Quand il s’agit d’apprendre, il y a généralement deux approches que l’on peut adopter: vous pouvez soit large, et essayez de couvrir autant que possible le spectre d’un domaine, ou vous pouvez aller plus loin et essayer d’être vraiment, vraiment spécifique avec le sujet que vous apprenez. La plupart des bons apprenants savent que, dans une certaine mesure, tout ce que vous apprenez dans la vie – des algorithmes aux compétences de base – implique une combinaison de ces deux approches.
Il en va de même pour l’informatique, la résolution de problèmes, et les structures de données. La semaine dernière, nous avons plongé dans la recherche en profondeur d’abord et avons appris ce que signifie réellement traverser un arbre de recherche binaire. Maintenant que nous sommes allés en profondeur, il est logique pour nous d’aller plus loin et de comprendre l’autre stratégie commune de traversée des arbres.
En d’autres termes, c’est le moment que vous attendiez tous: il est temps pour décomposer les bases de la recherche en largeur d’abord!
Une des meilleures façons de comprendre ce qu’est exactement la recherche en largeur d’abord (BFS) est de comprendre ce qu’elle n’est pas. Autrement dit, si nous comparons BFS à DFS, il nous sera beaucoup plus facile de les garder en tête. Alors, rafraîchissons notre mémoire de la recherche en profondeur avant d’aller plus loin.
Nous savons que la recherche en profondeur est le processus de traverser une branche d’un arbre jusqu’à ce que nous arrivions à une feuille, puis revenir au «tronc» de l’arbre. En d’autres termes, implémenter un DFS signifie parcourir les sous-arbres d’un arbre de recherche binaire.
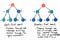
D’accord, alors comment fonctionne la recherche en largeur d’abord Si nous y réfléchissons, la seule vraie alternative pour descendre une branche d’un arbre, puis une autre est de parcourir l’arborescence section par section – ou niveau par niveau. Et c’est exactement ce qu’est BFS !
La recherche en largeur d’abord implique une recherche dans un arbre un niveau à la fois.
Nous traversez d’abord un niveau entier de nœuds enfants, avant de passer à travers les nœuds petits-enfants. Et nous traversons tout un niveau de nœuds petits-enfants avant de passer à travers les nœuds arrière-petits-enfants.
D’accord, cela semble assez clair. Qu’est-ce qui différencie les deux types d’algorithmes de traversée d’arbres? Eh bien, nous avons déjà couvert les différences dans les procédures de ces deux algorithmes. Pensons à l’autre aspect important dont nous n’avons pas encore parlé: la mise en œuvre.
Commençons par ce que nous savons. Comment avons-nous mis en œuvre la recherche en profondeur la semaine dernière? Vous vous souvenez peut-être que nous avons appris trois méthodes différentes – en ordre, en post-ordre et en précommande – de recherche dans un arbre à l’aide de DFS. Pourtant, il y avait quelque chose de super cool dans la similitude de ces trois implémentations; ils pourraient chacun être utilisés en utilisant la récursivité. Nous savons également que, puisque DFS peut être écrit comme une fonction récursive, il peut faire en sorte que la pile d’appels devienne aussi grande que le chemin le plus long de l’arbre.
Cependant, il y avait une chose que j’ai laissée la semaine dernière, cela semble bon à évoquer maintenant (et c’est peut-être même un peu évident!): la pile d’appels implémente en fait une structure de données de pile. Vous vous en souvenez? Nous avons appris l’existence des piles il y a un certain temps, mais les voici encore, qui apparaissent partout!
La chose vraiment intéressante à propos de l’implémentation d’une recherche en profondeur en utilisant une pile est que lorsque nous traversons les sous-arbres d’un arbre de recherche binaire, chacun des nœuds que nous «vérifions» ou «visitons» est ajouté à la pile. Une fois que nous atteignons un nœud feuille – un nœud qui n’a pas d’enfants – nous commençons à faire sauter les nœuds du haut de la pile. Nous nous retrouvons à nouveau au nœud racine, puis nous pouvons continuer à traverser le sous-arbre suivant.

