Kunstig intelligens har været vidne til en monumental vækst i at bygge bro over kløften mellem menneskers og maskiners muligheder. Forskere og entusiaster arbejder på adskillige aspekter af feltet for at få fantastiske ting til at ske. Et af mange sådanne områder er computervisionens domæne.
Dagsordenen for dette felt er at sætte maskiner i stand til at se verden som mennesker gør, opfatte den på en lignende måde og endda bruge viden til en lang række af opgaver såsom billede & Videogenkendelse, billedanalyse & Klassifikation, mediarekreation, anbefalingssystemer, behandling af naturlige sprog osv. Fremskridtene i Computer Vision with Deep Learning er konstrueret og perfektioneret med tiden, primært over en bestemt algoritme – et Convolutional Neural Network.
Introduktion

A Convolutional Neural Network (ConvNet / CNN) er en dyb læring algoritme, der kan optage et inputbillede, tildele betydning (lær vægte og bias) til forskellige aspekter / objekter i billedet og være i stand til at skelne det ene fra det andet. Forbehandlingen, der kræves i et ConvNet, er meget lavere sammenlignet med andre klassificeringsalgoritmer. Mens filtre i primitive metoder er hånddesignede, med tilstrækkelig træning, har ConvNets evnen til at lære disse filtre / karakteristika.
Arkitekturen i et ConvNet er analog med det tilslutningsmønster for neuroner i det menneskelige Hjernen og blev inspireret af organisationen af Visual Cortex. Individuelle neuroner reagerer kun på stimuli i et begrænset område af synsfeltet kendt som det modtagende felt. En samling af sådanne felter overlapper hinanden for at dække hele det visuelle område.
Hvorfor ConvNets over feed-forward neurale net?

Et billede er ikke andet end en matrix med pixelværdier, ikke? Så hvorfor ikke bare flade billedet (f.eks. 3×3 billedmatrix i en 9×1-vektor) og føre det til en Multi-Level Perceptron til klassificeringsformål? Uh .. ikke rigtig.
I tilfælde af ekstremt grundlæggende binære billeder kan metoden muligvis vise en gennemsnitlig præcisionsscore under udskrivning af klasser, men ville have ringe eller ingen nøjagtighed, når det kommer til komplekse billeder med pixelafhængighed hele vejen igennem.
Et ConvNet er i stand til at opfange de geografiske og tidsmæssige afhængigheder i et billede ved anvendelse af relevante filtre. Arkitekturen udfører en bedre tilpasning til billeddatasættet på grund af reduktion i antallet af involverede parametre og genanvendelighed af vægte. Med andre ord kan netværket trænes i at forstå billedets raffinement bedre.
Inputbillede

I figuren har vi et RGB-billede, der er adskilt af dets tre farveplaner – rød, grøn, og blå. Der er et antal af sådanne farverum, hvor der findes billeder – Gråtoner, RGB, HSV, CMYK osv.
Du kan forestille dig, hvordan beregningsintensive ting ville få, når billederne når dimensioner, siger 8K (7680 × 4320). ConvNets rolle er at reducere billederne til en form, der er lettere at behandle uden at miste funktioner, der er kritiske for at få en god forudsigelse. Dette er vigtigt, når vi skal designe en arkitektur, der ikke kun er god til at lære funktioner, men også er skalerbar til massive datasæt.
