Wenn es um das Lernen geht, gibt es im Allgemeinen zwei Ansätze: Sie können entweder gehen versuchen Sie, so viel wie möglich vom Spektrum eines Feldes abzudecken, oder gehen Sie tief und versuchen Sie, mit dem Thema, das Sie lernen, wirklich, wirklich spezifisch zu werden. Die meisten guten Lernenden wissen, dass alles, was Sie im Leben lernen – von Algorithmen bis zu grundlegenden Lebenskompetenzen – bis zu einem gewissen Grad eine Kombination dieser beiden Ansätze beinhaltet.
Gleiches gilt für Informatik, Problemlösung, und Datenstrukturen. Letzte Woche haben wir uns intensiv mit der Tiefensuche befasst und gelernt, was es bedeutet, einen binären Suchbaum tatsächlich zu durchlaufen. Jetzt, da wir tief gegangen sind, ist es für uns sinnvoll, weit zu gehen und die andere gängige Strategie zum Durchqueren von Bäumen zu verstehen.
Mit anderen Worten, es ist der Moment, auf den Sie alle gewartet haben: Es ist Zeit Um die Grundlagen der Breitensuche aufzuschlüsseln!
Eine der besten Möglichkeiten, um zu verstehen, was Breitensuche (BFS) genau ist, besteht darin, zu verstehen, was nicht. Das heißt, wenn wir BFS mit DFS vergleichen, wird es für uns viel einfacher sein, sie gerade im Kopf zu behalten. Lassen Sie uns also unsere Erinnerung an die Tiefensuche auffrischen, bevor wir fortfahren.
Wir wissen, dass bei der Tiefensuche ein Prozess durch einen Ast eines Baumes durchlaufen wird, bis wir zu einem Blatt gelangen. Mit anderen Worten, die Implementierung eines DFS bedeutet, die Teilbäume eines binären Suchbaums zu durchlaufen.
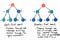
Okay, wie funktioniert die Breitensuche? Suche im Vergleich dazu? Nun, wenn wir darüber nachdenken, ist die einzige wirkliche Alternative, um einen Ast eines Baumes hinunter und dann einen anderen zu fahren, den Baum abschnittsweise hinunterzufahren – oder Stufe für Stufe. Und genau das ist BFS !
Bei der Breitensuche wird eine Ebene nach der anderen durchsucht.
Wir Durchlaufen Sie zuerst eine ganze Ebene von Kinderknoten, bevor Sie die Enkelknoten durchlaufen. Und wir durchlaufen eine ganze Ebene von Enkelknoten, bevor wir Urenkelknoten durchlaufen.
Okay, das scheint ziemlich klar zu sein. Was unterscheidet die beiden verschiedenen Arten von Baumdurchquerungsalgorithmen noch? Nun, wir haben bereits die Unterschiede in den Verfahren dieser beiden Algorithmen behandelt. Lassen Sie uns über den anderen wichtigen Aspekt nachdenken, über den wir noch nicht gesprochen haben: die Implementierung.
Beginnen wir zunächst mit dem, was wir wissen. Wie haben wir letzte Woche die Tiefensuche implementiert? Sie werden sich vielleicht daran erinnern, dass wir drei verschiedene Methoden gelernt haben – Inorder, Postorder und Preorder -, um einen Baum mit DFS zu durchsuchen. Trotzdem war es super cool, wie ähnlich diese drei Implementierungen waren. Sie könnten jeweils durch Rekursion eingesetzt werden. Wir wissen auch, dass DFS, da es als rekursive Funktion geschrieben werden kann, dazu führen kann, dass der Aufrufstapel so groß wird wie der längste Pfad im Baum.
Eines blieb mir jedoch noch übrig Letzte Woche scheint das gut zu sein (und vielleicht ist es sogar ein bisschen offensichtlich!): Der Aufrufstapel implementiert tatsächlich eine Stapeldatenstruktur. Erinnerst du dich an diese? Wir haben vor einiger Zeit etwas über Stapel gelernt, aber hier tauchen sie wieder auf!
Das wirklich Interessante an der Implementierung der Tiefensuche mithilfe eines Stapels ist, dass wir die Teilbäume von a durchlaufen Im binären Suchbaum wird jeder der Knoten, die wir „überprüfen“ oder „besuchen“, zum Stapel hinzugefügt. Sobald wir einen Blattknoten erreichen – einen Knoten, der keine untergeordneten Knoten hat – beginnen wir, die Knoten von der Oberseite des Stapels zu entfernen. Wir landen wieder am Wurzelknoten und können dann den nächsten Teilbaum weiter durchlaufen.

