A inteligência artificial tem testemunhado um crescimento monumental na redução da lacuna entre as capacidades dos humanos e das máquinas. Pesquisadores e entusiastas trabalham em vários aspectos do campo para fazer coisas incríveis acontecerem. Uma de muitas dessas áreas é o domínio da Visão Computacional.
A agenda para este campo é permitir que as máquinas vejam o mundo como os humanos, percebam-no de uma maneira semelhante e até mesmo usem o conhecimento para uma multidão de tarefas como Imagem & Reconhecimento de vídeo, Análise de imagem & Classificação, Recriação de mídia, Sistemas de recomendação, Processamento de linguagem natural, etc. Os avanços em Visão Computacional com Aprendizado Profundo foi construído e aperfeiçoado com o tempo, principalmente sobre um algoritmo específico – uma Rede Neural Convolucional.
Introdução

Uma rede neural convolucional (ConvNet / CNN) é um aprendizado profundo algoritmo que pode receber uma imagem de entrada, atribuir importância (aprender e pesos e vieses) para vários aspectos / objetos na imagem e ser capaz de diferenciar um do outro. O pré-processamento exigido em um ConvNet é muito menor em comparação com outros algoritmos de classificação. Enquanto em métodos primitivos, os filtros são projetados à mão, com treinamento suficiente, ConvNets têm a capacidade de aprender esses filtros / características.
A arquitetura de um ConvNet é análoga ao padrão de conectividade de Neurons in the Human Brain e foi inspirado na organização do Visual Cortex. Os neurônios individuais respondem a estímulos apenas em uma região restrita do campo visual conhecida como Campo Receptivo. Uma coleção de tais campos se sobrepõe para cobrir toda a área visual.
Por que ConvNets em vez de redes neurais feed-forward?

Uma imagem nada mais é que uma matriz de valores de pixel, certo? Então, por que não apenas nivelar a imagem (por exemplo, matriz de imagem 3×3 em um vetor 9×1) e alimentá-la em um Perceptron multinível para fins de classificação? Uh … não realmente.
Em casos de imagens binárias extremamente básicas, o método pode mostrar uma pontuação de precisão média ao realizar a previsão de classes, mas teria pouca ou nenhuma precisão quando se trata de imagens complexas com dependências de pixel por toda parte.
Um ConvNet é capaz de capturar com sucesso as dependências Espaciais e Temporais em uma imagem por meio da aplicação de filtros relevantes. A arquitetura realiza um melhor ajuste ao conjunto de dados da imagem devido à redução no número de parâmetros envolvidos e reutilização de pesos. Em outras palavras, a rede pode ser treinada para compreender melhor a sofisticação da imagem.
Imagem de entrada

Na figura, temos uma imagem RGB que foi separada por seus três planos de cores – Vermelho, Verde, e azul. Existem vários desses espaços de cores em que existem imagens – tons de cinza, RGB, HSV, CMYK, etc.
Você pode imaginar como as coisas seriam intensas em computação quando as imagens alcançassem dimensões, digamos 8K (7680 × 4320). O papel do ConvNet é reduzir as imagens a uma forma mais fácil de processar, sem perder recursos que são fundamentais para obter uma boa previsão. Isso é importante quando devemos projetar uma arquitetura que não seja apenas boa para aprender recursos, mas também escalável para conjuntos de dados massivos.
