Als het om leren gaat, zijn er over het algemeen twee benaderingen die je kunt volgen: je kunt ofwel gaan breed, en probeer zoveel mogelijk van het spectrum van een vakgebied te bestrijken, of je kunt diep gaan en proberen echt, echt specifiek te worden met het onderwerp dat je leert. De meeste goede leerlingen weten dat alles wat je leert in het leven – van algoritmen tot elementaire levensvaardigheden – tot op zekere hoogte een combinatie van deze twee benaderingen inhoudt.
Hetzelfde geldt voor informatica, probleemoplossing, en datastructuren. Vorige week doken we diep in de diepte-eerste zoektocht en leerden wat het betekent om daadwerkelijk door een binaire zoekboom te bladeren. Nu we diep zijn gegaan, is het logisch dat we breed gaan en de andere gebruikelijke strategie voor het doorkruisen van bomen begrijpen.
Met andere woorden, dit is het moment waarop jullie allemaal hebben gewacht: het is tijd om de basisprincipes van breedte-eerst zoeken op te splitsen!
Een van de beste manieren om te begrijpen wat breedte-eerst zoeken (BFS) precies is, is door te begrijpen wat het niet is. Dat wil zeggen dat als we BFS met DFS vergelijken, het voor ons veel gemakkelijker zal zijn om ze recht in ons hoofd te houden. Dus laten we ons geheugen van de eerste keer zoeken op diepte opfrissen voordat we verder gaan.
We weten dat de eerste zoekactie met diepte het proces is van het doorlopen van een tak van een boom tot we bij een blad komen, en dan terug te werken naar de “stam” van de boom. Met andere woorden, het implementeren van een DFS betekent omlaag door de substructuren van een binaire zoekboom bladeren.
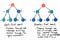
Oké, dus hoe werkt breedte-eerst vergelijken met dat? Als we erover nadenken, is het enige echte alternatief om de ene tak van een boom af te reizen en dan een andere, door de boom sectie voor sectie of, niveau voor niveau, af te reizen. En dat is precies wat BFS is !
Bij breedste zoekactie wordt een boom voor één niveau tegelijk doorzocht.
Wij doorkruis eerst een heel niveau van kinderknooppunten, voordat u doorgaat om door de kleinkinderenknooppunten te gaan. En we doorlopen een heel niveau van kleinkinderenknooppunten voordat we doorgaan door achterkleinkinderenknooppunten.
Oké, dat lijkt redelijk duidelijk. Wat onderscheidt de twee verschillende soorten algoritmen voor het doorlopen van bomen nog meer? Welnu, we hebben de verschillen in de procedures van deze twee algoritmen al besproken. Laten we eens kijken naar het andere belangrijke aspect waarover we het nog niet hebben gehad: implementatie.
Laten we eerst beginnen met wat we weten. Hoe hebben we vorige week diepte eerst zoeken geïmplementeerd? U herinnert zich misschien dat we drie verschillende methoden hebben geleerd – in volgorde, postorder en pre-order – om door een boomstructuur te zoeken met DFS. Toch was er iets super gaafs aan hoe vergelijkbaar deze drie implementaties waren; ze zouden elk kunnen worden gebruikt door middel van recursie. We weten ook dat, aangezien DFS kan worden geschreven als een recursieve functie, ze ervoor kunnen zorgen dat de call-stack zo groot wordt als het langste pad in de boomstructuur.
Er was echter één ding dat ik achterliet uit vorige week, dat lijkt nu goed om naar voren te brengen (en misschien is het zelfs een beetje voor de hand liggend!): de call-stack implementeert eigenlijk een stack-datastructuur. Onthoud die? We leerden een tijdje geleden over stapels, maar hier zijn ze weer, ze verschijnen overal!
Het echt interessante aan het implementeren van een diepte-eerst zoekactie met een stapel is dat als we door de substructuren van een stap gaan. binaire zoekboom, elk van de knooppunten die we “controleren” of “bezoeken” wordt toegevoegd aan de stapel. Zodra we een bladknooppunt bereiken – een knooppunt dat geen kinderen heeft – beginnen we de knooppunten vanaf de bovenkant van de stapel te verwijderen. We komen weer bij het hoofdknooppunt terecht en kunnen dan doorgaan met het doorlopen van de volgende substructuur.

