Artificiell intelligens har bevittnat en enorm tillväxt när det gäller att överbrygga klyftan mellan människors och maskiners kapacitet. Forskare och entusiaster arbetar med många aspekter av fältet för att få fantastiska saker att hända. Ett av många sådana områden är Computer Vision.
Dagordningen för detta fält är att göra det möjligt för maskiner att se världen som människor gör, uppfatta den på ett liknande sätt och till och med använda kunskapen för en mängd av uppgifter som bild & Videoigenkänning, bildanalys & Klassificering, mediarekreation, rekommendationssystem, bearbetning av naturliga språk osv. i Computer Vision with Deep Learning har konstruerats och perfekterats med tiden, främst över en viss algoritm – ett Convolutional Neural Network.
Inledning

A Convolutional Neural Network (ConvNet / CNN) är ett djupt lärande algoritm som kan ta in en ingångsbild, tilldela vikt (lärabl vikter och fördomar) till olika aspekter / objekt i bilden och kunna skilja varandra från varandra. Förbehandlingen som krävs i ett ConvNet är mycket lägre jämfört med andra klassificeringsalgoritmer. Medan filter i primitiva metoder är handgjorda, med tillräckligt med utbildning, har ConvNets förmågan att lära sig dessa filter / egenskaper.
Arkitekturen för ett ConvNet är analog med det för anslutningsmönstret för Neurons in the Human Hjärna och inspirerades av organisationen av Visual Cortex. Enskilda nervceller svarar bara på stimuli i ett begränsat område av synfältet som kallas det mottagande fältet. En samling av sådana fält överlappar varandra för att täcka hela det visuella området.
Varför ConvNets över Feed-Forward Neural Nets?

En bild är bara en matris av pixelvärden, eller hur? Så varför inte bara plana ut bilden (t.ex. 3×3 bildmatris i en 9×1-vektor) och mata den till en Multi-Level Perceptron för klassificeringsändamål? Uh .. inte riktigt.
I fall av extremt grundläggande binära bilder kan metoden visa en genomsnittlig precisionspoäng när man utför förutsägelse av klasser men skulle ha liten eller ingen precision när det gäller komplexa bilder med pixelberoende hela tiden.
Ett ConvNet kan framgångsrikt fånga de geografiska och temporala beroenden i en bild genom att använda relevanta filter. Arkitekturen utför en bättre anpassning till bilddatasetet på grund av minskningen av antalet parametrar som är inblandade och vikterna kan återanvändas. Med andra ord kan nätverket utbildas för att bättre förstå bildens sofistikering.
Inmatningsbild

I figuren har vi en RGB-bild som har separerats av dess tre färgplan – Röd, Grön, och blått. Det finns ett antal sådana färgrymder där bilder finns – Gråskala, RGB, HSV, CMYK, etc.
Du kan föreställa dig hur beräkningsintensiva saker skulle bli när bilderna når dimensioner, säg 8K (7680 × 4320). ConvNets roll är att reducera bilderna till en form som är lättare att bearbeta, utan att förlora funktioner som är kritiska för att få en bra förutsägelse. Detta är viktigt när vi ska utforma en arkitektur som inte bara är bra för inlärningsfunktioner utan också är skalbar till massiva datamängder.
