인공 지능은 인간과 기계의 능력 간 격차를 해소하는 데있어 기념비적 인 성장을 목격했습니다. 연구원과 애호가 모두 놀라운 일이 일어나도록 분야의 다양한 측면을 연구합니다. 그러한 많은 영역 중 하나가 컴퓨터 비전의 영역입니다.
이 분야의 의제는 기계가 인간처럼 세상을보고 유사한 방식으로 인식하고 심지어 지식을 여러 사람에게 사용할 수 있도록하는 것입니다. 이미지 & 비디오 인식, 이미지 분석 & 분류, 미디어 재생, 추천 시스템, 자연어 처리 등과 같은 작업의 수. in Computer Vision with Deep Learning은 주로 하나의 특정 알고리즘 인 Convolutional Neural Network를 통해 구축되고 완성되었습니다.
소개

컨볼 루션 신경망 (ConvNet / CNN)은 딥 러닝입니다. 입력 이미지를 받아 중요도를 할당 할 수있는 알고리즘 (learnabl e 가중치 및 편향) 이미지의 다양한 측면 / 객체에 적용하고 서로 구별 할 수 있습니다. ConvNet에 필요한 전처리는 다른 분류 알고리즘에 비해 훨씬 낮습니다. 원시 방법에서 필터는 수작업으로 설계되었지만 충분한 교육을 통해 ConvNet은 이러한 필터 / 특성을 학습 할 수 있습니다.
ConvNet의 아키텍처는 인간의 뉴런의 연결 패턴과 유사합니다. Brain은 Visual Cortex의 조직에서 영감을 받았습니다. 개별 뉴런은 수용 필드로 알려진 시야의 제한된 영역에서만 자극에 반응합니다. 이러한 필드의 모음은 전체 시각적 영역을 덮기 위해 겹칩니다.
왜 ConvNet이 Feed-Forward Neural Nets를 통해 이루어 지나요?

이미지는 픽셀 값의 매트릭스에 불과합니다. 그렇다면 이미지를 평평하게 (예 : 3×3 이미지 매트릭스를 9×1 벡터로)하고 분류를 위해 다중 레벨 퍼셉트론에 공급하지 않는 이유는 무엇입니까? 어 .. 그렇지 않습니다.
매우 기본적인 이진 이미지의 경우이 메서드는 클래스 예측을 수행하는 동안 평균 정밀도 점수를 표시 할 수 있지만 픽셀 종속성이있는 복잡한 이미지의 경우 정확도가 거의 또는 전혀 없습니다.
ConvNet은 관련 필터의 적용을 통해 이미지의 공간 및 시간 종속성을 성공적으로 캡처 할 수 있습니다. 이 아키텍처는 관련된 매개 변수 수의 감소와 가중치의 재사용 가능성으로 인해 이미지 데이터 세트에 더 잘 맞습니다. 즉, 이미지의 정교함을 더 잘 이해하도록 네트워크를 훈련시킬 수 있습니다.
입력 이미지

그림에는 빨간색, 녹색, 세 가지 색상 평면으로 구분 된 RGB 이미지가 있습니다. 그리고 블루. 그레이 스케일, RGB, HSV, CMYK 등 이미지가 존재하는 여러 가지 색상 공간이 있습니다.
이미지가 8K (7680x)에 도달하면 계산 집약적 인 작업이 얼마나 많은지 상상할 수 있습니다. 4320). ConvNet의 역할은 좋은 예측을 얻는 데 중요한 기능을 잃지 않고 이미지를 처리하기 쉬운 형태로 줄이는 것입니다. 이것은 학습 기능에 능숙 할뿐만 아니라 대규모 데이터 세트로 확장 가능한 아키텍처를 설계 할 때 중요합니다.
