Quando si tratta di imparare, ci sono generalmente due approcci che si possono adottare: si può ampio e cerca di coprire il più possibile lo spettro di un campo, oppure puoi andare in profondità e cercare di diventare davvero, davvero specifico con l’argomento che stai imparando. La maggior parte dei bravi studenti sa che, in una certa misura, tutto ciò che impari nella vita – dagli algoritmi alle abilità di base della vita – implica una combinazione di questi due approcci.
Lo stesso vale per l’informatica, la risoluzione dei problemi, e strutture dati. La scorsa settimana, ci siamo immersi nella ricerca approfondita e abbiamo imparato cosa significa attraversare effettivamente un albero di ricerca binario. Ora che siamo andati in profondità, ha senso per noi andare oltre e comprendere l’altra strategia comune di attraversamento degli alberi.
In altre parole, è il momento che tutti stavate aspettando: è il momento per analizzare le basi della ricerca in base all’ampiezza!
Uno dei modi migliori per capire cos’è esattamente la ricerca in base all’ampiezza (BFS) è capire cosa non è. Vale a dire, se confrontiamo BFS con DFS, sarà molto più facile per noi tenerli dritti nella nostra testa. Quindi, rinfresciamo la nostra memoria della ricerca in profondità prima di andare oltre.
Sappiamo che la ricerca in profondità è il processo di attraversamento attraverso un ramo di un albero fino a quando non arriviamo a una foglia, e poi tornando al “tronco” dell’albero. In altre parole, implementare un DFS significa attraversare le sottostrutture di un albero di ricerca binario.
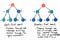
Ok, allora come funziona la ricerca in base all’ampiezza Beh, se ci pensiamo bene, l’unica vera alternativa al viaggio lungo un ramo di un albero e poi un altro è viaggiare lungo l’albero sezione per sezione o, livello per livello. Ed è esattamente ciò che è BFS !
La ricerca in ampiezza implica la ricerca in un albero un livello alla volta.
Noi attraversare prima un intero livello di nodi figli, prima di passare ad attraversare i nodi nipoti. E attraversiamo un intero livello di nodi dei nipoti prima di passare ai nodi dei pronipoti.
Va bene, sembra abbastanza chiaro. Cos’altro differenzia i due diversi tipi di algoritmi di attraversamento dell’albero? Bene, abbiamo già coperto le differenze nelle procedure di questi due algoritmi. Pensiamo all’altro aspetto importante di cui non abbiamo ancora parlato: l’implementazione.
Innanzitutto, iniziamo con ciò che sappiamo. Come abbiamo implementato la ricerca approfondita la scorsa settimana? Potresti ricordare che abbiamo imparato tre diversi metodi – inorder, postorder e preorder – per cercare attraverso un albero utilizzando DFS. Eppure c’era qualcosa di fantastico in quanto simili queste tre implementazioni; ciascuno di essi potrebbe essere impiegato usando la ricorsione. Sappiamo anche che, poiché DFS può essere scritto come una funzione ricorsiva, possono far crescere lo stack di chiamate fino a raggiungere le dimensioni del percorso più lungo dell’albero.
Tuttavia, c’era una cosa che ho lasciato uscito la scorsa settimana che sembra buono da far apparire ora (e forse è anche un po ‘ovvio!): lo stack di chiamate implementa effettivamente una struttura dati dello stack. Ricordi quelli? Abbiamo imparato a conoscere gli stack un po ‘di tempo fa, ma eccoli di nuovo, mostrati dappertutto!
La cosa davvero interessante dell’implementazione della ricerca in profondità usando uno stack è che mentre attraversiamo i sottoalberi di un albero di ricerca binario, ciascuno dei nodi che “controlliamo” o “visitiamo” viene aggiunto allo stack. Una volta raggiunto un nodo foglia, un nodo che non ha figli, iniziamo a estrarre i nodi dalla cima dello stack. Finiamo di nuovo al nodo radice, quindi possiamo continuare ad attraversare la sottostruttura successiva.

