drzewa. Innymi słowy, implementacja DFS oznacza przechodzenie w dół przez poddrzewa binarnego drzewa wyszukiwania.
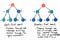
OK, więc jak to zrobić wszerz porównać wyszukiwania z tym? Cóż, jeśli się nad tym zastanowić, jedyną realną alternatywą dla podróżowania w dół jednej gałęzi drzewa, a potem kolejną, jest podróżowanie w dół po sekcji drzewa – lub poziom po poziomie. I właśnie tym jest BFS !
Przeszukiwanie wszerz polega na przeszukiwaniu drzewa po jednym poziomie na raz.
najpierw przechodź przez jeden cały poziom węzłów potomnych, zanim przejdziesz do przejścia przez węzły wnuków. A my przechodzimy przez cały poziom węzłów wnuków, zanim przejdziemy do węzłów prawnuków.
W porządku, to wydaje się dość jasne. Co jeszcze odróżnia dwa różne typy algorytmów przechodzenia po drzewie? Cóż, omówiliśmy już różnice w procedurach tych dwóch algorytmów. Pomyślmy o innym ważnym aspekcie, o którym jeszcze nie rozmawialiśmy: o wdrażaniu.
Najpierw zacznijmy od tego, co wiemy. Jak w zeszłym tygodniu wprowadziliśmy wyszukiwanie w głąb? Być może pamiętasz, że nauczyliśmy się trzech różnych metod – inorder, postorder i preorder – przeszukiwania drzewa przy użyciu DFS. Jednak było coś super fajnego w tym, jak podobne są te trzy implementacje; każdy z nich mógłby być wykorzystany przy użyciu rekurencji. Wiemy również, że skoro DFS można zapisać jako funkcję rekurencyjną, mogą one spowodować, że stos wywołań będzie tak duży, jak najdłuższa ścieżka w drzewie.
Zostawiłem jednak jedną rzecz w zeszłym tygodniu, które wydaje się dobre do omówienia teraz (i może jest to nawet trochę oczywiste!): stos wywołań faktycznie implementuje strukturę danych stosu. Pamiętasz te? Dowiedzieliśmy się o stosach jakiś czas temu, ale znowu są tutaj, pojawiają się w każdym miejscu!
Naprawdę interesującą rzeczą w implementowaniu wyszukiwania w głąb przy użyciu stosu jest to, że gdy przechodzimy przez poddrzewa a binarne drzewo wyszukiwania, każdy z węzłów, które „sprawdzamy” lub „odwiedzamy”, zostaje dodany do stosu. Gdy dotrzemy do węzła-liścia – węzła, który nie ma dzieci – zaczynamy zdejmować węzły ze szczytu stosu. Docieramy ponownie do węzła głównego, a następnie możemy kontynuować przechodzenie w dół następnego poddrzewa.

W powyższym przykładzie drzewa DFS zauważysz, że wszystkie węzły 2, 3 i 4 zostaną dodane do wierzchołek stosu. Kiedy dojdziemy do „końca” tego poddrzewa – to znaczy, kiedy dotrzemy do węzłów liści 3 i 4 – zaczynamy wyrywać te węzły z naszego stosu „węzłów do odwiedzenia”.Możesz zobaczyć, co ostatecznie stanie się z odpowiednim poddrzewem: węzły do odwiedzenia zostaną przeniesione na stos wywołań, odwiedzimy je i systematycznie usuniemy je ze stosu.
Ostatecznie, gdy już odwiedziliśmy zarówno lewe, jak i prawe poddrzewo, wrócimy do węzła głównego i nie pozostanie nic do sprawdzenia, a nasz stos wywołań będzie pusty.
Powinniśmy więc móc użyć strukturę stosu i zrób coś podobnego z naszą implementacją BFS… prawda? Cóż, nie wiem, czy to zadziała, ale myślę, że pomocne będzie przynajmniej rozpoczęcie od narysowania algorytmu, który chcemy zaimplementować, i zobaczenie, jak daleko możemy się z nim posunąć.
