Umělá inteligence byla svědkem monumentálního růstu překlenutí propasti mezi schopnostmi lidí a strojů. Výzkumní pracovníci i nadšenci pracují na mnoha aspektech oboru, aby uskutečnili úžasné věci. Jednou z mnoha takových oblastí je doména počítačového vidění.
Agendou pro toto pole je umožnit strojům dívat se na svět jako lidé, vnímat jej podobným způsobem a dokonce využívat znalosti pro velké množství úkolů, jako je Image & rozpoznávání videa, analýza obrazu & klasifikace, mediální rekreace, systémy doporučení, zpracování přirozeného jazyka atd. Pokrok v počítačovém vidění s technologií Deep Learning bylo zkonstruováno a zdokonaleno v čase, primárně na základě jednoho konkrétního algoritmu – konvoluční neurální sítě.
Úvod

Konvoluční neuronová síť (ConvNet / CNN) je hluboké učení algoritmus, který dokáže přijmout vstupní obraz, přiřadit důležitost (learnabl váhy a předpětí) na různé aspekty / objekty v obraze a být schopen odlišit jeden od druhého. Předběžné zpracování požadované v ConvNet je mnohem nižší ve srovnání s jinými klasifikačními algoritmy. Zatímco v primitivních metodách jsou filtry navrženy ručně, s dostatečným tréninkem, ConvNets mají schopnost naučit se tyto filtry / charakteristiky.
Architektura ConvNet je analogická s architekturou připojení Neuronů v člověku Mozek a byl inspirován organizací Visual Cortex. Jednotlivé neurony reagují na podněty pouze v omezené oblasti zorného pole známé jako recepční pole. Sbírka takových polí se překrývá a pokrývá celou vizuální oblast.
Proč ConvNets přes Feed-Forward Neural Nets?

Obrázek není nic jiného než matice hodnot pixelů, že? Proč tedy nejen zploštit obraz (např. Matici obrazu 3×3 do vektoru 9×1) a přivést jej pro účely klasifikace do víceúrovňového Perceptronu? Uh .. ne tak docela.
V případě extrémně základních binárních obrazů může metoda při provádění predikce tříd vykazovat průměrné skóre přesnosti, ale pokud jde o složité obrázky s pixelovými závislostmi, bude mít malou až žádnou přesnost. v celém.
ConvNet dokáže úspěšně zachytit prostorové a časové závislosti v obraze pomocí příslušných filtrů. Architektura provádí lepší přizpůsobení obrazové datové sadě kvůli snížení počtu zapojených parametrů a opětovné použitelnosti vah. Jinými slovy lze síť vycvičit, aby lépe pochopila propracovanost obrazu.
Input Image

Na obrázku máme obrázek RGB, který byl oddělen třemi barevnými rovinami – červenou, zelenou, a modrá. Existuje celá řada takových barevných prostorů, ve kterých obrázky existují – stupně šedi, RGB, HSV, CMYK atd.
Dokážete si představit, jak by se výpočetně náročné věci dostaly, jakmile obrázky dosáhnou rozměrů, řekněme 8K (7680 × 4320). Role ConvNet spočívá v redukci obrázků do formy, která je snadněji zpracovatelná, aniž by došlo ke ztrátě funkcí, které jsou zásadní pro získání dobré předpovědi. To je důležité, když máme navrhnout architekturu, která je nejen dobrá v učení funkcí, ale je také škálovatelná na masivní datové sady.
