학습과 관련하여 일반적으로 취할 수있는 두 가지 접근 방식이 있습니다. 가능한 한 분야의 스펙트럼을 최대한 많이 다루거나 깊이 들어가서 배우고있는 주제에 대해 정말, 정말 구체적으로 들어 가려고 노력할 수 있습니다. 대부분의 훌륭한 학습자는 알고리즘에서 기본 생활 기술에 이르기까지 인생에서 배우는 모든 것이이 두 가지 접근 방식의 조합을 포함한다는 것을 어느 정도 알고 있습니다.
컴퓨터 과학, 문제 해결, 및 데이터 구조. 지난주에 우리는 깊이 우선 검색에 대해 자세히 알아보고 이진 검색 트리를 실제로 탐색하는 것이 무엇을 의미하는지 배웠습니다. 이제 깊이 살펴 보았으므로 넓게 나아가 다른 일반적인 트리 탐색 전략을 이해하는 것이 합리적입니다.
다시 말해, 여러분 모두가 기다려온 순간입니다. 시간이되었습니다. 너비 우선 검색의 기본 사항을 분석합니다!
BFS (광역 우선 검색)가 무엇인지 정확히 이해하는 가장 좋은 방법 중 하나는 그것이 아닌 것을 이해하는 것입니다. 즉, BFS와 DFS를 비교하면 머리 속에 똑바로 유지하는 것이 훨씬 더 쉬울 것입니다. 그러니 더 진행하기 전에 깊이 우선 검색에 대한 기억을 새로 고쳐 보겠습니다.
우리는 깊이 우선 검색이 잎에 도달 할 때까지 나무의 한 가지를 통과하는 과정이라는 것을 알고 있습니다. 그런 다음 트리의 “트렁크”로 돌아갑니다. 즉, DFS를 구현한다는 것은 이진 검색 트리의 하위 트리를 통해 아래로 이동하는 것을 의미합니다.
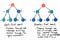
좋습니다. 우리가 그것에 대해 생각해 보면, 나무의 한 가지 아래로 이동하는 것의 유일한 대안은 섹션별로 또는 한 단계 씩 나무 아래로 이동하는 것입니다. 그리고 이것이 바로 BFS입니다. !
폭 우선 검색은 한 번에 한 수준 씩 트리를 검색하는 것입니다.
우리는 손자 노드를 통과하기 위해 이동하기 전에 먼저 하나의 전체 수준의 자식 노드를 통과합니다. 그리고 증손자 노드를 통과하기 전에 전체 수준의 손자 노드를 통과합니다.
좋아요. 꽤 분명해 보입니다. 두 가지 유형의 트리 순회 알고리즘을 다른 점은 무엇입니까? 음, 우리는 이미이 두 알고리즘의 절차 차이를 다루었습니다. 아직 다루지 않은 다른 중요한 측면 인 구현에 대해 생각해 보겠습니다.
먼저 우리가 알고있는 것부터 시작하겠습니다. 지난주에 깊이 우선 검색을 구현하는 방법은 무엇입니까? DFS를 사용하여 트리를 검색하는 세 가지 다른 방법 인 inorder, postorder 및 preorder를 배웠 음을 기억할 것입니다. 그러나이 세 가지 구현이 얼마나 유사한 지에 대해 멋진 점이있었습니다. 재귀를 사용하여 각각 사용할 수 있습니다. 또한 DFS는 재귀 함수로 작성 될 수 있기 때문에 호출 스택이 트리에서 가장 긴 경로만큼 커질 수 있다는 것도 알고 있습니다.
하지만 제가 남긴 것이 하나 있습니다. 지난주에 발표하기에 좋은 것 같습니다. (아마도 조금 분명 할 수도 있습니다!) : 호출 스택은 실제로 스택 데이터 구조를 구현합니다. 기억나요? 우리는 얼마 전에 스택에 대해 배웠지 만 여기에 다시 나타납니다!
스택을 사용하여 깊이 우선 검색을 구현할 때 정말 흥미로운 점은 스택의 하위 트리를 탐색 할 때 이진 검색 트리, 우리가 “확인”하거나 “방문”하는 각 노드가 스택에 추가됩니다. 리프 노드 (자식이없는 노드)에 도달하면 스택의 맨 위에서 노드를 터뜨리기 시작합니다. 다시 루트 노드로 이동 한 다음 계속해서 다음 하위 트리를 탐색 할 수 있습니다.