Dans l’exemple d’arborescence DFS ci-dessus, vous remarquerez que les nœuds 2, 3 et 4 sont tous ajoutés le haut de la pile. Lorsque nous arrivons à la « fin » de ce sous-arbre – c’est-à-dire lorsque nous atteignons les nœuds feuilles de 3 et 4 – nous commençons à faire sauter ces nœuds de notre pile de « nœuds à visiter ».Vous pouvez voir ce qui se passera finalement avec le bon sous-arbre: les nœuds à visiter seront poussés sur la pile d’appels, nous les visiterons et les sortirons systématiquement de la pile.
Finalement, une fois que nous ‘ai visité les sous-arbres gauche et droit, nous serons de retour au nœud racine avec rien à vérifier, et notre pile d’appels sera vide.
Donc, nous devrions être en mesure d’utiliser un structure de la pile et faire quelque chose de similaire avec notre implémentation BFS… non? Eh bien, je ne sais pas si cela fonctionnera, mais je pense qu’il sera utile au moins de commencer par dessiner l’algorithme que nous voulons implémenter et de voir jusqu’où nous pouvons aller avec.
Essayons:

D’accord, nous avons donc un graphique à gauche sur lequel nous avons implémenté DFS la semaine dernière. Comment pourrions-nous utiliser un algorithme BFS dessus?
Eh bien, pour commencer, nous savons que nous voulons d’abord vérifier le nœud racine. C’est le seul nœud auquel nous aurons accès au départ, et nous allons donc « pointer » vers le nœud f.
D’accord, nous allons maintenant devoir vérifier les enfants de ce nœud racine.
Nous voulons vérifier un enfant après l’autre, alors allons d’abord à l’enfant de gauche – le nœud d est le nœud vers lequel nous « pointons » maintenant (et le seul nœud auquel nous avons accès).
Ensuite, nous allons vouloir aller au bon nœud enfant.
Oh oh. Attendez, le nœud racine n’est même plus disponible pour nous! Et nous ne pouvons pas faire marche arrière, car les arbres binaires n’ont pas de liens inverses! Comment allons-nous arriver au bon nœud enfant? Et… oh non, le nœud enfant gauche d et le nœud enfant droit k ne sont pas du tout liés. Donc, cela signifie qu’il est impossible pour nous de passer d’un enfant à l’autre car nous n’avons accès à rien sauf aux enfants des nœuds.
Oh là là. Nous ne sommes pas allés très loin, n’est-ce pas? Nous devrons trouver une méthode différente pour résoudre ce problème. Nous devons trouver un moyen d’implémenter une traversée d’arbre qui nous permettra de parcourir l’arbre dans l’ordre des niveaux. La chose la plus importante que nous devons garder à l’esprit est la suivante:
Nous devons garder une référence à tous les nœuds enfants de chaque nœud que nous visitons. Sinon, nous ne pourrons jamais y revenir plus tard et leur rendre visite!
Plus j’y pense, plus j’ai envie c’est comme si nous voulions garder une liste de tous les nœuds que nous devons encore vérifier, n’est-ce pas? Et au moment où je veux garder une liste de quelque chose, mon esprit passe immédiatement à une structure de données en particulier: une file d’attente, bien sûr!
Voyons si les files d’attente peuvent nous aider avec notre implémentation BFS.
Les files d’attente à la rescousse!
En fait, une différence majeure entre la recherche en profondeur d’abord et la recherche en largeur d’abord est la structure de données utilisée pour implémenter ces deux algorithmes très différents.
Alors que DFS utilise une structure de données de pile, BFS s’appuie sur la structure de données de file d’attente. L’avantage d’utiliser les files d’attente est que cela résout le problème même que nous avons découvert plus tôt: cela nous permet de conserver une référence aux nœuds sur lesquels nous voulons revenir, même si nous ne les avons pas encore vérifiés / visités.
Nous ajoutons les nœuds que nous avons découverts – mais pas encore visités – à notre file d’attente, et y revenons plus tard.