Nell’esempio di albero DFS sopra, noterai che i nodi 2, 3 e 4 vengono tutti aggiunti a la parte superiore della pila. Quando arriviamo alla “fine” di quella sottostruttura – vale a dire, quando raggiungiamo i nodi foglia di 3 e 4 – iniziamo a estrarre quei nodi dalla nostra pila di “nodi da visitare”.Puoi vedere cosa accadrà alla fine con la sottostruttura giusta: i nodi da visitare verranno inseriti nello stack di chiamate, li visiteremo e li elimineremo sistematicamente dallo stack.
Alla fine, una volta che avremo abbiamo visitato sia il sottoalbero sinistro che quello destro, torneremo al nodo radice senza niente da controllare e il nostro stack di chiamate sarà vuoto.
Quindi, dovremmo essere in grado di usare un impilare la struttura e fare qualcosa di simile con la nostra implementazione BFS … giusto? Beh, non so se funzionerà, ma penso che sarà utile almeno iniziare disegnando l’algoritmo che vogliamo implementare e vedendo fino a che punto possiamo arrivare con esso.
Proviamo:

Ok, quindi abbiamo un grafico a sinistra in cui abbiamo implementato DFS la scorsa settimana. Come potremmo invece utilizzare un algoritmo BFS su di esso?
Bene, per iniziare, sappiamo che vogliamo prima controllare il nodo radice. Questo è l’unico nodo a cui avremo accesso inizialmente, quindi “punteremo” al nodo f.
Bene, ora dovremo controllare i figli di questo nodo radice.
Vogliamo controllare un figlio dopo l’altro, quindi andiamo prima al figlio a sinistra: il nodo d è il nodo a cui stiamo “puntando” ora (e l’unico nodo a cui abbiamo accesso).
Successivamente, vorremo andare al nodo figlio destro.
Uh oh. Aspetta, il nodo radice non è nemmeno più disponibile per noi! E non possiamo muoverci al contrario, perché gli alberi binari non hanno collegamenti inversi! Come arriveremo al nodo figlio giusto? E … oh no, il nodo figlio sinistro de il nodo figlio destro k non sono affatto collegati. Quindi, ciò significa che è impossibile per noi passare da un bambino all’altro perché non abbiamo accesso a nulla tranne che ai figli del nodo d.
Oh cielo. Non siamo andati molto lontano, vero? Dobbiamo trovare un metodo diverso per risolvere questo problema. Dobbiamo trovare un modo per implementare un attraversamento dell’albero che ci consenta di percorrere l’albero in ordine di livello. La cosa più importante che dobbiamo tenere a mente è questa:
Dobbiamo mantenere un riferimento a tutti i nodi figli di ogni nodo che visitiamo. Altrimenti, non saremo mai in grado di tornare da loro più tardi e visitarli!
Più ci penso, più mi sento come è come se volessimo mantenere un elenco di tutti i nodi che dobbiamo ancora controllare, non è vero? E nel momento in cui voglio tenere un elenco di qualcosa, la mia mente passa immediatamente a una struttura di dati in particolare: una coda, ovviamente!
Vediamo se le code possono aiutarci con la nostra implementazione BFS.
Code in soccorso!
A quanto pare, una delle principali differenze nella ricerca in profondità e in quella in ampiezza è la struttura dei dati utilizzata per implementare entrambi questi algoritmi molto diversi.
Mentre DFS utilizza una struttura di dati dello stack, BFS si appoggia alla struttura dei dati della coda. La cosa bella dell’utilizzo delle code è che risolve proprio il problema che abbiamo scoperto in precedenza: ci permette di mantenere un riferimento ai nodi a cui vogliamo tornare, anche se non li abbiamo ancora controllati / visitati.