컨볼 루션 계층 — 커널
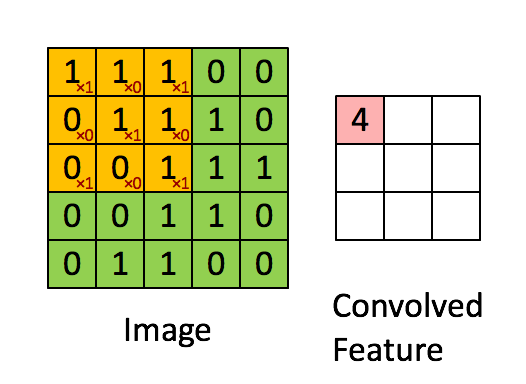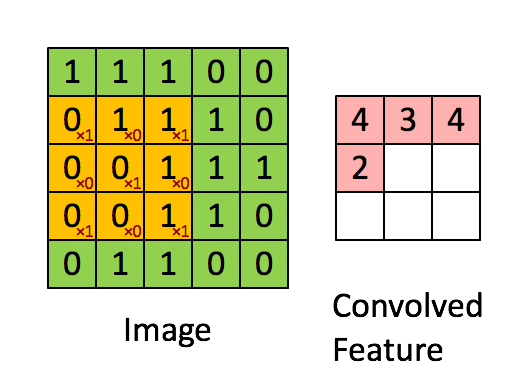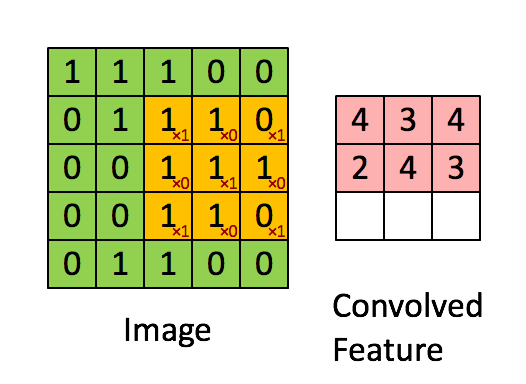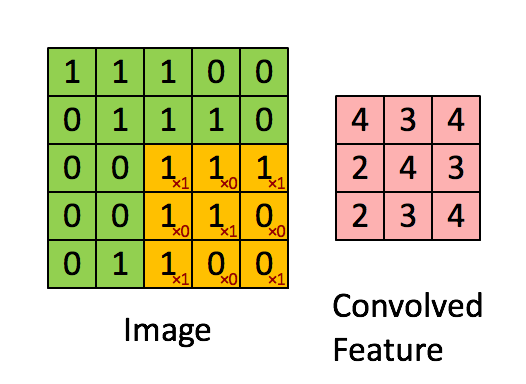
이미지 크기 = 5 (높이) x 5 (폭) x 1 (채널 수, 예 : RGB)
위의 데모에서 녹색 섹션은 5x5x1 입력 이미지 I와 유사합니다. 운반과 관련된 요소 Convolutional Layer의 첫 번째 부분에있는 convolution 연산은 Kernel / Filter, K라고하며 노란색으로 표시됩니다. K를 3x3x1 행렬로 선택했습니다.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
행렬 길이 = 1 (Non-Strided)로 인해 커널이 9 번 이동하며 행렬을 수행 할 때마다 K와 커널이 떠있는 이미지의 P 부분 사이의 곱셈 연산.

필터가 오른쪽으로 이동 전체 너비를 구문 분석 할 때까지 특정 보폭 값으로. 계속해서 동일한 보폭 값을 가진 이미지의 시작 부분 (왼쪽)으로 내려가 전체 이미지가 횡단 할 때까지 프로세스를 반복합니다.