Un terme courant pour les nœuds que nous ajoutons à notre file d’attente est les nœuds découverts; un nœud découvert est celui que nous ajoutons à notre file d’attente, dont nous connaissons l’emplacement, mais que nous n’avons pas encore visité. En fait, c’est exactement ce qui fait d’une file d’attente la structure parfaite pour résoudre le problème BFS.

Dans le graphique de gauche, nous commençons par ajouter le nœud racine à notre file d’attente, car c’est le seul nœud que nous ayons jamais avoir accès (au moins, initialement) dans un arbre. Cela signifie que le nœud racine est le seul nœud découvert à démarrer.
Une fois que nous avons au moins un nœud mis en file d’attente, nous pouvons démarrer le processus de visite des nœuds et d’ajouter des références à leurs nœuds enfants dans notre file d’attente.
D’accord, donc tout cela peut sembler un peu déroutant. Et ça va! Je pense que ce sera beaucoup plus facile à comprendre si nous le décomposons en étapes plus simples.
Pour chaque nœud de notre file d’attente – en commençant toujours par le nœud racine – nous voudrons faire trois choses:
- Visitez le nœud, ce qui signifie généralement simplement imprimer sa valeur.
- Ajoutez l’enfant gauche du nœud à notre file d’attente.
- Ajoutez le nœud droit du nœud child dans notre file d’attente.
Une fois que nous avons fait ces trois choses, nous pouvons supprimer le nœud de notre file d’attente, car nous n’en avons plus besoin!Nous devons essentiellement continuer à le faire à plusieurs reprises jusqu’à ce que nous arrivions au point où notre file d’attente est vide.
D’accord, regardons cela en action!
Dans le graphique ci-dessous, nous commençons désactivé avec le nœud racine, nœud f, comme seul nœud découvert. Vous vous souvenez de nos trois étapes? Faisons-les maintenant:
- Nous allons visiter le nœud f et afficher sa valeur.
- Nous allons mettre en file d’attente une référence à son enfant gauche, le nœud d.
- Nous allons mettre en file d’attente une référence à son enfant droit, le nœud k.
Et puis, nous supprimerons le nœud f de notre file d’attente!

Le nœud suivant au début de la file d’attente est le nœud d. Encore une fois, les trois mêmes étapes ici: imprimer sa valeur, ajouter son enfant gauche, ajouter son enfant droit, puis le supprimer de la file d’attente.
Notre file d’attente a maintenant des références aux nœuds k, b et e . Si nous répétons systématiquement ce processus, nous remarquerons que nous parcourons en fait le graphique et imprimons les nœuds dans l’ordre des niveaux. Hourra! C’est exactement ce que nous voulions faire en premier lieu.
La clé de ce fonctionnement si efficace est la nature même de la structure de la file d’attente. Les files d’attente suivent le principe du premier entré, premier sorti (FIFO), ce qui signifie que tout ce qui a été mis en file d’attente en premier est le premier élément qui sera lu et supprimé de la file d’attente.
Enfin, alors que nous sommes sur le sujet des files d’attente, il convient de mentionner que la complexité espace-temps d’un algorithme BFS est également liée à la file d’attente que nous utilisons pour l’implémenter – qui savait que les files d’attente reviendraient pour être si utile, non?
La complexité temporelle d’un algorithme BFS dépend directement du temps qu’il faut pour visiter un nœud. Étant donné que le temps nécessaire pour lire la valeur d’un nœud et mettre ses enfants en file d’attente ne change pas en fonction du nœud, nous pouvons dire que la visite d’un nœud prend un temps constant, ou un temps O (1). Puisque nous ne visitons chaque nœud dans une traversée d’arbre BFS qu’une seule fois, le temps qu’il nous faudra pour lire chaque nœud dépend vraiment du nombre de nœuds qu’il y a dans l’arbre! Si notre arbre a 15 nœuds, il nous prendra O (15); mais si notre arbre a 1500 nœuds, il nous faudra O (1500). Ainsi, la complexité temporelle d’un algorithme de recherche en largeur d’abord prend un temps linéaire, ou O (n), où n est le nombre de nœuds dans l’arbre.