Aggiungiamo i nodi che abbiamo scoperto, ma non ancora visitato, alla nostra coda e torniamo su di essi più tardi.
Un termine comune per i nodi che aggiungiamo alla nostra coda è nodi scoperti; un nodo scoperto è quello che aggiungiamo alla nostra coda, di cui conosciamo la posizione, ma che dobbiamo ancora visitare effettivamente. In effetti, questo è esattamente ciò che rende una coda la struttura perfetta per risolvere il problema BFS.

Nel grafico a sinistra, iniziamo aggiungendo il nodo radice alla nostra coda, poiché è l’unico nodo che abbiamo mai avere accesso (almeno, inizialmente) in un albero. Ciò significa che il nodo radice è l’unico nodo scoperto da avviare.
Dopo aver accodato almeno un nodo, possiamo avviare il processo di visita dei nodi e aggiungere riferimenti ai loro nodi figli nella nostra coda.
Ok, quindi tutto questo potrebbe sembrare un po ‘confuso. E va bene così! Penso che sarà molto più facile da capire se lo suddividiamo in passaggi più semplici.
Per ogni nodo nella nostra coda, iniziando sempre con il nodo radice, vorremo fare tre cose:
- Visita il nodo, che di solito significa solo stampare il suo valore.
- Aggiungi il figlio sinistro del nodo alla nostra coda.
- Aggiungi il nodo destro child alla nostra coda.
Una volta fatte queste tre cose, possiamo rimuovere il nodo dalla nostra coda, perché non ne abbiamo più bisogno!Fondamentalmente dobbiamo continuare a farlo ripetutamente fino a quando non arriviamo al punto in cui la nostra coda è vuota.
Ok, guardiamo questo in azione!
Nel grafico sotto, iniziamo spento con il nodo radice, nodo f, come unico nodo scoperto. Ricordi i nostri tre passaggi? Facciamoli ora:
- Visiteremo il nodo f e stamperemo il suo valore.
- Accoderemo un riferimento al suo figlio sinistro, il nodo d.
- Accoderemo un riferimento al suo figlio destro, il nodo k.
E poi, rimuoveremo il nodo f dalla nostra coda!

Il nodo successivo all’inizio della coda è il nodo d. Ancora una volta, gli stessi tre passaggi qui: stampa il suo valore, aggiungi il suo figlio sinistro, aggiungi il suo figlio destro e poi rimuovilo dalla coda.
La nostra coda ora ha riferimenti ai nodi k, be e . Se continuiamo a ripetere questo processo in modo sistematico, noteremo che stiamo effettivamente attraversando il grafico e stampando i nodi in ordine di livello. Evviva! Questo è esattamente ciò che volevamo fare in primo luogo.
La chiave per funzionare così bene è la natura stessa della struttura della coda. Le code seguono il principio FIFO (first-in, first-out), il che significa che tutto ciò che è stato accodato per primo è il primo elemento che verrà letto e rimosso dalla coda.
Infine, mentre siamo in tema di code, vale la pena ricordare che la complessità spazio-temporale di un algoritmo BFS è anche correlata alla coda che utilizziamo per implementarlo – chi sapeva che le code sarebbero tornate essere così utile, vero?
La complessità temporale di un algoritmo BFS dipende direttamente da quanto tempo ci vuole per visitare un nodo. Poiché il tempo necessario per leggere il valore di un nodo e accodare i suoi figli non cambia in base al nodo, possiamo dire che visitare un nodo richiede tempo costante, o tempo O (1). Dal momento che visitiamo ogni nodo in un attraversamento di un albero BFS esattamente una volta, il tempo necessario per leggere ogni nodo dipende in realtà solo da quanti nodi ci sono nell’albero! Se il nostro albero ha 15 nodi, ci vorrà O (15); ma se il nostro albero ha 1500 nodi, ci vorrà O (1500). Pertanto, la complessità temporale di un algoritmo di ricerca in ampiezza richiede tempo lineare, o O (n), dove n è il numero di nodi nell’albero.