Convolution Layer – The Kernel
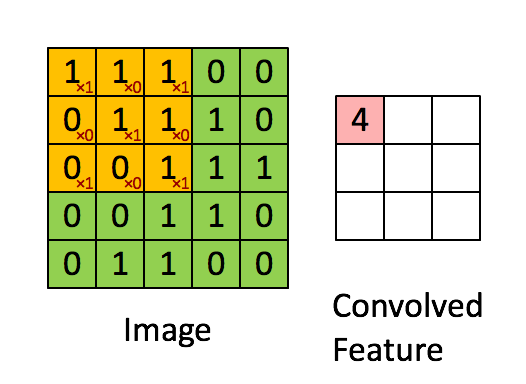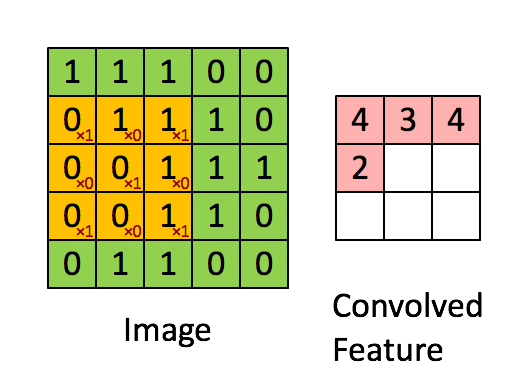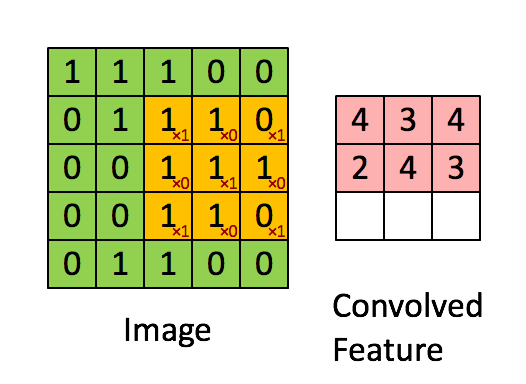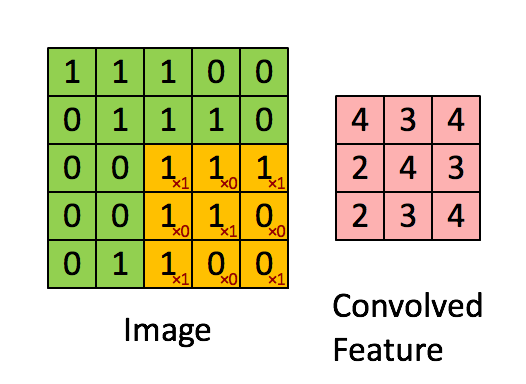
Bild Mått = 5 (höjd) x 5 (bredd) x 1 (antal kanaler, t.ex. RGB)
I ovanstående demonstration liknar det gröna avsnittet vår 5x5x1 ingångsbild, I. Elementet som är involverat i att bära ut konvolutionsoperationen i den första delen av ett Convolutional Layer kallas Kernel / Filter, K, representerad i färgen gul. Vi har valt K som en 3x3x1-matris.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