Camada de convolução – o kernel
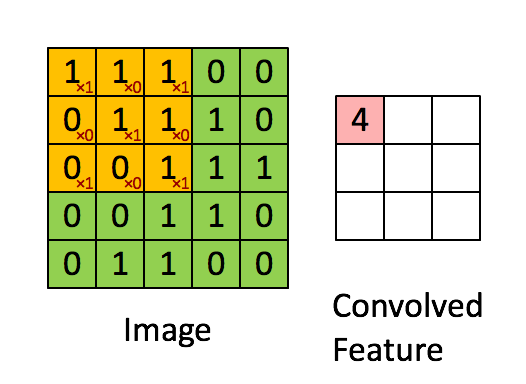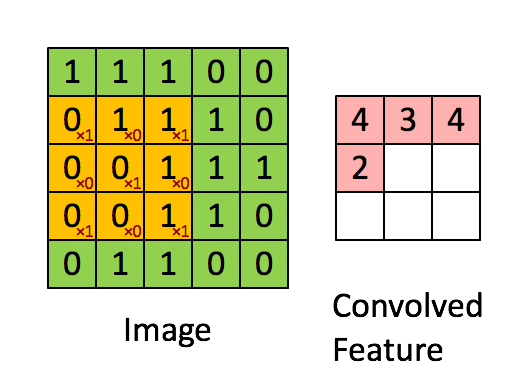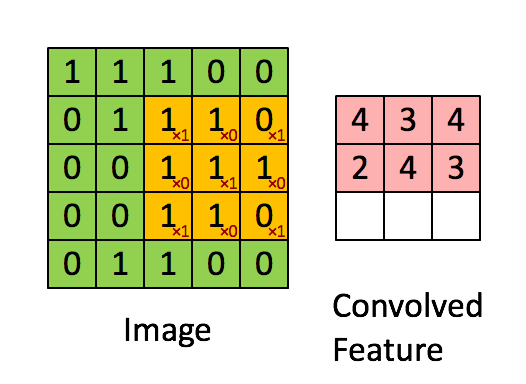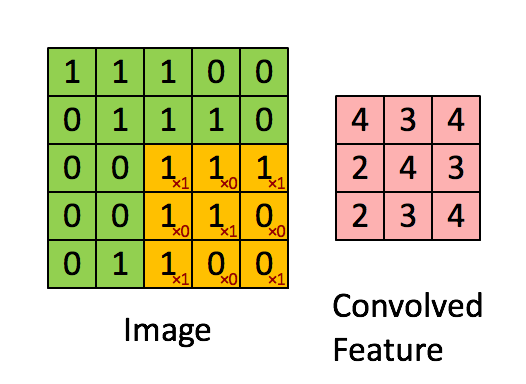
Imagem Dimensões = 5 (Altura) x 5 (Largura) x 1 (Número de canais, por exemplo, RGB)
Na demonstração acima, a seção verde se assemelha à nossa imagem de entrada 5x5x1, I. O elemento envolvido no transporte A operação de convolução na primeira parte de uma camada convolucional é chamada de núcleo / filtro, K, representado na cor amarela. Selecionamos K como uma matriz 3x3x1.