Convolution Layer – The Kernel
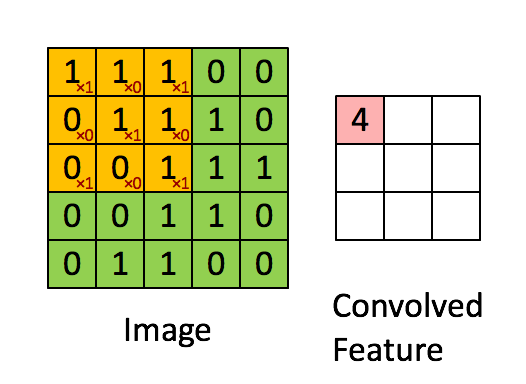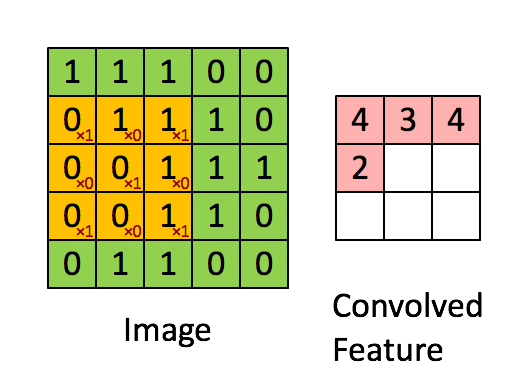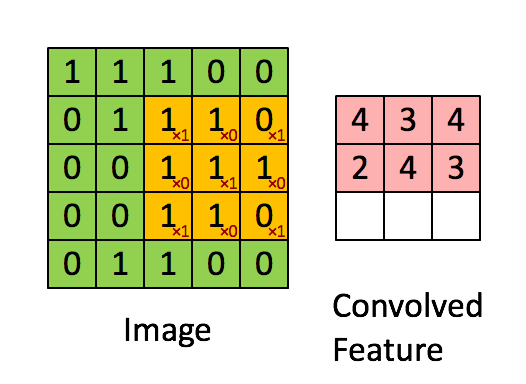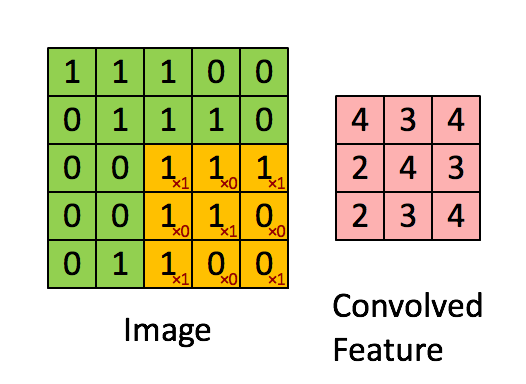
Billede Dimensioner = 5 (højde) x 5 (bredde) x 1 (antal kanaler, f.eks. RGB)
I ovenstående demonstration ligner det grønne afsnit vores 5x5x1 inputbillede, I. Elementet involveret i at bære ud af konvolutionsoperationen i den første del af et Convolutional Layer kaldes Kernel / Filter, K, repræsenteret i farven gul. Vi har valgt K som en 3x3x1 matrix.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