Konvoluční vrstva – jádro
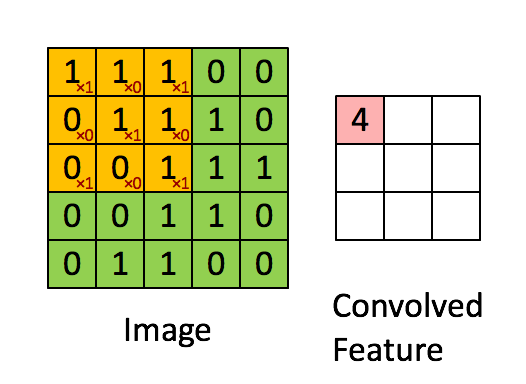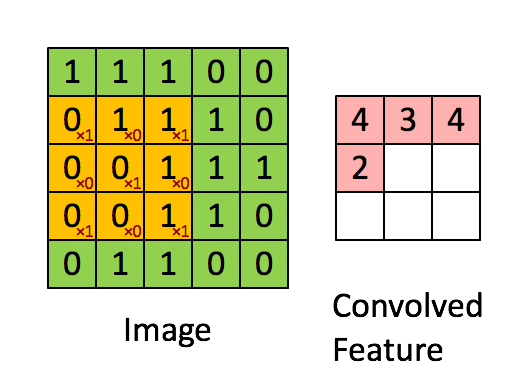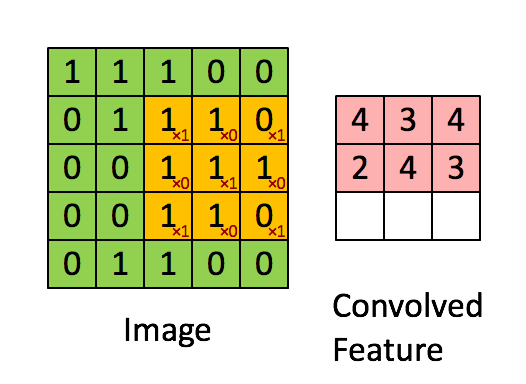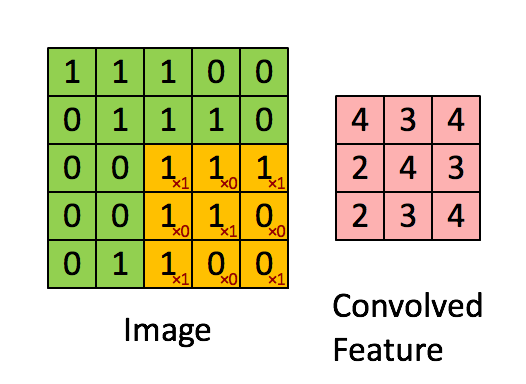
Obrázek Rozměry = 5 (výška) x 5 (šířka) x 1 (počet kanálů, např. RGB)
Ve výše uvedené ukázce se zelená část podobá našemu vstupnímu obrazu 5x5x1, I. Prvek zapojený do přenášení operace konvoluce v první části konvoluční vrstvy se nazývá jádro / filtr, K, znázorněné žlutou barvou. Vybrali jsme K jako matici 3x3x1.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