Im obigen Beispiel-DFS-Baum werden Sie feststellen, dass alle Knoten 2, 3 und 4 hinzugefügt werden die Oberseite des Stapels. Wenn wir das „Ende“ dieses Teilbaums erreichen – das heißt, wenn wir die Blattknoten von 3 und 4 erreichen – beginnen wir, diese Knoten von unserem Stapel von „zu besuchenden Knoten“ zu entfernen.Sie können sehen, was schließlich mit dem richtigen Teilbaum passieren wird: Die zu besuchenden Knoten werden auf den Aufrufstapel verschoben, wir werden sie besuchen und sie systematisch vom Stapel entfernen.
Schließlich, sobald wir Nachdem wir sowohl den linken als auch den rechten Teilbaum besucht haben, sind wir wieder am Stammknoten und haben nichts mehr zu überprüfen. Unser Aufrufstapel ist leer.
Wir sollten also in der Lage sein, a zu verwenden Stapeln Sie die Struktur und machen Sie etwas Ähnliches mit unserer BFS-Implementierung… richtig? Nun, ich weiß nicht, ob es funktionieren wird, aber ich denke, es wird hilfreich sein, zunächst den Algorithmus zu zeichnen, den wir implementieren möchten, und zu sehen, wie weit wir damit kommen können.
Versuchen wir Folgendes:

Okay, wir haben links ein Diagramm, in dem wir letzte Woche DFS implementiert haben. Wie können wir stattdessen einen BFS-Algorithmus verwenden?
Zunächst wissen wir, dass wir zuerst den Stammknoten überprüfen möchten. Dies ist der einzige Knoten, auf den wir anfangs Zugriff haben, und daher „zeigen“ wir auf Knoten f.
Okay, jetzt müssen wir die untergeordneten Knoten dieses Stammknotens überprüfen.
Wir möchten ein Kind nach dem anderen überprüfen, gehen wir also zuerst zum linken Kind – Knoten d ist der Knoten, auf den wir jetzt „zeigen“ (und der einzige Knoten, auf den wir Zugriff haben).
Als nächstes wollen wir zum richtigen untergeordneten Knoten gehen.
Oh oh. Warten Sie, der Stammknoten steht uns nicht einmal mehr zur Verfügung! Und wir können uns nicht rückwärts bewegen, da Binärbäume keine umgekehrten Links haben! Wie kommen wir zum richtigen untergeordneten Knoten? Und… oh nein, der linke untergeordnete Knoten d und der rechte untergeordnete Knoten k sind überhaupt nicht verbunden. Das bedeutet, dass wir nicht von einem Kind zum anderen springen können, da wir nur auf die Kinder von Knoten d zugreifen können.
Oh je. Wir sind nicht weit gekommen, oder? Wir müssen eine andere Methode zur Lösung dieses Problems finden. Wir müssen einen Weg finden, um eine Baumdurchquerung zu implementieren, mit der wir den Baum in ebener Reihenfolge laufen können. Das Wichtigste, was wir beachten müssen, ist Folgendes:
Wir müssen einen Verweis auf alle untergeordneten Knoten jedes Knotens behalten, den wir besuchen. Andernfalls können wir später nie mehr zu ihnen zurückkehren und sie besuchen!
Je mehr ich darüber nachdenke, desto mehr habe ich Lust Es ist, als wollten wir eine Liste aller Knoten führen, die wir noch überprüfen müssen, nicht wahr? Und in dem Moment, in dem ich eine Liste von etwas führen möchte, springt mein Verstand sofort zu einer bestimmten Datenstruktur: einer Warteschlange natürlich!
Mal sehen, ob Warteschlangen uns bei unserer BFS-Implementierung helfen können.
Warteschlangen zur Rettung!
Wie sich herausstellt, besteht ein Hauptunterschied bei der Tiefensuche und der Breitensuche in der Datenstruktur, die zur Implementierung dieser beiden sehr unterschiedlichen Algorithmen verwendet wird.
Während DFS eine Stapeldatenstruktur verwendet, stützt sich BFS auf die Warteschlangendatenstruktur. Das Schöne an der Verwendung von Warteschlangen ist, dass sie genau das Problem lösen, das wir zuvor entdeckt haben: Sie können einen Verweis auf Knoten behalten, zu denen wir zurückkehren möchten, obwohl wir sie noch nicht überprüft / besucht haben.
Wir fügen Knoten, die wir entdeckt – aber noch nicht besucht – zu unserer Warteschlange hinzu und kehren später zu ihnen zurück.