Kernel/Filter, K = 1 0 1
0 1 0
1 0 1
O kernel muda 9 vezes devido ao comprimento da passada = 1 (sem stride), sempre realizando uma matriz operação de multiplicação entre K e a porção P da imagem sobre a qual o kernel está pairando.

O filtro se move para a direita com um certo valor de passada até analisar a largura completa. Continuando, ele salta para o início (esquerda) da imagem com o mesmo valor de passo e repete o processo até que toda a imagem seja percorrida.
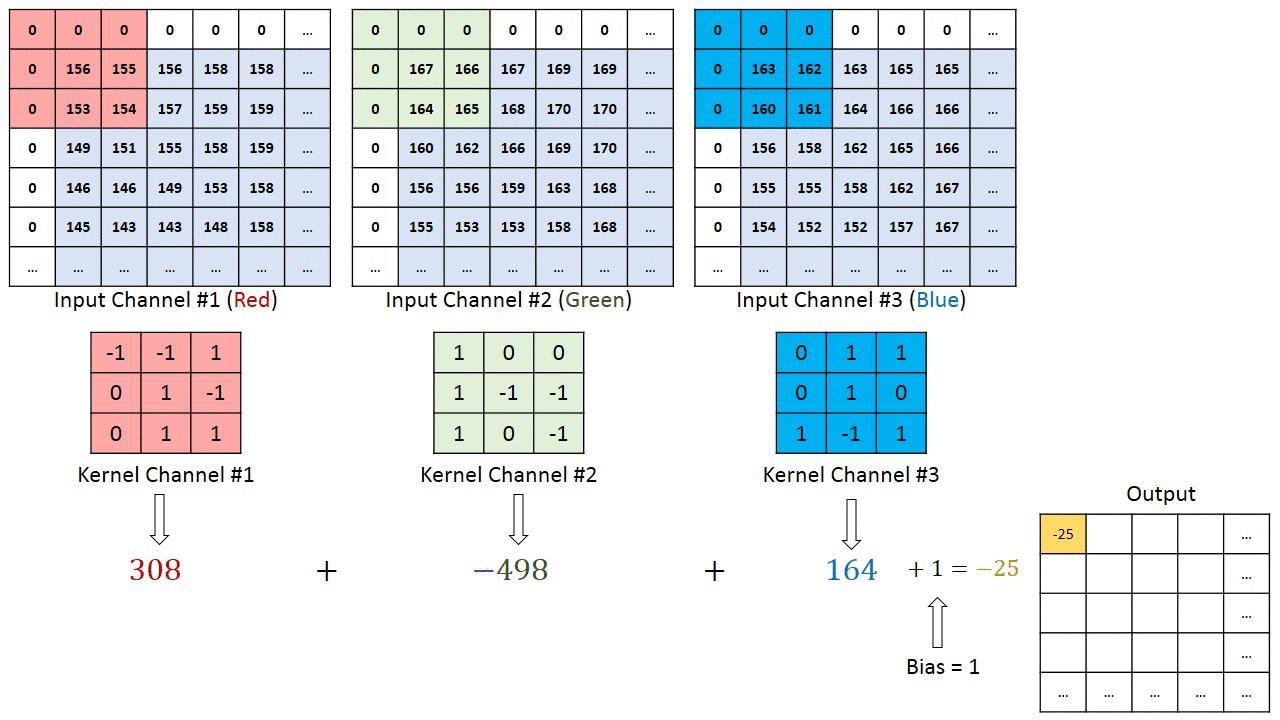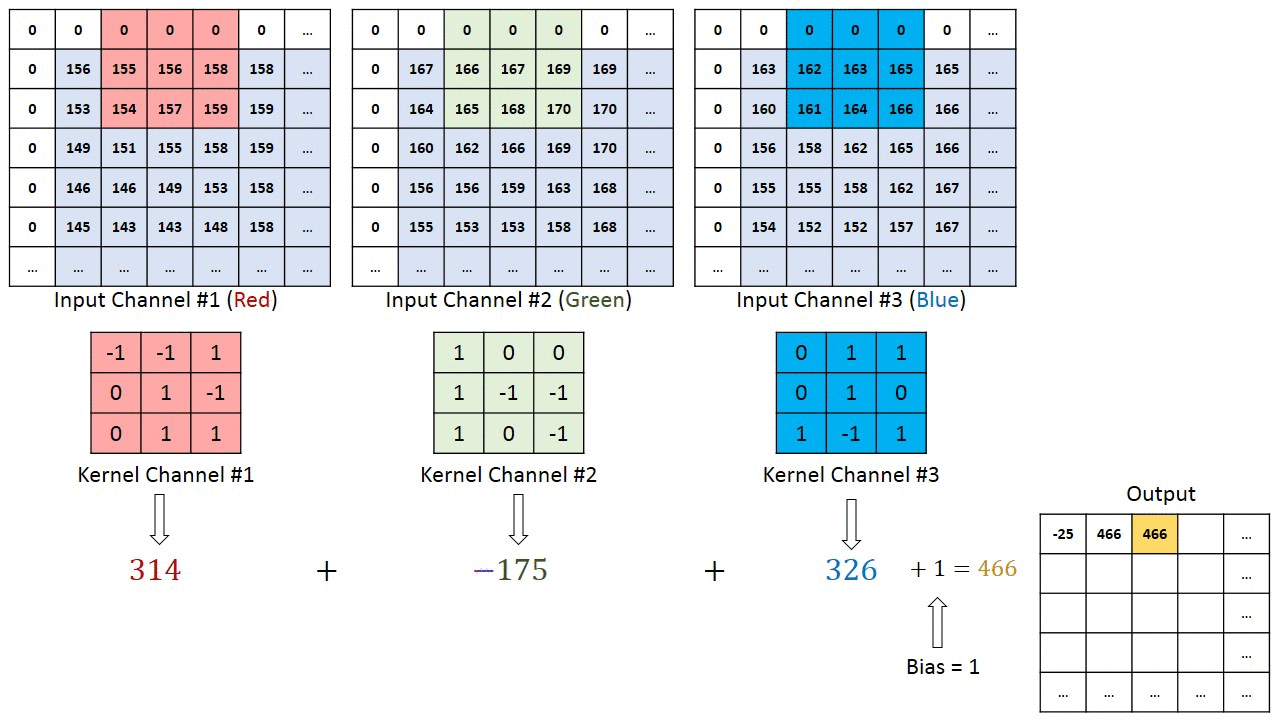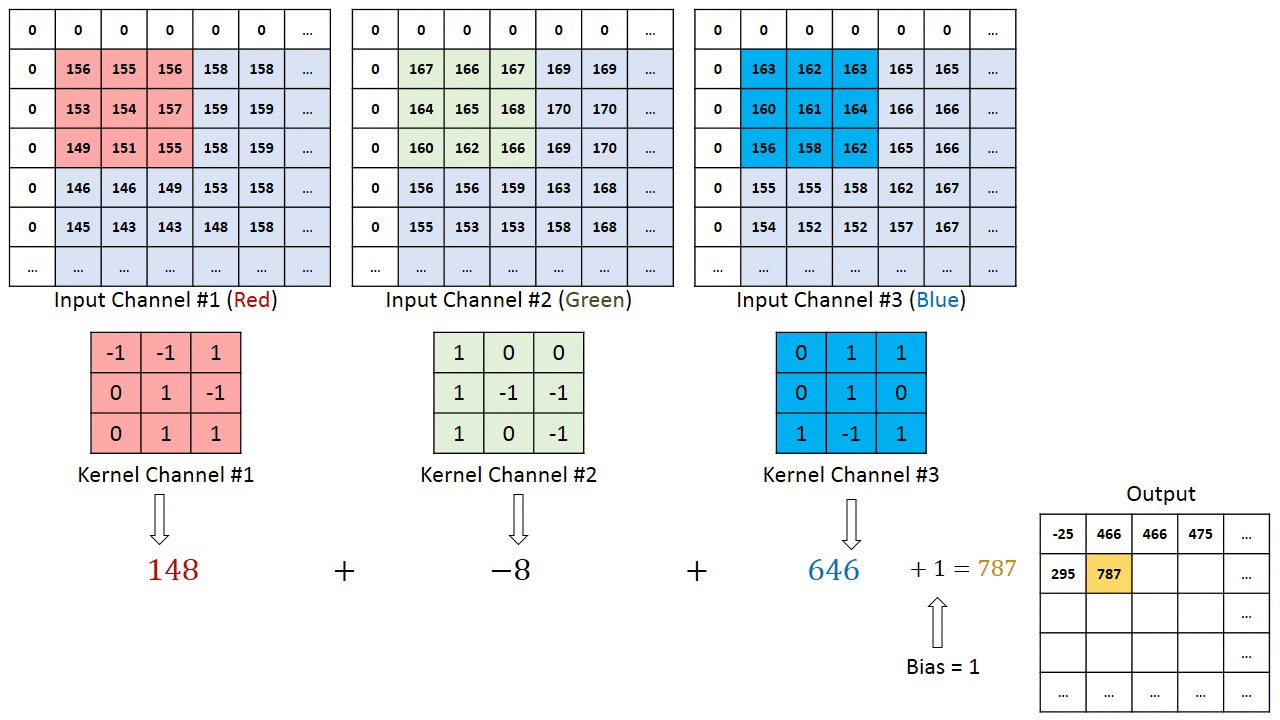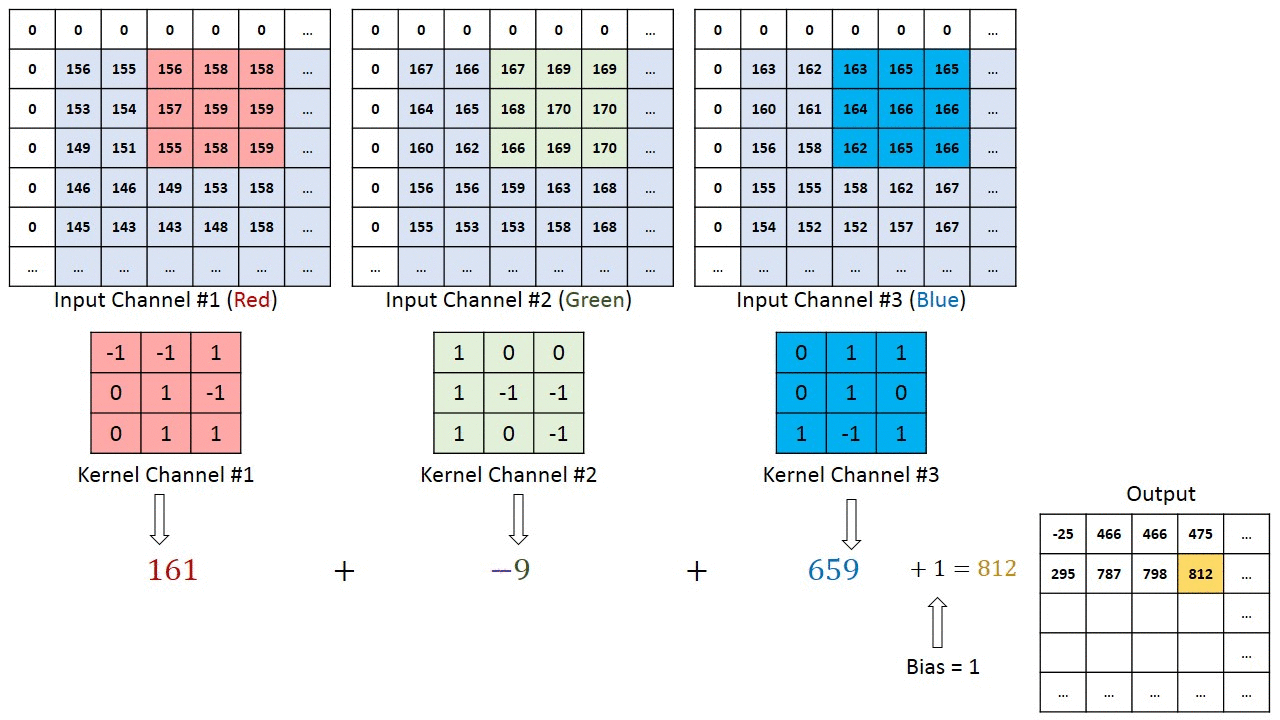
No caso de imagens com múltiplos canais (por exemplo, RGB ), o kernel tem a mesma profundidade da imagem de entrada. A multiplicação da matriz é realizada entre as pilhas Kn e In (;;) e todos os resultados são somados com a tendência para nos dar uma saída de recurso convoluta do canal de uma profundidade comprimida.
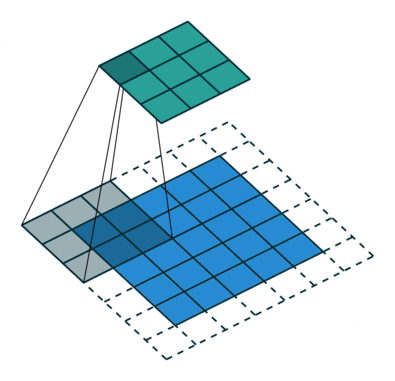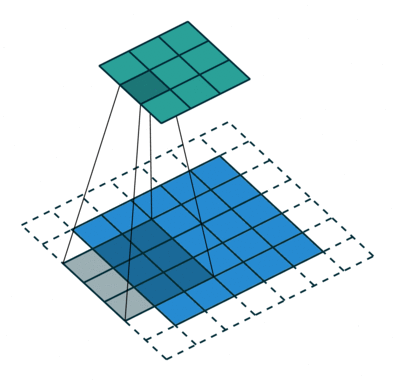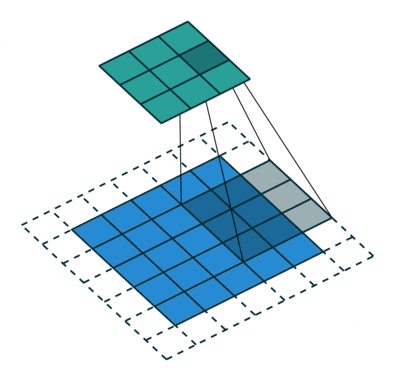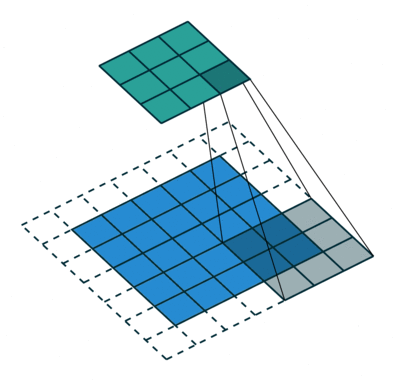
O objetivo da operação de convolução é extrair as características de alto nível, como bordas, da imagem de entrada. ConvNets não precisam ser limitados a apenas uma camada convolucional. Convencionalmente, o primeiro ConvLayer é responsável por capturar os recursos de baixo nível, como bordas, cor, orientação de gradiente, etc. Com camadas adicionadas, a arquitetura se adapta aos recursos de alto nível também, dando-nos uma rede que tem o entendimento completo de imagens no conjunto de dados, semelhante ao que faríamos.