Jádro se posune 9krát kvůli Stride Length = 1 (Non-Strided), při každém provedení matice operace násobení mezi K a částí P obrazu, nad kterou se jádro vznáší.

Filtr se posune doprava s určitou hodnotou kroku, dokud nerozebere celou šířku. Když se přesunete dále, přeskočí na začátek (vlevo) obrazu se stejnou hodnotou kroku a opakuje postup, dokud nebude projet celý obraz.
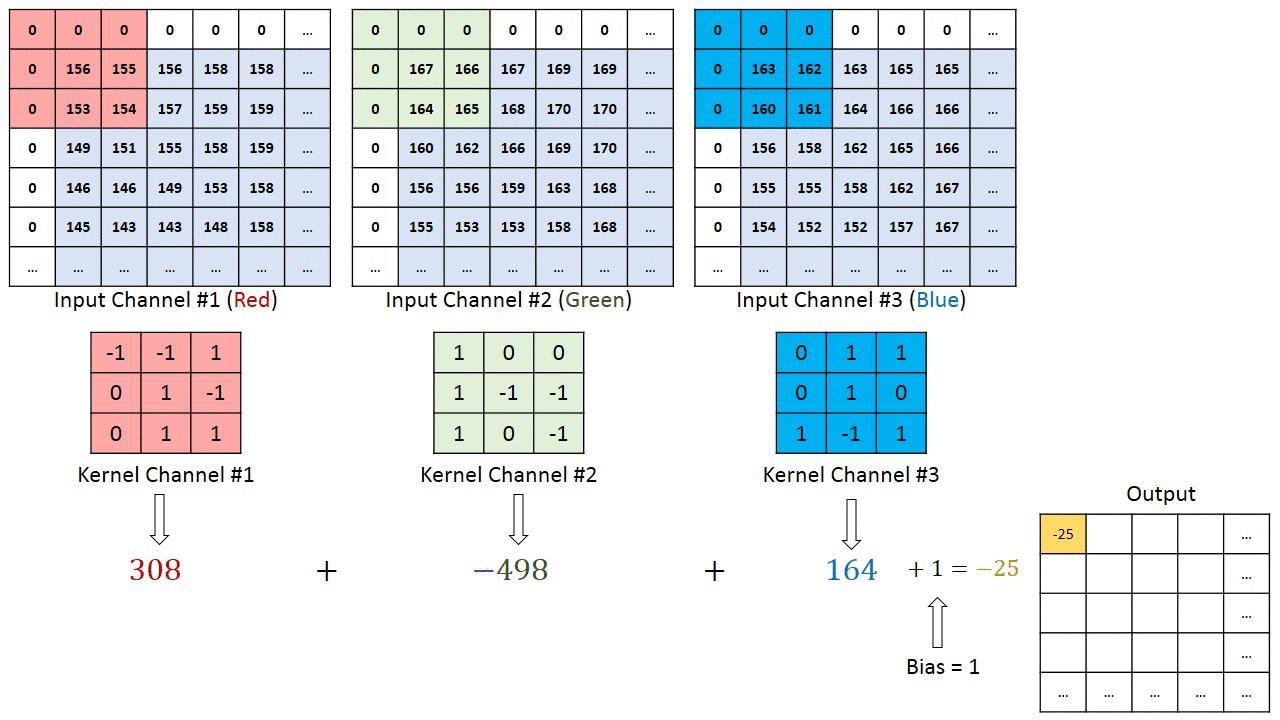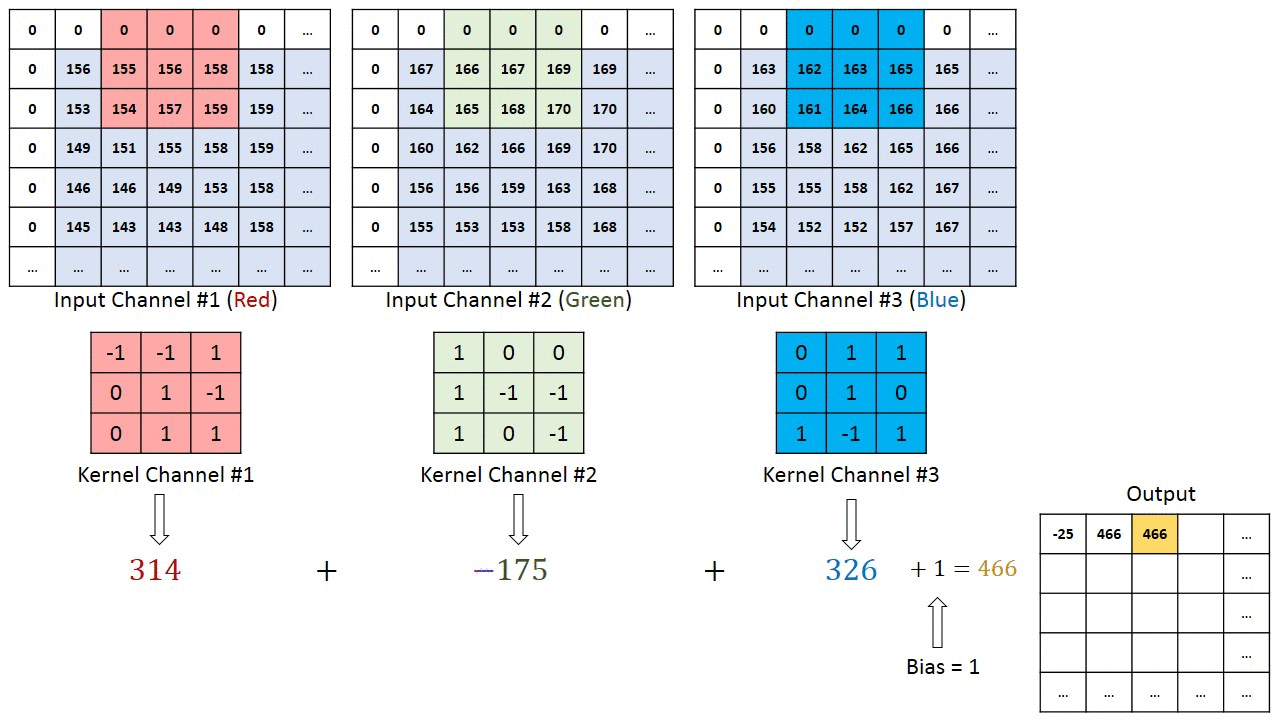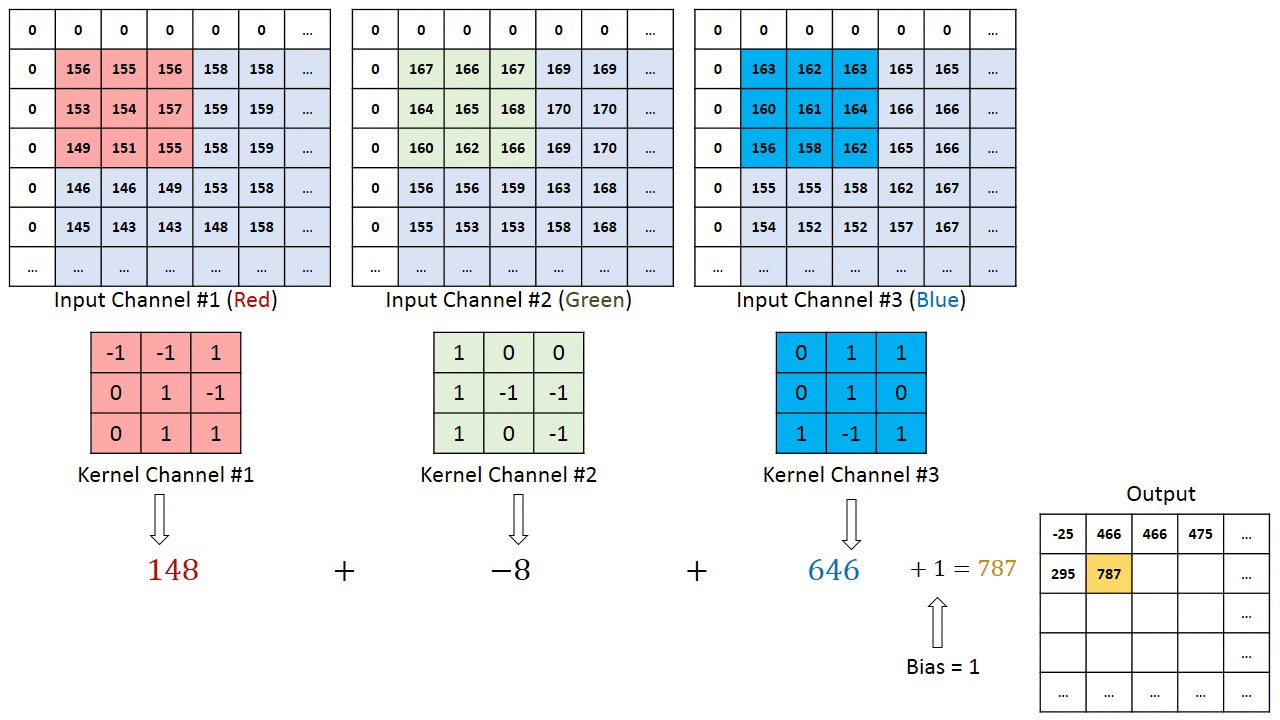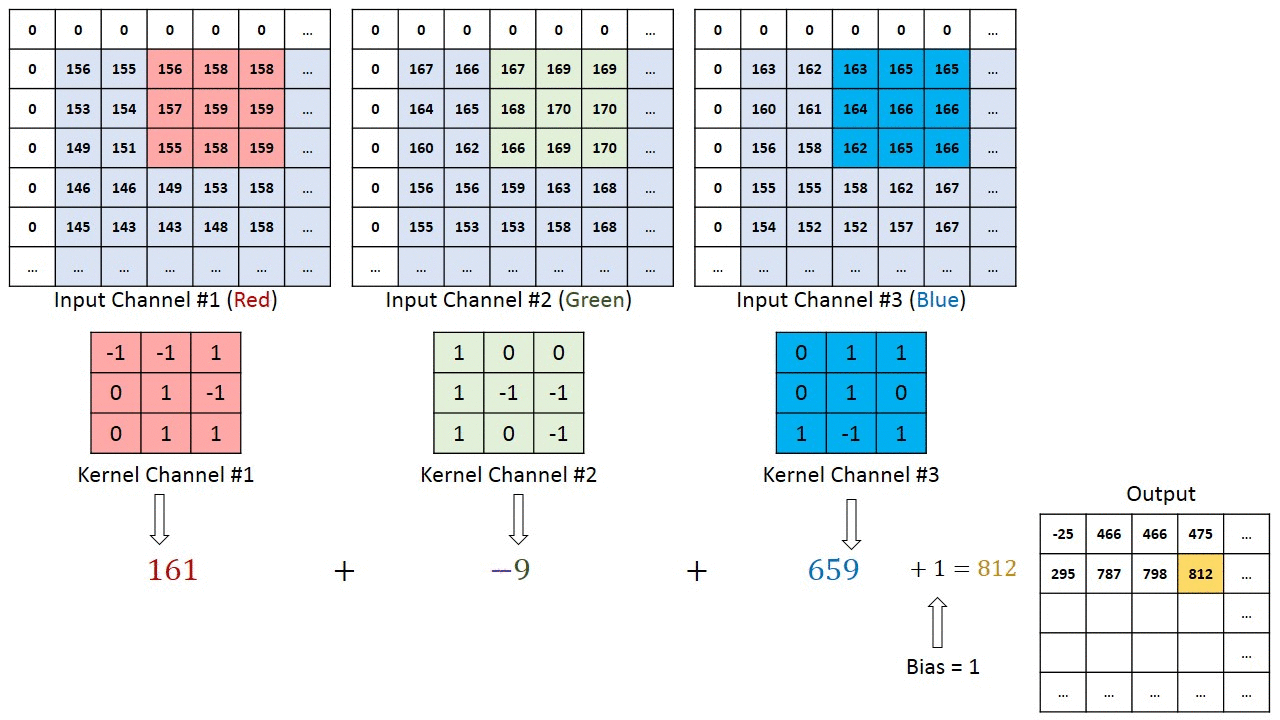
V případě obrázků s více kanály (např. RGB ), jádro má stejnou hloubku jako vstupní obraz. Maticové násobení se provádí mezi Kn a In stackem (;;) a všechny výsledky se sečtou s předpětím, aby nám poskytly rozmačkaný kanál s hloubkou Convolted Feature Output.
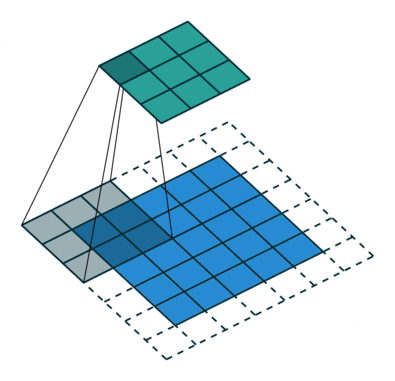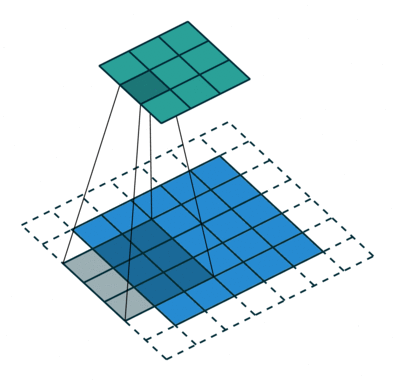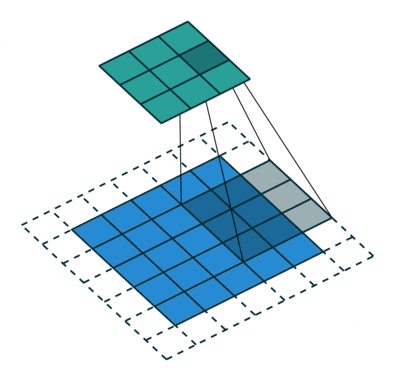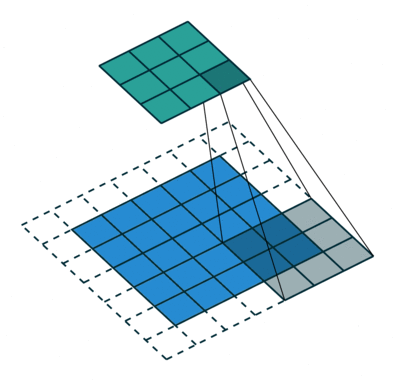
Cílem konvoluční operace je extrahovat funkce na vysoké úrovni, jako jsou hrany, ze vstupního obrazu. ConvNets nemusí být omezen pouze na jednu konvoluční vrstvu. První ConvLayer je běžně zodpovědný za zachycení funkcí na nízké úrovni, jako jsou hrany, barva, orientace přechodu atd. S přidanými vrstvami se architektura přizpůsobuje také funkcím na vysoké úrovni, což nám dává síť, která má zdravé porozumění obrázků v datové sadě, podobně jako bychom to udělali.