La complexité spatiale est similaire à ceci, a plus à faites avec la croissance et la réduction de notre file d’attente à mesure que nous y ajoutons les nœuds que nous devons vérifier. Dans le pire des cas, nous pourrions potentiellement mettre en file d’attente tous les nœuds d’un arbre s’ils sont tous enfants les uns des autres, ce qui signifie que nous pourrions éventuellement utiliser autant de mémoire qu’il y a de nœuds dans l’arbre. Si la taille de la file d’attente peut devenir le nombre de nœuds dans l’arborescence, la complexité de l’espace pour un algorithme BFS est également le temps linéaire, ou O (n), où n est le nombre de nœuds dans l’arborescence.
C’est bien beau, mais tu sais ce que j’aimerais vraiment faire maintenant? J’aimerais en fait écrire un de ces algorithmes! Mettons enfin toute cette théorie en pratique.
Codage de notre premier algorithme de recherche en largeur d’abord
Nous l’avons fait! Nous allons enfin coder notre tout premier algorithme BFS. Nous avons fait un peu de cela la semaine dernière avec les algorithmes DFS, alors essayons d’écrire une implémentation de recherche en largeur d’abord.
Vous vous souviendrez peut-être que nous avons écrit ceci en JavaScript vanille la semaine dernière, donc nous nous en tiendrons à cela pour des raisons de cohérence. Au cas où vous auriez besoin d’un rappel rapide, nous avons décidé de garder les choses simples et d’écrire nos objets nœuds comme des objets JavaScript simples (POJO), comme ceci:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
D’accord, cool. Une étape est faite.
Mais maintenant que nous connaissons les files d’attente et que nous sommes certains que nous devrons en utiliser une pour implémenter cet algorithme… nous devrions probablement trouver comment faire cela en JavaScript, n’est-ce pas? Eh bien, il s’avère que c’est vraiment facile de créer un objet de type file d’attente dans JS!
Nous pouvons utiliser un tableau, ce qui fait très bien l’affaire:
Si nous voulions rendre cela un peu plus sophistiqué, nous pourrions probablement aussi créer un objet Queue, qui pourrait avoir une fonction pratique comme top ou isEmpty; mais, pour l’instant, nous allons nous appuyer sur des fonctionnalités très simples.
D’accord, écrivons ce chiot! Nous allons créer une fonction levelOrderSearch, qui prend un objet rootNode.
Génial! C’est en fait… assez simple. Ou du moins, beaucoup plus simple que ce à quoi je m’attendais. Tout ce que nous faisons ici, c’est d’utiliser une boucle while pour continuer à faire ces trois étapes de vérification d’un nœud, d’ajouter son enfant gauche et d’ajouter son enfant droit.Nous continuons à parcourir le tableau queue jusqu’à ce que tout en ait été supprimé et que sa longueur soit 0.
Incroyable. Notre expertise en algorithmes a grimpé en flèche en une journée! Non seulement nous savons comment écrire des algorithmes de traversée d’arbres récursifs, mais maintenant nous savons également comment écrire des algorithmes itératifs. Qui savait que les recherches algorithmiques pouvaient être si stimulantes!
Ressources
Il y a encore beaucoup à apprendre sur la recherche en largeur d’abord, et quand elle peut être utile. Heureusement, il existe des tonnes de ressources qui couvrent des informations que je ne pourrais pas intégrer dans ce message. Découvrez quelques-uns des très bons ci-dessous.
- Algorithmes DFS et BFS utilisant des piles et des files d’attente, professeur Lawrence L. Larmore
- L’algorithme de recherche en largeur d’abord, Khan Academy
- Data Structure – Breadth First Traversal, TutorialsPoint
- Arbre binaire: Level Order Traversal, mycodeschool
- Breadth-First Traversal of a Tree, Département d’informatique de Université de Boston