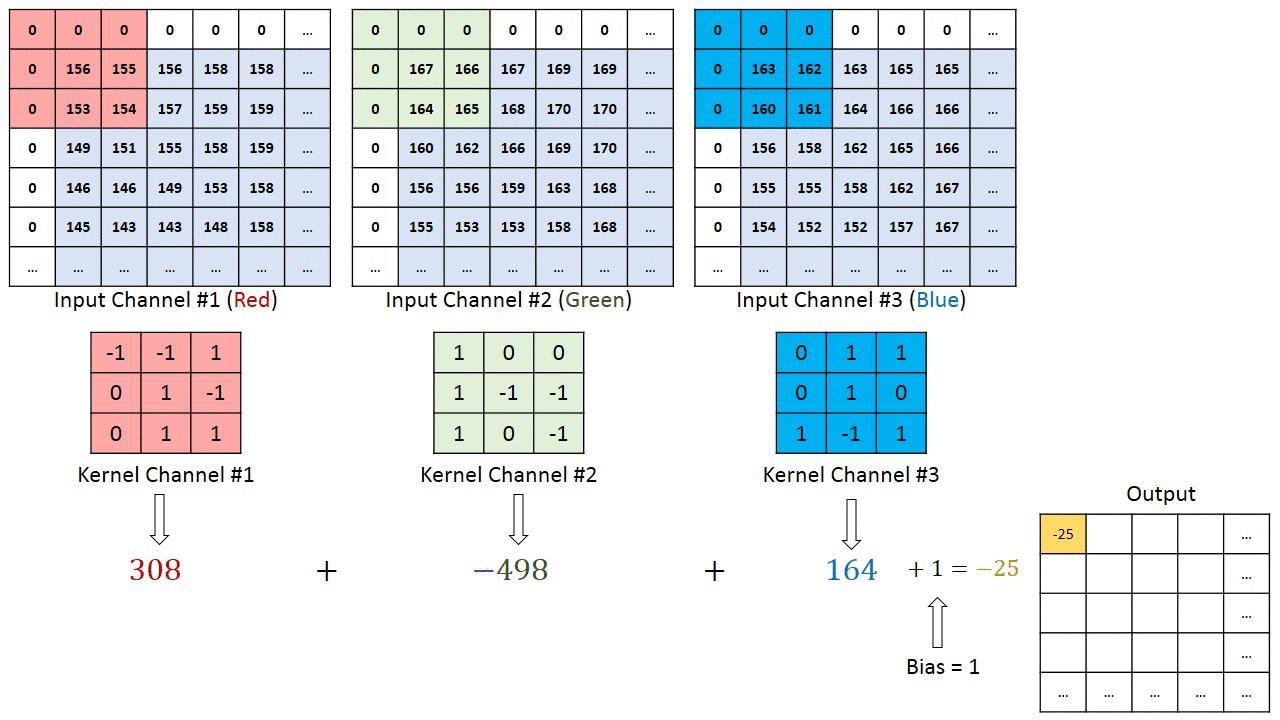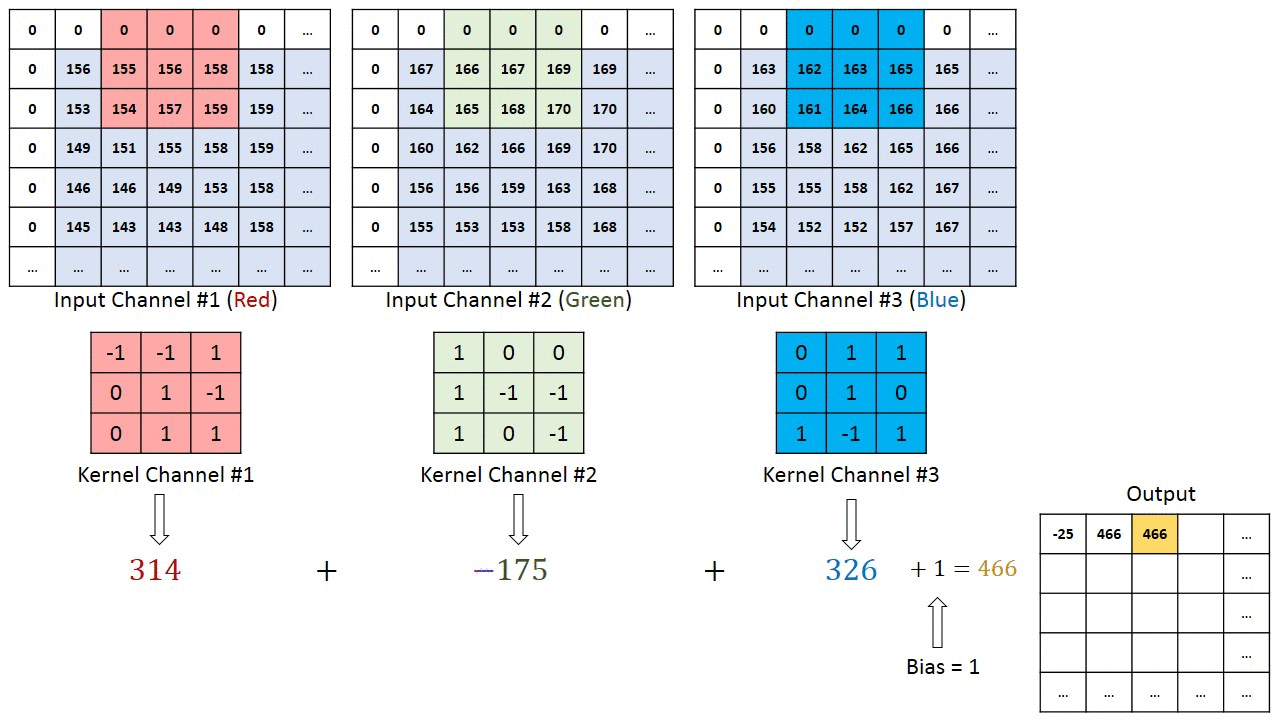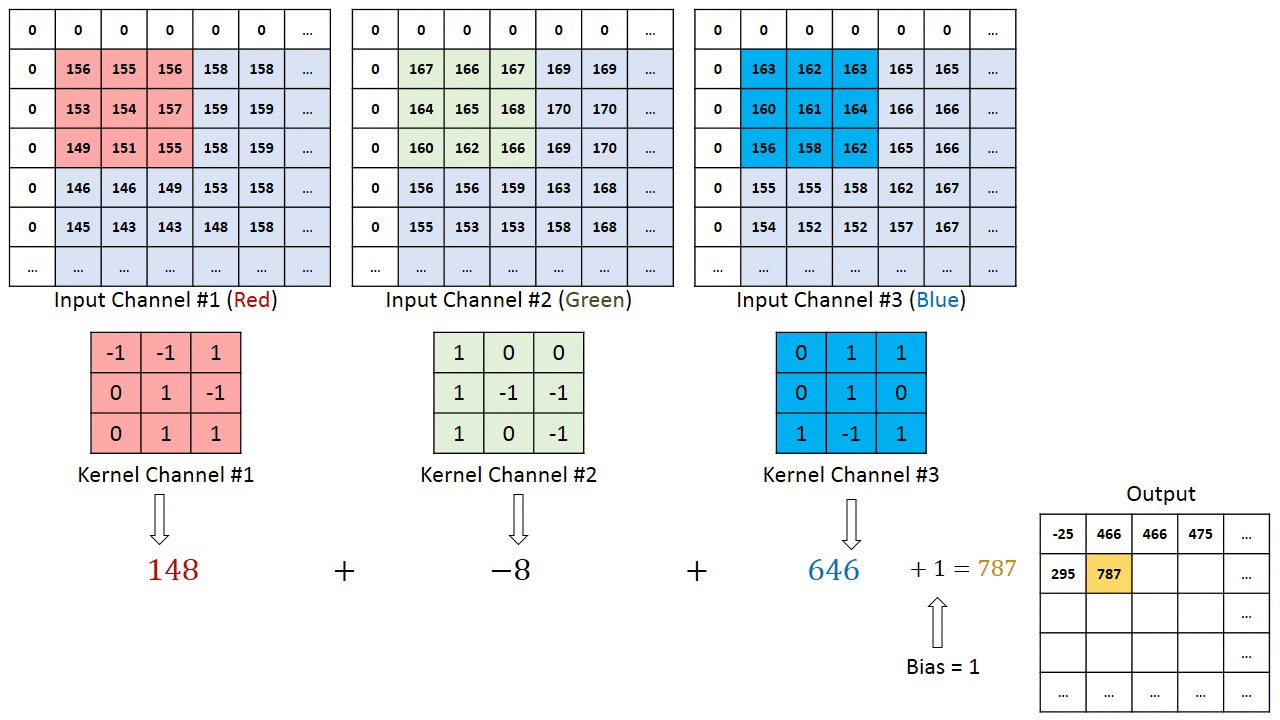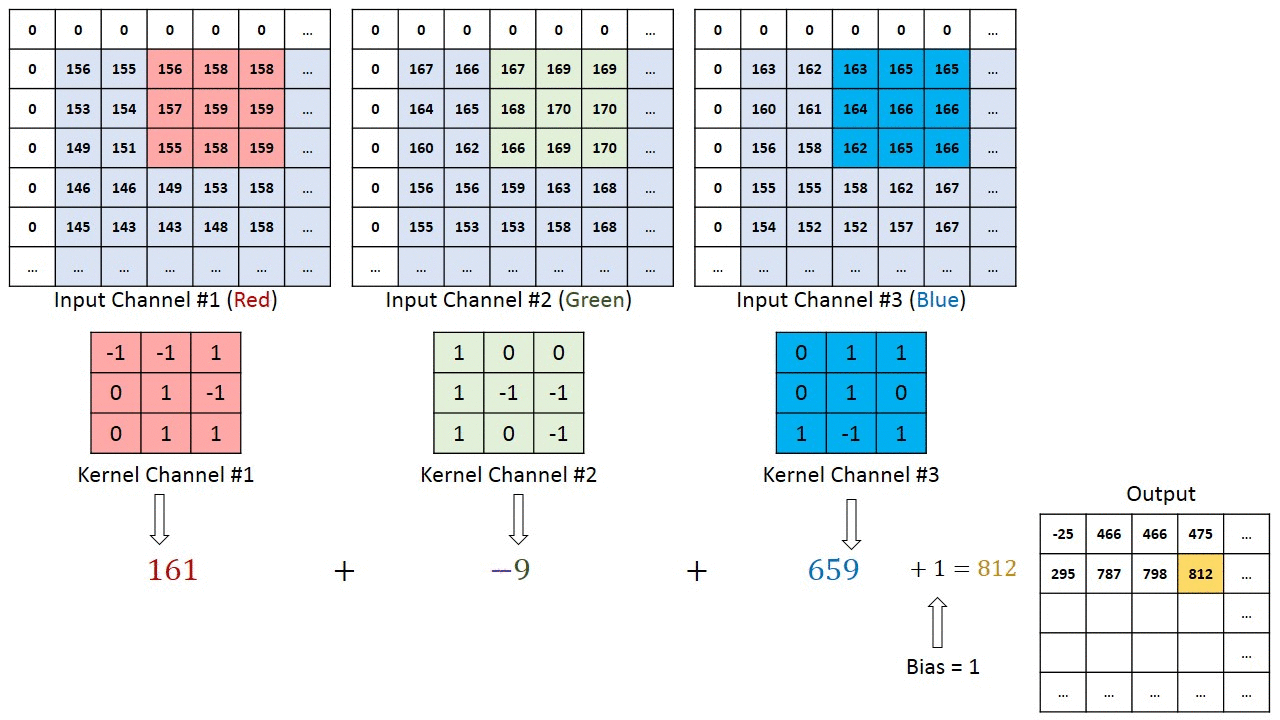
여러 채널이있는 이미지의 경우 (예 : RGB ) 커널은 입력 이미지와 동일한 깊이를 갖습니다. 행렬 곱셈은 Kn과 In 스택 (;;) 사이에서 수행되며 모든 결과는 편향으로 합산되어 스쿼시 된 1 심도 채널 복잡한 기능 출력을 제공합니다.