Existují dva typy výsledků operace – jeden, ve kterém je konvolvovaný prvek ve srovnání se vstupem zmenšen v rozměrnosti, a druhý, ve kterém rozměrnost se buď zvýší, nebo zůstane stejná. Toho dosáhnete použitím platného polstrování v případě prvního nebo stejného polstrování v případě druhého.
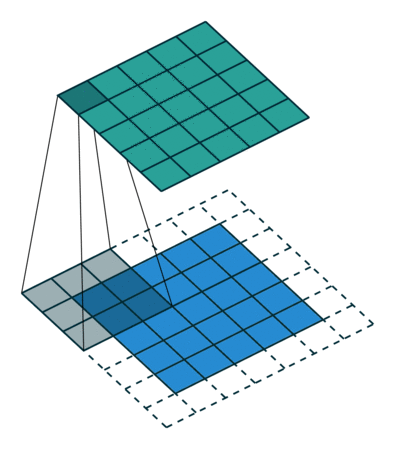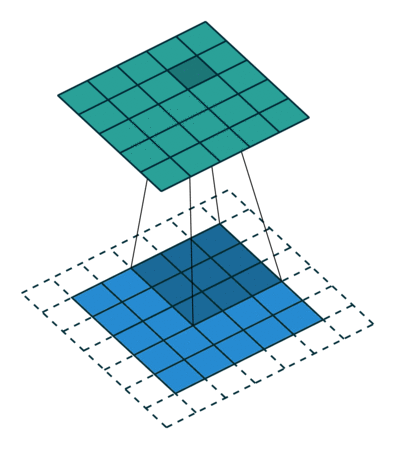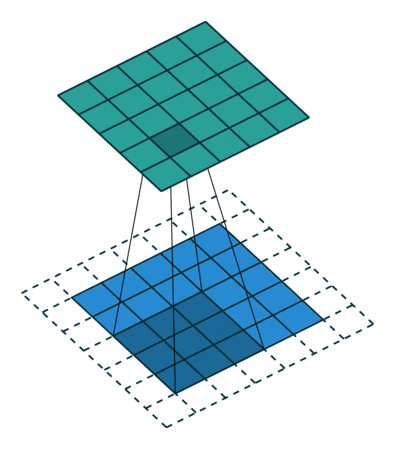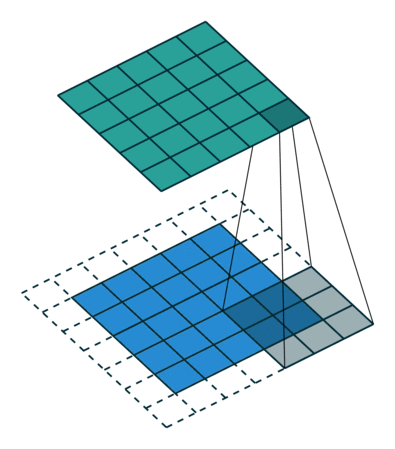
Když obrázek 5x5x1 zvětšíme na obrázek 6x6x1 a poté na něj použijeme jádro 3x3x1, zjistíme, že konvolvovaná matice má rozměry 5x5x1. Odtud název – Stejné polstrování.
Na druhou stranu, pokud provádíme stejnou operaci bez polstrování, zobrazí se nám matice, která má rozměry samotného jádra (3x3x1) – Platné polstrování.