위의 DFS 트리 예에서 노드 2, 3, 4가 모두 추가되는 것을 볼 수 있습니다. 스택의 맨 위. 하위 트리의 “끝”에 도달하면 (즉, 리프 노드 3과 4에 도달하면) “방문 할 노드”스택에서 해당 노드를 꺼내기 시작합니다.궁극적으로 올바른 하위 트리에서 어떤 일이 발생할지 확인할 수 있습니다. 방문 할 노드가 호출 스택으로 푸시되고, 우리가이를 방문하여 스택에서 체계적으로 제거합니다.
결국, 일단 우리가 왼쪽 및 오른쪽 하위 트리를 모두 방문했으면 확인할 항목이없는 루트 노드로 돌아갈 것이며 호출 스택이 비어있을 것입니다.
그래서 우리는 a를 사용할 수 있어야합니다. 스택 구조를 만들고 BFS 구현과 유사한 작업을 수행합니다. 글쎄, 작동할지 모르겠지만 적어도 우리가 구현하고 싶은 알고리즘을 그려서 우리가 그것을 얼마나 멀리 할 수 있는지 보는 것부터 시작하는 것이 도움이 될 것이라고 생각합니다.
해보기 :

좋습니다. 왼쪽에는 지난주에 DFS를 구현 한 그래프가 있습니다. 대신 BFS 알고리즘을 어떻게 사용할 수 있습니까?
음, 시작하려면 먼저 루트 노드를 확인해야한다는 것을 알고 있습니다. 이것이 우리가 처음에 액세스 할 수있는 유일한 노드이므로 노드 f를 “가리키게”됩니다.
좋습니다. 이제이 루트 노드의 자식을 확인해야합니다.
p>
우리는 자식을 하나씩 확인하고 싶으므로 먼저 왼쪽 자식으로 가자. 노드 d는 우리가 지금 “가리키고있는”노드 (그리고 우리가 접근 할 수있는 유일한 노드)입니다.
다음으로 오른쪽 자식 노드로 이동하겠습니다.
아. 더 이상 루트 노드를 사용할 수 없습니다! 이진 트리에는 역방향 링크가 없기 때문에 우리는 역방향으로 이동할 수 없습니다! 올바른 자식 노드로 어떻게 이동합니까? 그리고… 아뇨, 왼쪽 자식 노드 d와 오른쪽 자식 노드 k는 전혀 연결되지 않았습니다. 즉, 노드 d의 자식 외에는 액세스 할 수 없기 때문에 한 자식에서 다른 자식으로 이동할 수 없습니다.
오, 이런. 우리는 멀리 가지 않았죠? 이 문제를 해결하는 다른 방법을 찾아야합니다. 레벨 순서대로 트리를 걸을 수있는 트리 순회를 구현하는 방법을 찾아야합니다. 명심해야 할 가장 중요한 사항은 다음과 같습니다.
방문하는 모든 노드의 모든 하위 노드에 대한 참조를 유지해야합니다. 그렇지 않으면 나중에 다시 방문하여 방문 할 수 없습니다.
생각할수록 더 많은 느낌이 듭니다. 우리가 여전히 확인해야하는 모든 노드의 목록을 유지하고 싶은 것 같지 않습니까? 그리고 목록을 보관하고 싶은 순간, 즉시 마음이 하나의 데이터 구조, 즉 대기열로 이동합니다!
큐가 BFS 구현에 도움이 될 수 있는지 살펴 보겠습니다.
구출 대기열!
결과적으로 깊이 우선 검색과 폭 우선 검색의 주요 차이점은이 두 알고리즘을 모두 구현하는 데 사용되는 데이터 구조입니다.
DFS는 스택 데이터 구조를 사용하지만 BFS는 큐 데이터 구조에 의존합니다. 대기열 사용의 좋은 점은 이전에 발견 한 바로 그 문제를 해결한다는 것입니다. 아직 확인 / 방문하지 않았더라도 다시 돌아오고 싶은 노드에 대한 참조를 유지할 수 있습니다.