Spróbujmy:

OK, więc po lewej stronie mamy wykres, na którym zaimplementowaliśmy DFS w zeszłym tygodniu. Jak możemy zamiast tego użyć algorytmu BFS?
Na początek wiemy, że chcemy najpierw sprawdzić węzeł główny. To jedyny węzeł, do którego będziemy mieli początkowo dostęp, więc będziemy „wskazywać” na węzeł f.
W porządku, teraz będziemy musieli sprawdzić dzieci tego węzła głównego.
Chcemy sprawdzać jedno dziecko po drugim, więc przejdźmy najpierw do lewego dziecka – węzeł d to węzeł, na który „wskazujemy” teraz (i jedyny do którego mamy dostęp).
Następnie będziemy chcieli przejść do odpowiedniego węzła podrzędnego.
Aha. Czekaj, węzeł główny nie jest już dla nas dostępny! I nie możemy się cofać, ponieważ drzewa binarne nie mają odwrotnych linków! Jak dojdziemy do właściwego węzła potomnego? I… o nie, lewy węzeł potomny d i prawy węzeł podrzędny k nie są w ogóle połączone. Oznacza to więc, że nie możemy przeskakiwać z jednego dziecka na drugie, ponieważ nie mamy dostępu do niczego poza dziećmi węzła d.
Ojej. Nie zaszliśmy zbyt daleko, prawda? Będziemy musieli wymyślić inną metodę rozwiązania tego problemu. Musimy wymyślić jakiś sposób na zaimplementowanie przechodzenia po drzewie, które pozwoli nam chodzić po drzewie w kolejności poziomów. Najważniejszą rzeczą, o której musimy pamiętać, jest to:
Musimy zachować odniesienie do wszystkich węzłów potomnych każdego węzła, który odwiedzamy. W przeciwnym razie nigdy nie będziemy mogli do nich później wrócić i ich odwiedzić!
Im więcej o tym myślę, tym bardziej mam ochotę to tak, jakbyśmy chcieli zachować listę wszystkich węzłów, które nadal musimy sprawdzić, prawda? W momencie, gdy chcę zachować listę czegoś, mój umysł natychmiast przeskakuje do jednej struktury danych: oczywiście kolejki!
Zobaczmy, czy kolejki mogą nam pomóc w implementacji BFS.
Kolejki na ratunek!
Jak się okazuje, główną różnicą w przeszukiwaniu w głąb i przeszukiwaniu wszerz jest struktura danych wykorzystywana do implementacji obu tych bardzo różnych algorytmów.
Podczas gdy DFS używa struktury danych stosu, BFS opiera się na strukturze danych kolejki. Zaletą korzystania z kolejek jest to, że rozwiązuje problem, który odkryliśmy wcześniej: pozwala nam zachować odniesienie do węzłów, do których chcemy wrócić, nawet jeśli jeszcze ich nie sprawdziliśmy / nie odwiedziliśmy.
Dodajemy węzły, które odkryliśmy – ale jeszcze nie odwiedziliśmy – do naszej kolejki i wrócimy do nich później.
Wspólnym terminem określającym węzły, które dodajemy do naszej kolejki, są odkryte węzły; Odkryty węzeł to taki, który dodajemy do naszej kolejki, którego lokalizację znamy, ale jeszcze go nie odwiedziliśmy. W rzeczywistości właśnie to sprawia, że kolejka jest idealną strukturą do rozwiązania problemu BFS.

Na wykresie po lewej zaczynamy od dodania węzła głównego do naszej kolejki, ponieważ jest to jedyny węzeł, jaki kiedykolwiek mieć dostęp (przynajmniej początkowo) w drzewie. Oznacza to, że węzeł główny jest jedynym odkrytym węzłem, który ma się uruchomić.