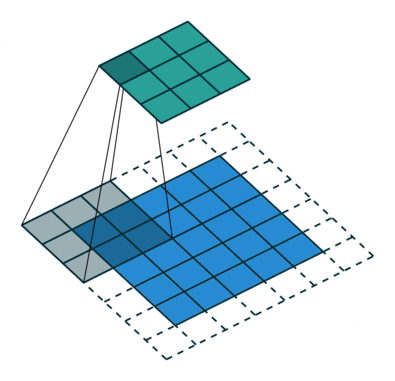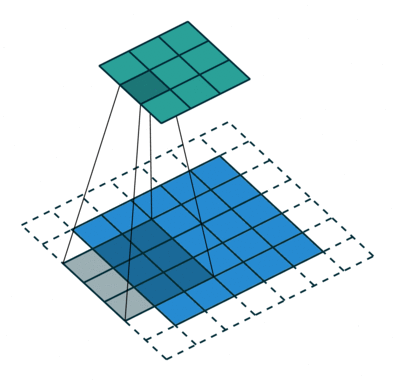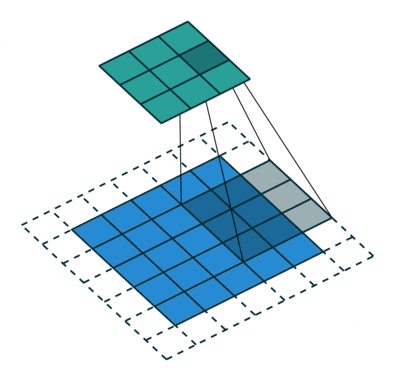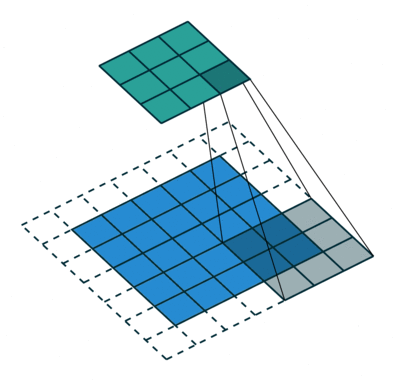
컨볼 루션 연산의 목적은 가장자리와 같은 고급 기능을 추출하는 것입니다. 입력 이미지에서. ConvNet은 하나의 Convolutional Layer로만 제한 될 필요는 없습니다. 일반적으로 첫 번째 ConvLayer는 가장자리, 색상, 그래디언트 방향 등과 같은 저수준 기능을 캡처하는 역할을합니다. 레이어가 추가되면 아키텍처는 고수준 기능에도 적응하여 건전한 이해를 가진 네트워크를 제공합니다. 작업 결과에는 두 가지 유형의 결과가 있습니다. 하나는 컨볼 브드 기능이 입력에 비해 차원이 감소하고 다른 하나는 차원은 증가하거나 동일하게 유지됩니다. 전자의 경우 유효한 패딩을 적용하거나 후자의 경우 동일한 패딩을 적용하여 수행됩니다.