Ein gebräuchlicher Begriff für Knoten, die wir unserer Warteschlange hinzufügen, sind erkannte Knoten. Ein entdeckter Knoten ist einer, den wir unserer Warteschlange hinzufügen, dessen Standort wir kennen, den wir jedoch noch nicht besucht haben. Genau dies macht eine Warteschlange zur perfekten Struktur zur Lösung des BFS-Problems.

In der Grafik links fügen wir zunächst den Stammknoten zu unserer Warteschlange hinzu, da dies der einzige Knoten ist, den wir jemals hatten Zugriff auf (zumindest anfänglich) einen Baum haben. Dies bedeutet, dass der Stammknoten der einzige erkannte Knoten ist, der gestartet wird.
Sobald mindestens ein Knoten in die Warteschlange gestellt wurde, können wir den Prozess des Besuchs von Knoten starten und Verweise auf ihre untergeordneten Knoten in unsere Warteschlange aufnehmen.
Okay, das klingt vielleicht etwas verwirrend. Und das ist okay! Ich denke, es wird viel einfacher zu verstehen sein, wenn wir es in einfachere Schritte aufteilen.
Für jeden Knoten in unserer Warteschlange – immer beginnend mit dem Stammknoten – möchten wir drei Dinge tun:
- Besuchen Sie den Knoten, was normalerweise nur das Ausdrucken seines Werts bedeutet.
- Fügen Sie das linke untergeordnete Element des Knotens zu unserer Warteschlange hinzu.
- Fügen Sie das rechte des Knotens hinzu Kind in unsere Warteschlange.
Sobald wir diese drei Dinge erledigt haben, können wir den Knoten aus unserer Warteschlange entfernen, da wir ihn nicht mehr benötigen!Grundsätzlich müssen wir dies wiederholt tun, bis wir den Punkt erreicht haben, an dem unsere Warteschlange leer ist.
Okay, sehen wir uns das in Aktion an!
In der folgenden Grafik beginnen wir Aus mit dem Wurzelknoten, Knoten f, als einzigem erkannten Knoten. Erinnerst du dich an unsere drei Schritte? Machen wir sie jetzt:
- Wir besuchen Knoten f und drucken seinen Wert aus.
- Wir werden einen Verweis auf sein linkes Kind, Knoten d, in die Warteschlange stellen.
- Wir werden einen Verweis auf sein rechtes Kind, Knoten k, in die Warteschlange stellen.
Und dann entfernen wir den Knoten f aus unserer Warteschlange!

Der nächste Knoten an der Vorderseite der Warteschlange ist Knoten d. Wieder die gleichen drei Schritte: Drucken Sie den Wert aus, fügen Sie das linke untergeordnete Element hinzu, fügen Sie das rechte untergeordnete Element hinzu und entfernen Sie es dann aus der Warteschlange.
Unsere Warteschlange enthält jetzt Verweise auf die Knoten k, b und e . Wenn wir diesen Vorgang weiterhin systematisch wiederholen, werden wir feststellen, dass wir das Diagramm tatsächlich durchlaufen und die Knoten in der Reihenfolge der Ebenen ausdrucken. Hurra! Genau das wollten wir zuerst tun.
Der Schlüssel dafür, dass dies so gut funktioniert, liegt in der Natur der Warteschlangenstruktur. Warteschlangen folgen dem FIFO-Prinzip (First-In, First-Out). Dies bedeutet, dass alles, was zuerst in die Warteschlange gestellt wurde, das erste Element ist, das gelesen und aus der Warteschlange entfernt wird.
Während wir uns mit dem Thema Warteschlangen befassen, ist es erwähnenswert, dass die Raum-Zeit-Komplexität eines BFS-Algorithmus auch mit der Warteschlange zusammenhängt, mit der wir ihn implementieren – wer wusste, dass Warteschlangen zurückkehren würden Um so nützlich zu sein, richtig?
Die zeitliche Komplexität eines BFS-Algorithmus hängt direkt davon ab, wie viel Zeit für den Besuch eines Knotens erforderlich ist. Da sich die Zeit, die zum Lesen des Werts eines Knotens und zum Einreihen seiner untergeordneten Elemente benötigt wird, nicht basierend auf dem Knoten ändert, können wir sagen, dass der Besuch eines Knotens eine konstante Zeit oder O (1) Zeit benötigt. Da wir jeden Knoten in einer BFS-Baumdurchquerung nur genau einmal besuchen, hängt die Zeit, die wir zum Lesen jedes Knotens benötigen, nur davon ab, wie viele Knoten sich im Baum befinden! Wenn unser Baum 15 Knoten hat, braucht er O (15); aber wenn unser Baum 1500 Knoten hat, braucht er O (1500). Somit nimmt die Zeitkomplexität eines Breitensuchalgorithmus eine lineare Zeit in Anspruch, oder O (n), wobei n die Anzahl der Knoten in dem Baum ist.