Po dodaniu co najmniej jednego węzła do kolejki możemy rozpocząć proces odwiedzania węzłów i dodawania odwołań do ich węzłów potomnych do naszej kolejki.
OK, więc to wszystko może wydawać się nieco zagmatwane. I to jest w porządku! Myślę, że będzie to dużo łatwiejsze do zrozumienia, jeśli podzielimy to na prostsze kroki.
Dla każdego węzła w naszej kolejce – zawsze zaczynając od węzła głównego – będziemy chcieli zrobić trzy rzeczy:
- Odwiedź węzeł, co zwykle oznacza po prostu wydrukowanie jego wartości.
- Dodaj lewe dziecko węzła do naszej kolejki.
- Dodaj prawą stronę węzła dziecko do naszej kolejki.
Po wykonaniu tych trzech czynności możemy usunąć węzeł z naszej kolejki, ponieważ już go nie potrzebujemy!Zasadniczo musimy powtarzać to wielokrotnie, aż dojdziemy do punktu, w którym nasza kolejka jest pusta.
Dobra, spójrzmy na to w akcji!
Na poniższym wykresie zaczynamy wyłącz z węzłem głównym, węzłem f, jako jedynym odkrytym węzłem. Pamiętasz nasze trzy kroki? Zróbmy to teraz:
- Odwiedzimy węzeł f i wydrukujemy jego wartość.
- Umieścimy w kolejce odniesienie do jego lewego dziecka, węzła d.
- Umieścimy w kolejce odniesienie do jego prawego dziecka, węzła k.
A potem usuniemy węzeł f z naszej kolejki!

Następny węzeł na początku kolejki to węzeł d. Ponownie, te same trzy kroki tutaj: wydrukuj jego wartość, dodaj lewe dziecko, prawe dziecko, a następnie usuń je z kolejki.
Nasza kolejka ma teraz odniesienia do węzłów k, b i e . Jeśli będziemy systematycznie powtarzać ten proces, zauważymy, że w rzeczywistości przechodzimy przez wykres i drukujemy węzły w kolejności poziomów. Brawo! Właśnie to chcieliśmy zrobić w pierwszej kolejności.
Kluczem do tego, aby tak dobrze działało, jest sama natura struktury kolejki. Kolejki działają zgodnie z zasadą FIFO, czyli pierwsze na wejściu, pierwsze na wyjściu (FIFO), co oznacza, że to, co zostało umieszczone w kolejce jako pierwsze, jest pierwszym elementem, który zostanie odczytany i usunięty z kolejki.
Na koniec, skoro już jesteśmy przy temacie kolejek, warto wspomnieć, że złożoność czasoprzestrzenna algorytmu BFS jest również związana z kolejką, której używamy do jego implementacji – kto wiedział, że kolejki wrócą być tak użytecznym, prawda?
Złożoność czasowa algorytmu BFS zależy bezpośrednio od tego, ile czasu zajmuje wizyta w węźle. Ponieważ czas potrzebny na odczytanie wartości węzła i umieszczenie w kolejce jego elementów podrzędnych nie zmienia się w zależności od węzła, możemy powiedzieć, że odwiedzanie węzła wymaga stałego czasu lub czasu O (1). Ponieważ każdy węzeł w drzewie BFS odwiedzamy tylko raz, czas, jaki zajmie nam odczytanie każdego węzła, naprawdę zależy tylko od liczby węzłów w drzewie! Jeśli nasze drzewo ma 15 węzłów, zajmie nam to O (15); ale jeśli nasze drzewo ma 1500 węzłów, zajmie nam to O (1500). Zatem złożoność czasowa algorytmu przeszukiwania wszerz wymaga czasu liniowego lub O (n), gdzie n jest liczbą węzłów w drzewie.