Kärnan skiftar 9 gånger på grund av steglängd = 1 (icke-stegad), varje gång en matris utförs multiplikationsoperation mellan K och den del P av bilden som kärnan svävar över.

Filtret flyttas till höger med ett visst stegvärde tills det analyserar hela bredden. När du går vidare hoppar den ner till början (till vänster) av bilden med samma stegvärde och upprepar processen tills hela bilden passeras.
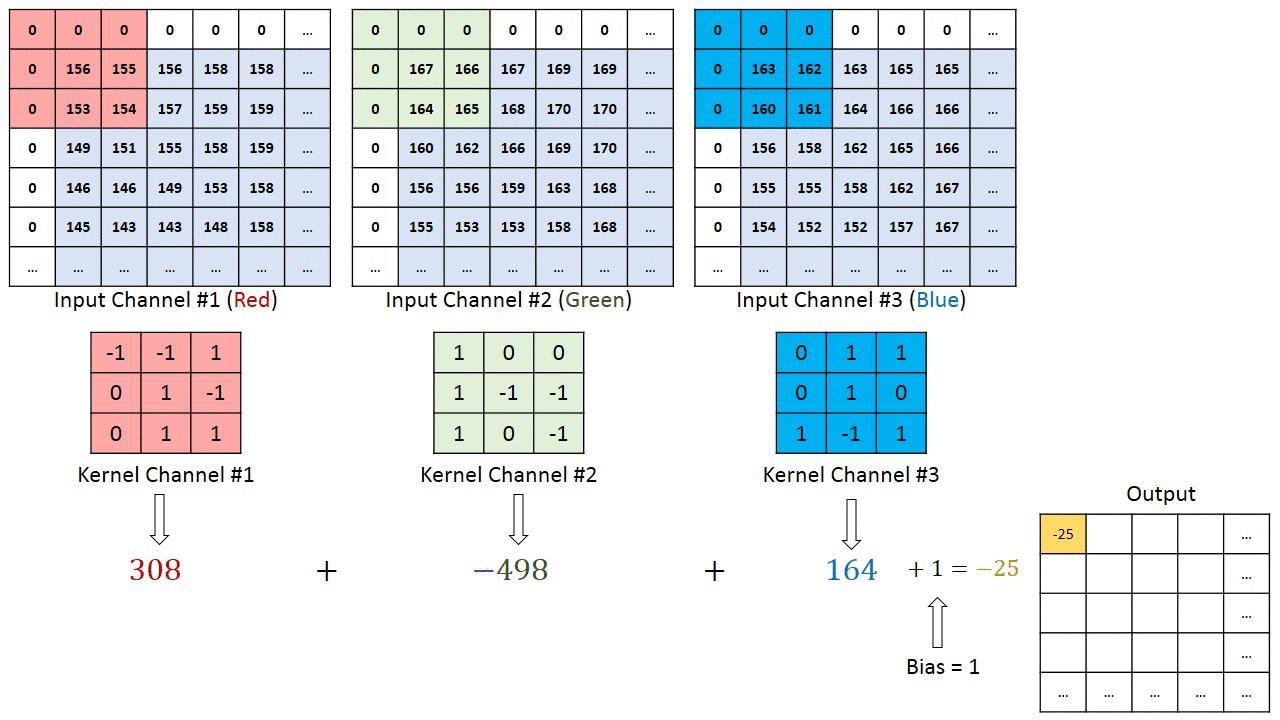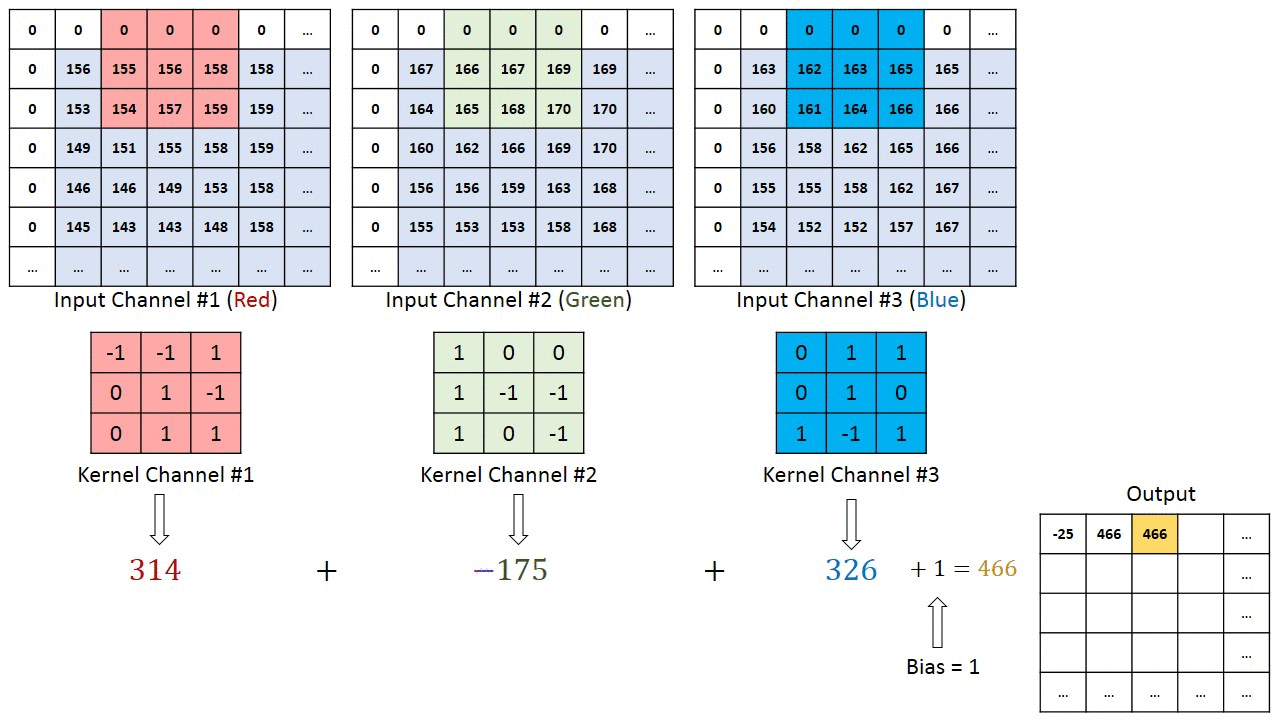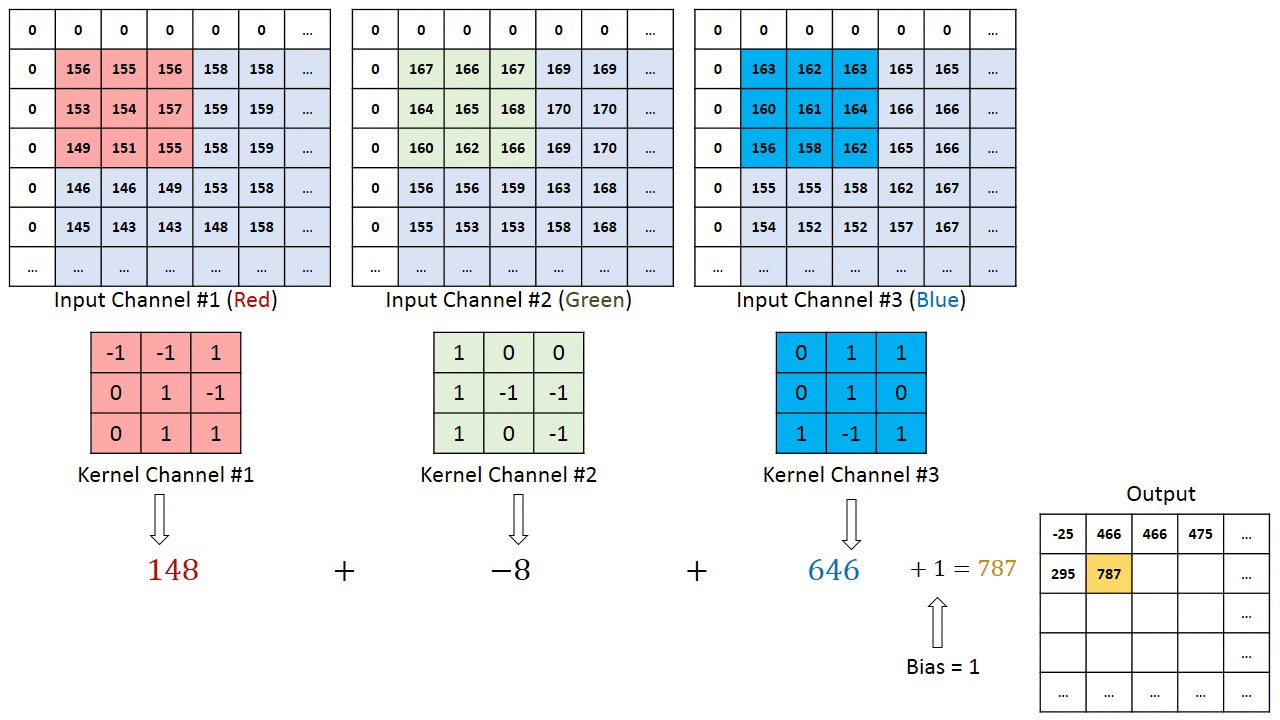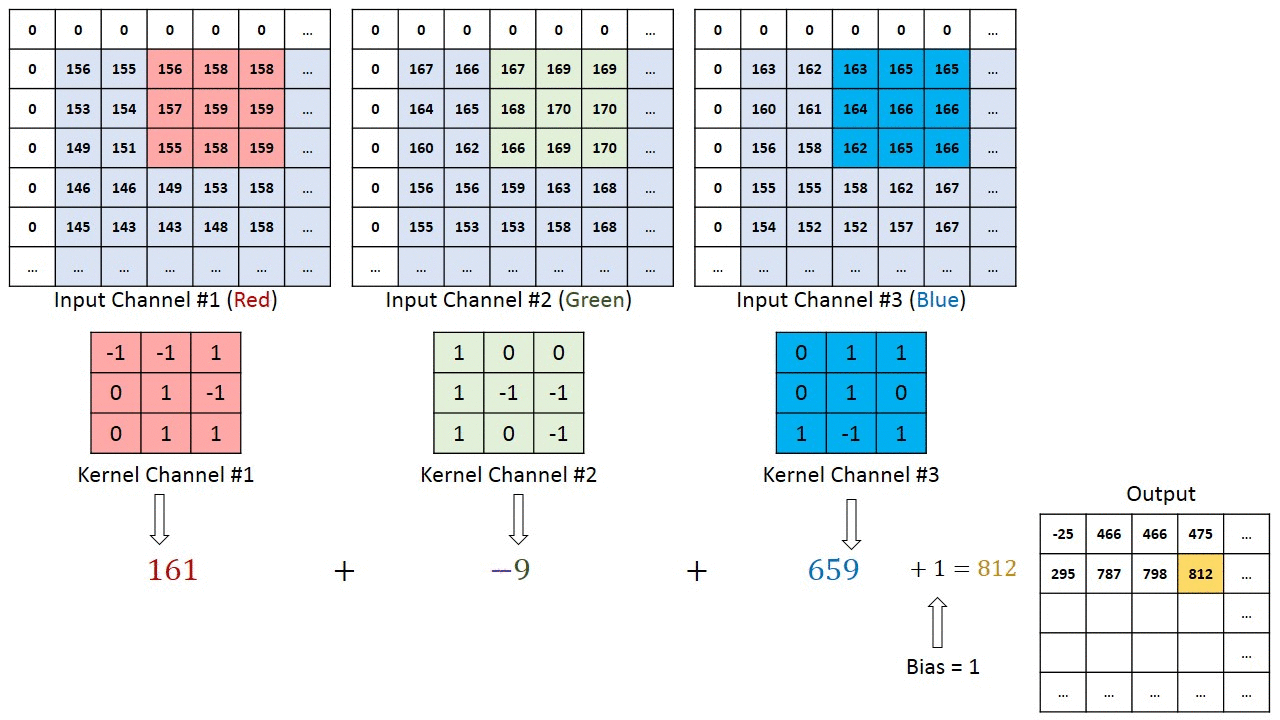
När det gäller bilder med flera kanaler (t.ex. RGB ) har kärnan samma djup som ingångsbildens. Matrixmultiplikation utförs mellan Kn och In stack (;;) och alla resultat summeras med förspänningen för att ge oss en sammanpressad en-djupskanal Convoluted Feature Output. >
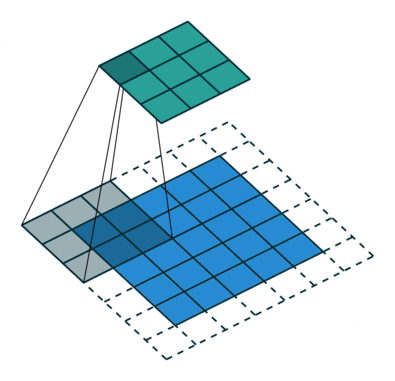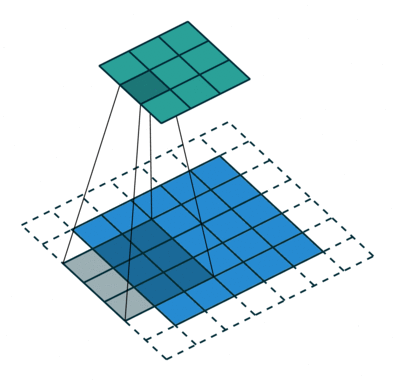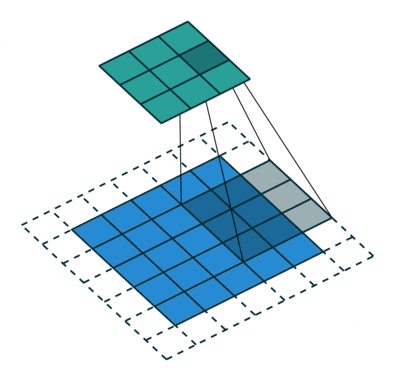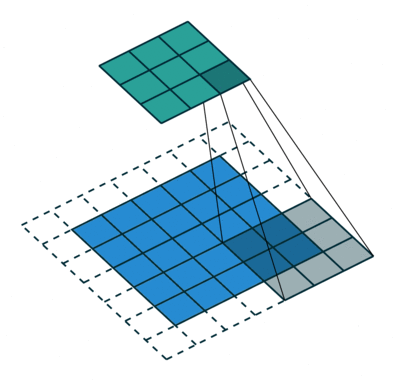
Syftet med Convolution Operation är att extrahera funktioner på hög nivå som kanter, från inmatningsbilden. ConvNets behöver inte vara begränsade till bara ett Convolutional Layer. Konventionellt är det första ConvLayer som ansvarar för att fånga lågnivåfunktionerna som kanter, färg, lutningsorientering etc. Med tillagda lager anpassar arkitekturen sig till högnivåfunktionerna, vilket ger oss ett nätverk som har en sund förståelse av bilder i datamängden, liknar hur vi skulle göra.