Die Raumkomplexität ist ähnlich, hat mehr zu tun Machen Sie damit, wie stark unsere Warteschlange wächst und schrumpft, wenn wir die Knoten hinzufügen, die wir überprüfen müssen. Im schlimmsten Fall könnten wir möglicherweise alle Knoten in einem Baum in die Warteschlange stellen, wenn sie alle Kinder untereinander sind. Dies bedeutet, dass wir möglicherweise so viel Speicher verwenden, wie Knoten im Baum vorhanden sind. Wenn die Größe der Warteschlange auf die Anzahl der Knoten im Baum anwachsen kann, ist die Raumkomplexität für einen BFS-Algorithmus auch die lineare Zeit oder O (n), wobei n die Anzahl der Knoten im Baum ist. P. >
Das ist alles schön und gut, aber wissen Sie, was ich jetzt wirklich gerne machen würde? Ich möchte tatsächlich einen dieser Algorithmen schreiben! Lassen Sie uns endlich all diese Theorie in die Praxis umsetzen.
Codierung unseres ersten Suchalgorithmus mit der Breite zuerst
Wir haben es geschafft! Wir werden endlich unseren ersten BFS-Algorithmus codieren. Wir haben letzte Woche ein wenig davon mit DFS-Algorithmen gemacht, also versuchen wir auch, eine umfassende Suchimplementierung davon zu schreiben.
Vielleicht erinnern Sie sich, dass wir dies letzte Woche in Vanille-JavaScript geschrieben haben Wir werden uns aus Gründen der Konsistenz wieder daran halten. Für den Fall, dass Sie eine schnelle Auffrischung benötigen, haben wir uns entschlossen, diese einfach zu halten und unsere Knotenobjekte wie folgt in einfache alte JavaScript-Objekte (POJOs) zu schreiben:
node1 = {
data: 1,
left: referenceToLeftNode,
right: referenceToRightNode
};
Okay, cool. Ein Schritt getan.
Aber jetzt, da wir über Warteschlangen Bescheid wissen und sicher sind, dass wir einen verwenden müssen, um diesen Algorithmus zu implementieren, sollten wir wahrscheinlich herausfinden, wie das in JavaScript gemacht wird, oder? Nun, wie sich herausstellt, ist es wirklich einfach, ein warteschlangenähnliches Objekt in JS zu erstellen!
Wir können ein Array verwenden, das den Trick ganz gut macht:
Wenn wir dies etwas schicker machen wollten, könnten wir wahrscheinlich auch erstellen ein Queue -Objekt, das möglicherweise nützliche Funktionen wie top oder isEmpty hat; Im Moment verlassen wir uns jedoch auf sehr einfache Funktionen.
Okay, schreiben wir diesen Welpen! Wir erstellen eine levelOrderSearch -Funktion, die ein rootNode -Objekt aufnimmt.
Großartig! Das ist eigentlich … ziemlich einfach. Oder zumindest viel einfacher als ich erwartet hatte. Wir verwenden hier lediglich eine while -Schleife, um mit diesen drei Schritten fortzufahren: Überprüfen eines Knotens, Hinzufügen seines linken und rechten Kindes.Wir iterieren weiter durch das Array queue, bis alles daraus entfernt wurde und seine Länge 0 ist.
Tolle. Unsere Algorithmus-Expertise ist in nur einem Tag in die Höhe geschossen! Wir wissen nicht nur, wie man rekursive Baumdurchlaufalgorithmen schreibt, sondern jetzt auch, wie man iterative Algorithmen schreibt. Wer hätte gedacht, dass algorithmische Suchen so hilfreich sein können!
Ressourcen
Es gibt noch viel über die Breitensuche zu lernen und wann sie nützlich sein kann. Glücklicherweise gibt es unzählige Ressourcen, die Informationen enthalten, die ich nicht in diesen Beitrag einfügen konnte. Schauen Sie sich einige der wirklich guten unten an.
- DFS- und BFS-Algorithmen unter Verwendung von Stapeln und Warteschlangen, Professor Lawrence L. Larmore
- Der Breitensuchalgorithmus, Khan Akademie
- Datenstruktur – Breite erste Durchquerung, TutorialsPoint
- Binärbaum: Durchquerung der Ebenenreihenfolge, Mycodeschool
- Breite-erste Durchquerung eines Baums, Informatik-Abteilung von Boston University