In het bovenstaande voorbeeld van de DFS-structuur ziet u dat de knooppunten 2, 3 en 4 allemaal worden toegevoegd aan de bovenkant van de stapel. Wanneer we bij het “einde” van die substructuur komen – dat wil zeggen, wanneer we de bladknooppunten van 3 en 4 bereiken – beginnen we die knooppunten uit onze stapel “te bezoeken knooppunten” te laten springen.U kunt zien wat er uiteindelijk zal gebeuren met de juiste substructuur: de knooppunten die u wilt bezoeken, worden op de call-stack geduwd, we zullen ze bezoeken en ze systematisch van de stack verwijderen.
Uiteindelijk, zodra we hebben zowel de linker als de rechter substructuur bezocht, we zijn terug bij het hoofdknooppunt en hebben niets meer om te controleren, en onze call-stack zal leeg zijn.
Dus we zouden in staat moeten zijn om een stack-structuur en doe iets soortgelijks met onze BFS-implementatie … toch? Nou, ik weet niet of het zal werken, maar ik denk dat het nuttig zal zijn om in ieder geval te beginnen met het uittekenen van het algoritme dat we willen implementeren, en te kijken hoe ver we ermee kunnen komen.
Laten we het proberen:

Oké, we hebben dus een grafiek aan de linkerkant waarop we vorige week DFS hebben geïmplementeerd. Hoe kunnen we er in plaats daarvan een BFS-algoritme op gebruiken?
Om te beginnen weten we dat we eerst de root-node willen controleren. Dat is het enige knooppunt waartoe we in eerste instantie toegang hebben, en dus zullen we naar knooppunt f “wijzen”.
Oké, nu zullen we de kinderen van dit rootknooppunt moeten controleren.
We willen het ene kind na het andere controleren, dus laten we eerst naar het linkerkind gaan – knooppunt d is het knooppunt waarnaar we nu “wijzen” (en het enige knooppunt waartoe we toegang hebben).
Vervolgens willen we naar het juiste kindknooppunt gaan.
Oh oh. Wacht, het rootknooppunt is niet eens meer voor ons beschikbaar! En we kunnen niet achteruit bewegen, omdat binaire bomen geen omgekeerde links hebben! Hoe gaan we bij het juiste kindknooppunt komen? En … oh nee, het linker kindknooppunt d en het rechter kindknooppunt k zijn helemaal niet met elkaar verbonden. Dat betekent dus dat het voor ons onmogelijk is om van het ene kind naar het andere te springen, omdat we nergens toegang toe hebben behalve de kinderen van node d.
Oh jee. We zijn niet ver gekomen, toch? We zullen een andere methode moeten bedenken om dit probleem op te lossen. We moeten een manier bedenken om een boomdoorgang te implementeren waarmee we de boom in horizontale volgorde kunnen doorlopen. Het belangrijkste dat we in gedachten moeten houden is dit:
We moeten een verwijzing houden naar alle onderliggende knooppunten van elk knooppunt dat we bezoeken. Anders kunnen we er later nooit meer op terugkomen en ze bezoeken!
Hoe meer ik erover nadenk, hoe meer ik zin krijg het is alsof we een lijst willen bijhouden van alle knooppunten die we nog moeten controleren, nietwaar? En op het moment dat ik een lijst van iets wil bijhouden, springt mijn geest onmiddellijk naar één datastructuur in het bijzonder: een wachtrij natuurlijk!
Laten we eens kijken of wachtrijen ons kunnen helpen met onze BFS-implementatie.
Wachtrijen die te hulp schieten!
Het blijkt dat een groot verschil in diepte-eerst zoeken en breedte-eerst zoeken de datastructuur is die wordt gebruikt om beide zeer verschillende algoritmen te implementeren.
Terwijl DFS een stapelgegevensstructuur gebruikt, leunt BFS op de wachtrijgegevensstructuur. Het leuke van het gebruik van wachtrijen is dat het juist het probleem oplost dat we eerder ontdekten: het stelt ons in staat een verwijzing te bewaren naar knooppunten waarnaar we terug willen komen, ook al hebben we ze nog niet gecontroleerd / bezocht.
We voegen knooppunten die we hebben ontdekt – maar nog niet bezocht – toe aan onze wachtrij en komen er later op terug.