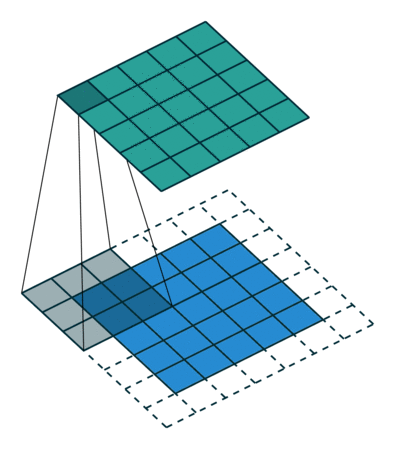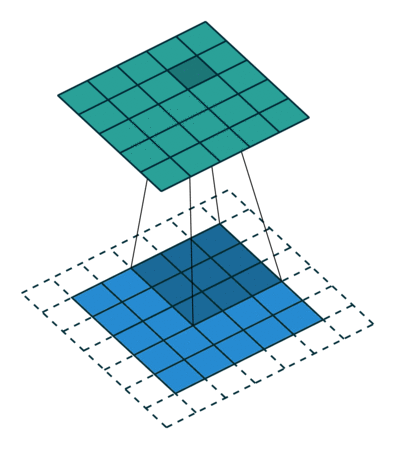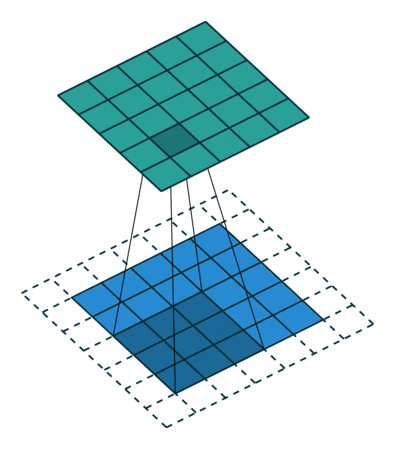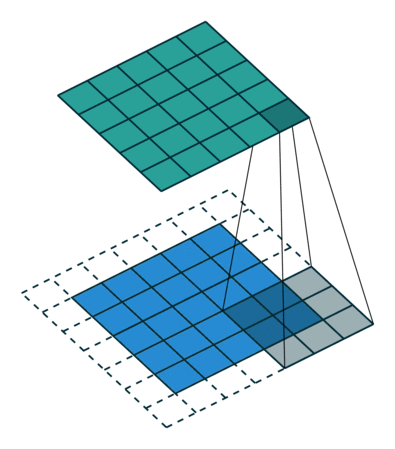
5x5x1 이미지를 6x6x1 이미지로 확대 한 다음 그 위에 3x3x1 커널을 적용하면 convolved matrix는 5x5x1 차원입니다. 따라서 이름은 동일한 패딩입니다.
반면에 패딩없이 동일한 작업을 수행하면 커널 (3x3x1) 자체의 차원 인 유효한 패딩 인 행렬이 표시됩니다.
p>
다음 저장소에는 패딩과 보폭이 함께 작동하여 우리의 요구에 맞는 결과를 얻는 방법을 더 잘 이해하는 데 도움이되는 많은 GIF가 있습니다.