발견했지만 아직 방문하지 않은 노드를 대기열에 추가하고 나중에 다시 돌아옵니다.
큐에 추가하는 노드의 일반적인 용어는 검색된 노드입니다. 발견 된 노드는 위치를 알고 있지만 아직 실제로 방문하지 않은 큐에 추가하는 노드입니다. 사실 이것이 바로 큐를 BFS 문제를 해결하기위한 완벽한 구조로 만드는 것입니다.

왼쪽 그래프에서 루트 노드를 대기열에 추가하는 것으로 시작합니다. 트리에서 (적어도 처음에는) 액세스 할 수 있습니다. 이것은 루트 노드가 시작할 유일한 발견 노드라는 것을 의미합니다.
최소한 하나의 노드가 대기열에 추가되면 노드를 방문하고 자식 노드에 대한 참조를 대기열에 추가하는 프로세스를 시작할 수 있습니다.
좋습니다.이 모든 것이 약간 혼란스럽게 들릴 수 있습니다. 그리고 괜찮습니다! 좀 더 간단한 단계로 나누면 이해하기 훨씬 쉬울 것 같습니다.
큐의 모든 노드 (항상 루트 노드부터 시작)에 대해 세 가지 작업을 수행해야합니다.
- 노드를 방문하십시오. 일반적으로 값을 인쇄하는 것을 의미합니다.
- 노드의 왼쪽 자식을 대기열에 추가합니다.
- 노드의 오른쪽을 추가합니다. 자식을 대기열에 추가합니다.
이 세 가지 작업을 수행하면 더 이상 필요하지 않으므로 대기열에서 노드를 제거 할 수 있습니다.기본적으로 대기열이 비어있는 지점에 도달 할 때까지이 작업을 계속 반복해야합니다.
좋아,이 작업을 살펴 보겠습니다!
아래 그래프에서 시작합니다. 루트 노드 인 노드 f를 유일한 검색된 노드로 사용합니다. 세 단계를 기억하십니까? 이제 해 봅시다 :
- 노드 f를 방문하여 그 값을 출력합니다.
- 왼쪽 자식 노드 d에 대한 참조를 대기열에 추가합니다. li>
- 오른쪽 자식 노드 k에 대한 참조를 대기열에 추가합니다.
그런 다음 대기열에서 노드 f를 제거합니다!

대기열 앞에있는 다음 노드는 노드 d입니다. 다시, 여기서도 동일한 세 단계 : 값을 인쇄하고, 왼쪽 자식을 추가하고, 오른쪽 자식을 추가하고, 큐에서 제거합니다.
이제 큐에는 노드 k, b 및 e에 대한 참조가 있습니다. . 이 프로세스를 체계적으로 계속 반복하면 실제로 그래프를 순회하고 노드를 레벨 순서대로 인쇄하고 있음을 알 수 있습니다. 만세! 이것이 바로 우리가 애초에하고 싶었던 일입니다.
이 작업의 핵심은 대기열 구조의 특성입니다. 대기열은 선입 선출 (FIFO) 원칙을 따릅니다. 즉, 대기열에 먼저 추가 된 항목은 대기열에서 읽고 제거되는 첫 번째 항목입니다.
마지막으로 대기열에 관한 주제를 다루고 있지만 BFS 알고리즘의 공간-시간 복잡성은이를 구현하는 데 사용하는 대기열과도 관련이 있다는 점을 언급 할 가치가 있습니다. 그렇게 유용 하겠죠?
BFS 알고리즘의 시간 복잡도는 노드를 방문하는 데 걸리는 시간에 직접적으로 좌우됩니다. 노드의 값을 읽고 자식을 큐에 넣는 데 걸리는 시간은 노드에 따라 변경되지 않으므로 노드를 방문하는 데는 일정한 시간 또는 O (1) 시간이 걸린다고 말할 수 있습니다. BFS 트리 탐색의 각 노드를 정확히 한 번만 방문하기 때문에 모든 노드를 읽는 데 걸리는 시간은 실제로 트리에있는 노드 수에 따라 다릅니다! 우리 트리에 15 개의 노드가 있다면 O (15)를 사용합니다. 그러나 우리의 트리가 1500 개의 노드를 가지고 있다면 O (1500)가 될 것입니다. 따라서 폭 우선 검색 알고리즘의 시간 복잡도는 선형 시간 또는 O (n)이 필요합니다. 여기서 n은 트리의 노드 수입니다.