Existem dois tipos de resultados para a operação – um em que o recurso convolvido é reduzido em dimensionalidade em comparação com a entrada e outro em que a dimensionalidade é aumentada ou permanece a mesma. Isso é feito aplicando-se o preenchimento válido no caso do primeiro, ou o mesmo preenchimento no caso do último.
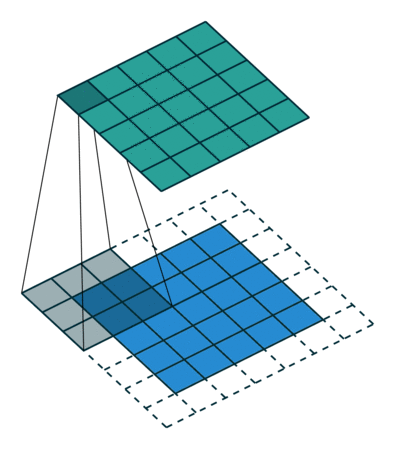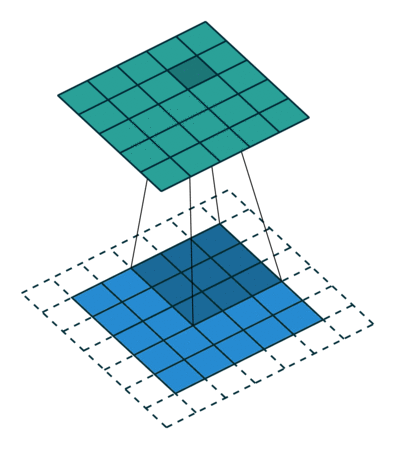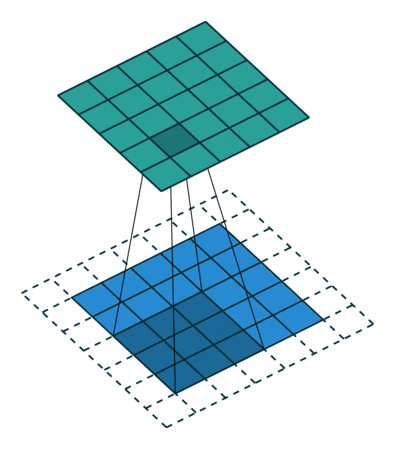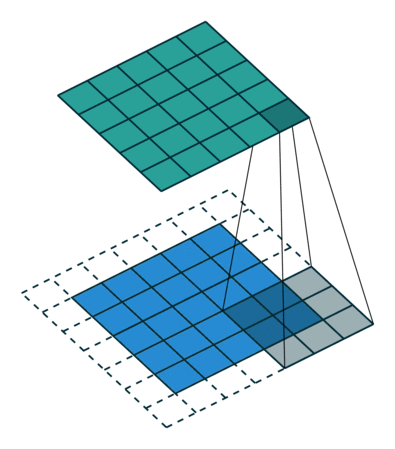
Quando aumentamos a imagem 5x5x1 para uma imagem 6x6x1 e, em seguida, aplicamos o kernel 3x3x1 sobre ela, descobrimos que o a matriz convolvida tem as dimensões 5x5x1. Daí o nome – Same Padding.