Kernen skifter 9 gange på grund af skridtlængde = 1 (ikke-stridet), hver gang der udføres en matrix multiplikationsoperation mellem K og den del P af billedet, som kernen svæver over.

Filteret flytter til højre med en vis skridtværdi, indtil den analyserer hele bredden. Når vi går videre, hopper det ned til begyndelsen (til venstre) af billedet med den samme skridtværdi og gentager processen, indtil hele billedet krydses.
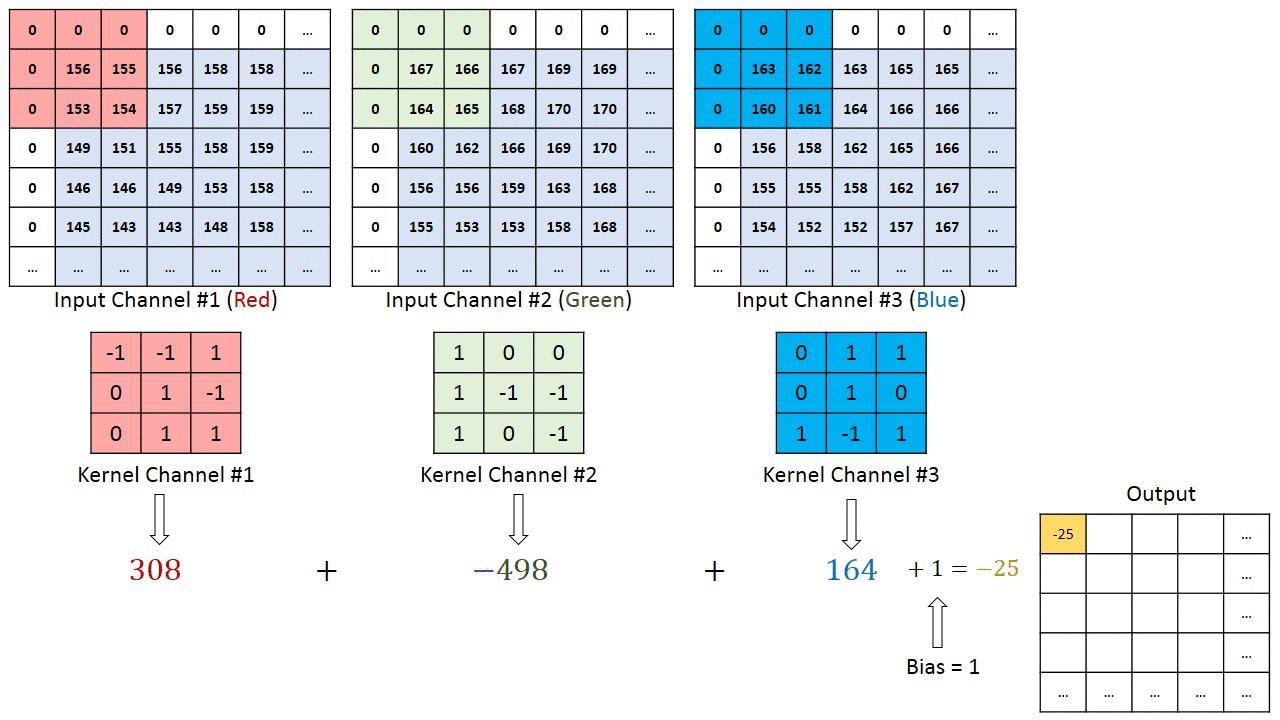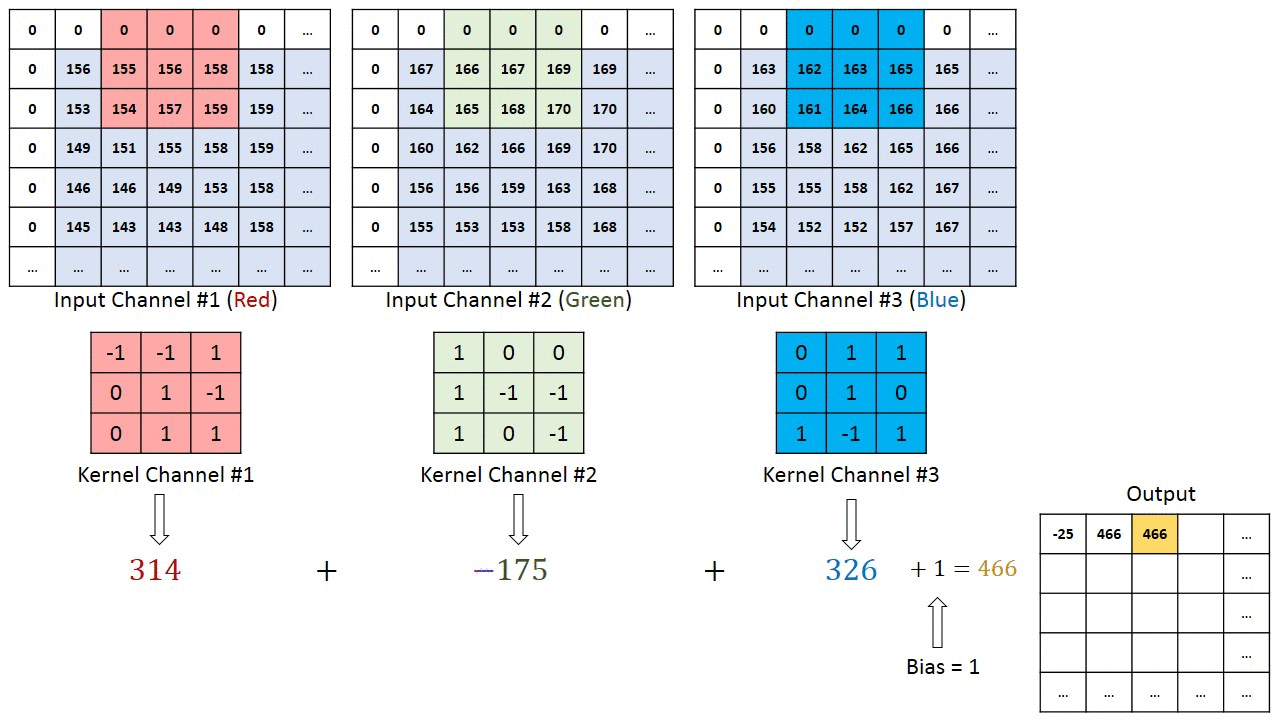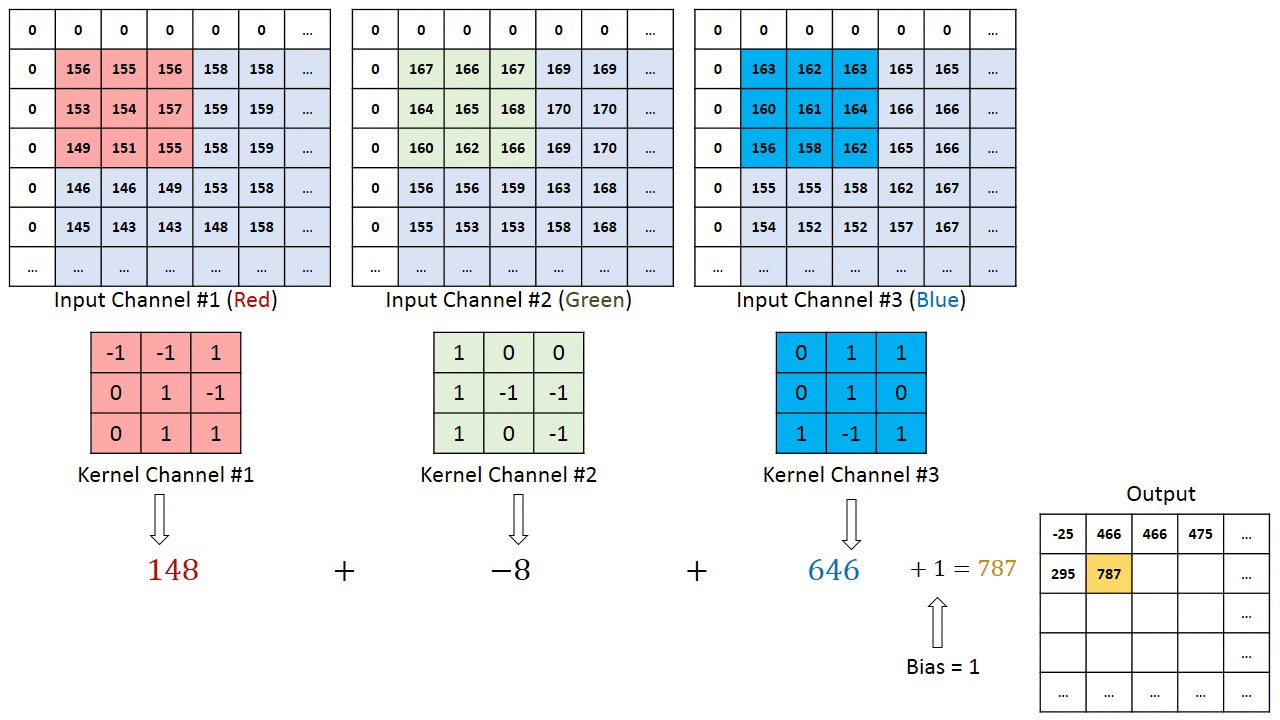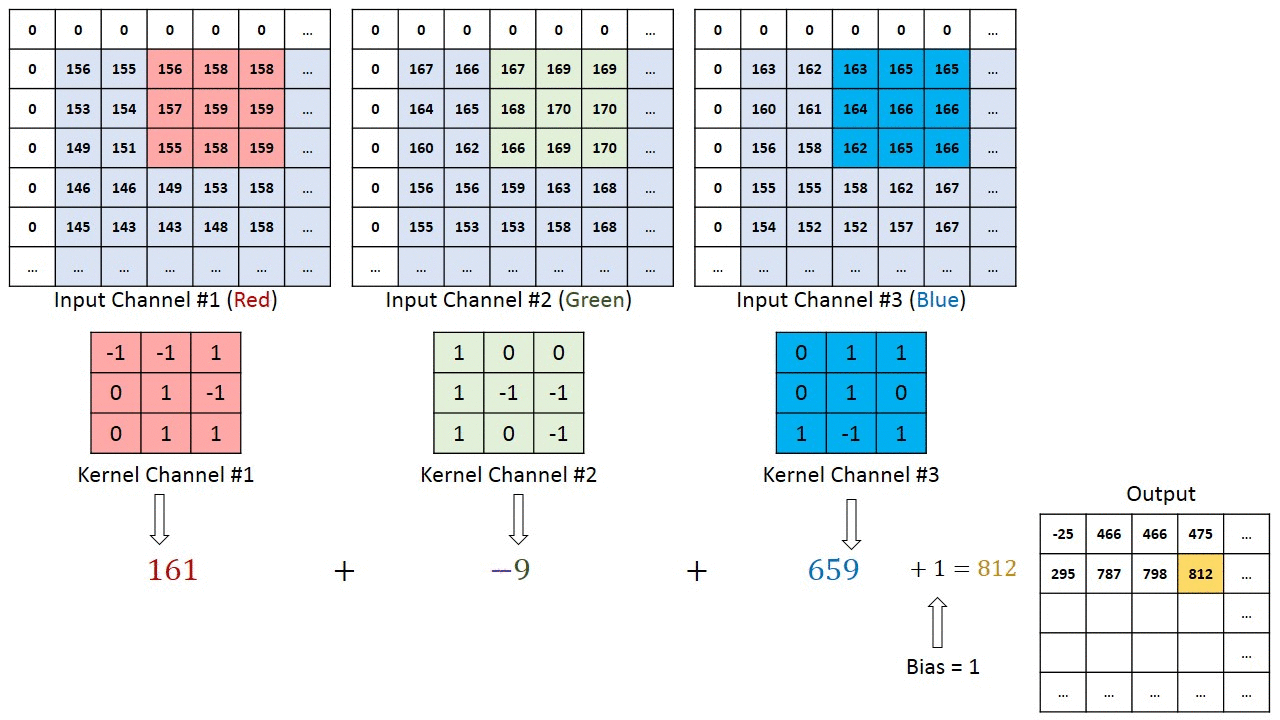
I tilfælde af billeder med flere kanaler (f.eks. RGB ), har kernen samme dybde som inputbilledet. Matrixmultiplikation udføres mellem Kn og In stack (;;), og alle resultaterne opsummeres med forspændingen for at give os en squashed en dybdekanal Convoluted Feature Output.
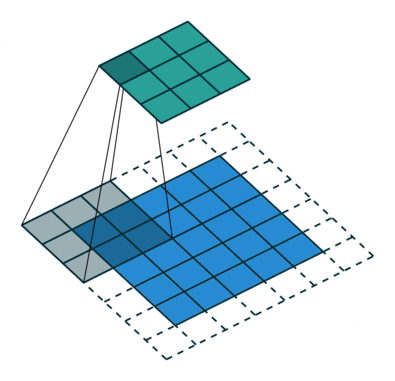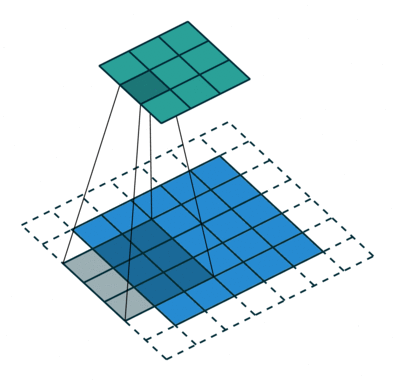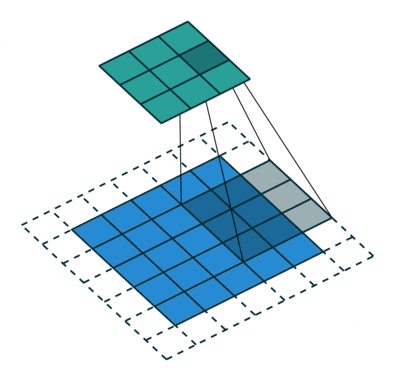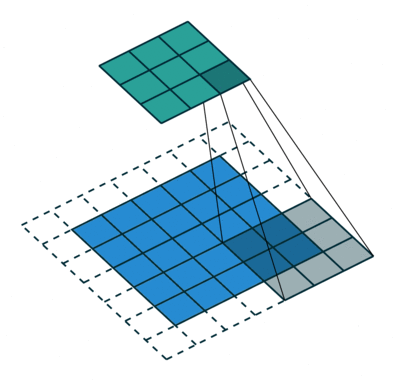
Formålet med Convolution Operation er at udtrække funktioner på højt niveau såsom kanter, fra inputbilledet. ConvNets behøver ikke kun at være begrænset til et Convolutional Layer. Konventionelt er det første ConvLayer ansvarlig for at indfange Low-Level-funktionerne som kanter, farve, gradientorientering osv. Med tilføjede lag tilpasser arkitekturen sig også til High-Level-funktionerne, hvilket giver os et netværk, der har den sunde forståelse af billeder i datasættet, svarende til hvordan vi ville.