풀링 레이어
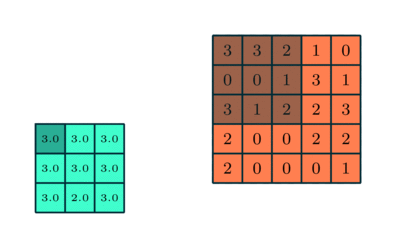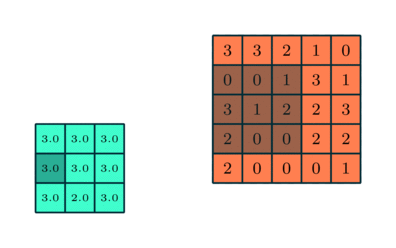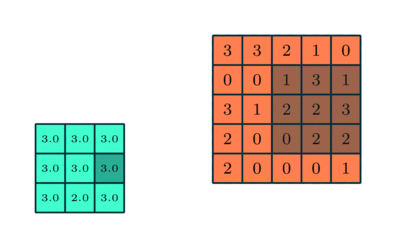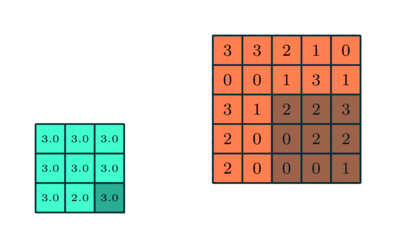
컨볼 루션 레이어와 유사, 풀링 레이어 Convolved Feature의 공간 크기를 줄이는 역할을합니다. 이는 차원 축소를 통해 데이터를 처리하는 데 필요한 계산 능력을 줄이기위한 것입니다. 또한 회전 및 위치 불변 인 주요 특성을 추출하여 모델을 효과적으로 학습하는 프로세스를 유지하는 데 유용합니다.
풀링에는 최대 풀링과 평균 풀링의 두 가지 유형이 있습니다. 최대 풀링은 커널이 포함하는 이미지 부분에서 최대 값을 반환합니다. 반면에 평균 풀링은 커널이 포함하는 이미지 부분에서 모든 값의 평균을 반환합니다.
최대 풀링은 노이즈 억제 기능도 수행합니다. 노이즈가있는 활성화를 모두 버리고 차원 감소와 함께 노이즈 제거를 수행합니다. 반면에 Average Pooling은 단순히 소음 억제 메커니즘으로 차원 감소를 수행합니다. 따라서 Max Pooling이 Average Pooling보다 훨씬 더 잘 수행된다고 말할 수 있습니다.
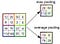
컨볼 루션 계층과 풀링 계층은 함께 컨볼 루션 신경망의 i 번째 계층을 형성합니다. 이미지의 복잡성에 따라 낮은 수준의 세부 정보를 캡처하기 위해 이러한 레이어의 수가 증가 할 수 있지만 더 많은 계산 능력이 필요합니다.
위의 과정을 거친 후에는 모델이 기능을 이해하는 데 성공했습니다. 계속해서 최종 출력을 평면화하고 분류 목적으로 일반 신경망에 공급할 것입니다.
분류 — 완전 연결 레이어 (FC 레이어)

Fully-Connected 레이어를 추가하는 것은 컨볼 루션 레이어의 출력으로 표현되는 고수준 기능의 비선형 조합을 배우는 저렴한 방법입니다. 완전 연결 계층은 해당 공간에서 가능한 비선형 함수를 학습하고 있습니다.
이제 입력 이미지를 다중 레벨 퍼셉트론에 적합한 형식으로 변환 했으므로 이미지를 열 벡터. 평탄화 된 출력은 피드 포워드 신경망에 공급되고 모든 훈련 반복에 적용되는 역 전파입니다. 일련의 시대에 걸쳐 모델은 이미지의 지배적 특징과 특정 저수준 특징을 구별하고 Softmax 분류 기술을 사용하여 분류 할 수 있습니다.
핵심적인 CNN의 다양한 아키텍처를 사용할 수 있습니다. 가까운 미래에 AI 전체를 강화하고 강화할 알고리즘을 구축합니다. 그중 일부는 다음과 같습니다.
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