Det finns två typer av resultat i operationen – en där den konvolverade funktionen minskar dimensionen jämfört med ingången och den andra där dimensionaliteten ökar antingen eller förblir densamma. Detta görs genom att använda Valid Padding i fallet med den förra, eller Same Padding i fallet med den senare.
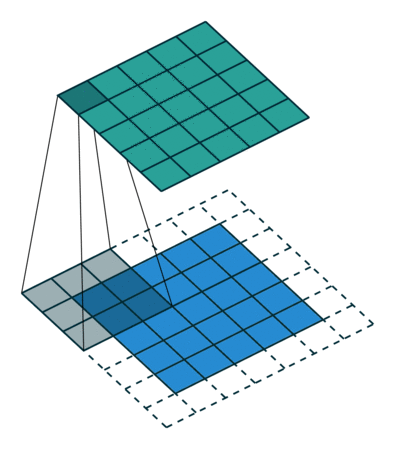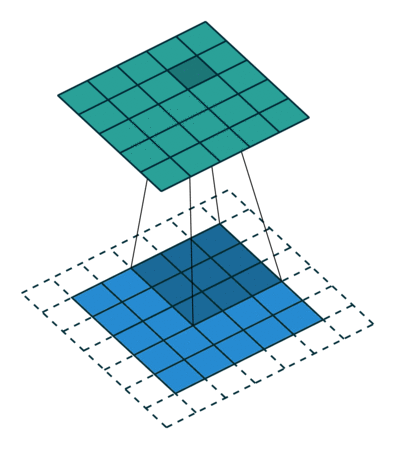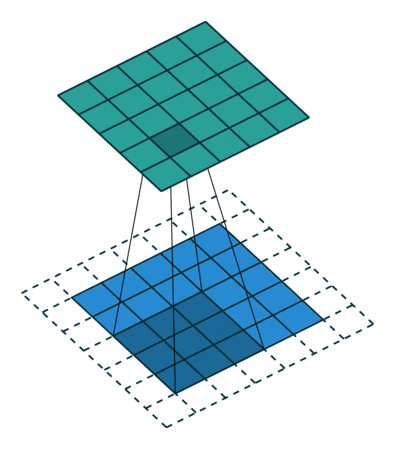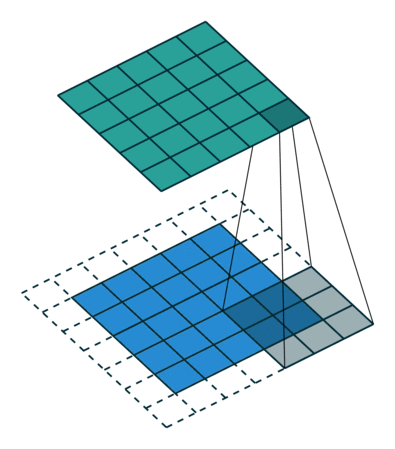
När vi förstärker 5x5x1-bilden till en 6x6x1-bild och sedan applicerar 3x3x1-kärnan över den, finner vi att konvolverad matris visar sig ha dimensioner 5x5x1. Därav namnet – Samma padding.
Å andra sidan, om vi utför samma operation utan vaddering, presenteras vi för en matris som har dimensionerna på själva Kärnan (3x3x1) – Valid Padding.