Der er to typer resultater til operationen – den ene, hvor den indviklede funktion er reduceret i dimensionalitet sammenlignet med input, og den anden, hvor dimensionaliteten øges enten eller forbliver den samme. Dette gøres ved at anvende gyldig polstring i tilfælde af førstnævnte eller samme polstring i tilfælde af sidstnævnte.
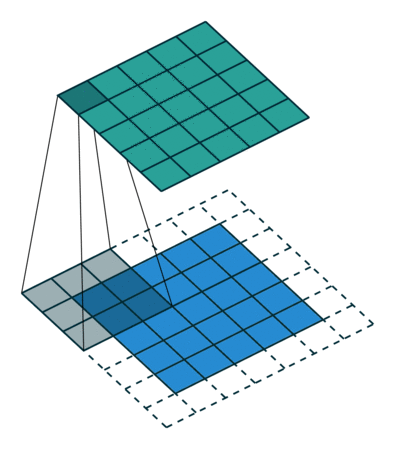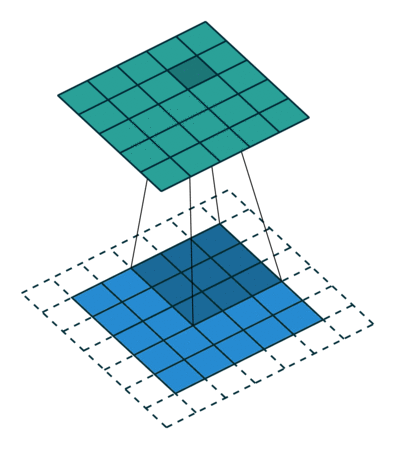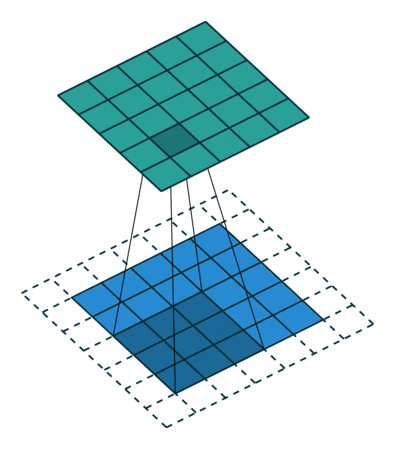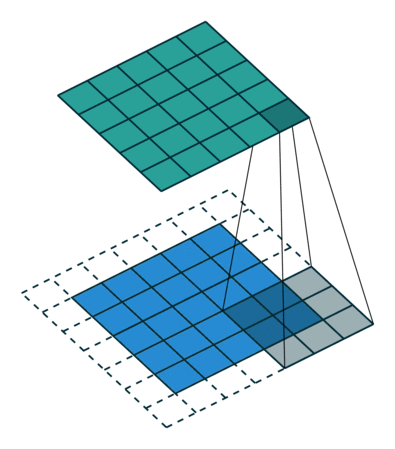
Når vi udvider 5x5x1-billedet til et 6x6x1-billede og derefter anvender 3x3x1-kernen over det, finder vi ud af at indviklet matrix viser sig at være af dimensionerne 5x5x1. Deraf navnet – Samme polstring.
På den anden side, hvis vi udfører den samme operation uden polstring, får vi en matrix, der har dimensionerne af selve kernen (3x3x1) – Gyldig polstring.