Een veelgebruikte term voor knooppunten die we aan onze wachtrij toevoegen, zijn ontdekte knooppunten; een ontdekt knooppunt is een knooppunt dat we aan onze wachtrij toevoegen, waarvan we de locatie weten, maar die we nog niet daadwerkelijk hebben bezocht. In feite is dit precies wat een wachtrij de perfecte structuur maakt om het BFS-probleem op te lossen.

In de grafiek aan de linkerkant beginnen we met het toevoegen van de root-node aan onze wachtrij, aangezien dat het enige knooppunt is dat we ooit hebben toegang hebben tot (tenminste, aanvankelijk) in een boom. Dit betekent dat het rootknooppunt het enige ontdekte knooppunt is dat wordt gestart.
Zodra we ten minste één knooppunt in de wachtrij hebben geplaatst, kunnen we het proces starten van het bezoeken van knooppunten en het toevoegen van verwijzingen naar hun onderliggende knooppunten aan onze wachtrij.
Oké, dus dit klinkt misschien allemaal een beetje verwarrend. En dat is oké! Ik denk dat het een stuk gemakkelijker te begrijpen zal zijn als we het opsplitsen in eenvoudigere stappen.
Voor elk knooppunt in onze wachtrij – altijd beginnend met het hoofdknooppunt – willen we drie dingen doen:
- Bezoek het knooppunt, wat meestal betekent dat je de waarde ervan afdrukt.
- Voeg het linkerkind van het knooppunt toe aan onze wachtrij.
- Voeg de rechterkant van het knooppunt toe kind in onze wachtrij.
Zodra we deze drie dingen hebben gedaan, kunnen we het knooppunt uit onze wachtrij verwijderen, omdat we het niet meer nodig hebben!We moeten dit in principe herhaaldelijk blijven doen totdat we op het punt komen dat onze wachtrij leeg is.
Oké, laten we dit in actie bekijken!
In de onderstaande grafiek beginnen we uitgeschakeld met het hoofdknooppunt, knooppunt f, als het enige ontdekte knooppunt. Herinner je je onze drie stappen nog? Laten we ze nu doen:
- We bezoeken knooppunt f en drukken de waarde ervan af.
- We plaatsen een verwijzing naar het linkerkind, knooppunt d.
- We zullen een verwijzing naar het juiste kind, knoop k, in de wachtrij plaatsen.
En dan verwijderen we knooppunt f uit onze wachtrij!

Het volgende knooppunt vooraan in de wachtrij is knooppunt d. Nogmaals, dezelfde drie stappen hier: druk de waarde af, voeg het linkerkind toe, voeg het rechterkind toe en verwijder het dan uit de wachtrij.
Onze wachtrij heeft nu verwijzingen naar knooppunten k, b en e . Als we dit proces systematisch blijven herhalen, zullen we merken dat we in feite de grafiek doorlopen en de knooppunten in horizontale volgorde afdrukken. Hoera! Dat is precies wat we in de eerste plaats wilden doen.
De sleutel tot dit zo goed werken is de aard van de wachtrijstructuur. Wachtrijen volgen het first-in, first-out (FIFO) -principe, wat betekent dat wat het eerst in de wachtrij is geplaatst, het eerste item is dat wordt gelezen en uit de wachtrij wordt verwijderd.
Ten slotte, terwijl we het over wachtrijen hebben, is het de moeite waard om te vermelden dat de ruimte-tijd-complexiteit van een BFS-algoritme ook verband houdt met de wachtrij die we gebruiken om het te implementeren – wie wist dat wachtrijen terug zouden komen om zo nuttig te zijn, toch?
De tijdcomplexiteit van een BFS-algoritme hangt rechtstreeks af van hoeveel tijd het kost om een knooppunt te bezoeken. Aangezien de tijd die nodig is om de waarde van een knooppunt te lezen en de onderliggende items ervan in de wachtrij te plaatsen, niet verandert op basis van het knooppunt, kunnen we zeggen dat het bezoeken van een knooppunt constante tijd kost, of O (1) tijd. Omdat we elk knooppunt in een BFS-tree traversal maar één keer bezoeken, hangt de tijd die het kost om elk knooppunt te lezen eigenlijk gewoon af van het aantal knooppunten in de boom! Als onze boom 15 knooppunten heeft, zullen we O (15) nodig hebben; maar als onze boom 1500 knooppunten heeft, zullen we O (1500) nodig hebben. De tijdcomplexiteit van een breedte-eerst zoekalgoritme kost dus lineaire tijd, of O (n), waarbij n het aantal knooppunten in de boom is.