Złożoność przestrzeni jest podobna do tej, ma więcej do zrobić z tym, jak bardzo nasza kolejka rośnie i kurczy się, gdy dodajemy węzły, które musimy do niej sprawdzić. W najgorszym przypadku moglibyśmy potencjalnie kolejkować wszystkie węzły w drzewie, jeśli wszystkie są swoimi dziećmi, co oznacza, że prawdopodobnie używalibyśmy tyle pamięci, ile jest węzłów w drzewie. Jeśli rozmiar kolejki może wzrosnąć do liczby węzłów w drzewie, złożoność przestrzeni dla algorytmu BFS to również czas liniowy lub O (n), gdzie n to liczba węzłów w drzewie.
Wszystko w porządku, ale wiesz, co naprawdę chciałbym teraz zrobić? Chciałbym napisać jeden z tych algorytmów! W końcu zastosujmy całą tę teorię w praktyce.
Kodowanie naszego pierwszego algorytmu wyszukiwania wszerz
Udało się! W końcu zamierzamy zakodować nasz pierwszy algorytm BFS. Zrobiliśmy trochę tego w zeszłym tygodniu z algorytmami DFS, więc spróbujmy napisać również implementację wyszukiwania wszerz.
Być może pamiętasz, że napisaliśmy to w waniliowym JavaScript w zeszłym tygodniu, więc dla zachowania spójności będziemy się przy tym trzymać. Jeśli potrzebujesz szybkiego przypomnienia, zdecydowaliśmy się zachować prostotę i napisać nasze obiekty węzłów jako zwykłe stare obiekty JavaScript (POJO), na przykład:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
OK, spoko. Jeden krok zrobiony.
Ale teraz, gdy wiemy o kolejkach i jesteśmy pewni, że będziemy musieli go użyć do zaimplementowania tego algorytmu… prawdopodobnie powinniśmy dowiedzieć się, jak to zrobić w JavaScript, prawda? Cóż, jak się okazuje, bardzo łatwo jest stworzyć obiekt podobny do kolejki w JS!
Możemy użyć tablicy, która całkiem nieźle załatwia sprawę:
Gdybyśmy chcieli zrobić to nieco bardziej wyszukanym, prawdopodobnie moglibyśmy również stworzyć obiekt Queue, który może mieć przydatne funkcje, takie jak top lub isEmpty; ale na razie będziemy polegać na bardzo prostej funkcjonalności.
OK, napiszmy tego szczeniaka! Utworzymy funkcję levelOrderSearch, która przyjmuje obiekt rootNode.
Super! To jest właściwie… dość proste. A przynajmniej o wiele prostsze, niż się spodziewałem. Wszystko, co tutaj robimy, to używanie pętli while, aby kontynuować wykonywanie tych trzech kroków sprawdzania węzła, dodawania jego lewego dziecka i prawego.Kontynuujemy iterację po tablicy queue, aż wszystko zostanie z niej usunięte, a jego długość wyniesie 0.
Niesamowity. Nasza wiedza na temat algorytmów gwałtownie wzrosła w ciągu zaledwie jednego dnia! Nie tylko wiemy, jak pisać rekurencyjne algorytmy przechodzenia po drzewie, ale teraz wiemy również, jak pisać algorytmy iteracyjne. Kto by pomyślał, że wyszukiwanie algorytmiczne może być tak inspirujące!
Zasoby
Jest jeszcze wiele do nauczenia się o przeszukiwaniu wszerz i kiedy może być przydatne. Na szczęście istnieje mnóstwo zasobów obejmujących informacje, których nie mogłem zmieścić w tym poście. Zapoznaj się z kilkoma naprawdę dobrymi poniżej.
- Algorytmy DFS i BFS wykorzystujące stosy i kolejki, profesor Lawrence L. Larmore
- Algorytm przeszukiwania wszerz, Khan Akademia
- Struktura danych – pierwsza wędrówka wszerz, TutorialsPoint
- Drzewo binarne: przemierzanie kolejności poziomów, mykodeschool
- Breadth-first Traversal, Wydział Informatyki Boston University