공간 복잡도는 이와 유사하며 확인해야하는 노드를 추가 할 때 큐가 얼마나 늘어나고 줄어드는 지와 관련이 있습니다. 최악의 상황에서 우리는 모든 노드가 서로의 자식 인 경우 잠재적으로 트리의 모든 노드를 대기열에 넣을 수 있습니다. 즉, 트리에있는 노드만큼 많은 메모리를 사용할 수 있습니다. 큐의 크기가 트리의 노드 수만큼 커질 수있는 경우 BFS 알고리즘의 공간 복잡성도 선형 시간 또는 O (n)입니다. 여기서 n은 트리의 노드 수입니다.
이 모든 것이 좋고 좋지만 지금 당장 제가 무엇을하고 싶은지 아십니까? 이 알고리즘 중 하나를 실제로 작성하고 싶습니다! 마침내이 모든 이론을 실행 해 보겠습니다.
첫 번째 폭 우선 검색 알고리즘 코딩
우리가 만들었습니다! 드디어 첫 번째 BFS 알고리즘을 코딩 할 것입니다. 지난주에 DFS 알고리즘으로이 작업을 약간 수행 했으므로 이것의 폭 우선 검색 구현도 작성해 보겠습니다.
지난 주에 바닐라 자바 스크립트로 작성했음을 기억할 것입니다. 일관성을 위해 다시 고수하겠습니다. 빠른 복습이 필요한 경우, 단순하게 유지하고 노드 객체를 다음과 같이 POJO (Plain Old JavaScript Object)로 작성하기로 결정했습니다.
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
좋아요. 한 단계 완료되었습니다.
하지만 이제 우리는 큐에 대해 알고 있으며이 알고리즘을 구현하기 위해 큐를 사용해야한다는 것을 확신합니다. 자바 스크립트에서이를 수행하는 방법을 알아 내야합니다. 결과적으로 JS에서 큐와 같은 객체를 만드는 것은 정말 쉽습니다!
배열을 사용할 수 있습니다.이 방법은 매우 훌륭합니다.
이것을 좀 더 멋지게 만들고 싶다면 top 또는 isEmpty와 같은 편리한 기능이있을 수있는 Queue 개체 하지만 지금은 매우 간단한 기능에 의존하겠습니다.
좋아,이 강아지를 작성 해보자! rootNode 개체를받는 levelOrderSearch 함수를 만듭니다.
대단합니다! 이것은 실제로… 상당히 간단합니다. 또는 적어도 내가 예상했던 것보다 훨씬 간단합니다. 여기서 수행하는 작업은 while 루프를 사용하여 노드 확인, 왼쪽 자식 추가, 오른쪽 자식 추가의 세 단계를 계속하는 것입니다.모든 항목이 제거 될 때까지 queue 배열을 반복하고 길이는 0입니다.
놀랄 만한. 우리의 알고리즘 전문 지식이 단 하루 만에 급증했습니다! 재귀 트리 순회 알고리즘을 작성하는 방법을 알고있을뿐만 아니라 이제 반복적 인 알고리즘을 작성하는 방법도 알고 있습니다. 알고리즘 검색이 그토록 힘을 실어 줄 수 있다는 것을 누가 알았습니까!
리소스
광범위 우선 검색에 대해 알아야 할 내용이 많이 있으며 언제 유용 할 수 있는지 알 수 있습니다. 운 좋게도이 게시물에 포함 할 수없는 정보를 다루는 수많은 리소스가 있습니다. 아래에서 정말 좋은 몇 가지를 확인하십시오.
- 스택 및 대기열을 사용하는 DFS 및 BFS 알고리즘, Lawrence L. Larmore 교수
- 폭 우선 검색 알고리즘, Khan Academy
- 데이터 구조 — Breadth First Traversal, TutorialsPoint
- Binary tree : Level Order Traversal, mycodeschool
- Breadth-First Traversal of a Tree, Computer Science Department of 보스턴 대학교