Ruimtecomplexiteit is vergelijkbaar met dit, heeft meer te maken met doen met hoeveel onze wachtrij groeit en krimpt als we de knooppunten toevoegen die we eraan moeten controleren. In het ergste geval kunnen we mogelijk alle knooppunten in een boom in de wachtrij plaatsen als ze allemaal kinderen van elkaar zijn, wat betekent dat we mogelijk evenveel geheugen kunnen gebruiken als er knooppunten in de boom zijn. Als de grootte van de wachtrij kan uitgroeien tot het aantal knooppunten in de boom, is de ruimtecomplexiteit voor een BFS-algoritme ook lineaire tijd, of O (n), waarbij n het aantal knooppunten in de boom is.
Dit is allemaal leuk en aardig, maar weet je wat ik nu echt graag zou willen doen? Ik zou eigenlijk een van deze algoritmen willen schrijven! Laten we eindelijk al deze theorie in praktijk brengen.
Codering van ons eerste breedte-eerst zoekalgoritme
We hebben het gehaald! We gaan eindelijk ons allereerste BFS-algoritme coderen. We hebben dit vorige week een beetje gedaan met DFS-algoritmen, dus laten we proberen hier ook een eerste zoekimplementatie van te schrijven.
Misschien herinnert u zich dat we dit vorige week in vanille JavaScript schreven, dus we zullen het nogmaals vasthouden voor de consistentie. Voor het geval je een snelle opfriscursus nodig hebt, hebben we besloten om het simpel te houden en onze node-objecten als gewone oude JavaScript-objecten (POJO’s) te schrijven, zoals dit:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
Oké, cool. Een stap gedaan.
Maar nu we op de hoogte zijn van wachtrijen en er zeker van zijn dat we er een moeten gebruiken om dit algoritme te implementeren … moeten we waarschijnlijk uitzoeken hoe we dat in JavaScript moeten doen, toch? Nou, het blijkt dat het heel gemakkelijk is om een wachtrij-achtig object in JS te maken!
We kunnen een array gebruiken, die het heel goed doet:
Als we dit een beetje mooier wilden maken, zouden we waarschijnlijk ook een Queue object, dat een handige functie zou kunnen hebben zoals top of isEmpty; maar voorlopig vertrouwen we op zeer eenvoudige functionaliteit.
Oké, laten we deze puppy schrijven! We maken een levelOrderSearch -functie, die een rootNode -object opneemt.
Geweldig! Dit is eigenlijk… vrij eenvoudig. Of in ieder geval veel eenvoudiger dan ik had verwacht. Het enige dat we hier doen, is een while -lus gebruiken om door te gaan met het uitvoeren van deze drie stappen: het controleren van een knooppunt, het toevoegen van het linkerkind en het toevoegen van het rechterkind.We gaan door met itereren door de queue array totdat alles eruit is verwijderd, en de lengte is 0.
Verbazingwekkend. Onze expertise op het gebied van algoritmen is in slechts een dag omhooggeschoten! We weten niet alleen hoe we recursieve tree traversal-algoritmen moeten schrijven, maar we weten nu ook hoe we iteratieve algoritmen moeten schrijven. Wie wist dat algoritmisch zoeken zo krachtig zou kunnen zijn!
Bronnen
Er is nog veel te leren over breedte-eerst zoeken, en wanneer het nuttig kan zijn. Gelukkig zijn er talloze bronnen die informatie bevatten die ik niet in dit bericht zou kunnen passen. Bekijk hieronder enkele van de echt goede.
- DFS- en BFS-algoritmen met behulp van stapels en wachtrijen, professor Lawrence L. Larmore.
- Het Breadth-First Search-algoritme, Khan Academy
- Datastructuur – breedte eerste doorgang, TutorialsPoint
- Binaire boom: Level Order Traversal, mycodeschool
- Breedte-eerste doorgang van een boom, Afdeling Computerwetenschappen Universiteit van Boston