Följande arkiv innehåller många sådana GIF-filer som skulle hjälpa dig att få en bättre förståelse för hur Padding och Stride Length fungerar tillsammans för att uppnå resultat som är relevanta för våra behov.
Pooling Layer
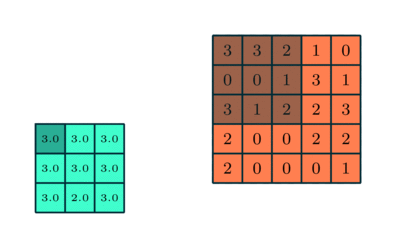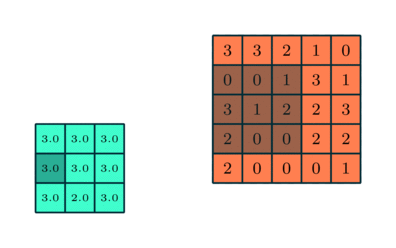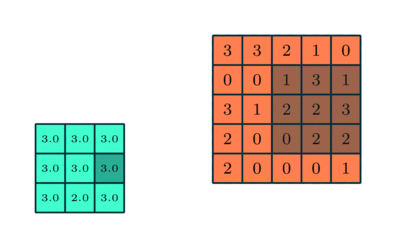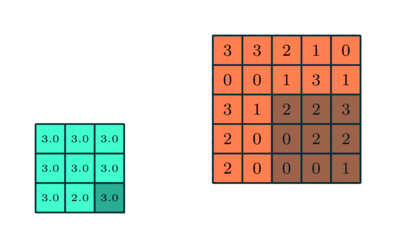
Liknar Convolutional Layer, Pooling-lagret ansvarar för att minska den rumsliga storleken på Convolved Feature. Detta för att minska den beräkningskraft som krävs för att bearbeta data genom dimensioneringsreduktion. Dessutom är det användbart för att extrahera dominerande funktioner som är roterande och positionella invarianta, och därmed bibehålla processen för effektiv träning av modellen.
Det finns två typer av pooling: Max Pooling och Average Pooling. Max Pooling returnerar det maximala värdet från den del av bilden som täcks av kärnan. Å andra sidan returnerar genomsnittlig poolning medelvärdet av alla värden från den del av bilden som täcks av kärnan.
Maxpooling fungerar också som ett brusreducerande medel. Det slänger de bullriga aktiveringarna helt och hållet och utför även av buller tillsammans med dimensioneringsreduktion. Å andra sidan utför genomsnittlig sammanslagning helt enkelt dimensioneringsreduktion som en ljudundertryckande mekanism. Därför kan vi säga att Max Pooling presterar mycket bättre än genomsnittlig pooling.
Convolutional Layer och Pooling Layer bildar tillsammans det i: e lagret av ett Convolutional Neural Network. Beroende på komplexiteten i bilderna kan antalet sådana lager ökas för att fånga detaljer på låga nivåer ytterligare, men på bekostnad av mer beräkningskraft.
Efter att ha gått igenom ovanstående process har vi gjorde det möjligt för modellen att förstå funktionerna. När vi går vidare kommer vi att plana ut den slutliga produktionen och mata den till ett vanligt neuralt nätverk för klassificeringsändamål.
Klassificering – Fullt anslutet lager (FC Layer)

Att lägga till ett fullständigt anslutet lager är ett (vanligtvis) billigt sätt att lära sig icke-linjära kombinationer av högnivåfunktionerna som representeras av utgången från konvolutionsskiktet. Det fullständigt anslutna lagret lär sig en möjligen icke-linjär funktion i det utrymmet.
Nu när vi har konverterat vår ingångsbild till en lämplig form för vår Multi-Level Perceptron, ska vi platta bilden till en kolumnvektor. Den plana utmatningen matas till ett neuralt nätverk för matning framåt och backpropagation appliceras på varje iteration av träning. Under en serie av epoker kan modellen skilja mellan dominerande och vissa lågnivåfunktioner i bilder och klassificera dem med hjälp av Softmax Classification-tekniken.
Det finns olika arkitekturer av CNNs som har varit viktiga för bygga algoritmer som driver och ska driva AI som helhet inom överskådlig framtid. Några av dem har listats nedan:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