Følgende lager indeholder mange sådanne GIF’er, som kan hjælpe dig med at få en bedre forståelse af, hvordan polstring og stridlængde fungerer sammen for at opnå resultater, der er relevante for vores behov.
Pooling Layer
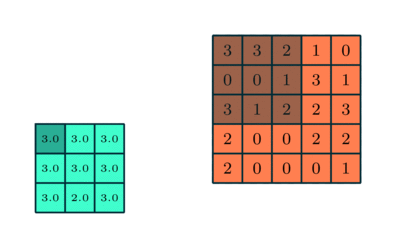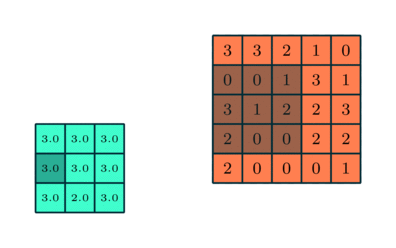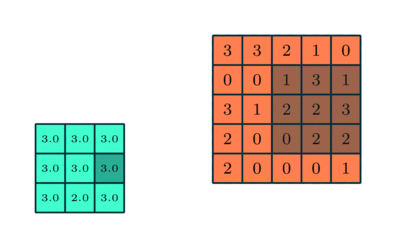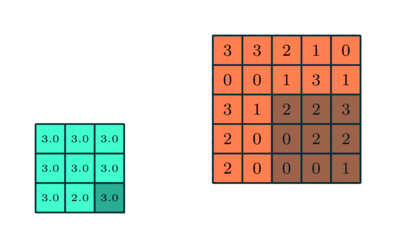
Svarende til Convolutional Layer, Pooling-laget er ansvarlig for at reducere den rumlige størrelse af den indviklede funktion. Dette er for at mindske den beregningsstyrke, der kræves for at behandle dataene gennem dimensioneringsreduktion. Desuden er det nyttigt at udtrække dominerende træk, der er rotations- og positionsvarianter, og dermed opretholde processen med effektiv træning af modellen.
Der er to typer pooling: Max Pooling og Average Pooling. Max Pooling returnerer den maksimale værdi fra den del af billedet, der er dækket af kernen. På den anden side returnerer gennemsnitlig pooling gennemsnittet af alle værdierne fra den del af billedet, der er dækket af kernen.
Max Pooling fungerer også som et støjdæmpende middel. Det kasserer de støjende aktiveringer helt og udfører også de-støj sammen med dimensionalitetsreduktion. På den anden side udfører gennemsnitlig pooling simpelthen dimensioneringsreduktion som en støjdæmpende mekanisme. Derfor kan vi sige, at Max Pooling klarer sig meget bedre end gennemsnitlig pooling.
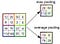
Convolutional Layer og Pooling Layer danner sammen det i-th lag af et Convolutional Neural Network. Afhængig af kompleksiteten i billederne kan antallet af sådanne lag øges for at opfange detaljer på lave niveauer endnu mere, men på bekostning af mere beregningskraft.
Efter at have gennemgået ovenstående proces har vi aktiverede modellen med succes til at forstå funktionerne. Når vi går videre, skal vi flade det endelige output og føde det til et almindeligt neuralt netværk til klassificeringsformål.
Klassifikation – Fuldt tilsluttet lag (FC-lag)

Tilføjelse af et fuldt tilsluttet lag er en (normalt) billig måde at lære ikke-lineære kombinationer af funktionerne på højt niveau op som repræsenteret ved output fra det foldende lag. Det fuldt forbundne lag lærer en muligvis ikke-lineær funktion i det rum.
Nu når vi har konverteret vores inputbillede til en passende form til vores Multi-Level Perceptron, skal vi flade billedet til en søjlevektor. Det flade output tilføres et feed-forward neuralt netværk, og backpropagation anvendes til hver iteration af træning. I løbet af en række epoker er modellen i stand til at skelne mellem dominerende og visse funktioner på lavt niveau i billeder og klassificere dem ved hjælp af Softmax Classification-teknikken.
Der findes forskellige arkitekturer af CNN’er, som har været nøglen til bygningsalgoritmer, der driver og skal drive AI som helhed i en overskuelig fremtid. Nogle af dem er anført nedenfor:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