Por outro lado, se realizarmos a mesma operação sem padding, nos é apresentada uma matriz que possui as próprias dimensões do Kernel (3x3x1) – Valid Padding.
O repositório a seguir contém muitos desses GIFs que o ajudariam a entender melhor como Padding e Stride Length funcionam juntos para alcançar resultados relevantes para nossas necessidades.
Pooling Layer
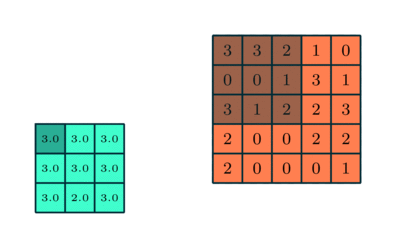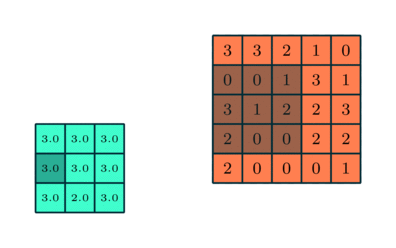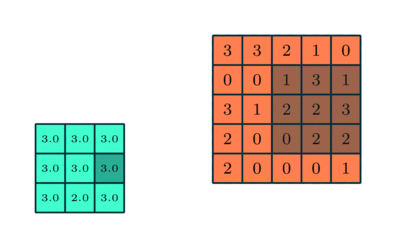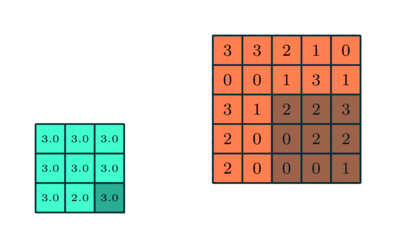
Semelhante à Camada Convolucional, a camada Pooling é responsável por reduzir o tamanho espacial do Convolved Feature. Isso diminui o poder computacional necessário para processar os dados por meio da redução da dimensionalidade. Além disso, é útil para extrair características dominantes que são invariantes rotacionais e posicionais, mantendo assim o processo de treinamento eficaz do modelo.
Existem dois tipos de Pooling: Pooling máximo e Pooling médio. Max Pooling retorna o valor máximo da parte da imagem coberta pelo Kernel. Por outro lado, Average Pooling retorna a média de todos os valores da parte da imagem coberta pelo kernel.
Max Pooling também atua como um supressor de ruído. Ele descarta completamente as ativações ruidosas e também executa a eliminação de ruído junto com a redução de dimensionalidade. Por outro lado, o Average Pooling simplesmente executa a redução da dimensionalidade como um mecanismo de supressão de ruído. Portanto, podemos dizer que o Pooling máximo tem um desempenho muito melhor do que o Pooling médio.
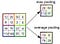
A camada convolucional e a camada pooling, juntas, formam a i-ésima camada de uma rede neural convolucional. Dependendo da complexidade das imagens, o número de tais camadas pode ser aumentado para capturar ainda mais detalhes de baixos níveis, mas ao custo de mais poder computacional.
Depois de passar pelo processo acima, temos habilitou com sucesso o modelo para entender os recursos. Continuando, vamos nivelar a saída final e alimentá-la para uma rede neural normal para fins de classificação.
Classificação – Camada totalmente conectada (camada FC)

Adicionar uma camada Fully-Connected é uma maneira (geralmente) barata de aprender combinações não lineares dos recursos de alto nível, conforme representado pela saída da camada convolucional. A camada Fully-Connected está aprendendo uma função possivelmente não linear nesse espaço.
Agora que convertemos nossa imagem de entrada em uma forma adequada para nosso Perceptron multinível, devemos achatar a imagem em um vetor coluna. A saída achatada é fornecida a uma rede neural feed-forward e a retropropagação aplicada a cada iteração de treinamento. Ao longo de uma série de épocas, o modelo é capaz de distinguir entre características dominantes e certas características de baixo nível em imagens e classificá-las usando a técnica de classificação Softmax.
Existem várias arquiteturas de CNNs disponíveis que foram fundamentais para construir algoritmos que alimentam e devem alimentar AI como um todo em um futuro próximo Alguns deles foram listados abaixo:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