Následující repozitář obsahuje mnoho takových souborů GIF, které vám pomohou lépe porozumět tomu, jak Padding a Stride Length spolupracují na dosažení výsledků relevantních pro naše potřeby.
Pooling Layer
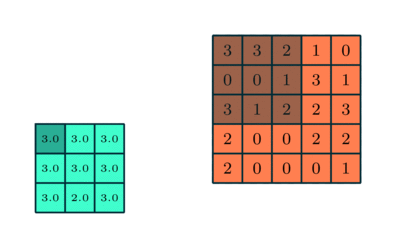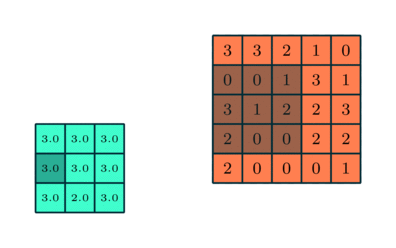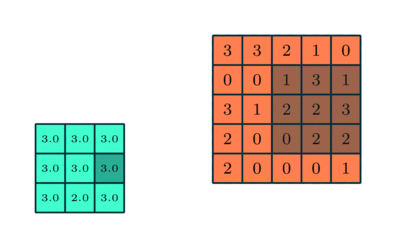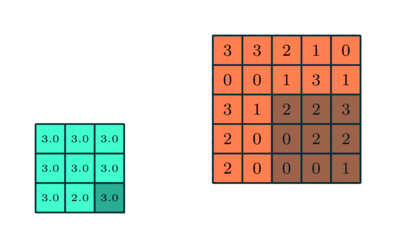
Podobně jako u konvoluční vrstvy, sdružovací vrstva je zodpovědný za zmenšení prostorové velikosti funkce Convolved. To má snížit výpočetní výkon potřebný ke zpracování dat snížením rozměrů. Dále je užitečné extrahovat dominantní prvky, které jsou rotační a poziční invariantní, čímž se udržuje proces efektivního trénování modelu.
Existují dva typy sdružování: Max. Sdružování a průměrné sdružování. Max Pooling vrací maximální hodnotu z části obrazu pokryté jádrem. Na druhou stranu průměrné sdružování vrací průměr všech hodnot z části obrázku pokryté jádrem.
Max sdružování také funguje jako potlačovač šumu. Zbavuje se hlučných aktivací úplně a také provádí odstranění šumu spolu s redukcí rozměrů. Na druhou stranu průměrné sdružování jednoduše provádí redukci rozměrů jako mechanismus potlačení šumu. Můžeme tedy říci, že Max Pooling funguje mnohem lépe než průměrné Pooling.
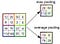
Konvoluční vrstva a sdružovací vrstva společně tvoří i-tu vrstvu konvoluční neuronové sítě. V závislosti na složitosti obrázků může být počet takových vrstev zvýšen pro další zachycení podrobností na nízkých úrovních, ale za cenu větší výpočetní síly.
Po provedení výše uvedeného procesu máme úspěšně umožnil modelu porozumět funkcím. Pokračujeme, zploštíme konečný výstup a přivedeme ho do běžné neurální sítě pro účely klasifikace.
Klasifikace – plně propojená vrstva (vrstva FC)

Přidání plně propojené vrstvy je (obvykle) levný způsob, jak se naučit nelineární kombinace funkcí na vysoké úrovni, které představují výstup konvoluční vrstvy. Plně propojená vrstva se v tomto prostoru učí možná nelineární funkci.
Nyní, když jsme převedli náš vstupní obraz do vhodné formy pro náš Víceúrovňový Perceptron, sloučíme obraz do vektor sloupce. Zploštělý výstup se přivádí do neuronové sítě s předáváním dopředu a zpětná propagace se aplikuje na každou iteraci tréninku. V sérii epoch je model schopen rozlišit mezi dominujícími a určitými nízkoúrovňovými funkcemi v obrazech a klasifikovat je pomocí techniky Softmax Classification.
K dispozici jsou různé architektury CNN, které byly klíčové budování algoritmů, které v dohledné budoucnosti budou napájet a napájet AI jako celek. Některé z nich jsou uvedeny níže:
- LeNet
- AlexNet
- VGGNet
- DreamstimeNet
- ResNet
- ZFNet