La complessità dello spazio è simile a questa, ha più da fare con quanto la nostra coda cresce e si riduce man mano che aggiungiamo i nodi che dobbiamo controllare. Nella peggiore delle ipotesi, potremmo potenzialmente accodare tutti i nodi di un albero se sono tutti figli l’uno dell’altro, il che significa che potremmo utilizzare tanta memoria quanti sono i nodi dell’albero. Se la dimensione della coda può crescere fino a essere il numero di nodi nell’albero, anche la complessità dello spazio per un algoritmo BFS è tempo lineare, o O (n), dove n è il numero di nodi nell’albero.
Va tutto bene, ma sai cosa mi piacerebbe davvero fare adesso? Vorrei effettivamente scrivere uno di questi algoritmi! Mettiamo finalmente in pratica tutta questa teoria.
Codifica il nostro primo algoritmo di ricerca in ampiezza
Ce l’abbiamo fatta! Finalmente codificheremo il nostro primo algoritmo BFS. Abbiamo fatto un po ‘di questo la scorsa settimana con algoritmi DFS, quindi proviamo a scrivere un’implementazione di ricerca ampia anche di questo.
Potresti ricordare che lo abbiamo scritto in JavaScript vanilla la scorsa settimana, quindi continueremo di nuovo con quello per coerenza. Nel caso avessi bisogno di un rapido aggiornamento, abbiamo deciso di mantenerlo semplice e di scrivere i nostri oggetti nodo come Plain Old JavaScript Objects (POJO), in questo modo:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
Va bene, va bene. Un passaggio fatto.
Ma ora che sappiamo delle code e siamo certi che avremo bisogno di usarne uno per implementare questo algoritmo … dovremmo probabilmente capire come farlo in JavaScript, giusto? Bene, a quanto pare, è davvero facile creare un oggetto simile a una coda in JS!
Possiamo usare un array, che fa il trucco abbastanza bene:
Se volessimo renderlo un po ‘più elaborato, probabilmente potremmo anche creare un Queue oggetto, che potrebbe avere funzioni utili come top o isEmpty; ma, per ora, faremo affidamento su funzionalità molto semplici.
Ok, scriviamo questo cucciolo! Creeremo una funzione levelOrderSearch, che accetta un rootNode oggetto.
Fantastico! Questo è in realtà … abbastanza semplice. O almeno, molto più semplice di quanto mi aspettassi. Tutto ciò che stiamo facendo qui è utilizzare un ciclo while per continuare a eseguire questi tre passaggi di controllo di un nodo, aggiungendo il suo figlio sinistro e aggiungendo il suo figlio destro.Continuiamo a iterare attraverso l’array queue fino a quando tutto è stato rimosso da esso e la sua lunghezza è 0.
Sorprendente. La nostra esperienza in materia di algoritmi è salita alle stelle in un solo giorno! Non solo sappiamo come scrivere algoritmi ricorsivi di attraversamento dell’albero, ma ora sappiamo anche come scrivere quelli iterativi. Chi sapeva che le ricerche algoritmiche potessero essere così potenti!
Risorse
C’è ancora molto da imparare sulla ricerca in ampiezza e quando può essere utile. Fortunatamente, ci sono tonnellate di risorse che trattano informazioni che non sono riuscito a inserire in questo post. Dai un’occhiata ad alcuni di quelli veramente buoni di seguito.
- Algoritmi DFS e BFS che utilizzano stack e code, Professor Lawrence L. Larmore
- L’algoritmo di ricerca Breadth-First, Khan Academy
- Struttura dei dati – Ampiezza del primo attraversamento, TutorialsPoint
- Albero binario: Attraversamento dell’ordine dei livelli, mycodeschool
- Attraversamento della prima larghezza di un albero, Dipartimento di informatica di Boston University
